CVPR2020 | 论文阅读——CentripetalNet: Pursuing High-quality Keypoint Pairs for Object Detection
CentripetalNet
- 前言
- 1、Background Introduction
- 1.1 Related work
- 1.2 CornerNet
- 1.3 CenterNet
- 1.4 Background Introduction
- 2、Network Architecture
- 2.1 CentripetalNet
- 2.2 Centripetal Shift Module
- 2.2.1 Centripetal Shift
- 2.2.2 Centripetal Shift Loss
- 2.2.3 Centripetal Shift Module
- 2.2.4 Corner Matching
- 2.3 Cross-star Deformable Convolution
- 2.3.1 Corner Pooling
- 2.3.2 Guiding shift
- 2.2.3 Offset field
- 2.4 Instance Mask Head
- 3、Experiments
- 3.1 Experimental Setting
- 3.2 Comparison with state-of-the-art models
- 3.3 Ablation study
- 3.3.1 Centripetal Shift
- 3.3.2 Cross-star Deformable Convolution
- 3.3.3 Instance Segmentation Module
- 3.4 Qualitative analysis
- 4、Conclusions
- 5、References

前言
论文地址:https://arxiv.org/pdf/2003.09119.pdf
开源代码:https://github.com/KiveeDong/CentripetalNet
简介:
该论文发表于CVPR2020,是基于关键点检测器的一篇创新的论文。作者在本文中提出了一种使用向心偏移来对同一个目标的角点进行配对的CentripetalNet(向心网络)。CentripetalNet不仅预测角点的位置和向心偏移,而且匹配移动结果将属于同一个框中的角点进行配对,选取两个角点的向心中心划定的区域作为中心区域,产生候选框。 这种方法比传统的嵌入方法能够更准确地匹配角点。Corner pooling(角点池化)将边界框内的信息提取到边界上,为了使得这些信息在角落里更容易被察觉,作者提出了一个Cross-star Deformable Convolution(交叉星可变形卷积)模块来代替corner网络中的Embedding,更好地适应特征。除了检测,作者的CentripetalNet安置一个mask预测模块来探索anchor-free检测器上的实例分割。CentripetalNet网络在MS-COCO数据集中,目标检测的AP达到48.0%,在anchor-free的方法中达到了SOTA。
内容目录:
1、Background Introduction
1.1 Related work
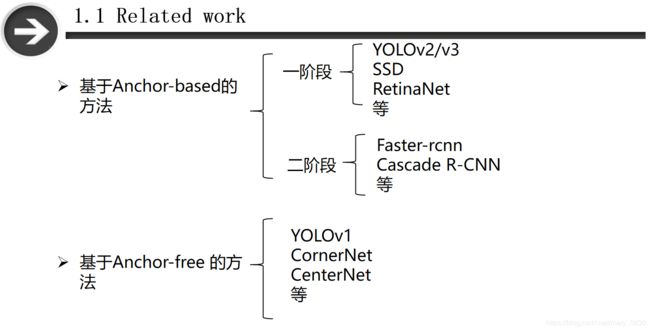
首先,介绍一下Anchor-based和Anchor-free的区别,这两种方法的区别就在于有没有利用anchor提取候选目标框。基于Anchor-based方法是我们常说的faster-rcnn,yolov2/v3这些,无论是一阶段还是二阶段,都会先使用anchor生成候选框,基于所有生成的候选框,选取得分最高的作为最后的预测结果。Anchor-free则没有通过anchor生成候选框的这一类方法(YOLOv1\CornerNet),如基于多个关键点的描述、基于单个中心点预测。
1.2 CornerNet
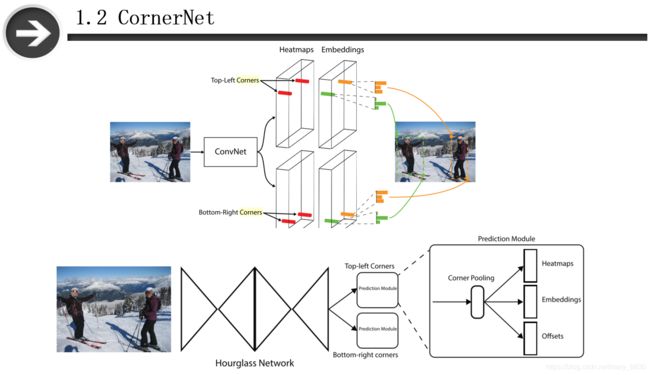
CornerNet的作者把目标检测问题当作关键点检测问题来解决,检测目标的两个关键点——左上角(Top-left)和右下角( Bottom-right ),有了两个点之后,基本就能确定框了。CornerNet的基本流程是:输入图片经过Hourglass主干网络后,得到特征图,然后将该特征图作为两个预测模块的输入,分别是Top-left corners和Bottom-right corners。在每个预测模块中,先经过corner pooling,然后输出heatmaps,Embeddings, Offsets三个分支。heatmaps预测的是哪些点最有可能是corners点,embeddings的作用是找到哪些点最有可能是一组的,offsets则是用于对点的位置进行修正。
1.3 CenterNet
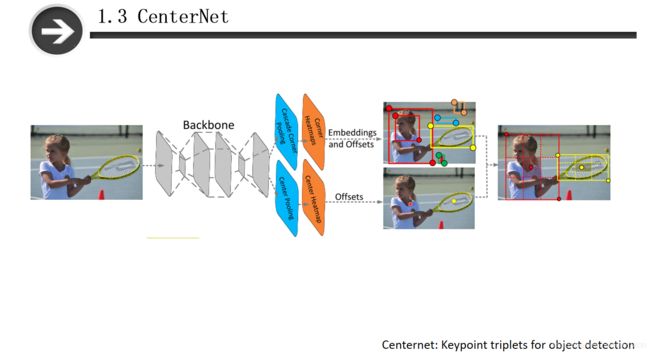
在cornernet中,容易产生一些无效的框,同时这些无效框的中心位置一般不在物体上,因此需要通过预测物体的中心点来对cornernet的bounding box进行过滤,去除那些中心点不在物体上的bbox。由于cornernet中使用了Corner Pooling,这种Pooling方式过于关注物体的边缘信息,而对物体内部信息缺少关注。
基于以上的不足, CenterNet的作者提出了一种方法对于cornernet中的不足的地方进行修改。CenterNet基本流程是:首先输入一张图片,经过hourglass作为主干网络提取特征图,将该特征图输入到cascade corner pooling(级联角点池化)模块,然后输出corner heatmaps,采用与cornernet中一样的方法,找到左上角和右下角,得到目标的bounding box。另一分支是采用center pooling模块,获得图像center heatmaps,根据center heatmap找到所有的目标中心点。最后使用目标中心点对所有的bounding box进行过滤,如果box的中间区域没有中心点的存在,则认为该box是不可取的,直到找到所有中心点与左上角点、右下角点匹配的框作为最终预测框。
1.4 Background Introduction
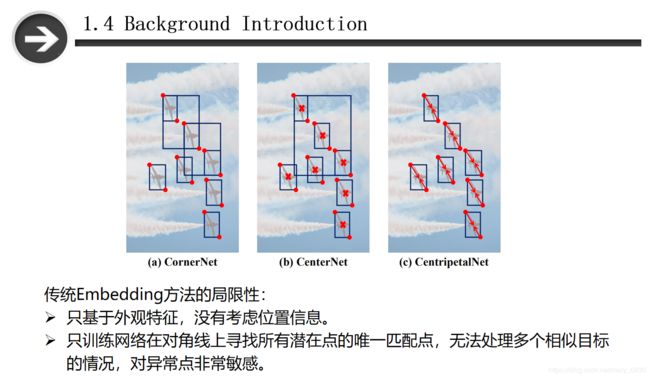
(a)目标相似且密集,CornerNet基于目标表观特征匹配角点对产生了许多错误的结果。
(b)CenterNet通过中心预测除去了一些错误的角对,但仍然无法处理一些目标密集的情况。
(c)CentripetalNet修正了CornerNet和CenterNet的缺点。
在以上两种方法的介绍中,我们可以从上图中看到,理论上这些方法是可以找到很好的预测框的,但是在多个目标密集且相似的情况下,训练难度会增加,并且基于embedding的方法仅仅利用目标的表观特征,而没有使用位置信息。如图所示。本文作者提出的方法可以有效地改善关键点匹配问题。
2、Network Architecture
2.1 CentripetalNet
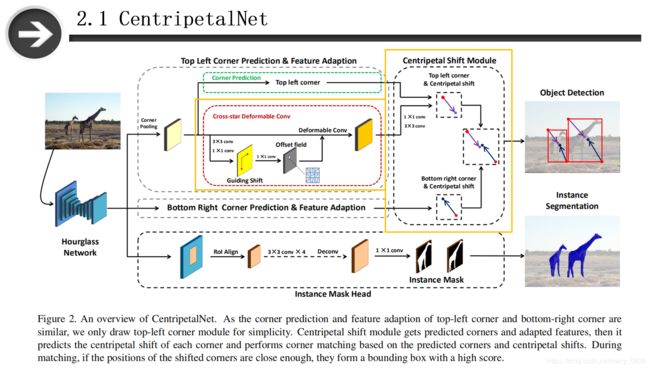
如图所示,这是CentripetalNet网络的总体结构。基本流程是:输入一张图片,经过hourglass主干网络提取出特征图,将得到的特征图分别输入三个模块中。第一个模块是左上角点预测和特征自适应,特征图输入到cornernet pooling中,输出两个分支,上分支得到heatmaps进行角点预测(与cornernet一样)。下分支是进行交叉星可变形卷积操作,这部分操作代替了cornernet中的Embedding模块,这部分的作用是从角点到中心点的偏移中来产生“偏移场”,进行特征适配,用丰富角点位置的特征来进行可变形卷积操作,这可以提高向心偏移模块的精度。
将角点预测和交叉星可变形卷积的结果输入到向心偏移模块中,进行角点匹配,在匹配过程中,如果两个角点对应的的中心位置足够接近,就会形成得分比较高的边界框,作为最终输出的预测框。
最下面的实例掩码模块用来进一步提高检测性能,可将该方法拓展到实例分割区域。该方法是以向心偏移模块的预测边框为region proposals,利用RoIAlign提取region特征,并利用4个3×3卷积和反卷积对分割的掩码进行预测。由于CentripetalNet网络是端到端训练的,可以不加入实例掩码模块到目标检测中,并不会影响检测效果。
2.2 Centripetal Shift Module
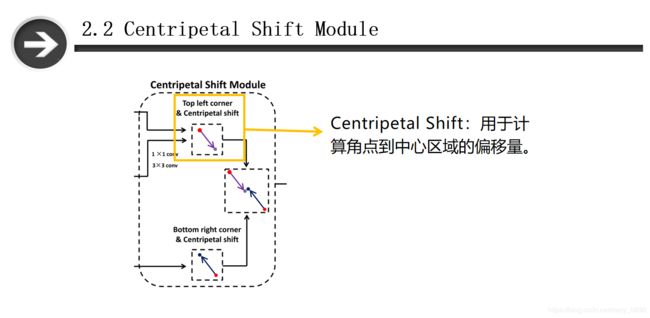
按照文章的顺序,先介绍Centripetal Shift Module 。这个模块分为两个部分,第一个部分是左上角的向心偏移,作用是计算角点到中心区域的偏移量,第二个部分是左上角和右下角的角点匹配,作用是计算角点对的中心区域的权重,然后选取得分最高的作为候选框。
2.2.1 Centripetal Shift

作者首先定义了一个边界框的坐标,如上图所示,包含左上角、右下角和几何中心。又定义了左上角和右下角的向心偏移,在这个公式中,s在代码中代表的是scale = 1,用来表示GT被缩放了多少倍。log的作用是减少向心偏移的数值范围,使得学习更加容易。
2.2.2 Centripetal Shift Loss

定义边界框,就要计算真实与预测的角点位置到中心区域的偏移误差,因此定义了 L c s L_{cs} Lcs。在训练过程中,使用SmoothL1损失函数对向心位移进行预测优化。如图(a)和(c)所示,边界框内蓝色和绿色的线段则表示GT和预测的向心偏移,用 L c s L_{cs} Lcs来预测并优化这个位移。
2.2.3 Centripetal Shift Module
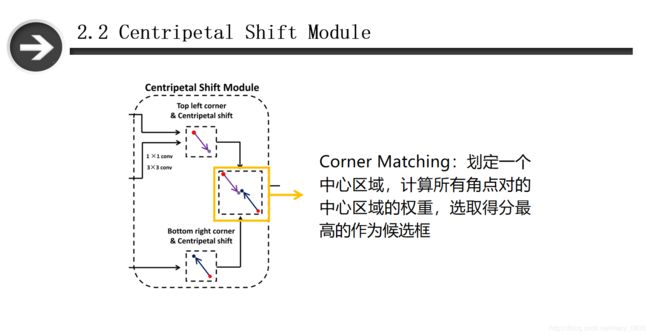
第一部分提到向心位移的定义,以及如何使用损失函数对向心位移的预测优化,以达到对角点预测的优化。第二部分就介绍如何对检测的角点进行匹配。论文利用了向心位移以及其位置信息匹配角点,简单的说就是当一对角点来自同一个边界框,那么它们应该共享边界框的中心区域。Corner Matching作用是划定一个中心区域,计算角点对的中心区域的权重,然后选取得分最高的作为候选框。
2.2.4 Corner Matching

对于从corner heatmap和局部偏移heatmap获得角点后,对属于同一个别的角点进行分组,满足 t l x < b r x tlx
由于原图上的点和特征图上的点相互映射会存在偏差,因此定义Otl和Obr分别表示左上角和右下角的偏差(这里整数点为特征图映射到原图的结果,由于计算会造成精度丢失,因此使用Otl和Obr用于精度补偿。)这里取左上角和右下角向心位移的指数形式,是为了后面便于求梯度时的导数。

如图(c),模型预测的角点位置和向心位移指向相应的中心点(蓝色点和绿色点),由角点对组成的边界框的中心区域(即粉色区域),可以判断一对角点的中心是否靠得足够近。
基于向心偏移,可以解码出左上角点和右下角点的中心点。然后计算每个满足条件的边界框的权重,就是说满足角点对的中心点均位于边界框的中心区域内。计算权重的式子是一个减函数,其中,分母是一个固定值(粉红区域),分子是所得候选角点对中心点的横纵坐标差的绝对值的乘积(即橙色区域),若是回归的中心点对越接近,计算得到的权重越大,对其他不满足条件的边界框则令权重 w = 0 w=0 w=0。
2.3 Cross-star Deformable Convolution
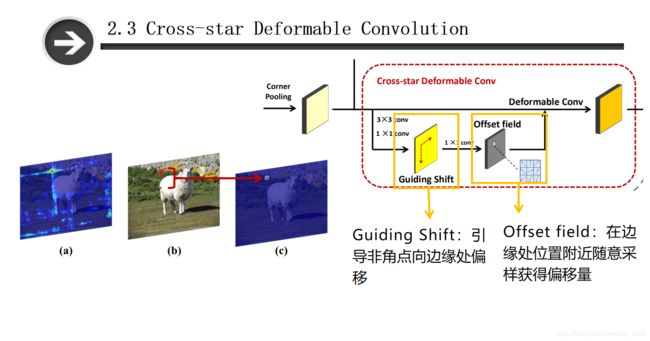
(a)由 corner pooling会产生一些“Cross star”。
(b)Cross star可变形卷积在角点处的采样点。
(c)角点预测模块(corner prediciton module)的左上角heatmap。
经过corner pooling会产生一些cross stars(交叉星),这些交叉星是通过最大值求和得到的,会包含大量的目标上下文信息。为了能够获得上下文信息,我们需要较大的感受野,并且需要学习交叉星的几何结构信息。为了解决这个问题,作者提出了Cross-star Deformable Convolution模块,用于增加角点的视觉特征。
由于左上角和右下角的步骤是一致的,只介绍左上角部分的操作。交叉星可变形卷积网络由两个部分组成,分别是引导偏移和偏移场。
Q:可变形卷积(deformable convolution)是什么呢?
A:标准卷积中的规则格点采样是导致网络难以适应几何形变的“罪魁祸首”。为了削弱这个限制,研究员们对卷积核中每个采样点的位置都增加了一个偏移的变量。通过这些变量,卷积核就可以在当前位置附近随意的采样,而不再局限于之前的规则格点。这样扩展后的卷积操作被称为可变形卷积(deformable convolution)。
2.3.1 Corner Pooling
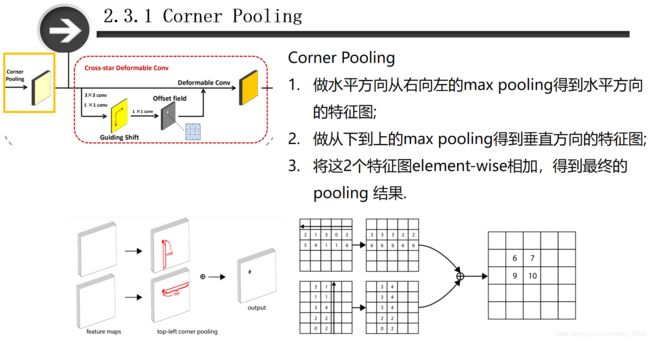
先说一下corner pooling的计算,先对特征图做水平方向从右向左的最大池化,得到特征图,之后在做从下到上的最大池化,得到特征图,最后将这两个特征图的每个像素值直接相加,得到特征图。
Q:为什么要Corner Pooling?
A:因为CornerNet是预测左上角和右下角两个角点,但是这两个角点在不同目标上没有相同规律可循,如果采用普通池化操作,那么在训练预测角点支路时会比较困难。考虑到左上角角点的右边有目标顶端的特征信息,左上角角点的下边有目标左侧的特征信息,因此如果左上角角点经过池化操作后能有这两个信息,那么就有利于该点的预测,这就有了corner pooling。总之就是从左上角点的角度出发:左上角角点的右边有目标顶端的特征信息,左上角角点的下边有目标左侧的特征信息。
2.3.2 Guiding shift
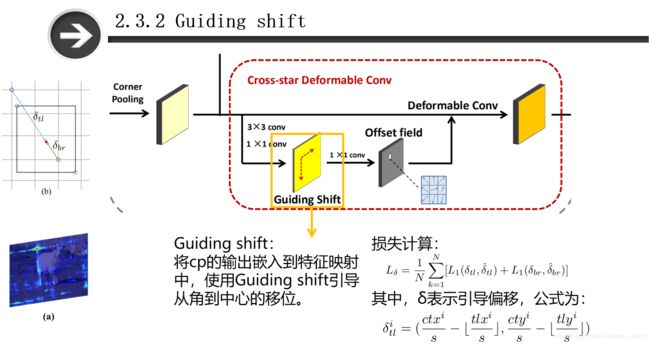
如图所示,Cross-star Deformable Convolution模块(简称“CDC”)是以corner pooling的结果作为输入,为了学习交叉点的几何信息,作者使用了相应目标的大小来引导偏移场的产生(偏移场是用于确定卷积核的形状)。以左上角为例,模型应该忽略交叉星的左上角区域(即该区域在目标之外),因此给模型加入一个引导偏移,(如左图)该偏移是从角点到中心点的移位,其包含了边界框的形状和方向信息,在偏移场中的方向信息可以引导角点和向心位移生成相应的中心点。可以看到偏移场由三个卷积层组成,前两个卷积层是以corner pooling的输出作为输入嵌入到特征图中,通过SmoothL1对这个损失函数 L δ L_{\delta } Lδ进行优化。
2.2.3 Offset field
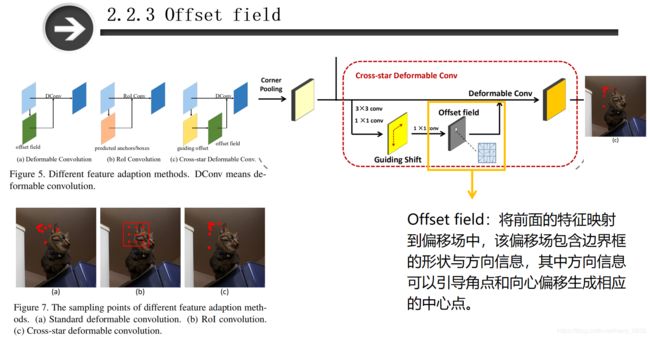
第三个卷积层的输入是引导偏移,输出是偏移场。 该偏移场是将前面得到的特征信息与corner pooling得到的角点信息进行融合,得到交叉星周围区域的几何信息,包括边界框的形状信息与方向信息。
图(c)是本文提出cross-star可变形卷积的结果。结合左边的图可以看出,这部分内容是基于标准可变形卷积来进行改进的,引入了引导偏移这一个模块。 论文提出的方法可以有效地获得交叉点的几何信息和交叉点的边缘位置信息,将处于物体上的信息偏移到角点的附近。(图(a)是标准的可变形卷积的采样结果,图(b)是RoI卷积的结果)
2.4 Instance Mask Head
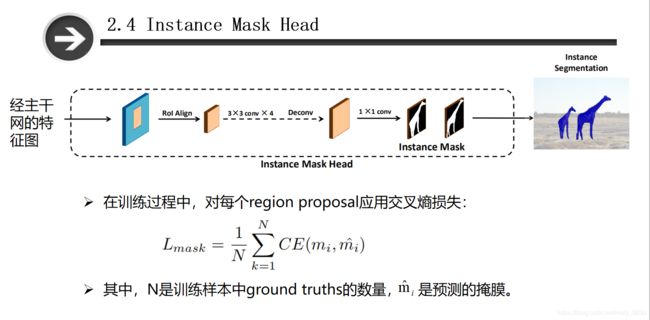
网络的最后一部分是介绍如何通过模型得到实例分割的结果。为了得到实例分割的掩膜,将送入soft-nms之前检测结果作为region proposal,并利用全卷积神经网络(FCN)对候选区域处理得到目标掩膜。 具体而言,为了得到候选区域,首先预训练几个 e p o c h epoch epoch的CentripetalNe产生一系列候选框。接着取分数前k的候选框作为RoIAlign的输入,并使用交叉熵损失函数来优化掩膜。由于CentripetalNet网络是端到端训练的,可以不加入实例掩码模块到目标检测中,并不会影响检测效果。
3、Experiments
3.1 Experimental Setting
下面是实验部分。

本篇论文是基于MS-COCO 2017数据集上进行的,在多任务的情况下,最终的目标函数如上图所示。
几个参数的含义:
p c i j p_{cij} pcij表示预测的heatmaps在第c个通道(类别c)的(i,j)位置的值;
y c i j y_{cij} ycij表示对应位置的ground truth;
N N N是图片中目标的总数;
y c i j = 1 y_{cij}=1 ycij=1时候的损失函数容易理解,就是focal loss,α参数用来控制难易分类样本的损失权重; y c i j y_{cij} ycij等于其他值时表示(i,j)点不是类别c的目标顶点,照理说此时 y c i j = 0 y_{cij}=0 ycij=0(大部分算法都是这样处理的),但是这里 y c i j ≠ 0 y_{cij}\neq 0 ycij=0,而是用基于ground truth顶点的高斯分布计算得到,因此距离ground truth比较近的(i,j)点的 y c i j y_{cij} ycij值接近1,这部分通过β参数控制权重,这是和focal loss的差别。
这里的offset是表示在取整计算时丢失的精度信息.
3.2 Comparison with state-of-the-art models
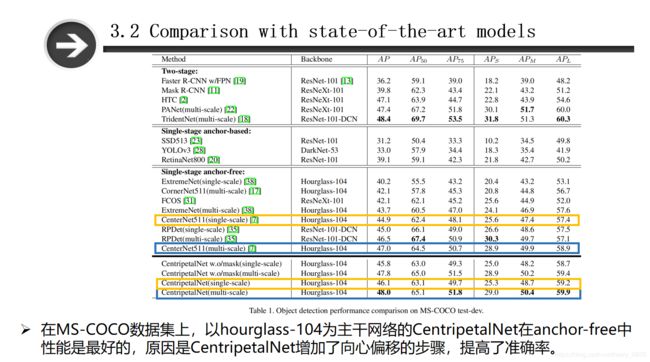
在MS-COCO数据集上,以hourglass-104为主干网络的模型来说,本篇论文提出的方法在anchor-free中的性能是最好的,其原因是增加了向心偏移模块,提高了角点配对的准确率。
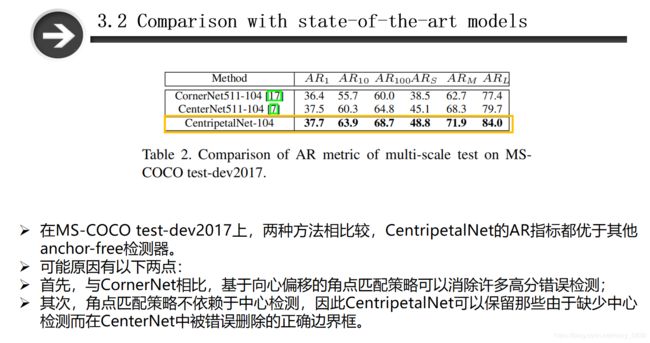
在MS-COCO test-dev2017上,两种方法相比较,CentripetalNet的AR指标都优于其他anchor-free检测器。
可能原因有以下两点:
- 与CornerNet相比,基于向心偏移的角点匹配策略可以消除许多高分错误检测;
- 角点匹配策略不依赖于中心检测,因此CentripetalNet可以保留那些由于缺少中心检测而在CenterNet中被错误删除的正确边界框。
(下面是实例分割实验的对比)
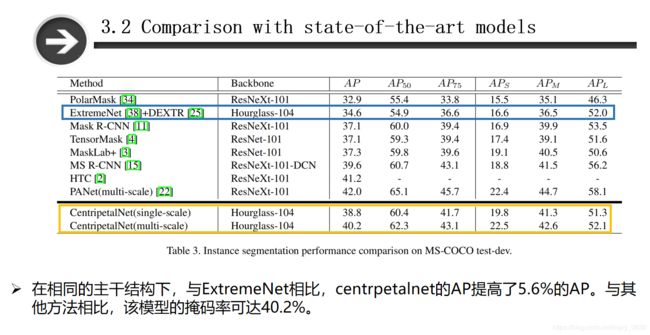
在相同的主干结构下,与ExtremeNet相比,centripetalnet的AP提高了5.6%的AP。与其他方法相比,该模型的掩码率可达40.2%。
3.3 Ablation study
3.3.1 Centripetal Shift
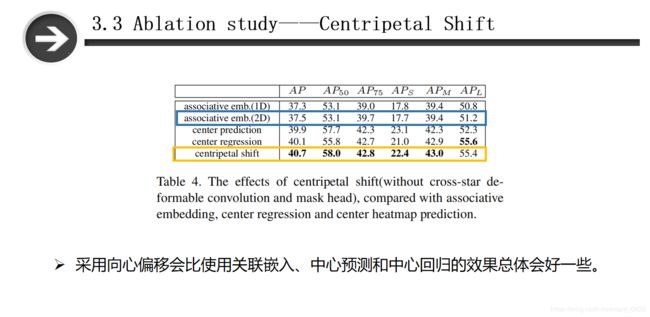
为了证明我们的向心偏移的有效性,用我们的向心偏移代替了CornerNet的关联嵌入(associative embedding),并使用了corner matching的匹配策略。 为了公平起见,并没有使用cross-star可变形卷积,并将关联嵌入的维数扩展到2维,这与向心偏移维数相同。基于向心偏移的方法为 CornerNet带来了巨大的性能提升。
3.3.2 Cross-star Deformable Convolution
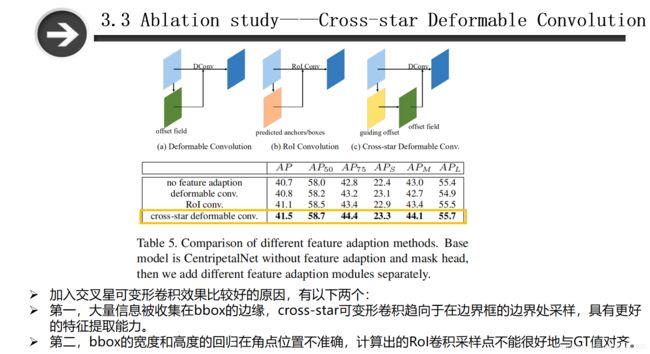
加入交叉星可变形卷积效果比较好的原因,有以下两个:
- 大量信息被收集在bbox的边缘,cross-star可变形卷积趋向于在边界框的边界处采样,具有更好的特征提取能力。
- bbox的宽度和高度的回归在角点位置不准确,计算出的RoI卷积采样点不能很好地与GT值对齐。
3.3.3 Instance Segmentation Module

加入mask head并没有提高AP值。在这种多任务学习对角点预测和联想嵌入预测的影响很小,但有利于预测我们的向心位移。如图所示,centrpetalnet可以生成精细的分割掩码。
3.4 Qualitative analysis
上面三行分别显示CornerNet,CenterNet和CentripetalNet的结果。 当相同类别的相似对象高度集中时,CornerNet和CenterNet的效果不佳。 但是,CentripetalNet可以处理这种情况。
4、Conclusions

5、References
https://blog.csdn.net/Skies_/article/details/105198601