python绘制柱状图与饼图
对《青春有你2》对选手体重及地区分布进行可视化,以柱状图与饼图显示
调用matplootlib库与pandas库形式统计与绘制
1、柱状图
方法一:maplotlib方式绘制:plt.bar函数生成柱状图
import numpy as np
import json
import matplotlib.font_manager as font_manager
#显示matplotlib生成的图形
%matplotlib inline
with open('data/data31557/20200422.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
#绘制小姐姐区域分布柱状图,x轴为地区,y轴为该区域的小姐姐数量
zones = []
for star in json_array:
zone = star['zone']
zones.append(zone)
print(len(zones))
print(zones)
zone_list = []
count_list = []
for zone in zones:
if zone not in zone_list:
count = zones.count(zone)
zone_list.append(zone)#汇总城市分布
count_list.append(count)#各城市中选手数量统计
print(zone_list)
print(count_list)
# 设置显示中文
plt.rcParams['font.sans-serif'] = ['simhei'] # 设置中文字体格式
plt.figure(figsize=(20,15))#生成画布,figsize为画布大小
plt.bar(range(len(count_list)), count_list,color='r',tick_label=zone_list,facecolor='#9999ff',edgecolor='white')
# 这里是调节横坐标的倾斜度,rotation是度数,以及设置刻度字体大小
plt.xticks(rotation=45,fontsize=20)
plt.yticks(fontsize=20)
plt.legend()#图像图例
plt.title('''《青春有你2》参赛选手''',fontsize = 24)
plt.savefig('/home/aistudio/work/result/bar_result.jpg')
plt.show()
程序运行结果:

生成图片样式:
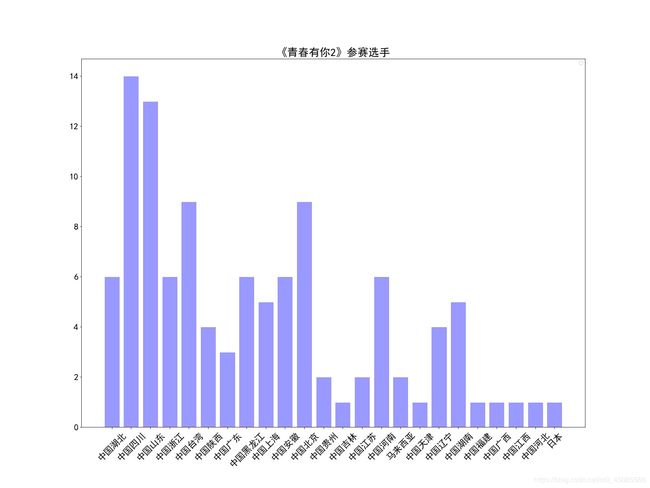
方式二:pandas方式统计地区分布及数量
import pandas as pd
#显示matplotlib生成的图形
%matplotlib inline
df = pd.read_json('data/data31557/20200422.json')
print(df)
grouped=df['name'].groupby(df['zone'])
s = grouped.count()
zone_list = s.index
count_list = s.values
#剩余代码部分同上,显示结果相同
print(df)内容显示:

2、饼图之选手体重绘制
方法一:maplotlib中plt.pie()函数可实现,对应参数设置如下:
import matplotlib.pyplot as plt
import numpy as np
import json
import matplotlib.font_manager as font_manager
with open('data/data31557/20200422.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
#显示matplotlib生成的图形
# %matplotlib inline
error_list=['k','g']
weights = []
for star in json_array:
weight = star['weight']
for c in weight:
if c in error_list:
weight=weight.replace(c,'')#去除选手体重中的‘kg’字符
#weight=float(star['weight'].repalce('kg',''))
# print(type(weight))
weights.append(weight)
print(len(weights))
print(weights)
# num=len(weights)
size_1=0
size_2=0
size_3=0
size_4=0
for i in range(len(weights)):
if weights[i] <= '45':
size_1+=1
continue
elif weights[i]<='50' and weights[i]>'45':
size_2+=1
continue
elif weights[i]<='55' and weights[i]>'50':
size_3+=1
continue
else:
size_4+=1
print(size_1)
print(size_2)
print(size_3)
print(size_4)
sizes=[size_1,size_2,size_3,size_4]
labels='小于45kg','45~50kg','50~55kg','大于55kg'
explode = (0,0.1,0,0.2) #饼图中的显示突出出来
plt.pie(sizes,explode=explode,labels=labels,autopct='%1.1f%%',shadow=False,startangle=150)
plt.axis('equal')#设置饼图为正圆形式,而非椭圆
plt.title("饼图示例-《青春有你2》选手体重")
plt.show()
小细节:weight=float(star['weight'].repalce('kg',''))快速去除字符串中不必要字符,并转换字符为float数值
最终结果:109为选手总人数

方法二:pandas快速实现数据分割与统计
所用函数pandas.cut用来把一组数据分割成离散的区间,value_counts()函数对Series里面的每个值进行计数并排序
代码明显要比上一种简洁。
#显示matplotlib生成的图形
%matplotlib inline
df=pd.readjson('data/data31557/20200422.json')
print(df)
weight=df['weight']#列的索引取选手体重
arrs=weights.values
for i in range(len(arrs)):
print(float(arrs[i][0:-2]))
arrs[i]=float(arrs[i][0:-2])#切片方式把字符串最后的‘kg’截取掉
prit(arrs)
# pandas.cut用来吧一组数据分割成离散的区间
bin=[0,45,55,100]#区间分割上下限
sel=pd.cut(arrs,bin)
# pandas的value_counts()函数可以对Series里面的每个值进行计数并排序
pd.value_counts(sel)
labels='小于45kg','45~50kg','50~55kg','大于55kg'
sizes=pd.value_counts(sel)
explode=(0,0)
fig1,ax1=plt.subplots()
ax1.pie(sizes,explode=explode,labels=labels,autopct='%1.1f%%',
shadow=True,startangle=90)#explode:偏离中心点,startangle=90:顺时针
ax1.axis('equal')
plt.savefig('/home/aistudio/work/result/bar_result02.jpg')
plt.show()
注:另一种去除特定字符的方法,切片形式arrs[i]=float(arrs[i][0:-2]);第一种为.replace(a,'b'),即用b代替a
3、下载中文字体方法
# 下载中文字体
!wget https://mydueros.cdn.bcebos.com/font/simhei.ttf
# 将字体文件复制到matplotlib字体路径
!cp simhei.ttf /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf/
# 一般只需要将字体文件复制到系统字体目录下即可,但是在aistudio上该路径没有写权限,所以此方法不能用
# !cp simhei.ttf /usr/share/fonts/
# 创建系统字体文件路径
!mkdir .fonts
# 复制文件到该路径
!cp simhei.ttf .fonts/
!rm -rf .cache/matplotlib
字体调用:
# 设置显示中文
plt.rcParams['font.sans-serif'] = ['simhei'] # 指定默认字体
AI Studio平台七日打卡营作业分享,Day3《青春有你2》选手数据分析,
https://aistudio.baidu.com/aistudio/projectdetail/426148