YOLOv2实现分析与改进思考
目标检测算法实现细节
代码:https://github.com/experiencor/keras-yolo2
1 网络结构的构建
输入维度:
416*416(yolo v2为全卷积网络,可以接受任意尺寸的图像输入)
输出维度:
13*13*(5+80/20)
栅格数*anchor box个数*(5+类别数)
5中1个元素表示是目标的置信概率,4个元素为目标框的信息(x,y,w,h)
网络结构:
跑过的是yolov2-voc的模型,共23个卷积层,参照goolenet的设计结构,不过没有使用goolenet中的inception模块,而是简单的使用1*1卷积后面接3*3卷积的模式,简化网络
-
卷积滤波器模板:主要用到3*3卷积(same模式)和1*1卷积(主要用于压缩通道),1*1卷积也可以用于构建瓶颈层,降低计算成本(比如将28*28*192->28*28*32变为中间插入1*1 卷积,28*28*16)
-
池化模板:主要用到2*2的池化,用于缩小尺寸,共有5个池化层(1/2/5/8/13)
-
每层进行Batch Norm,规范化网络,学习速度更快,而且有正则化效果,无需在进行dropout
-
用leakyRelu的激活函数(相比relu解决了神经死亡问题,相比sigmoid和tanh函数,减轻了梯度消失问题)
优化方法
-
Adam梯度下降算法
训练样本
-
voc2007
-
训练集和测试集均为2500多张图片,6300多个目标,类别20(人、动物、交通工具、室内物体)
anchor box的作用思考
-
学习时有一定参考,可以更快收敛
-
让一个栅格可以检测多个目标
2 loss函数的构建
loss
-
四类loss,分别是object、noobject、class、coord。总体loss是四个部分的平方和
-
权重不同,对有目标的权重为5,其余为1
-
yolov2不直接预测位置信息,而是预测位置相对于anchor box的变换关系
下图分别为yolo_v1和yolo_v2的loss函数
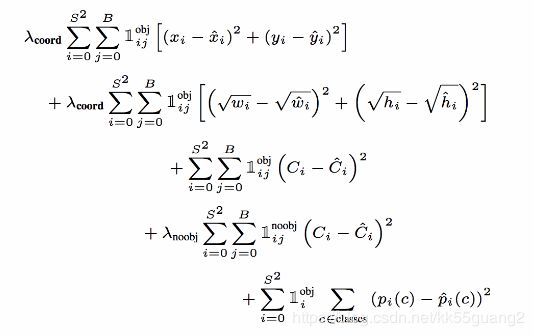

The above function defines the loss function for an iteration t. If a bounding box doesn’t have any object then its confidence of objectness need to be reduced and it is represented as first loss term. (作者实现时,此处的iou阈值为0.6)
As the bounding boxes coordinates prediction need to align with our prior information, a loss term reducing the difference between prior and the predicted is added for few iterations (t < 12800). (用于在早期迭代的时候让输出框贴近anchor box)
If a bounding box k is responsible for a truth box, then the predictions need to be aligned with the truth values which is represented as the third loss term.
The ? values are the pre-defined weightages for each of the loss terms.
参考:https://towardsdatascience.com/training-object-detection-yolov2-from-scratch-using-cyclic-learning-rates-b3364f7e4755
loss的思考:loss函数中置信概率的loss存在“真空”,
对于没有被分配目标而且最大iou大于0.6的box的loss是没有考虑的,因为不知道该让这种框往小的置信概率(0)走还是大的方向走(1)
输出维度(13,13,5,25),以batch为单位处理
y_pred
每个box输出为[tx, ty, tw, th, to, c1, c2..c20]
计算loss时,还需按如下公式进行调整,计算预测框的位置信息和置信概率:
![]()

-
原始输出tx、ty、tw、th、to没有约束,故需要用上面式子进行约束
-
原始输出为相对于anchor box的平移参数和放缩参数
-
网络对每个box输出5个参数tx、ty、tw、th、to用变换公式变换成实际的位置信息(以栅格长度为单位的目标框中心坐标以及长宽,与y_true对应)和置信概率
-
x,y需要计算相对于栅格左上角(cx,cy)的坐标偏移,用sigmoid函数让偏移量在0~1范围
-
置信概率 = sigmoid(t0),可以看成是两分类时的激活函数(分类为前景和背景)
y_true
分配真实框的位置信息和置信概率到某个anchor box检测器(真实框的中心落在的栅格中,与真实框交并比最大的anchor box)
(y_true[0~3]) x,y,w,h赋值为真实box的值
-
以栅格长度为单位的目标框中心坐标以及长宽
(y_true[4])置信概率处赋1(没目标的为0)
(y_true[5~24])对应的类别概率赋1(其他类别处已经初始化为0)
在计算loss时,还需要做如下调整:


-
实际的置信概率为预测框与真实框的iou值
-
实际的类别概率为1或0(目标的类别索引处为1)
coord_mask:
坐标mask指明了哪些box检测器中有目标,并考虑了loss的权重SCALE
![]()
loss_xy
loss_wh
![]()
conf_mask
目标mask(前景置信概率mask),为没有目标的box检测器的权重模板+有目标的权重模板

loss_conf
![]()
class_mask

loss_class
![]()
3 目标框的筛选
(1) yolo中目标框的筛选
每个栅格得到5个预测的box
低概率抑制
-
去掉(置0)置信概率较小的box(作者设置的是0.3)
非极大值抑制(时间复杂度O(n^2))
-
去掉与极大值框重叠较大的框
-
第一重循环:(类别数)
-
遍历类别,对每个类别分别进行非极大值抑制
-
-
对某个类别的box,按照置信概率降序排列
-
第二重循环:(box数,i=0~n-2)
-
从左到右遍历某一类中的所有box(选择的是置信概率较大的box)
-
为0的可以跳过(非极大值抑制中会把某些框置0)
-
-
第三重循环:(box数,j=i+1~n-1)
-
遍历其他box,计算iou,抑制掉(置0)与其iou比较大(作者的实现选的0.3)的box,在选择下一个较大的box进行相同的操作直至扫描完所有box
-
-
-
剩下的框会被画出,其判断类别属于box中类别概率最大的类别
注:这里的置信概率均指类别的预测概率(=实际的类别输出值*前景置信概率)
参考:非极大值抑制(Non-Maximum Suppression,NMS)
为什么要对每个类别分别进行NMS?
-
一般对同一个物体,网络会输出多个目标框(干扰框的主要来源,一个栅格中多个anchor box的输出)
-
而同一个物体类别是一样的,如果对每个类别分别进行NMS就能抑制掉这些干扰框
-
如果不分开的话,当不同类别的目标框有重叠时,可能会被抑制掉
NMS存在的问题:
-
当两个同类别的目标框本身重叠度较高时,NMS会把较低置信概率的抑制掉
(2) NMS的改进
上述NMS算法的一个主要问题是当两个目标(同类别)的确重叠度很高时,NMS会将具有较低置信度的框抑制掉(置信度改成0)
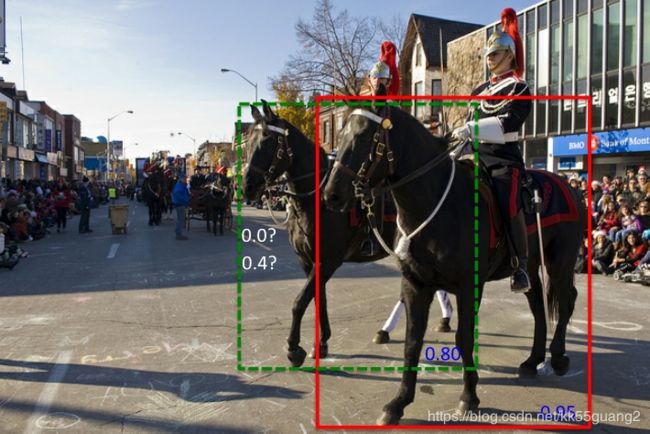
例子:
0.8抑制为0.4,最后再用一个低概率抑制(如0.3),这个框就能保留了
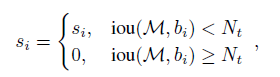 (原NMS)
(原NMS)
解决方法:soft NMS
思路:不要粗鲁地删除所有IOU大于阈值的框,而是降低其置信度。(iou越大,得分降低越大)
改进方法在于将置信度改为IoU的函数:f(IoU),具有较低的值而不至于从排序列表中删去.
1. 线性函数
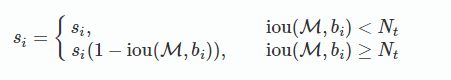
之前若iou>T,会将s置0
函数值不连续,在某一点的值发生跳跃.
2. 高斯函数
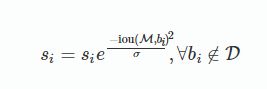
时间复杂度同传统的greedy-NMS,为O(N2)
思考:感觉这个方法还是无法完全解决两个同类别目标相距较近时的检出问题
论文: Improving Object Detection With One Line of Code
4 yolo可以改进的地方:
-
提升map
-
VOC数据集是90%左右,COCO数据集上是60%左右,还有提升的空间
-
可以考虑用上focal loss解决样本不均衡以及分类难度差异的问题
-
为什么预测类别概率与AP有关?可能网络的识别能力也影响了边界框的定位能力
-
-
同类靠得很近的目标检测
-
soft NMS用上
-
-
小目标
-
目标检测算法的分辨率评价指标
-
要有一个评价指标来看小目标的检测到底效果是怎么样的,定量去描述,而不是定性描述
-
-
目标检测算法能有可变的分辨率,提高灵活性和速度
-
对感兴趣区域用高分辨率检测,其他区域用低分辨检测,比如人眼在看物体时并不是所有地方都是一样清晰的,视线上的地方分辨率最高,辨别能力最强
-
比如在一副图像中有100人,要求算法既要能识别有多少人,又要看关注某个特定的人的特征,比如说想识别这个人衣服上写的是什么字,手上带的是什么,是手表还是手环还是手镯等等
-
-
尺度融合的定量解释,让多尺度检测可以实现选择尺度,定量可以检测到什么大小的目标。
-