在跑通Faster-rcnn的demo,以及机智地在VOC2007上只使用行人对象训练跑通后,还是要自己制作数据集。以Caltech行人数据集为例,要将下载的seq转为png格式,vbb格式转为xml格式,转变为VOC格式,还要读取pascal_voc.py中数据接口,保证数据读取正确。
代码主要参考这篇博客
1.seq转为png(python3)
import os
import glob
import cv2 as cv
# 保存图片以指定名字到指定位置
def save_img(dname, fn, i, frame):
cv.imwrite('{}/{}_{}_{}.png'.format(
out_dir, os.path.basename(dname),
os.path.basename(fn).split('.')[0], i), frame)
#输出图片位置
out_dir = 'E:/images'
if not os.path.exists(out_dir):
os.makedirs(out_dir)
#seq文件位置
for dname in sorted(glob.glob('E:/bishe/database/set*')):
for fn in sorted(glob.glob('{}/*.seq'.format(dname))):
cap = cv.VideoCapture(fn)
i = 0
while True:
# ret为标志位,bool型,是否读到数据,frame为视频帧图像数据
ret, frame = cap.read()
if not ret:
break
save_img(dname, fn, i, frame)
i += 1
print(fn)
注意:输出路径不能包括中文,python3中cv包好像读不了。

2.vbb转为txt(matlab带code3.2.1的库)
a = [0 1 2 3 4 5];
vPath = 'E:\bishe\database\datasize caltech\annotations\';
outpath = 'E:\bishe\database\datasize caltech\annotations\caltechAnnotations';
if ~isdir(outpath)
mkdir(outpath);
end
disp('Begin to extract annotations from vbb....')
for ii = 1:length(a)
vName = ['set0',num2str(a(ii))];
vbbpath = [vPath vName];
str = dir(vbbpath); %读文件
for k = 3:numel(str)
finalpath = [vbbpath,'\',str(k).name];
disp(finalpath);
A = vbb( 'vbbLoad', finalpath);
Path = [outpath,'\',vName];
if ~isdir(Path)
mkdir(Path);
end
st = str(k).name;
p = findstr(st,'.');
st = st(1,1:p(1)-1);
fnm = [st,'.txt'];
c=fopen([Path,'\',fnm],'w');
for i = 1:A.nFrame
iframe = A.objLists(1,i);
iframe_data = iframe{1,1};
n1length = length(iframe_data);
for j = 1:n1length
iframe_dataj = iframe_data(j);
if iframe_dataj.pos(1) ~= 0 %pos posv
fprintf(c,'%d %f %f %f %f\n', i, iframe_dataj.pos(1),...
iframe_dataj.pos(2),iframe_dataj.pos(3),iframe_dataj.pos(4));
end
end
end
end
fclose(c);
end
disp('Done................')
A便是vbb文件的信息,需要把断点打在A = vbb( 'vbbLoad', finalpath);
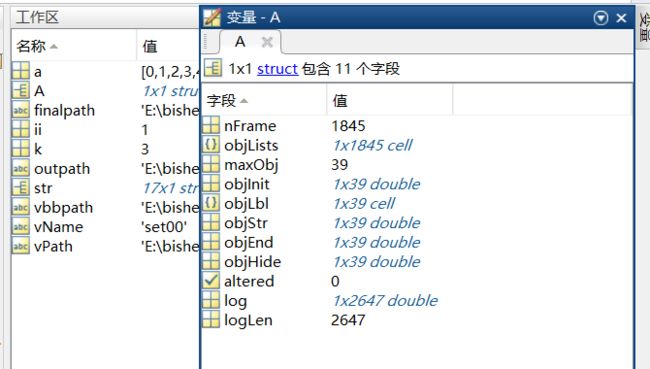
结构体A获取后,后一段就是写内容到txt。
txt生成以后,打开(用matlab打开,用txt打开有点乱)

每一行第一个数字是对应帧数,后四个数字是行人框的左上角横坐标、纵坐标、框宽度、高度。
有很多人都在提问V000的69张图片并没有人(其实txt中69对应V000_68的图片,matlab处理从1开始,而图片命名从0开始),而以为自己数据处理错误。其实图片中是有人的,只不过很小而已(我也是看了半天才发现)。
3.txt转为xml
这一段处理最费时间,基于原博客的代码我进行了很多修改。
from lxml.etree import Element, SubElement, tostring
import pprint
from xml.dom.minidom import parseString
import os
import pdb
def mkdir(path):
import os
path = path.strip()
path = path.rstrip("\\")
isExists = os.path.exists(path)
if not isExists:
os.makedirs(path)
print (path + 'ok')
return True
else:
print (path + 'failed!')
return False
def generate_xml(file_info, obj):
# xml写操作
node_root = Element('annotation')
node_folder = SubElement(node_root, 'folder')
node_folder.text = file_info[0]
node_filename = SubElement(node_root, 'filename')
node_filename.text = file_info[1]
node_size = SubElement(node_root, 'size')
node_width = SubElement(node_size, 'width')
node_width.text = '640'
node_height = SubElement(node_size, 'height')
node_height.text = '480'
node_depth = SubElement(node_size, 'depth')
node_depth.text = '3'
for obj_i in obj:
print (obj_i)
node_object = SubElement(node_root, 'object')
node_name = SubElement(node_object, 'name')
#node_name.text = 'mouse'
node_name.text = 'person'
node_bndbox = SubElement(node_object, 'bndbox')
node_xmin = SubElement(node_bndbox, 'xmin')
#node_xmin.text = '99'
node_xmin.text = obj_i['xmin']
node_ymin = SubElement(node_bndbox, 'ymin')
#node_ymin.text = '358'
node_ymin.text = obj_i['ymin']
node_xmax = SubElement(node_bndbox, 'xmax')
#node_xmax.text = '135'
node_xmax.text = obj_i['xmax']
node_ymax = SubElement(node_bndbox, 'ymax')
#node_ymax.text = '375'
node_ymax.text = obj_i['ymax']
xml = tostring(node_root, pretty_print=True) #格式化显示,该换行的换行
dom = parseString(xml)
file_root = 'E:/bishe/database/CaltechVOC/Annotations'
fw = open(file_root+"/"+file_info[1].split('.')[0]+".xml", 'wb')
fw.write(xml)
print ("xml _ ok")
fw.close()
#for debug
#print xml
def printPath(level, path):
global allFileNum
'''''
打印一个目录下的所有文件夹和文件
'''
# 所有文件夹,第一个字段是次目录的级别
dirList = []
# 所有文件
fileList = []
# 返回一个列表,其中包含在目录条目的名称(google翻译)
files = os.listdir(path)
# pdb.set_trace()
# 先添加目录级别
dirList.append(str(level))
#获取文件,set00-set0*
for f in files:
if(os.path.isdir(path + '/' + f)):
# 排除隐藏文件夹。因为隐藏文件夹过多
if(f[0] == '.'):
pass
else:
# 添加非隐藏文件夹
dirList.append(f)
if(os.path.isfile(path + '/' + f)):
# 添加文件
fileList.append(f)
# 当一个标志使用,文件夹列表第一个级别不打印
i_dl = 0
#获取每个文件下的txt文件
for dl in dirList:
if(i_dl == 0):
i_dl = i_dl + 1
else:
# 打印至控制台,不是第一个的目录
path1 = path + '/' + dl
# 遍历获取文件下所有的txt文件
files = os.listdir(path1)
# 读取txt文件
for fl in files:
#if(os.path.isfile(path1 + '/' + f)):
fileList.append(fl)
file_info = []
print(path1)
file_name = path1+"/"+fl
fw = open(file_name, 'r');
#读取文件每一行信息
line_content = fw.readlines()
fw.close()
print(line_content)
tmp = -1
obj = []
con_len = len(line_content)
try:
# 分割,每一行相当于一个单元
string = line_content[0].split(" ")
tmp = int(string[0])
except Exception:
continue
# folder的命名
file_info.append('Caltech_{}_{}'.format(
os.path.basename(dl),os.path.basename(fl).split('.')[0]))
# 图片的命名需要与图片名对应
file_info.append('{}_{}_{}.png'.format(
os.path.basename(dl),os.path.basename(fl).split('.')[0], str(tmp-1)))
#box赋值,xmin,ymin不能等于0,否则faster-rcnn中数据溢出
if int(float(string[1]))==0:
xmin = '1'
else:
xmin = str(int(float(string[1])))
if int(float(string[2]))==0:
ymin = '1'
else:
ymin = str(int(float(string[2])))
xmax = str(int(float(string[1]) + float(string[3])))
ymax = str(int(float(string[2]) + float(string[4])))
dict1 = {}
dict1["xmin"] = xmin
dict1["ymin"] = ymin
dict1["xmax"] = xmax
dict1["ymax"] = ymax
obj.append(dict1)
for con_i in range(1, con_len):
string = line_content[con_i].split(" ")
tmp1 = int(string[0])
#一帧中多个对象
if tmp == tmp1:
if int(float(string[1]))==0:
xmin = '1'
else:
xmin = str(int(float(string[1])))
if int(float(string[2]))==0:
ymin = '1'
else:
ymin = str(int(float(string[2])))
xmax = str(int(float(string[1]) + float(string[3])))
ymax = str(int(float(string[2]) + float(string[4])))
dict1 = {}
dict1["xmin"] = xmin
dict1["ymin"] = ymin
dict1["xmax"] = xmax
dict1["ymax"] = ymax
obj.append(dict1)
# 最后1帧不会再执行tmp1 > 0产生xml,因此需特殊处理
if con_i == con_len-1:
generate_xml(file_info, obj)
elif tmp1 > 0:
generate_xml(file_info, obj)
#下一帧处理
obj = []
tmp = tmp1
file_info[1] = "{}_{}_{}.png".format(
os.path.basename(dl),os.path.basename(fl).split('.')[0], str(tmp-1))
if int(float(string[1]))==0:
xmin = '1'
else:
xmin = str(int(float(string[1])))
if int(float(string[2]))==0:
ymin = '1'
else:
ymin = str(int(float(string[2])))
xmax = str(int(float(string[1]) + float(string[3])))
ymax = str(int(float(string[2]) + float(string[4])))
dict1 = {}
dict1["xmin"] = xmin
dict1["ymin"] = ymin
dict1["xmax"] = xmax
dict1["ymax"] = ymax
obj.append(dict1)
continue
def read_annotations_generate_fileinfo_obj(file_path):
pass
if __name__=="__main__":
#
# file_info = ['set00/V000', '1.jpg']
#
# obj = []
# obj1 = {"xmin":"1", "ymin":"1", "xmax":"5", "ymax":"5"}
# obj2 = {"xmin":"2", "ymin":"2", "xmax":"6", "ymax":"6"}
# obj.append(obj1)
# obj.append(obj2)
#
# generate_xml(file_info, obj)
#
printPath(1, "E:/bishe/database/datasize caltech/annotations/caltechAnnotations")
注意点:
- matlab处理从1开始,而图片命名从0开始,因此读取txt中帧数1,需要做减1处理。
-
box赋值,xmin,ymin不能等于0,因为faster-rcnn有-1处理,否则faster-rcnn中数据溢出。
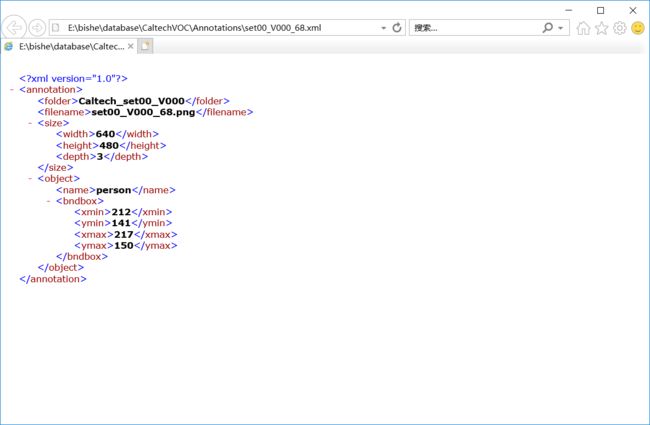
4.产生测试集训练集
import os
import glob
import cv2 as cv
import random
import pdb
def save_txt(nameList):
trainval_percent = 0.66
train_percent = 0.5
folder_root = 'E:/bishe/database/CaltechVOC/'
# pdb.set_trace()
num = len(nameList)
#print num
# 通过随机函数产生训练集测试集
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open(folder_root + 'ImageSets/Main/trainval.txt', 'a')
ftest = open(folder_root + 'ImageSets/Main/test.txt' , 'a')
ftrain = open(folder_root + 'ImageSets/Main/train.txt' , 'a')
fval = open(folder_root + 'ImageSets/Main/val.txt' , 'a')
for i in list:
name = nameList[i] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
out_dir = 'E:/images'
nameList=[]
if not os.path.exists(out_dir):
os.makedirs(out_dir)
for dname in sorted(glob.glob('E:/bishe/database/set*')):
for fn in sorted(glob.glob('{}/*.seq'.format(dname))):
cap = cv.VideoCapture(fn)
i = 0
while True:
ret, frame = cap.read()
if not ret:
break
name='{}_{}_{}'.format(
os.path.basename(dname),os.path.basename(fn).split('.')[0], i)
# 遍历seq文件后获取所有图片名字
nameList.append(name)
i += 1
save_txt(nameList)