洞见 SELENIUM 自动化测试
洞见SELENIUM自动化测试
写在最前面:目前自动化测试并不属于新鲜的事物,或者说自动化测试的各种方法论已经层出不穷,但是,能够在项目中持之以恒的实践自动化测试的团队,却依旧不是非常多。有的团队知道怎么做,做的还不够好;有的团队还正在探索和摸索怎么做,甚至还有一些多方面的技术上和非技术上的旧系统需要重构……
本文将会从
使用和实践两个视角,尝试对基于Web UI自动化测试做细致的分析和解读,给各位去思考和实践做一点引路,以便各团队能找到更好的方式。
- 洞见SELENIUM自动化测试
- 使用测试工具
- 1 自动化测试理论介绍
- 2 自动化测试工具
- 21 Selenium 基本介绍
- 22 JetBrains PyCharm 使用
- 23 Selenium 的环境搭建
- 3 Selenium 的最简脚本
- 4 Selenium WebDriver API 的使用
- 41 控制浏览器
- 42 元素定位操作
- 依据ID查找
- 依据名称name查找
- 依据class name查找
- 依据标签名tag name查找
- 依据链接文字link查找
- 依据部分链接文字partial text查找
- 依据XPath进行查找
- 依据CSS选择器进行查找
- 特殊 iframe 操作
- 特殊 Select 操作
- 组合操作
- 43 鼠标事件操作
- 44 键盘事件操作
- 45 截图操作
- 5 unittest 单元测试框
- 6 为什么需要封装 Selenium
- 7 封装的概念与基本操作
- 8 Page-Object设计模式介绍
- 构建测试方案
- 1 数据驱动在自动化测试中的应用
- 2 测试方案的编码实现
- 3 测试报告的生成
- 4 具体案例分析
- 使用测试工具
- 自动化测试在路上
1. 使用测试工具
《论语》有云:工欲善其事,必先利其器。在开始具体的自动化测试之前,我们需要做好更多的准备,包括以下几个方面:
- 认识自动化测试
- 准备自动化测试工具
- 使用有效的方式
- 针对具体的测试对象
接下来的第一部分内容,我们将会从上述的几个方面进行探讨。
1.1 自动化测试理论介绍
自动化测试的
5W正如开篇所提到的,自动化测试不再是一个陌生的话题,而是一个具体的存在。作为测试实践活动的一部分,我们首先分析一下自动化测试的方方面面。
WHAT, 什么是自动化测试
G.J.Myers在其经典的著作《软件测试艺术》(The Art of Software Testing)一书中,给出了测试的定义:
“程序测试是为了发现错误而执行的过程。”
这个概念产生于30年前,对软件测试的认识还非常有局限性,当然也是因为受瀑布开发模型的影响,认为软件测试是编程之后的一个阶段。只有等待代码开发出来以后,通过执行程序,像用户那样操作软件去发现问题。
自动化测试:以人为驱动的测试行为转化为机器执行的一种过程
自动化测试,就是把手工进行的测试过程,转变成机器自动执行的测试过程。该过程,依旧是为了发现错误而执行。因此自动化测试的关键在于“自动化”三个字。自动化测试的内容,也就相应的转变成如何“自动化”去实现原本手工进行的测试的过程。
所有的“自动化”,依靠的无疑都是程序。
通过程序,可以把手工测试,转变成自动化测试。
WHEN, 在什么时候开展自动化测试
自动化测试的开展,依赖于“程序”。那么程序,其实就是由“源代码”构建而来的。那么原则上,只要能做出自动化测试所需要的“程序”的时候,变可以进行自动化测试。但往往,并不是所有的“时候”都是好的“时机”。从这个
W开始,我们将会加入对于成本的顾虑,也正是因为“成本”的存在,才使得下面的讨论,变得有意义。所有的开销,都是有成本的。构建成“程序”的源代码,也是由工程师写出来的。那么需要考虑这个过程中的成本。基于这个考虑,在能够比较稳定的构建“程序”的时候,不需要花费太多开销在“源代码”的时候,就是开展自动化测试的好时机。这个开销包括
编写和修改源代码,而源代码指的是构建出用来做自动化测试的程序的源代码。WHERE, 在什么地方进行自动化测试
自动化测试的执行,依靠的是机器。那么自动化测试必将在“机器”上进行。一般来说,这个机器包括桌面电脑和服务器。通过将写好的
源代码部署在机器上,构建出用来做自动化测试的”程序”,并且运行该程序,实现自动化测试。WHICH, 对什么目标进行自动化测试
自动化测试的目标,是被测试的软件。抛开人工智能的成分,手工测试必将在“人工智能”足够普及和足够“智能”之前,替代一大部分不需要“人类智能”的手工测试;以及自动化测试会做一些手工测试无法实施的,或者手工测试无法覆盖的测试。
- 不需要“人类智能”的普通手工测试
- 界面的普通操作
- 通过固定输入和固定操作而进行的流程化测试
- 重复的普通测试
手工测试无法实施或者覆盖的
- 大量的数据的输入
- 大量的步骤的操作
- 源代码基本的测试
- 系统模块间接口的调用测试
- ……
HOW, 如何开展自动化测试
和所有的其他测试一样,自动化测试的流程也是由“用例”执行和“缺陷”验证组成。差别是需要找到合适的“工具”来替代“人手”。不同目标的自动化测试有不同的测试工具,但是任何工具都无不例外的需要“编程”的过程,实现“源代码”,也可以称之为测试脚本。于是开展自动化测试的方式基本上如下:
- 准备测试用例
- 找到合适的自动化测试工具
- 用准确的编程形成测试脚本
- 在测试脚本中对目标进行“检查”,即做断言
- 记录测试日志,生成测试结果
自动化测试的典型金字塔原理
谈到自动化测试,就不得不提的一个人和概念就是:Martin Fowler和他的金字塔原理。首先请看金字塔原理的图示如下:

该图说明了三个问题:
- 自动化测试包括三个方面:UI前端界面,Service服务契约和Unit底层单元
- 越是底层的测试,运行速度越快,时间开销越少,金钱开销越少
- 越是顶层的测试,运行速度越慢,时间开销越多,金钱开销越多
这是理想中的金字塔原理。
在实际的项目中,尤其是结合国内的项目实践,其实还隐藏了另一个问题:越是顶层的测试,效果越明显。有句话说“贵的东西,除了贵,其他都是好的!”能够很清晰的阐述这个观点。
金字塔原理在国内的适应性也有一定的问题
- 自动化测试的起步不是特别早
- 甚至软件测试很长一段时间都在进行基于业务的手工测试,测试人员的代码能力相对较弱
- 开发人员在代码中不太习惯写单元测试
- 近些年基于服务契约的API测试也在兴起
相对来说,在基于UI前端界面的自动化测试反倒是开展和实施的不是特别多。尽管基于界面的测试带来的效果还是能够立竿见影的。对于产品的质量提升,还是比较容易有保证。
自动化测试的适用范围
自动化测试可以涉及和试用的范围主要在以下方面:
- 基于
Web UI的浏览器应用的界面测试 - 基于
WebService或者WebAPI的服务契约测试 - 基于
WCF、.net remoting、Spring等框架的服务的集成测试 - 基于
APP UI的移动应用界面测试 - 基于
Java、C#等编程文件进行的单元测试
本文集中讨论第一条:基于
Web UI的浏览器应用的界面测试。界面的改动对于测试来说,具有较大的成本风险。主要考虑以下方面:- 任务测试明确,不会频繁变动
- 每日构建后的测试验证
- 比较频繁的回归测试
- 软件系统界面稳定,变动少
- 需要在多平台上运行的相同测试案例、组合遍历型的测试、大量的重复任务
- 软件维护周期长
- 项目进度压力不太大
- 被测软件系统开发比较规范,能够保证系统的可测试性
- 具备大量的自动化测试平台
- 测试人员具备较强的编程能力
- 基于
自动化测试的流程
自动化测试和普通的手工测试遵循的测试流程,与项目的具体实践相关。一般来说,也是需要从测试计划开始涉及自动化测试的。
- 测试计划:划定自动化测试的范围包含哪些需求,涉及到哪些测试过程
- 测试策略:确定自动化测试的工具、编程方案、代码管理、测试重点
- 测试设计:使用测试设计方法对被测试的需求进行设计,得出测试的测试点、用例思维导图等
- 测试实施:根据测试设计进行用例编写,并且将测试用例用编程的方式实现测试脚本
- 测试执行:执行测试用例,运行测试脚本,生成测试结果
1.2 自动化测试工具
基于Web UI的自动化测试工具主要有两大类:付费的商业版工具和免费使用的开源版工具。典型的有两种:
- UFT,QTP被惠普收购以后的新名称。
- 通过程序的录制,可以实现测试的编辑
- 录制的测试脚本是 VBScript 语法
- 成熟版的商业付费工具
- 工具比较庞大,对具体的项目定制测试有难度
- SELENIUM,本次选择的开源工具
- 本身不是测试工具,只是模拟浏览器操作的工具
- 背后有 Google 维护源代码
- 支持全部主流的浏览器
- 支持主流的编程语言,包括:Java、Python、C#、PHP、Ruby、JavaScript等
- 工具很小,可以实现对测试项目的定制测试方案
- 基于标准的 WebDriver 语法规范
1.2.1 Selenium 基本介绍
Selenium`是开源的自动化测试工具,它主要是用于Web 应用程序的自动化测试,不只局限于此,同时支持所有基于web 的管理任务自动化。
Selenium官网的介绍Selenium is a suite of tools to automate web browsers across many platforms.
- runs in many browsers and operating systems
- can be controlled by many programming languages and testing frameworks.
- Selenium 官网:http://seleniumhq.org/
- Selenium Github 主页:https://github.com/SeleniumHQ/selenium
Selenium 是用于测试 Web 应用程序用户界面 (UI) 的常用框架。它是一款用于运行端到端功能测试的超强工具。您可以使用多个编程语言编写测试,并且 Selenium 能够在一个或多个浏览器中执行这些测试。
Selenium 经历了三个版本:Selenium 1,Selenium 2 和 Selenium 3。Selenium 也不是简单一个工具,而是由几个工具组成,每个工具都有其特点和应用场景。
Selenium 诞生于 2004 年,当在
ThoughtWorks工作的 Jason Huggins 在测试一个内部应用时。作为一个聪明的家伙,他意识到相对于每次改动都需要手工进行测试,他的时间应该用得更有价值。他开发了一个可以驱动页面进行交互的 Javascript 库,能让多浏览器自动返回测试结果。那个库最终变成了 Selenium 的核心,它是 Selenium RC(远程控制)和 Selenium IDE 所有功能的基础。Selenium RC 是开拓性的,因为没有其他产品能让你使用自己喜欢的语言来控制浏览器。这就是 Selenium 1。然而,由于它使用了基于 Javascript 的自动化引擎,而浏览器对 Javascript 又有很多安全限制,有些事情就难以实现。更糟糕的是,网站应用正变得越来越强大,它们使用了新浏览器提供的各种特性,都使得这些限制让人痛苦不堪。
在 2006 年,一名 Google 的工程师, Simon Stewart 开始基于这个项目进行开发,这个项目被命名为 WebDriver。此时,Google 早已是 Selenium 的重度用户,但是测试工程师们不得不绕过它的限制进行工具。Simon 需要一款能通过浏览器和操作系统的本地方法直接和浏览器进行通话的测试工具,来解决Javascript 环境沙箱的问题。WebDriver 项目的目标就是要解决 Selenium 的痛点。
到了 2008 年,Selenium 和 WebDriver 两个项目合并。Selenium 有着丰富的社区和商业支持,但 WebDriver 显然代表着未来的趋势。两者的合并为所有用户提供了一组通用功能,并且借鉴了一些测试自动化领域最闪光的思想。这就是 Selenium 2。
2016 年,Selenium 3 诞生。移除了不再使用的 Selenium 1 中的 Selenium RC,并且官方重写了所有的浏览器驱动。
Selenium 工具集
- Selenium IDE
Selenium IDE (集成开发环境) 是一个创建测试脚本的原型工具。它是一个 Firefox 插件,实现简单的浏览器操作的录制与回放功能,提供创建自动化测试的建议接口。Selenium IDE 有一个记录功能,能记录用户的操作,并且能选择多种语言把它们导出到一个可重用的脚本中用于后续执行。
- Selenium RC
Selenium RC 是selenium 家族的核心工具,Selenium RC 支持多种不同的语言编写自动化测试脚本,通过selenium RC 的服务器作为代理服务器去访问应用从而达到测试的目的。
selenium RC 使用分Client Libraries 和Selenium Server。
- Client Libraries 库主要主要用于编写测试脚本,用来控制selenium Server 的库。
Selenium Server 负责控制浏览器行为,总的来说,Selenium Server 主要包括3 个部分:Launcher、Http Proxy、Core。
Selenium Grid
Selenium Grid 使得 Selenium RC 解决方案能提升针对大型的测试套件或者哪些需要运行在多环境的测试套件的处理能力。Selenium Grid 能让你并行的运行你的测试,也就是说,不同的测试可以同时跑在不同的远程机器上。这样做有两个有事,首先,如果你有一个大型的测试套件,或者一个跑的很慢的测试套件,你可以使用 Selenium Grid 将你的测试套件划分成几份同时在几个不同的机器上运行,这样能显著的提升它的性能。同时,如果你必须在多环境中运行你的测试套件,你可以获得多个远程机器的支持,它们将同时运行你的测试套件。在每种情况下,Selenium Grid 都能通过并行处理显著地缩短你的测试套件的处理时间。
- Selenium WebDriver
WebDriver 是 Selenium 2 主推的工具,事实上WebDriver是Selenium RC的替代品,因为Selenium需要保留向下兼容性的原因,在 Selenium 2 中, Selenium RC才没有被彻底的抛弃,如果使用Selenium开发一个新的自动化测试项目,那么我们强烈推荐使用Selenium2 的 WebDriver进行编码。另外, 在Selenium 3 中,Selenium RC 被移除了。
Python 语言的选择,便捷
- 测试人员的编程能力普遍不是很强,而Python作为一种脚本语言,不仅功能强大,而且语法优美,支持多种自动化测试工具,而且学习上手比较容易。
- Python的社区发展比较好,有着非常多的文档和支持库,另外Python也可以在Web开发、数据处理、科学计算等纵多领域有着非常好的应用前景。
- 对于有一定编程基础的人员,使用Python作为自动化测试的语言可以非常顺畅的转换,几乎没有学习成本。同时Python是标准的面向对象的编程语言,对于C#、Java等面向对象的语言有着非常好的示例作用,通过Python的示例可以非常轻松的触类旁通,使用其他语言进行Selenium2.0的WebDriver的使用。
- 读音:
/'paɪθən/ - Python的创始人为Guido Van Rossum。1989年圣诞节期间,在阿姆斯特丹,Guido为了打发圣诞节的无趣,决心开发一个新的脚本解释程序,做为ABC 语言的一种继承。之所以选中Python(大蟒蛇的意思)作为程序的名字,是因为他是一个叫Monty Python的喜剧团体的爱好者。
- Python 语言除了在自动化测试领域有出色的表现外,在系统编程,网络编程,web 开发,GUI开发,科学计算,游戏开发等多个领域应用非常广泛,而且具有非常良好的社区支持。也就是说学习和掌握python 编程,其实是为你打开了一道更广阔的大门。
使用的工具集
- IDE: Jetbrains PyCharm
- 语言: Python
- 工具: Selenium WebDriver
- 源代码管理: SVN/Git
1.2.2 JetBrains PyCharm 使用
JetBrains PyCharm 的介绍
PyCharm 是 JetBrains 公司针对Python推出的IDE(Integrated Development Environment,集成开发环境)。是目前最好的Python IDE之一。目前包含了两个版本:
- 社区版,Community Edition
- 专业版,Professional Edition
- 付费
- 比社区版主要多了Web开发框架
我们推荐使用免费的社区版本,进行Python脚本的编写和自动化测试执行。
PyCharm可以在官网下载,http://www.jetbrains.com
PyCharm 安装后,如果也安装过 Python 环境,可以直接进行操作。否则请在 1.2.3 中安装好 Python,再使用 PyCharm。
安装按照默认的步骤安装
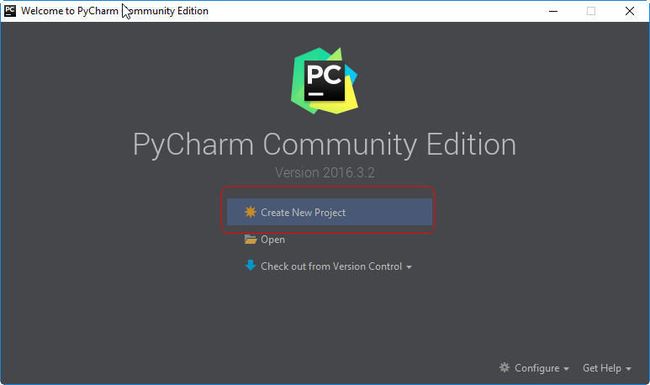
使用方式
- Create New Project:
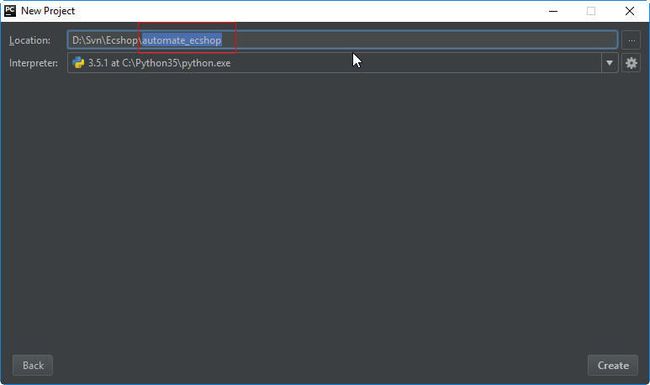
创建新的项目,选择项目创建的位置,选择Python的解释器

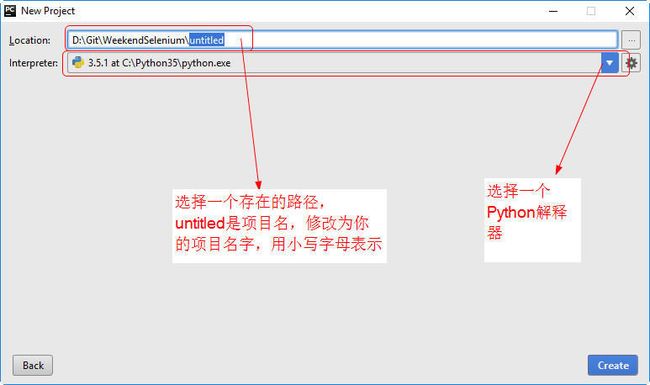
- 设置location,项目的路径和名称
- 名称必须以英文字母开头
- 名称不可以有空格
- 位置不可以在
C:\Pytho34中,应该放到普通的目录中
- 设置interpreter
- 一个电脑可以装多个 Python
- 这里选择一个你需要的 Pythpn
新建Python文件

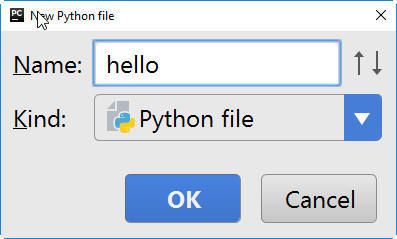
在创建的文件中编写第一个Python语句
print("hello Python!")
右键该文件,选择
Run hello,运行该语句,在下面的运行框中会显示运行结果C:\Python35\python.exe D:/Git/WeekendSelenium/untitled/hello.py hello python! Process finished with exit code 0如图

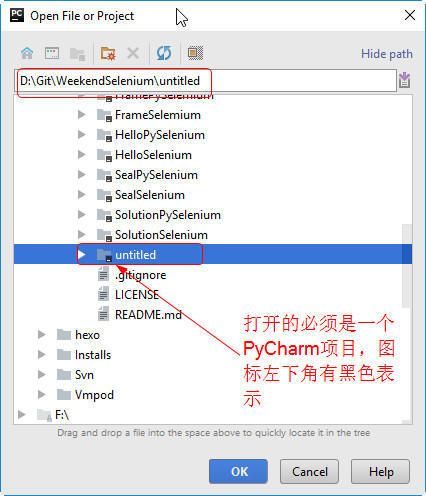
- Open
打开已经存在的项目,比如别人发给你的项目,或者已经创建过的项目

安装后进行设置如下:
设置行号的显示
在PyCharm 里,显示行号有两种办法:
临时设置(不推荐)。右键单击行号处,选择
Show Line Numbers。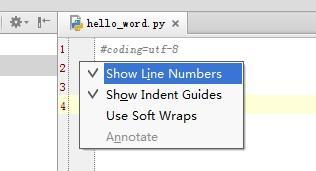
但是这种方法,只对一个文件有效,并且,重启PyCharm 后消失。
永久设置。
File–>Settings–>Editor–>Appearance, 之后勾选Show Line Numbers。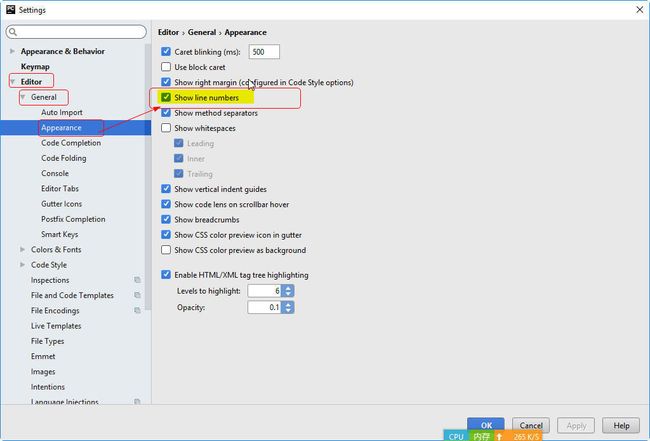
设置字体
选择 Settings | Editor | Colors & Fonts | Fonts
Save AS 主题
选择 Source Code Pro(建议选择,等宽字体)
SVN / Git 在工具中的集成
源代码管理工具(VCS, version control system)
如果TortoiseSVN版本低于
1.8,需要先升级安装1.8以上的版本选择SVN(git)作为代码的源代码管理工具。集成在PyCharm中的步骤如下
代码已经存在在SVN repo中:把代码放到SVN在本地签出(check out)的文件夹目录中,例如
D:\SVN\XXProject\Trunck
代码没有创建:在本地的SVN项目文件夹中新建项目,用PyCharm打开,提交。

用PyCharm打开 刚刚部署的代码
选择PyCharm的
VCS|Enable VCS integration,选择 Subversion(svn) 或者 Git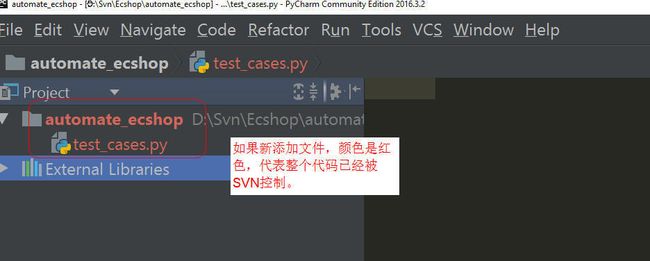
右键项目文件的根目录,选择 Subversion | add to VCS
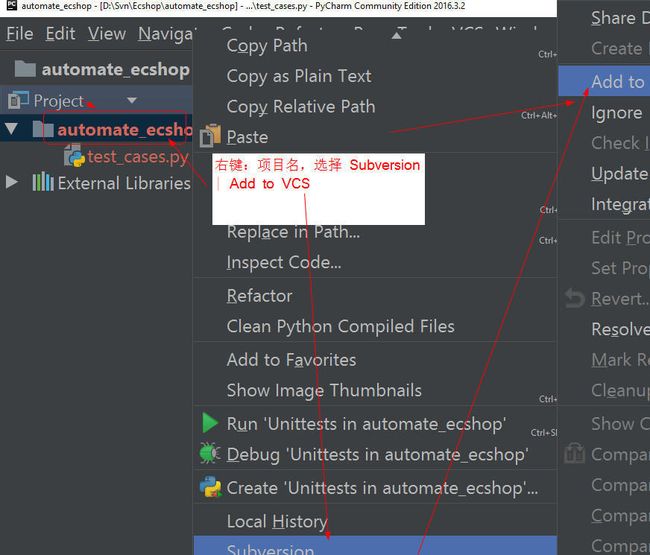
右键项目文件的根目录,或者选 VCS | Commit Directory…
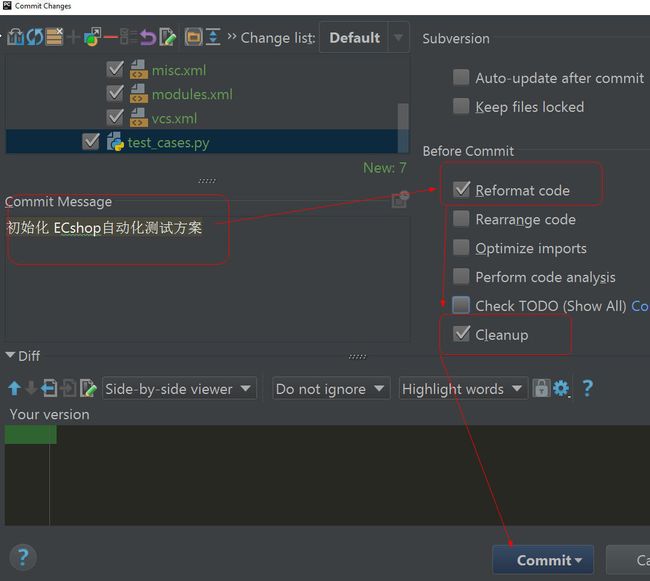

每天打开代码后,右键项目文件的根目录,首先 Subversion | update project
如果有冲突,先本地手工保存你做的修改(备份你的文件到其他地方,SVN目录之外的地方,然后Revert)
1.2.3 Selenium 的环境搭建
在 Windows 搭建和部署 Selenium 工具
主要包括两个步骤:
- 安装 Python 语言
Python的官方网站:http://www.python.org
Python 目前并行了两套版本,2.x 和 3.x。如果你之前没有 Python 的使用经验,建议使用 Python 3.x 版本。两套版本互相不兼容,并且 Python 从 3.5(含)开始,不再支持 Windows XP 系统,请注意。
选择安装目录
- 3.4或者3.4以下的版本,都是
C:\python34 - 3.5以上的目录,默认装个人文件夹,建议用类似上面的目录,比如
C:\python35
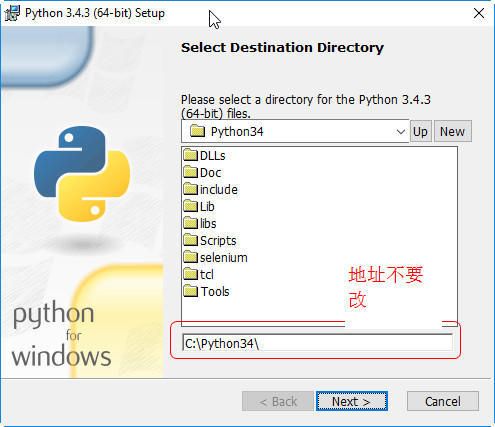
- 3.4或者3.4以下的版本,都是
勾选添加环境变量
勾选
Add Python.exe to PATH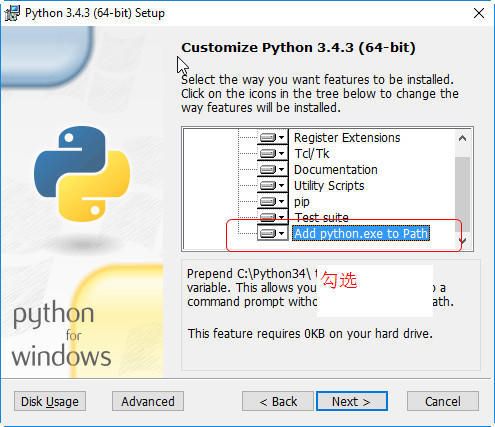
安装过程中不要关闭弹出来的命令行窗口
关于 Python 的安装,也可以选择一些第三方的Python 安装包,典型的有
Anaconda3,这样的包有丰富的第三方库,在使用 Python 的过程中会更加方便。Anaconda 的官网:https://www.continuum.io/anaconda-overview
安装 Selenium 工具包
由于 安装好的 Python 默认有
pipPython 包管理工具,可以通过pip非常方便的安装 Selenium。启动命令行工具:Win+R | 输入 cmd | 回车
输入命令:
pip install selenium该命令的执行需要有互联网联网环境。此外该命令有以下几种选项可以使用
- 安装指定的版本,例如安装指定的 Selenium 3.4.3
pip install selenium==3.4.3
- 安装最新版的 Selenium
pip install -U selenium # -U 也可以用 --upgrade pip install --upgrade selenium
- 卸载安装当前的 Selenium
pip uninstall selenium当然,如果您的机器处于非接入互联网的环境,您可以事先下载 Selenium 的 Python 安装包,再进行手动安装。
官方下载地址:https://pypi.python.org/pypi/selenium
上述地址会下载最新版的 Selenium,目前最先版的是 3.4.3,您也可以根据以下路径下载指定的 3.4.3
Selenium 3.4.3 下载地址:https://pypi.python.org/pypi/selenium/3.4.3#downloads
下载后,解压该压缩包
然后用命令行进入该压缩包的根目录,输入命令进行安装
python setup.py install
配置 浏览器 和 驱动
Selenium 2 可以默认支持Firefox 46.0或者更低版本,对于其他浏览器需要额外安装驱动。
Selenium 3 对于所有的浏览器都需要安装驱动,本文以 Chrome 和 Firefox、IE为例设置浏览器和驱动。
ChromeDriver下载地址:http://chromedriver.storage.googleapis.com/index.html
ChromeDriver 与 Chrome 对应关系表:
ChromeDriver版本 支持的Chrome版本 v2.31 v58-60 v2.30 v58-60 v2.29 v56-58 v2.28 v55-57 v2.27 v54-56 v2.26 v53-55 v2.25 v53-55 v2.24 v52-54 v2.23 v51-53 v2.22 v49-52 v2.21 v46-50 v2.20 v43-48 GeckoDriver下载地址:https://github.com/mozilla/geckodriver/releases
GeckoDriver 与 Firefox 的对应关系表:
GeckoDriver版本 支持的Firefox版本 v0.18.0 v56 v0.17.0 v55 v0.16.0 v54,需要Selenium 3.4或者以上 v0.15.0 v53,需要Selenium 3.3或者以上 IEDriverServer下载地址:http://selenium-release.storage.googleapis.com/index.html
IEDriverServer 的版本需要与 Selenium 保持严格一致。
浏览器驱动的配置
首先,将下载好的对应版本的浏览器安装。
- 其次,在 Python 的根目录中,放入浏览器驱动。
- 最好再重启电脑,一般情况下不重启也可以的。
1.3 Selenium 的最简脚本
通过上一节的环境安装成功以后,我们可以进行第一个对Selenium 的使用,就是最简脚本编写。脚本如下:
# 声明一个司机,司机是个Chrome类的对象
driver = webdriver.Chrome()
# 让司机加载一个网页
driver.get("http://demo.ranzhi.org")
# 给司机3秒钟去打开
sleep(3)
# 开始登录
# 1. 让司机找用户名的输入框
we_account = driver.find_element_by_css_selector('#account')
we_account.clear()
we_account.send_keys("demo")
# 2. 让司机找密码的输入框
we_password = driver.find_element_by_css_selector('#password')
we_password.clear()
we_password.send_keys("demo")
# 3. 让司机找 登录按钮 并 单击
driver.find_element_by_css_selector('#submit').click()
sleep(3)实际上一段20行的代码,也不能算太少了。但是这段代码的使用,确实体现了 Selenium 的最简单的使用。我们在下面内容进行阐述。
关于面向对象编程
通过前面的介绍,我们知道 Selenium 支持多种语言,并且推荐使用面向对象的方式进行编程。接下来我们将着重介绍如何使用面向对象的方式进行编程。
我们利用 Python 进行面向对象编程,需要首先了解一个概念:类
- 类
类是任何面向对象编程的语言的基本组成,描述了使用的基本方法。我们可能在目前,还不是特别明白类的含义,但是我们可以通过类的使用,来进一步了解。
- 类的使用
类,通过实例化进行使用。比如有一个类:
Driver,该类有一个方法:head(road)那么关于这个类的使用,只需要两个步骤:
- 实例化该类:
d = Driver() 调用类的方法:
d.head("中山路")- 了解上述例子和使用以后,我们来看具体的 Selenium 的使用。
具体的对象的使用
在面向对象的理念看来,任何的编码,都是由对象而来的,这里也不例外。和之前介绍 WebDriver 时候的描述对应,我们需要用到两种主要的类,并将其实例化。
- WebDriver 类:主要靠直接实例化该类为对象,然后用其对象直接调用该类的方法和属性
- WebElement 类:主要通过 WebDriver 类实例化的对象,通过对页面元素的查找,得到 WebElement 类的对象,然后调用该类的方法和属性。
上述代码中,使用了一个 WebDriver 类 的对象,即第2行,声明了该类的对象,并赋值给变量 driver,接着变量 driver 作为 WebDriver 类的对象,使用了多个 WebDriver 类的方法。
注意:Chrome 是 WebDriver 的子类,是 WebDriver 类的一种
- get(url): 第5行,打开网址
- find_element_by_css_selector(selector): 第12、17、22行都使用了该方法,同时通过对该方法的调用,分别各产生了一个 WebElement类的对象,
we_account,we_password和最后一个匿名的对象,并通过产生的三个对象,调用 WebElement 类的方法 - clear():清理页面元素中的文字
- send_keys(text):给页面元素中,输入新的文字
- click():鼠标左键点击页面元素
正是通过这样的面向对象的方式,产生 Web司机(WebDriver类的对象),并且通过 Web司机不懈的努力,寻找到各种 Web元素(WebElement类的对象)进行操作,这样便实现了 Selenium WebDriver 作为一款出色的浏览器测试工具,进行浏览器UI界面的自动化测试的代码编写和用例执行。
1.4 Selenium WebDriver API 的使用
通过上述最简脚本的使用,我们可以来进一步了解 Selenium 的使用。事实上,上一节用的,便是 Selenium 的 WebDriver API。API(Application Programming Interface,应用程序编程接口,即通过编程语言,操作 WebDriver 的方法集合)
Selenium WebDriver API 官方参考:http://seleniumhq.github.io/selenium/docs/api/py/
具体API文档地址:https://seleniumhq.github.io/selenium/docs/api/py/api.html
- API 使用: 用现成的类(大部分情况)的方法进行编程
- WebDriver
- WebElement
- API 文档
- 编程使用说明
- 介绍了每个方法的使用
- 方法的作用
- 方法的参数
- 方法的返回值
1.4.1 控制浏览器
浏览器的控制也是自动化测试的一个基本组成部分,我们可以将浏览器最大化,设置浏览器的高度和宽度以及对浏览器进行导航操作等。
# 浏览器打开网址
driver.get("https://www.baidu.com")
# 浏览器最大化
driver.maximize_window()
# 设置浏览器的高度为800像素,宽度为480像素
driver.set_window_size(480, 800)
# 浏览器后退
driver.back()
# 浏览器前进
driver.forward()
# 浏览器关闭
driver.close()
# 浏览器退出
driver.quit()1.4.2 元素定位操作
WebDriver提供了一系列的定位符以便使用元素定位方法。常见的定位符有以下几种:
- id
- name
- class name
- tag
- link text
- partial link text
- xpath
- css selector
那么我们以下的操作将会基于上述的定位符进行定位操作。
对于元素的定位,WebDriver API可以通过定位简单的元素和一组元素来操作。在这里,我们需要告诉Selenium如何去找元素,以至于他可以充分的模拟用户行为,或者通过查看元素的属性和状态,以便我们执行一系列的检查。
在Selenium2中,WebDriver提供了多种多样的find_element_by方法在一个网页里面查找元素。这些方法通过提供过滤标准来定位元素。当然WebDriver也提供了同样多种多样的find_elements_by的方式去定位多个元素。
尽管上述的方式,可以进行元素定位,实际上我们也是更多的用组合的方式进行元素定位。
| 方法Method | 描述Description | 参数Argument | 示例Example |
|---|---|---|---|
id |
该方法通过ID的属性值去定位查找单个元素 | id: 需要被查找的元素的ID | find_element_by_id('search') |
name |
该方法通过name的属性值去定位查找单个元素 | name: 需要被查找的元素的名称 | find_element_by_name('q') |
class name |
该方法通过class的名称值去定位查找单个元素 | class_name: 需要被查找的元素的类名 | find_element_by_class_name('input-text') |
tag_name |
该方法通过tag的名称值去定位查找单个元素 | tag: 需要被查找的元素的标签名称 | find_element_by_tag_name('input') |
link_text |
该方法通过链接文字去定位查找单个元素 | link_text: 需要被查找的元素的链接文字 | find_element_by_link_text('Log In') |
partial_link_text |
该方法通过部分链接文字去定位查找单个元素 | link_text: 需要被查找的元素的部分链接文字 | find_element_by_partial_link_text('Long') |
xpath |
该方法通过XPath的值去定位查找单个元素 | xpath: 需要被查找的元素的xpath | find_element_by_xpath('//*[@id="xx"]/a') |
css_selector |
该方法通过CSS选择器去定位查找单个元素 | css_selector: 需要被查找的元素的ID | find_element_by_css_selector('#search') |
接下来的列表将会详细展示find_elements_by的方法集合。这些方法依据匹配的具体标准返回一系列的元素。
| 方法Method | 描述Description | 参数Argument | 示例Example |
|---|---|---|---|
id |
该方法通过ID的属性值去定位查找多个元素 | id: 需要被查找的元素的ID | find_elements_by_id('search') |
name |
该方法通过name的属性值去定位查找多个元素 | name: 需要被查找的元素的名称 | find_elements_by_name('q') |
class_name |
该方法通过class的名称值去定位查找多个元素 | class_name: 需要被查找的元素的类名 | find_elements_by_class_name('input-text') |
tag_name |
该方法通过tag的名称值去定位查找多个元素 | tag: 需要被查找的元素的标签名称 | find_elements_by_tag_name('input') |
link_text |
该方法通过链接文字去定位查找多个元素 | link_text: 需要被查找的元素的链接文字 | find_elements_by_link_text('Log In') |
partial_link_text |
该方法通过部分链接文字去定位查找多个元素 | link_text: 需要被查找的元素的部分链接文字 | find_elements_by_partial_link_text('Long') |
xpath |
该方法通过XPath的值去定位查找多个元素 | xpath: 需要被查找的元素的xpath | find_elements_by_xpath("//div[contains(@class,'list')]") |
css_selector |
该方法通过CSS选择器去定位查找多个元素 | css_selector: 需要被查找的元素的ID | find_element_by_css_selector('.input_class') |
依据ID查找
请查看如下HTML的代码,以便实现通过ID的属性值去定义一个查找文本框的查找:
<input id="search" type="text" name="q" value=""
class="input-text" maxlength="128" autocomplete="off"/>根据上述代码,这里我们使用find_element_by_id()的方法去查找搜索框并且检查它的最大长度maxlength属性。我们通过传递ID的属性值作为参数去查找,参考如下的代码示例:
def test_search_text_field_max_length(self):
# get the search textbox
search_field = self.driver.find_element_by_id("search")
# check maxlength attribute is set to 128
self.assertEqual("128", search_field.get_attribute("maxlength"))如果使用find_elements_by_id()方法,将会返回所有的具有相同ID属性值的一系列元素。
依据名称name查找
这里还是根据上述ID查找的HTML代码,使用find_element_by_name的方法进行查找。参考如下的代码示例:
# get the search textbox
self.search_field = self.driver.find_element_by_name("q")同样,如果使用find_elements_by_name()方法,将会返回所有的具有相同name属性值的一系列元素。
依据class name查找
除了上述的ID和name的方式查找,我们还可以使用class name的方式进行查找和定位。
事实上,通过ID,name或者类名class name查找元素是最提倡推荐的和最快的方式。当然Selenium2 WebDriver也提供了一些其他的方式,在上述三类方式条件不足,查找无效的时候,可以通过这些其他方式来查找。这些方式将会在后续的内容中讲述。
请查看如下的HTML代码,通过改代码进行练习和理解.
<button type="submit" title="Search" class="button">
<span><span>Searchspan>span>
button>根据上述代码,使用find_element_by_class_name()方法去定位元素。
def test_search_button_enabled(self):
# get Search button
search_button = self.driver.find_element_by_class_name("button")
# check Search button is enabled
self.assertTrue(search_button.is_enabled())同样的如果使用find_elements_by_class_name()方法去定位元素,将会返回所有的具有相同name属性值的一系列元素。
依据标签名tag name查找
利用标签的方法类似于利用类名等方法进行查找。我们可以轻松的查找出一系列的具有相同标签名的元素。例如我们可以通过查找表中的 下面有一个HTML的示例,这里在无序列表中使用了 这里面我们使用 具体代码如下: 链接文字查找通常比较简单。使用 测试代码如下: 这里依旧使用上述的列子进行代码编写: XPath是一种在XML文档中搜索和定位节点node的一种查询语言。所有的主流Web浏览器都支持XPath。Selenium2可以用强大的XPath在页面中查找元素。 常用的XPath的方法有 若想要了解更多关于XPath的内容,请查看http://www.w3schools.com/XPath/ 如下有一段HTML代码,其中里面的 具体代码如下: 当然,如果使用 CSS是一种设计师用来描绘HTML文档的视觉的层叠样式表。一般来说CSS用来定位多种多样的风格,同时可以用来是同样的标签使用同样的风格等。类似于XPath,Selenium2也可以使用CSS选择器来定位元素。 请查看如下的HTML文档。 我们来创建一个测试,验证这些消息是否正确。 iframe 元素会创建包含另外一个文档的内联框架(即行内框架)。 iframe: 紫禁城 在一个中,包含了另一个 示例 需要定位上面示例中的 如下是selenium WebDiriver的代码 Select 是个selenium的类 Select 类的路径: 示例,选择 Audi 自动化经验的积累,需要100%按照手工的步骤进行操作。 比如步骤如下: 代码示例 Web测试中,有关鼠标的操作,不只是单击,有时候还要做右击、双击、拖动等操作。这些操作包含在ActionChains类中。 常用的鼠标方法: 例子: 键盘操作经常处理的如下: 代码如下 截图的方法: 在上一节,我们对 Selenium WebDriver 的使用,仅仅停留在让网页自动的进行操作的阶段,并没有对任何一个步骤进行“检查”。当然,这样没有“检查”的操作,实际上是没有测试意义的。那么第一项,我们需要解决的便是“检查”的问题。 所谓“检查”,实际上就是断言。对需要检查的步骤操作,通过对预先设置的期望值,和执行结果的实际值之间的对比,得到测试的结果。在这里,我们并不需要单独的写 目前 Java 语言主流的单元测试框架有 JUnit 和 TestNG。Python 语言主流的单元测试框架有 unittest 。本小节的内容,主要介绍 unittest 的使用,探讨单元测试框架如何帮助自动化测试。 接下来我们将会使用 Python 语言的 使用unittest需要以下简单的三步: unittest 并未使用 Java 语言常见的注解方式,依旧停留在 比较早期的 Java 版本中依靠方法名称进行识别的方式。主要有以下两个固定名字的方法: 具体的代码如下: 需要注意步骤: 上述代码运行结果如下: 为什么选择 unittest unittest 的断言配置使用 unittest 的断言,属于 什么是封装 封装是一个面向对象编程的概念,是面向对象编程的核心属性,通过将代码内部实现进行密封和包装,从而简化编程。对Selenium进行封装的好处主要有如下三个方面: 关键方法的封装思路 封装的具体示例: type(selector, text) 不用在业务逻辑中,使用多次的 click(selector) switch_to_frame(selector) select_by_index(selector, index) 以上的代码是封装了 面向对象编程思想的运用 封装后的方法如何被调用 使用上面的封装类,就需要指定特定的 selector 具体调用示例 “`python “` Page-Object设计模式的本质 Page Object设计模式是Selenium自动化测试项目的最佳设计模式之一,强调测试、逻辑、数据和驱动相互分离。 Page Object模式是Selenium中的一种测试设计模式,主要是将每一个页面设计为一个Class,其中包含页面中需要测试的元素(按钮,输入框,标题等),这样在Selenium测试页面中可以通过调用页面类来获取页面元素,这样巧妙的避免了当页面元素id或者位置变化时,需要改测试页面代码的情况。当页面元素id变化时,只需要更改测试页Class中页面的属性即可。 它的好处如下: 具体的做法如下: Page 如何划分 一般通过继承的方式,进行按照实际Web页面进行划分 Page-Object 类如何实现 实现的示例 Page 基类 设计了一个基本的 Page类,以便所有的页面进行继承,该类标明了一个sub page类的基本功能和公共的功能。 全局变量: self.base_driver,让所有的子类都使用的。 构造方法: 私有的常量:存放元素的定位符 成员方法: 每个子类都需要的系统功能: open 所有子类(页面)都具有的业务功能 select_app Sub Pages(s)子类 具体的页面的类,定义了某个具体的页面的功能 必须继承基类 特定页面的业务 使用基类的 Tests 类 这部分描述的是具体的测试用例。 声明全局变量 调用各种页面(pages) 实例化Page 使用page的对象,调用成员方法 什么是数据驱动 主要的数据驱动方式有两种: 通过 CSV 文件 或者 MySQL 数据库,是主流的数据驱动方式。当然数据驱动也可以结合单元测试框架的参数化测试进行编写(此部分本文不做具体描述)。 无论使用了 哪一种(CSV 或者 MySQL),读取数据后都要进行遍历操作。 使用 csv 使用 MySQL 需要掌握的知识点: 如何生成测试报告 测试报告的种类 HTML 测试报告的生成 HTML测试报告需要引入HTMLTestRunner HTMLTestRunner是基于Python2.7的,我们的课程讲义基于Python3.x,那么需要对这个文件做一定的修改。 测试的示例代码如下 来获取行数。
<ul class="promos">
<li>
<a href="http://demo.magentocommerce.com/home-decor.html">
<img src="/media/wysiwyg/homepage-three-column-promo-
01B.png" alt="Physical & Virtual Gift Cards">
a>
li>
<li>
<a href="http://demo.magentocommerce.com/vip.html">
<img src="/media/wysiwyg/homepage-three-column-promo-
02.png" alt="Shop Private Sales - Members Only">
a>
li>
<li>
<a href="http://demo.magentocommerce.com/accessories/
bags-luggage.html">
<img src="/media/wysiwyg/homepage-three-columnpromo-
03.png" alt="Travel Gear for Every Occasion">
a>
li>
ul>find_elements_by_tag_name()的方式去获取全部的图片,在此之前,我们将会使用find_element_by_class_name()去获取到指定的def test_count_of_promo_banners_images(self):
# get promo banner list
banner_list = self.driver.find_element_by_class_name("promos")
# get images from the banner_list
banners = banner_list.find_elements_by_tag_name("img")
# check there are 20 tags displayed on the page
self.assertEqual(20, len(banners))依据链接文字link查找
find_element_by_link_text请查看以下示例<a href="#header-account" class="skip-link skip-account">
<span class="icon">span>
<span class="label">ACCOUNT Descriptionspan>
a>def test_my_account_link_is_displayed(self):
# get the Account link
account_link =
self.driver.find_element_by_link_text("ACCOUNT Description")
# check My Account link is displayed/visible in
# the Home page footer
self.assertTrue(account_link.is_displayed())依据部分链接文字partial text查找
def test_account_links(self):
# get the all the links with Account text in it
account_links = self.driver.\
find_elements_by_partial_link_text("ACCOUNT")
# check Account and My Account link is
# displayed/visible in the Home page footer
self.assertTrue(2, len(account_links)) 依据XPath进行查找
starts-with(),contains()和ends-with()等
alt属性,定位到指定的tag。<ul class="promos">
<li>
<a href="http://demo.magentocommerce.com/home-decor.html">
<img src="/media/wysiwyg/homepage-three-column-promo-
01B.png" alt="Physical & Virtual Gift Cards">
a>
li>
<li>
<a href="http://demo.magentocommerce.com/vip.html">
<img src="/media/wysiwyg/homepage-three-column-promo-
02.png" alt="Shop Private Sales - Members Only">
a>
li>
<li>
<a href="http://demo.magentocommerce.com/accessories/
bags-luggage.html">
<img src="/media/wysiwyg/homepage-three-columnpromo-
03.png" alt="Travel Gear for Every Occasion">
a>
li>
ul>def test_vip_promo(self):
# get vip promo image
vip_promo = self.driver.\
find_element_by_xpath("//img[@alt='Shop Private Sales - Members Only']")
# check vip promo logo is displayed on home page
self.assertTrue(vip_promo.is_displayed())
# click on vip promo images to open the page
vip_promo.click()
# check page title
self.assertEqual("VIP", self.driver.title)find_elements_by_xpath()的方法,将会返回所有匹配了XPath查询的元素。依据CSS选择器进行查找
<div class="minicart-wrapper">
<p class="block-subtitle">Recently added item(s)
<a class="close skip-link-close" href="#" title="Close">×a>
p>
<p class="empty">You have no items in your shopping cart.
p>
div>def test_shopping_cart_status(self):
# check content of My Shopping Cart block on Home page
# get the Shopping cart icon and click to open the
# Shopping Cart section
shopping_cart_icon = self.driver.\
find_element_by_css_selector("div.header-minicart
span.icon")
shopping_cart_icon.click()
# get the shopping cart status
shopping_cart_status = self.driver.\
find_element_by_css_selector("p.empty").text
self.assertEqual("You have no items in your shopping cart.",
shopping_cart_status)
# close the shopping cart section
close_button = self.driver.\
find_element_by_css_selector("div.minicart-wrapper
a.close")
close_button.click()特殊 iframe 操作
<html>
<head>
<title>iframe示例title>
head>
<body>
<h1>
这里是H1,标记了标题
h1>
<p>
这里是段落,标记一个段落,属于外层
p>
<div>
<iframe id="iframe-1">
<html>
<body>
<p>
这里是个段落,属于内层,内联框架中的
p>
<div id="div-1">
<p class="hahahp">
这里是div中的段落,需要被定位
p>
div>
body>
html>
iframe>
div>
body>
html>:这里是div中的段落,需要被定位## 查找并定位 iframe
element_frame = driver.find_element_by_css_selector('#iframe-1')
## 切换到刚刚查找到的 iframe
driver.switch_to.frame(element_frame)
## 定位
driver.find_element_by_css_selector('#div-1 > p')
## TODO....
## 退出刚刚切换进去的 iframe
driver.switch_to.default_content()特殊 Select 操作
是选择列表selenium.webdriver.support.select.SelectC:\Python35\Lib\site-packages\selenium\webdriver\support\select.py<select id="brand">
<option value ="volvo">Volvooption>
<option value ="saab">Saaboption>
<option value="opel">Opeloption>
<option value="audi">Audioption>
select>## 查找并定位到 select
element_select = driver.find_element_by_css_selector('#brand')
## 用Select类的构造方法,实例化一个对象 object_select
object_select = Select(element_select)
## 操作 object_select
object_select.select_by_index(3)
## 也可以这样
object_select.select_by_value('audi')
## 还可以这样
object_select.select_by_visible_text('Audi')组合操作
driver.find_element_by_css_selector('#customer_chosen').click()
sleep(1)
driver.find_element_by_css_selector('#customer_list > li:nth-child(5)')1.4.3 鼠标事件操作
# 方法模拟鼠标右键,参考代码如下:
# 引入ActionChains 类
from selenium.webdriver.common.action_chains import ActionChains
...
# 定位到要右击的元素
right =driver.find_element_by_xpath("xx")
# 对定位到的元素执行鼠标右键操作
ActionChains(driver).context_click(right).perform()
...
# 定位到要双击的元素
double = driver.find_element_by_xpath("xxx")
# 对定位到的元素执行鼠标双击操作
ActionChains(driver).double_click(double).perform()1.4.4 键盘事件操作
代码
描述
send_keys(Keys.BACKSPACE)删除键(BackSpace)
send_keys(Keys.SPACE)空格键(Space)
send_keys(Keys.TAB)制表键(Tab)
send_keys(Keys.ESCAPE)回退键(Esc)
send_keys(Keys.ENTER)回车键(Enter)
send_keys(Keys.CONTROL,'a')全选(Ctrl+A)
send_keys(Keys.CONTROL,'c')复制(Ctrl+C)
from selenium import webdriver
# 引入Keys 类包
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
# 输入框输入内容
driver.find_element_by_id("kw").send_keys("selenium")
time.sleep(3)
# 删除多输入的一个m
driver.find_element_by_id("kw").send_keys(Keys.BACK_SPACE)
time.sleep(3)
# 输入空格键+“教程”
driver.find_element_by_id("kw").send_keys(Keys.SPACE)
driver.find_element_by_id("kw").send_keys("教程")
time.sleep(3)
# ctrl+a 全选输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'a')1.4.5 截图操作
save_screenshot(file)1.5 unittest 单元测试框
if 语句进行各种判定,而是可以使用编程语言中对应的单元测试框架,即可解决好此类问题。unittest框架展开“检查”。unittest框架的原本的名字是PyUnit。是从JUnit 这样一个被广泛使用的 经典的Java应用开发的单元测试框架创造而来。类似的框架还有NUnit(.Net开发的单元测试框架)等。我们可以使用unittest框架为任意Python项目编写可理解的单元测试集合。现在这个unittest已经作为Python的标准库模块发布。我们安装完Python以后,便可以直接使用unittest。
test开头
## 引入unittest模组
import unittest
## 定义测试类,名字为DemoTests
## 该类必须继承unittest.TestCase基类
class DemoTests(unittest.TestCase):
## 使用'@'修饰符,注明该方法是类的方法
## setUpClass方法是在执行测试之前需要先调用的方法
## 是开始测试前的初始化工作
@classmethod
def setUpClass(cls):
print("call setUpClass()")
## 每一个测试开始前的预置条件
def setUp(self):
print("call setUp()")
## 每一个测试结束以后的清理工作
def tearDown(self):
print("call tearDown()")
## 测试一(务必以test开头)
def test_01(self):
print("call test_01()")
pass
## 测试三(务必以test开头)
def test_02(self):
print("call test_02()")
pass
## 测试三(务必以test开头)
def test_03(self):
print("call test_03()")
pass
## tearDownClass方法是执行完所有测试后调用的方法
## 是测试结束后的清除工作
@classmethod
def tearDownClass(cls):
print("call tearDownClass()")
# 执行测试主函数
if __name__ == '__main__':
## 执行main全局方法,将会执行上述所有以test开头的测试方法
unittest.main(verbosity=2)
需要在 类实例化的对象,运行的开头和结尾进行执行。
加了星号(*)的步骤,可以不用。call setUpClass()
call setUp()
call test_01()
call tearDown()
call setUp()
call test_02()
call tearDown()
call setUp()
call test_06()
call tearDown()
call tearDownClass()
TestCase类,只要继承了该类,均可以通过 self调用断言
方法 Method
检查条件
assertEqual(a, b [, msg])a == b,msg可选,用来解释失败的原因
assertNotEqual(a, b [, msg]a != b,msg可选,用来解释失败的原因
assertTrue(x [, msg])x 是真,msg可选,用来解释失败的原因
assertFalse(x [, msg])x 是假,msg可选,用来解释失败的原因
assertIsNot(a, b [, msg])a 不是 b,msg可选,用来解释失败的原因
1.6 为什么需要封装 Selenium
1.7 封装的概念与基本操作
find_element_by_id(...))def type(self, selector, text):
"""
Operation input box.
Usage:
driver.type("i,el","selenium")
"""
el = self._locate_element(selector)
el.clear()
el.send_keys(text)
def click(self, selector):
"""
It can click any text / image can be clicked
Connection, check box, radio buttons, and even drop-down box etc..
Usage:
driver.click("i,el")
"""
el = self._locate_element(selector)
el.click()
def switch_to_frame(self, selector):
"""
Switch to the specified frame.
Usage:
driver.switch_to_frame("i,el")
"""
el = self._locate_element(selector)
self.base_driver.switch_to.frame(el)
def select_by_index(self, selector, index):
"""
It can click any text / image can be clicked
Connection, check box, radio buttons, and even drop-down box etc..
Usage:
driver.select_by_index("i,el")
"""
el = self._locate_element(selector)
Select(el).select_by_index(index)_locate_element()的几种方法,在具体使用封装过的代码的时候,只需要简单的调用即可。接下来的重点,是介绍 _locate_element(selector)的封装方式。
find_element_by_...)selector 显示出分类selector中需要包含一个特殊符号
硬编码 hard code来实例化,例如 , 或者 ? 或者 其他非常用字符 =>this.byCharWebElementdef _locate_element(self, selector):
"""
to locate element by selector
:arg
selector should be passed by an example with "i,xxx"
"x,//*[@id='langs']/button"
:returns
DOM element
"""
if self.by_char not in selector:
return self.base_driver.find_element_by_id(selector)
selector_by = selector.split(self.by_char)[0].strip()
selector_value = selector.split(self.by_char)[1].strip()
if selector_by == "i" or selector_by == 'id':
element = self.base_driver.find_element_by_id(selector_value)
elif selector_by == "n" or selector_by == 'name':
element = self.base_driver.find_element_by_name(selector_value)
elif selector_by == "c" or selector_by == 'class_name':
element = self.base_driver.find_element_by_class_name(selector_value)
elif selector_by == "l" or selector_by == 'link_text':
element = self.base_driver.find_element_by_link_text(selector_value)
elif selector_by == "p" or selector_by == 'partial_link_text':
element = self.base_driver.find_element_by_partial_link_text(selector_value)
elif selector_by == "t" or selector_by == 'tag_name':
element = self.base_driver.find_element_by_tag_name(selector_value)
elif selector_by == "x" or selector_by == 'xpath':
element = self.base_driver.find_element_by_xpath(selector_value)
elif selector_by == "s" or selector_by == 'css_selector':
element = self.base_driver.find_element_by_css_selector(selector_value)
else:
raise NameError("Please enter a valid type of targeting elements.")
return element
类型
示例(分隔符以逗号
,为例)描述
id
“account” 或者 “i,account” 或者 “id,account”
分隔符左右两侧不可以空格
xpath
“x,//*[@id=”s-menu-dashboard”]/button/i”
css selector
“s,#s-menu-dashboard > button > i”
link text
“l,退出”
partial link text
“p,退”
name
“n,name1”
tag name
“t,input”
class name
“c,dock-bottom
def login(self, account, password, keep):
“””
登录系统
:param account:
:param password:
:param keep:
:return: 返回保持登录复选框的 checked 值
“””
self.base_driver.type(self.LOGIN_ACCOUNT_SELECTOR, account)
self.base_driver.type(self.LOGIN_PASSWORD_SELECTOR, password) current_checked = self.get_current_keep_value()
if keep:
if current_checked is None:
self.base_driver.click(self.LOGIN_KEEP_SELECTOR)
else:
if current_checked == "true":
self.base_driver.click(self.LOGIN_KEEP_SELECTOR)
actual_checked = self.get_current_keep_value()
self.base_driver.click(self.LOGIN_SUBMIT_SELECTOR)
sleep(2)
return actual_checked
1.8 Page-Object设计模式介绍
# 基类的变量,所有继承的类,都可以使用
base_driver = None
# 方法
def __init__(self, driver: BoxDriver):
"""
构造方法
:param driver: ":BoxDriver" 规定了 driver 参数类型
"""
self.base_driver = driverLOGIN_ACCOUNT_SELECTOR = "s, #account"
LOGIN_PASSWORD_SELECTOR = "s, #password"
LOGIN_KEEP_SELECTOR = "s, #keepLoginon"
LOGIN_SUBMIT_SELECTOR = "s, #submit"
LOGIN_LANGUAGE_BUTTON_SELECTOR = "s, #langs > button"
LOGIN_LANGUAGE_MENU_SELECTOR = "s, #langs > ul > li:nth-child(%d) > a"
LOGIN_FAIL_MESSAGE_SELECTOR = "s, body > div.bootbox.modal.fade.bootbox-alert.in > div > div > div.modal-body"
def open(self, url):
"""
打开页面
:param url:
:return:
"""
self.base_driver.navigate(url)
self.base_driver.maximize_window()
sleep(2)class MainPage(BasePage):self.base_driver 成员变量base_driver = None
base_url = None
main_page = None
self.main_page = MainPage(self.base_driver)self.main_page.open(self.base_url)
self.main_page.change_language(lang)2. 构建测试方案
2.1 数据驱动在自动化测试中的应用
import csv
csv_file = open("xxx.csv", "r", encoding="utf8")
csv_data = csv.reader(csv_file)
for row in csv_data:
# 进行测试
# 使用字典类型
data_to_test = {
"key1": row[0],
"key2": row[1]
}
csv_file.close()import pymysql
connect = pymysql.connect(host="xx", port=3306, user="root", passwd="xxx", db="xx")
cur = connect.cursor()
cur.execute("SELECT...")
mysql_data = cur.fetchall()
for row in mysql_data:
# 进行测试
# 使用字典类型
data_to_test = {
"key1": row[0],
"key2": row[1]
}
cur.close()
connect.close()
dict 类型
2.2 测试方案的编码实现
2.3 测试报告的生成
# 声明一个测试套件
suite = unittest.TestSuite()
# 添加测试用例到测试套件
suite.addTest(RanzhiTests("test_ranzhi_login"))
# 创建一个新的测试结果文件
buf = open("./result.html", "wb")
# 声明测试运行的对象
runner = HTMLTestRunner.HTMLTestRunner(stream=buf,
title="Ranzhi Test Result",
description="Test Case Run Result")
# 运行测试,并且将结果生成为HTML
runner.run(suite)
# 关闭文件输出
buf.close()2.4 具体案例分析
自动化测试在路上
你可能感兴趣的:(测试开发)