数据库复习(一)基础理论和SQL语句
文章目录
- 1.数据库范式
- 2. SQL基础知识
- DML
- DDL
- 1.Select
- 2.Where
- 3.And & OR
- 4.Order by
- 5.Insert into
- 6.Update
- 7.Delete
- 3.SQL高级知识
- 1.Top
- 2.Like
- 3.通配符
- 4.In
- 5.Between
- 6.Alias(as)
- 7.Join
- 8.Union
- 9.Select into
- 10.Drop
- 11.Alter
- 12.Auto-Increment
- 13.Constraints 约束
- 14.Create Index
- 15.View
- 16.Date
- 17.数据类型
- Text 类型
- Number类型
- Date 类型
- 4、SQL函数
- 1.Group by
- 2.Having
- 附1:分享一些问题
1.数据库范式
一、表中每项独立唯一、
二、主键被依赖
三、非主键依赖主键,无法传递依赖
2. SQL基础知识
SQL (结构化查询语言)是用于执行查询,也包含用于更新、插入和删除记录的语法。
DML
数据操作语言 (DML) :查询和更新指令
- SELECT - 获取数据
- UPDATE - 更新数据
- DELETE - 删除数据
- INSERT INTO - 插入数据
DDL
数据定义语言 (DDL):创建或删除表格,定义索引(键),规定表间链接,施加表间的约束
- CREATE DATABASE - 创建新数据库
- ALTER DATABASE - 修改数据库
- CREATE TABLE - 创建新表
- ALTER TABLE - 变更(改变)数据库表
- DROP TABLE - 删除表
- CREATE INDEX - 创建索引(搜索键)
- DROP INDEX - 删除索引
1.Select
SELECT 列 From表
注:**DISTINCT** 没有重复值
SELECT DISTINCT 列 FROM 表
2.Where
SELECT 列 FROM 表 WHERE 列 运算符 值
注:字符单引号,数字无引号
| 操作符 | 描述 |
|---|---|
| ~~~~ | 常规(大小等) |
| <> | 不等于 |
| BETWEEN | 在某个范围内 |
| LIKE | 搜索某种模式 |
3.And & OR
两条件都成立,AND显示一条记录
只要一个成立,OR显示一条记录
SELECT * FROM 表 WHERE 条件1 AND 条件2
4.Order by
指定结果排序,默认升序
SELECT 列1, 列2 FROM 表 ORDER BY 表1 Desc //按照表1的顺序降序(逆转)排列
5.Insert into
INSERT INTO 表 VALUES (值1, 值2,....) INSERT INTO 表 (列1, 列2,...) VALUES (值1, 值2,....)
6.Update
UPDATE 表 SET 列 = vaue WHERE 列 = 某值 //注:先给修改值,后找位置
7.Delete
DELETE FROM 表 WHERE 列 = 值
3.SQL高级知识
1.Top
定义:前多少个数据
SELECT TOP 2 * FROM 表 TOP PERCENT:前百分比
2.Like
定义:搜索列中的指定模式
SELECT * FROM 表 WHERE 列 LIKE ‘%N%’ SELECT * FROM 表 WHERE 列 Not LIKE ‘%N%’
3.通配符
% _ [charlist] [!charlist]
| 通配符 | 描述 | 例子 |
|---|---|---|
| % | N个字符 | |
| _ | 1个字符 | |
| [charlist] | 包含单一字符 | LIKE ‘[ALN]%’ |
| [!charlist] | 不包含单一字符 |
4.In
定义: WHERE 子句中规定多个值
SELECT * FROM 表 WHERE 列 IN ('val1','cal2')
5.Between
定义: 选取介于两个值之间的数据范围
SELECT * FROM 表 WHERE 列 BETWEEN 'val1' AND 'cal2' // 注:不同DB对于边界包含定义不同
6.Alias(as)
定义: 定义别名
SELECT 列1 AS 别名1, 列2 AS 别名2 FROM 表
主键和外键
主键:表中唯一标识的一列,保证数据完整性,只有一个
外键:用于与另一张表的关联,保持数据一致性,可以多个
-
索引:提高查询排序效率,可以有多个唯一索引
- 聚集索引,索引页里放数据
- 非聚集索引,索引页里放索引(指向数据页)
补充知识:稠密索引 vs 稀疏索引
7.Join
定义: 根据多表中的列之间的关系查询数据
SELECT 列 FROM 表1 Inner Join 表2E 列 BETWEEN 'val1' AND 'cal2'
注:不同DB对于边界包含定义不同
Persons表

Orders表
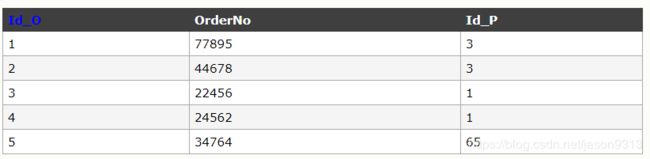


8.Union
合并两个或多个 SELECT 语句的结果集
SELECT 列2 FROM 表1 UNION SELECT 列2 FROM 表2
9.Select into
将原有表的列数据插入新表
作用:制作表的备份
SELECT 列 INTO 新表 FROM 已有表
//从 "Persons" 表中提取居住在 "Beijing" 的人的信息,创建了一个带有两个列的名为 "Persons_backup" 的表 SELECT LastName,Firstname INTO Persons_backup FROM Persons WHERE City='Beijing'
10.Drop
删除:索引、表和数据库
DROP TABLE 表名称 DROP DATABASE 数据库名称 TRUNCATE TABLE 表名称 //清空表中数据
11.Alter
在已有的表中添加、修改或删除列
添加:ALTER TABLE 表 ADD 列 数据类型
删除:ALTER TABLE 表 DROP COLUMN 列 (某些DB不允许)
修改:ALTER TABLE 表 ALTER COLUMN 列 数据类型
12.Auto-Increment
新记录插入表中时生成一个唯一的数字
13.Constraints 约束
约束加入表的数据类型(Create建表时、Alter改表时)
常见约束:
- NOT NULL 不为空
- UNIQUE 唯一
- PRIMARY KEY 主键
- FOREIGN KEY 外键
- CHECK 值范围
- DEFAULT 默认值
CREATE TABLE Persons( Id int UNIQE Id_P int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), City varchar(255) DEFAULT ‘Sandnes’ CHECK (Id_P>0) )
CHEAK
修改过程
// 匿名 ALTER TABLE 表 ADD CHECK (列 >0) // 命名 ALTER TABLE Persons ADD CONSTRAINT 约束名 CHECK ( 列 >0 AND City=‘Sandnes’)
删除
ALTER TABLE 表 DROP CHECK 约束名
Default
修改过程
ALTER TABLE 表 ALTER 列 SET DEFAULT 'value'
删除过程
ALTER TABLE 表 ALTER City DROP DEFAULT
14.Create Index
创建索引
(未完待续)
http://www.w3school.com.cn/sql/sql_create_index.asp
15.View
可视化表。内容:创建、更新和删除视图
1.什么是试图
基于 SQL 语句结果集的可视化的表,包含行列。
可添加 SQL 函数、WHERE 以及 JOIN 语句,以及提交数据
2.基本用法
a.创建视图 CREATE VIEW [视图名] AS SELECT 列(s) FROM 表 WHERE 条件 //查询视图 SELECT * FROM [视图名] b.更新视图 c.撤销视图 SQL DROP VIEW Syntax DROP VIEW [视图名]
16.Date
包括一些基本操作函数 http://www.w3school.com.cn/sql/sql_dates.asp
MySQL 使用下列数据类型在数据库中存储日期或日期/时间值:
- DATE - 格式 YYYY-MM-DD
- DATETIME - 格式: YYYY-MM-DD HH:MM:SS
- TIMESTAMP - 格式: YYYY-MM-DD HH:MM:SS
- YEAR - 格式 YYYY 或 YY
17.数据类型
Text 类型
| 数据类型 | 描述 |
|---|---|
| CHAR(size) | 保存固定长度字符串(可包含字母、数字以及特殊字符)括号中指定字符串的长度,最多 255 个字符 |
| VARCHAR(size) | 保存可变长度的字符串(可包含字母、数字以及特殊字符)注释:如果值的长度大于 255,则被转换为 TEXT 类型。 |
| TINYTEXT | 存放最大长度为 255 个字符的字符串。 |
| TEXT | 存放最大长度为 65,535 个字符的字符串。 |
| BLOB | 用于 BLOBs (Binary Large OBjects)。存放最多 65,535 字节的数据。 |
| MEDIUMTEXT | 存放最大长度为 16,777,215 个字符的字符串。 |
| MEDIUMBLOB | 用于 BLOBs (Binary Large OBjects)。存放最多 16,777,215 字节的数据。 |
| LONGTEXT | 存放最大长度为 4,294,967,295 个字符的字符串。 |
| LONGBLOB | 用于 BLOBs (Binary Large OBjects)。存放最多 4,294,967,295 字节的数据。 |
| ENUM(x,y,z,etc.) | 允许你输入可能值的列表。可以在 ENUM 列表中列出最大 65535 个值。如果列表中不存在插入的值,则插入空值。注释:这些值是按照你输入的顺序存储的。可以按照此格式输入可能的值:ENUM(‘X’,‘Y’,‘Z’) |
| SET | 与 ENUM 类似,SET 最多只能包含 64 个列表项,不过 SET 可存储一个以上的值。 |
Number类型
| 数据类型 | 描述 |
|---|---|
| TINYINT(size) | -128 到 127 常规。0 到 255 无符号*。在括号中规定最大位数。 |
| SMALLINT(size) | -32768 到 32767 常规。0 到 65535 无符号*。在括号中规定最大位数。 |
| MEDIUMINT(size) | -8388608 到 8388607 普通。0 to 16777215 无符号*。在括号中规定最大位数。 |
| INT(size) | -2147483648 到 2147483647 常规。0 到 4294967295 无符号*。在括号中规定最大位数。 |
| BIGINT(size) | -9223372036854775808 到 9223372036854775807 常规。0 到 18446744073709551615 无符号*。在括号中规定最大位数。 |
| FLOAT(size,d) | 带有浮动小数点的小数字。在括号中规定最大位数。在 d 参数中规定小数点右侧的最大位数。 |
| DOUBLE(size,d) | 带有浮动小数点的大数字。在括号中规定最大位数。在 d 参数中规定小数点右侧的最大位数。 |
| DECIMAL(size,d) | 作为字符串存储的 DOUBLE 类型,允许固定的小数点。 |
* 这些整数类型拥有额外的选项 UNSIGNED。通常,整数可以是负数或正数。如果添加 UNSIGNED 属性,那么范围将从 0 开始,而不是某个负数。
Date 类型
| 数据类型 | 描述 |
|---|---|
| DATE() | 日期。格式:YYYY-MM-DD注释:支持的范围是从 ‘1000-01-01’ 到 ‘9999-12-31’ |
| DATETIME() | *日期和时间的组合。格式:YYYY-MM-DD HH:MM:SS注释:支持的范围是从 ‘1000-01-01 00:00:00’ 到 ‘9999-12-31 23:59:59’ |
| TIMESTAMP() | *时间戳。TIMESTAMP 值使用 Unix 纪元(‘1970-01-01 00:00:00’ UTC) 至今的描述来存储。格式:YYYY-MM-DD HH:MM:SS注释:支持的范围是从 ‘1970-01-01 00:00:01’ UTC 到 ‘2038-01-09 03:14:07’ UTC |
| TIME() | 时间。格式:HH:MM:SS 注释:支持的范围是从 ‘-838:59:59’ 到 ‘838:59:59’ |
| YEAR() | 2 位或 4 位格式的年。注释:4 位格式所允许的值:1901 到 2155。2 位格式所允许的值:70 到 69,表示从 1970 到 2069。 |
4、SQL函数
语法
SELECT function(列) FROM 表
类型
- Aggregate 合计函数----面向一系列的值,并返回一个单一的值
- Scalar 数量函数—某个单一的值,并返回基于输入值的一个单一的值
在 SQL Server 中的合计函数
| 函数 | 描述 |
|---|---|
| AVG(column) | 返回某列的平均值 |
| COUNT(column) | 函数返回匹配指定条件的行数(数目) |
| COUNT(*) | 返回被选行数 |
| COUNT(DISTINCT column) | 返回相异结果的数目 |
| FIRST(column) | 返回在指定的域中第一个记录的值(SQLServer2000 不支持) |
| LAST(column) | 返回在指定的域中最后一个记录的值(SQLServer2000 不支持) |
| MAX(column) | 返回某列的最高值 |
| MIN(column) | 返回某列的最低值 |
| SUM(column) | 返回某列的总和 |
MS Access 中的 Scalar 函数
| 函数 | 描述 |
|---|---|
| UCASE(列名) | 将某个域转换为大写 |
| LCASE(列名) | 将某个域转换为小写 |
| MID(列名,start[,end]) | 从某个文本域提取字符 |
| LEN(列) | 返回某个文本域的长度 |
| ROUND(列名,小数位数) | 对某个数值域进行指定小数位数的四舍五入 |
| MOD(x,y) | 返回除法操作的余数 |
| NOW() | 返回当前的系统日期 |
| FORMAT(列名,规定格式) | 改变某个域的显示方式 |
1.Group by
定义: 根据一个或多个列对结果集进行分组
SELECT 列名, 函数名(列名) FROM 表名
WHERE 条件
GROUP BY 列名1,列名2
2.Having
WHERE 关键字无法与合计函数一起使用
SELECT 列名, 函数名(列名) FROM 表名
WHERE 条件 GROUP BY 列名1,列名2
HAVING 函数名(列名) operator value
SELECT Customer,SUM(OrderPrice) FROM Orders
WHERE Customer='Bush' OR Customer='Adams' GROUP BY Customer
HAVING SUM(OrderPrice)>1500
SQL快速参考
| 语句 | 语法 |
|---|---|
| AND / OR | SELECT column_name(s)FROM table_nameWHERE conditionAND|OR condition |
| ALTER TABLE (add column) | ALTER TABLE table_name ADD column_name datatype |
| ALTER TABLE (drop column) | ALTER TABLE table_name DROP COLUMN column_name |
| AS (alias for column) | SELECT column_name AS column_aliasFROM table_name |
| AS (alias for table) | SELECT column_nameFROM table_name AS table_alias |
| BETWEEN | SELECT column_name(s)FROM table_nameWHERE column_nameBETWEEN value1 AND value2 |
| CREATE DATABASE | CREATE DATABASE database_name |
| CREATE INDEX | CREATE INDEX index_nameON table_name (column_name) |
| CREATE TABLE | CREATE TABLE table_name(column_name1 data_type,column_name2 data_type,…) |
| CREATE UNIQUE INDEX | CREATE UNIQUE INDEX index_nameON table_name (column_name) |
| CREATE VIEW | CREATE VIEW view_name ASSELECT column_name(s)FROM table_nameWHERE condition |
| DELETE FROM | DELETE FROM table_name (Note: Deletes the entire table!!)orDELETE FROM table_nameWHERE condition |
| DROP DATABASE | DROP DATABASE database_name |
| DROP INDEX | DROP INDEX table_name.index_name |
| DROP TABLE | DROP TABLE table_name |
| GROUP BY | SELECT column_name1,SUM(column_name2)FROM table_nameGROUP BY column_name1 |
| HAVING | SELECT column_name1,SUM(column_name2)FROM table_nameGROUP BY column_name1HAVING SUM(column_name2) condition value |
| IN | SELECT column_name(s)FROM table_nameWHERE column_nameIN (value1,value2,…) |
| INSERT INTO | INSERT INTO table_nameVALUES (value1, value2,…)orINSERT INTO table_name(column_name1, column_name2,…)VALUES (value1, value2,…) |
| LIKE | SELECT column_name(s)FROM table_nameWHERE column_nameLIKE pattern |
| ORDER BY | SELECT column_name(s)FROM table_nameORDER BY column_name [ASC|DESC] |
| SELECT | SELECT column_name(s)FROM table_name |
| SELECT * | SELECT *FROM table_name |
| SELECT DISTINCT | SELECT DISTINCT column_name(s)FROM table_name |
| SELECT INTO(used to create backup copies of tables) | SELECT INTO new_table_nameFROM original_table_nameor*SELECT column_name(s)INTO new_table_nameFROM original_table_name |
| TRUNCATE TABLE(deletes only the data inside the table) | TRUNCATE TABLE table_name |
| UPDATE | UPDATE table_nameSET column_name=new_value[, column_name=new_value]WHERE column_name=some_value |
| WHERE | SELECT column_name(s)FROM table_nameWHERE condition |
附1:分享一些问题
转载内容:原po出处已不详。如有侵权,请联络本人。
