用numpy进行数据分析练习
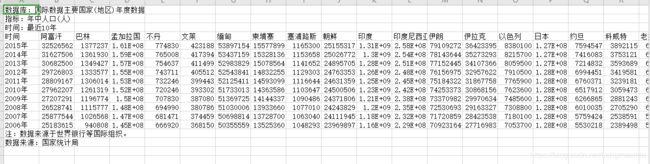
原始数据
from itertools import islice
import numpy as np
def read_file():
content=[]
# 跳过前面没用的3行数据
with open('G://国际数据主要国家(地区)年度数据.csv', 'r') as f:
# 跳过后面两行没用的数据
lines=len(f.readlines())-2
# 将文件指针指到开始位置
f.seek(0)
for line in islice(f, 3, lines):
content.append(line.split('\n')[0].split(','))
return content
def split_content(content):
year='2012年'
# 用来存放国家
country=[]
# 将列表变成矩阵
data=np.array(content)
# 获取索引
index=np.argwhere(data == year)[0][0]
# 获取2012年数据
data_2012 = data[index][:][1:]
# 将空白字符替换为零
data_2012=np.where(data_2012=='',0,data_2012)
# 将数据转换成整型
data_2012 = data_2012.astype(np.int64)
# 筛选2012年排名前十的人口数量
count = np.sort(data_2012)[::-1][:10].astype(np.str)
# 找到对应的国家
for it in count:
i= np.where(data==it)[1][0]
country.append(data[0][i])
return zip(country,count)
def for_each(data):
# 遍历
for item in data:
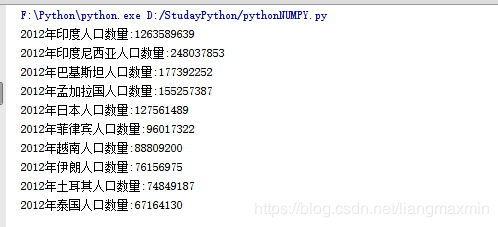
print("2012年{0}人口数量:{1}".format(item[0],item[1]))
if __name__ == '__main__':
data=split_content(read_file())
for_each(data)
from itertools import islice
import numpy as np
def read_file():
content = []
# 跳过前面没用的3行数据
with open('G://国际数据主要国家(地区)年度数据.csv', 'r') as f:
lines = len(f.readlines()) - 2
f.seek(0)
for line in islice(f, 3, lines):
content.append(line.split('\n')[0].split(','))
return content
def split_content(content):
sum=[]
avg=[]
years =['2011年','2012年','2013年']
countries = ['印度', '柬埔寨', '阿富汗']
data = np.array(content)
index1 = np.argwhere(data == years[0])[0][0]+1
index2 = np.argwhere(data == years[2])[0][0]
country1 = np.argwhere(data == countries[0])[0][1]
country2 = np.argwhere(data == countries[1])[0][1]
country3 = np.argwhere(data == countries[2])[0][1]
sum.append(data[index2:index1,country1].astype(np.int64).sum())
avg.append(data[index2:index1,country1].astype(np.int64).mean())
sum.append(data[index2:index1,country2].astype(np.int64).sum())
avg.append(data[index2:index1,country2].astype(np.int64).mean())
sum.append(data[index2:index1,country3].astype(np.int64).sum())
avg.append(data[index2:index1,country3].astype(np.int64).mean())
return zip(countries,sum,avg)
def for_each(data):
for item in data:
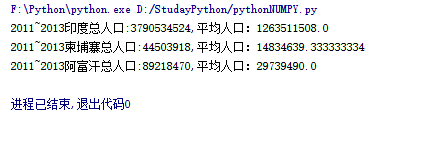
print("2011~2013{0}总人口:{1},平均人口:{2}".format(item[0],item[1],item[2]))
if __name__ == '__main__':
data = split_content(read_file())
for_each(data)
from itertools import islice
import numpy as np
def read_file():
content=[]
# 跳过前面没用的3行数据
with open('G://国际数据主要国家(地区)年度数据.csv', 'r') as f:
# 跳过后面两行没用的数据
lines=len(f.readlines())-2
# 将文件指针指到开始位置
f.seek(0)
for line in islice(f, 3, lines):
content.append(line.split('\n')[0].split(','))
return content
def split_content(content):
# 将列表矩阵化
data = np.array(content)
# 获取除第一行第一列以外的数据
ret_data = data[1:, 1:]
# 用零替代空白字符
ret_data = np.where(ret_data == '', 0, ret_data)
# 将字符型转化成整形
result = ret_data.astype(np.int64).mean(axis=0)
return zip(data[0, 1:], result)
# 遍历
def Average(data):
for item in data:
print(item[0], "历史平均人口为:", item[1])
if __name__ == '__main__':
data = split_content(read_file())
Average(data)

from itertools import islice
import numpy as np
def read_file():
content=[]
# 跳过前面没用的3行数据
with open('G://国际数据主要国家(地区)年度数据.csv', 'r') as f:
# 跳过后面两行没用的数据
lines=len(f.readlines())-2
# 将文件指针指到开始位置
f.seek(0)
for line in islice(f, 3, lines):
content.append(line.split('\n')[0].split(','))
return content
def split_content(content):
year='2012年'
# 将列表矩阵化
data=np.array(content)
# 获取索引的位置
index=np.argwhere(data == year)[0][0]
# 获取2012年数据
ret_data = data[index][:][1:]
# 将数据转成整形
ret_data=np.where(ret_data=='',0,ret_data)
# 获取平均值
avg = ret_data.astype(np.int64).mean()
# 求和
sum = ret_data.astype(np.int64).sum()
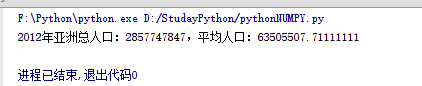
print('2012年亚洲总人口:{0},平均人口:{1}'.format(sum,avg))
if __name__ == '__main__':
data=split_content(read_file())