李宏毅: improved generative adversarial network(GAN)
1、generation

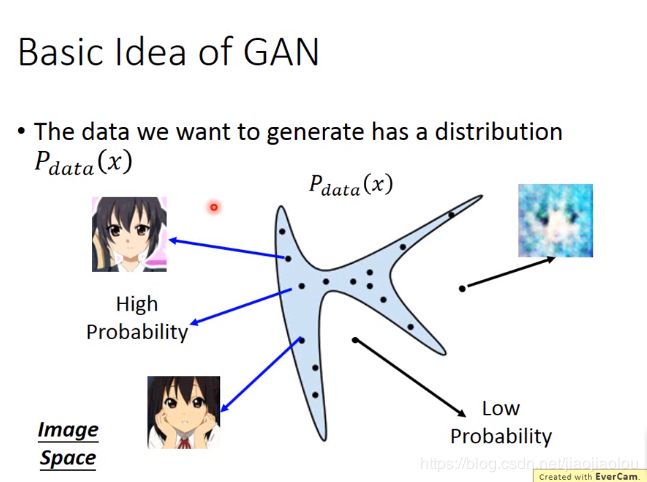
从normal distribution(正态分布)中sample出一些点:

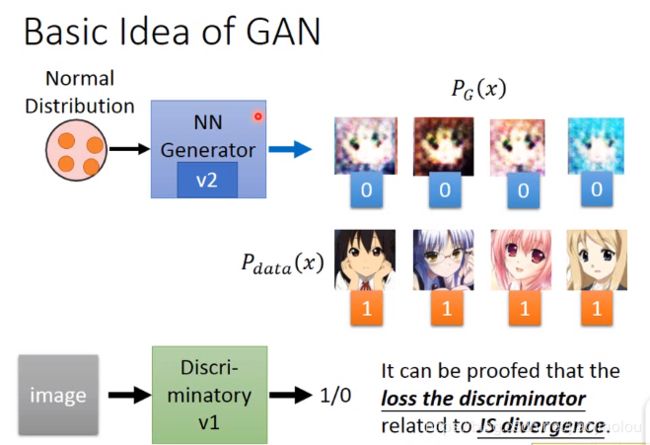
generator需要update它的参数,使得它output产生的image能被discriminator误认为它是realistic。

再update discriminator,使得之前被它判断出来是realistic的image重新判断为fake。
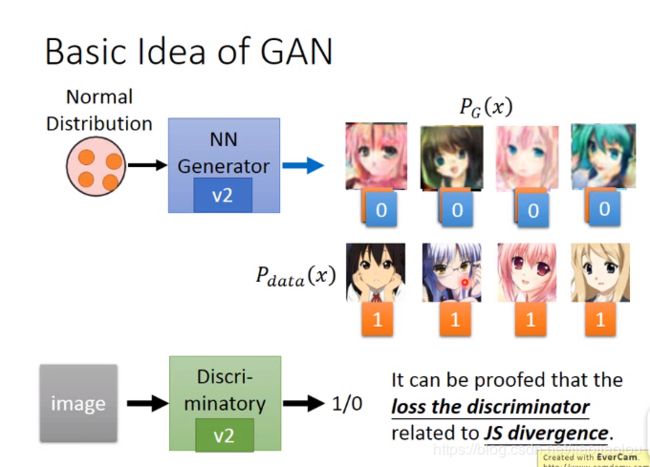
不断更新,直到generator产生出的image够好为止。
2、algorithm


3、f-divergence
convex function是指凸函数

(1)KL-divergence
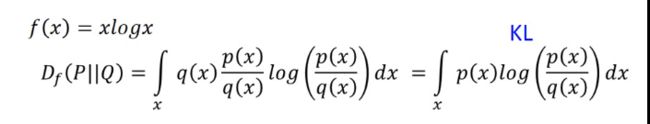
(2)Reverse KL divergence
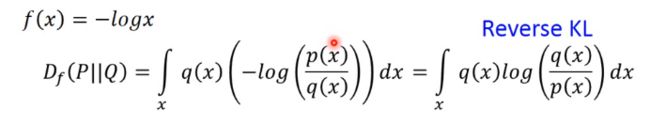
(3)Chi Square
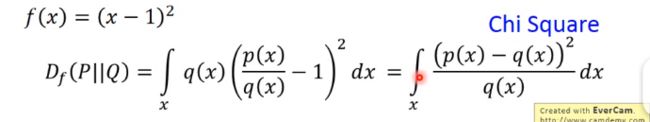
4、Fenchel Conjugate(Fenchel 共轭)
(1)
给定t,找到不同x下的f*(t)的最大值

先给定x,得到不同的直线,再给定t,找到式子的最大值。不断取不同的t,就会得到不同的f*,下图所示的红色实线就是f*(t),是一个convex。
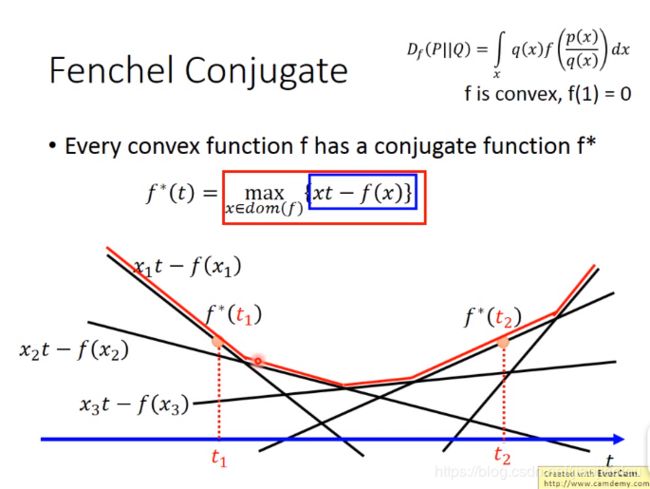
如下图:f(x) = xlogx,则画出来的f*(t)有点像指数(expoential)函数。


(2)connection with GAN
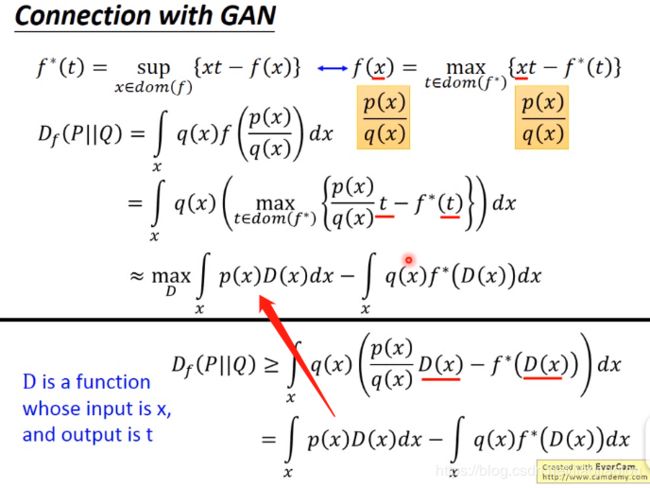

5、double loop vs single step


6、WGAN
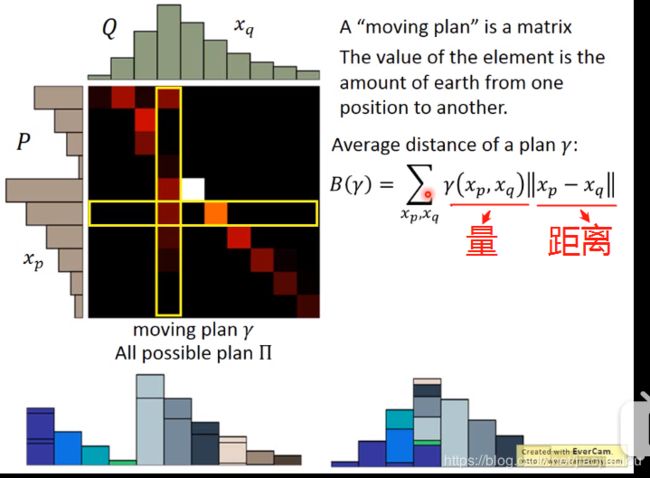
(1)earth mover's distance
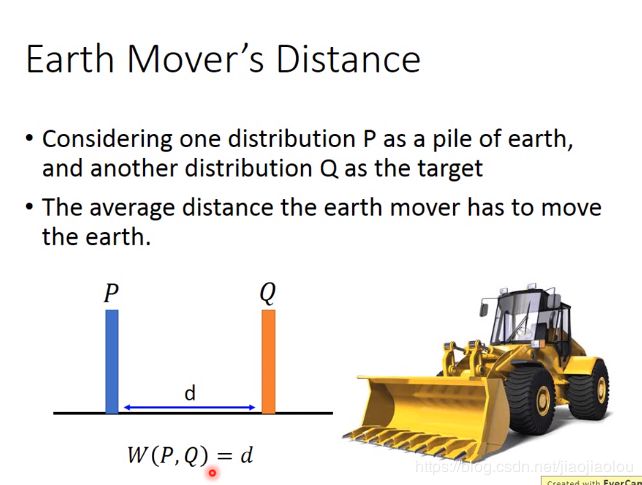
想把P的distribution移成Q的distribution,会有很多不一样的方法,所以你的distance也不一样。选移动距离最小的。
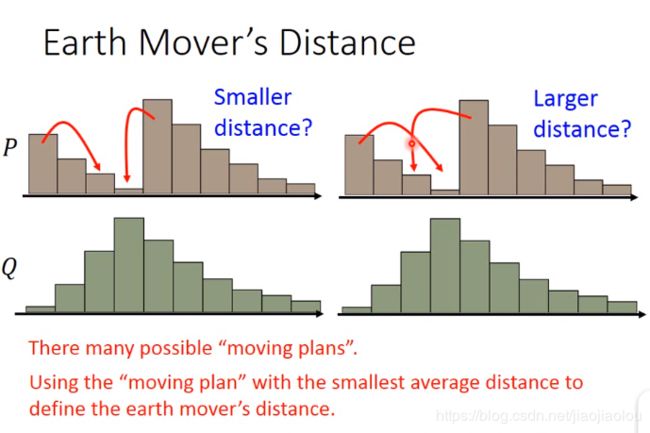
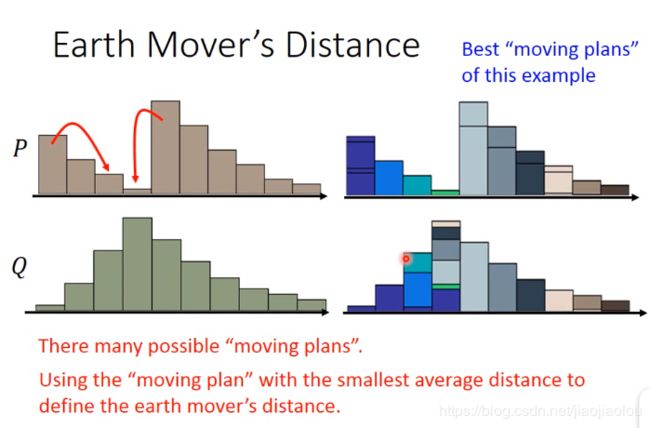
每一个row之和,为P要运送出去的量,颜色越亮,量越多。

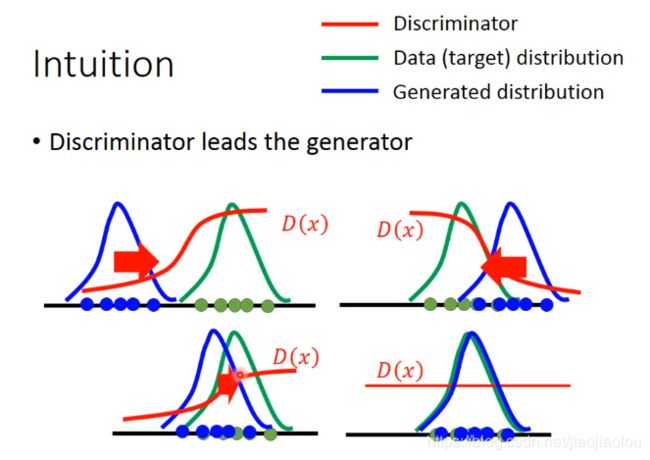
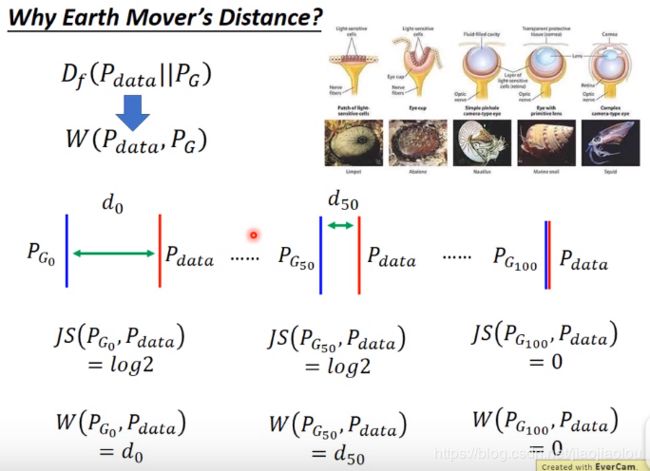
如果用JS divergence,会发现PG50并没有比PG0更接近Pdata。但如果用earth mover's distance就会不一样。这样你在做gradient的时候会有梯度下降。

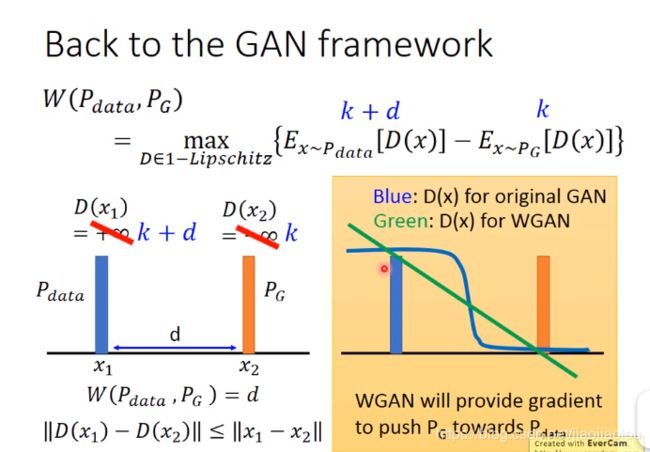
右边绿色的那根线,从PG到Pdata才会有梯度下降,就不会有gradient vanish的问题。
如何optimize?
weight clipping
你的weight是有range的,所以你input变化的时候,你的output变化总是有限的。如果你的K是一个够大的值,那你的neural network就会满足k-lipschitz function。


WGAN:用RMSprop好还是用adam效果好是不一定的。

(2)improve WGAN
gradient penalty
这里的gradient descent是input对output的descent(这里是input x 对 output D(x)的gradient descent),与从前是对neural network 的参数进行gradient descent不同。
。
什么是Ppenalty:
如何从Ppenalty中sample点:
先从Pdata中sample一个点,在从generator中sample一个点 ,再把这两个点连起来。在他们的连线中间再sample一个点,就是你得到的x。不断sample。。。
为什么这样的结果是好的呢:

其实你希望gradient越接近1越好。

(3)sentence generation
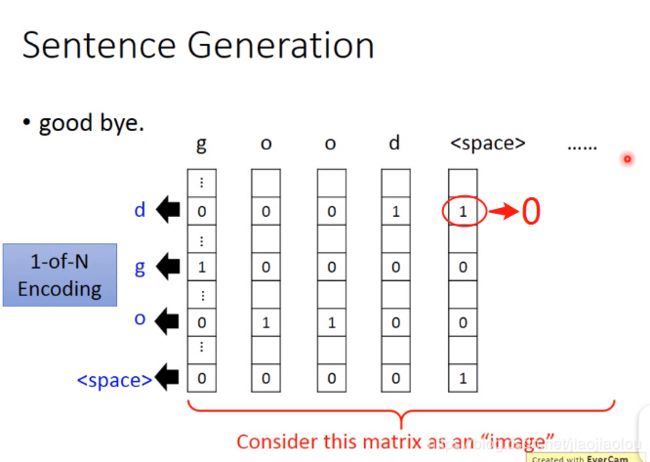
但是你用neural network产生一个matrix的时候,很难固定只有0和1。对于binary classifier来说,你的discriminator只要认为这个地方不是1或者不是0(没有重叠部分no overlap),就会认为是假的。WGAN就可以派上用场。

7、transform
1)sentence to image
conditional GAN中,如何train discriminator:
方法一:可以用WGAN来train 你的discriminator,input一个image,output distribution。结果:可能会得到清晰,但与输入内容无关的image。
方法二:input 的是两个东西,是generator的input和output。看他们两个合在一起好不好。比如你输入一个c为单词“train”,x为火车的image,output的值越大越好。negative example:①c为“train”,但x不为火车的image;②c不为“train”,但x为火车的image。他们output的值要越小越好。结果比较好。

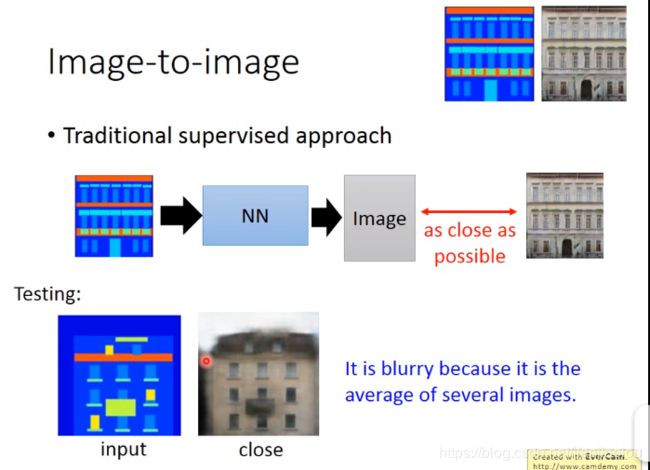
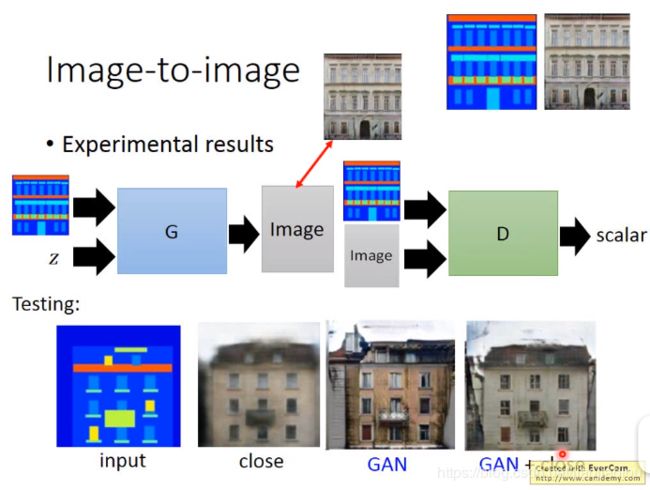
2)image to image
方法一:用传统的有监督的方法,train出来的图片可能是糊的。
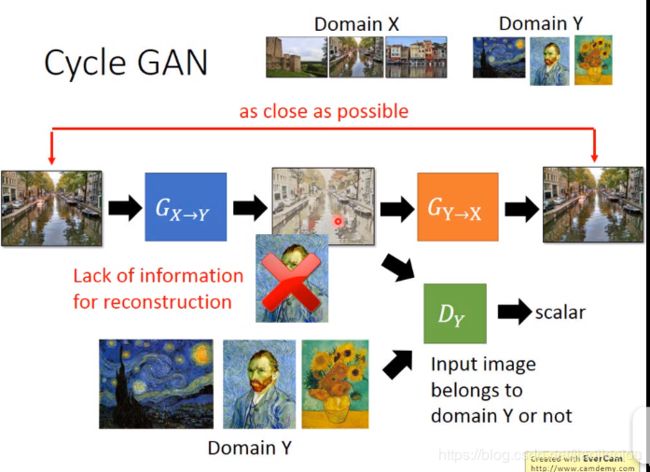
3)unpaired transformation --cycle GAN disco GAN
之前都是paired数据,比如说一段话及对应的image,一个简单的几何图及对应真实的image。。。这里用unpaired,有点类似风格迁移。把一幅一般的风景画转换为梵高式的image。
① cycle GAN
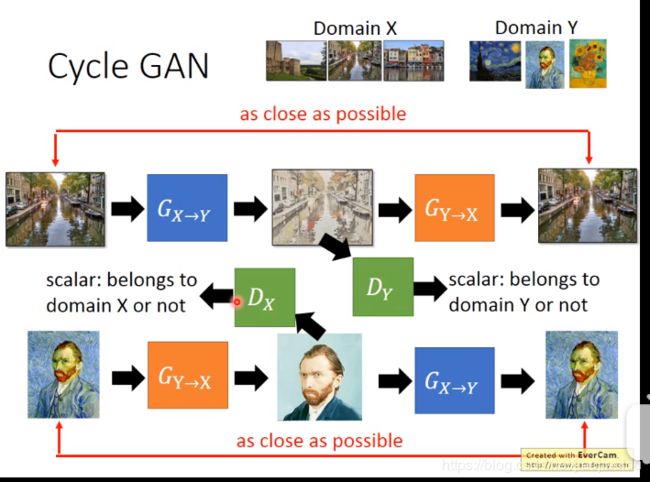
②真实的人物image转化为动漫
