Fixing Performance Problems - 2019.3 (性能优化——Unity 2019.3)
一旦你发现了游戏中的性能问题,你应该如何去解决它呢?
脚本、垃圾收集和图形呈现的一些常见问题和优化技术。
1.Optimizing scripts in Unity games 在unity中优化脚本
Introduction 当我们的游戏运行时,设备的中央处理器(CPU)执行指令。我们游戏的每一帧都需要执行数百万条CPU指令。 为了保持平滑的帧速率,CPU必须在规定的时间内执行指令。当CPU不能及时执行所有指令时,我们的游戏可能会变慢、卡顿或暂停。 许多事情会导致CPU有太多的工作要做。例子可能包括高要求的渲染代码,过于复杂的物理模拟或太多的动画回调。本文只关注其中一个原因:我们在脚本中编写的代码导致的CPU性能问题。 在本文中,我们将学习如何将脚本转换成CPU指令,什么会导致脚本为CPU生成过多的工作,以及如何修复脚本中的代码导致的性能问题。
Diagnosing problems with our code 诊断代码中的问题
对CPU的过度需求导致的性能问题可以表现为低帧速率、不稳定的性能或间歇性的死机。然而,其他问题也会引起类似的症状。如果我们的游戏有这样的性能问题,我们必须做的第一件事是使用Unity的分析器窗口来确定我们的性能问题是否是由于CPU不能及时完成它的任务。旦我们确定了这一点,我们必须确定是用户脚本导致了问题,还是问题是由游戏的其他部分引起的:例如复杂的物理或动画。 要学习如何使用Unity的Profiler窗口来查找性能问题的原因,请遵循Diagnosing Performance Problems - 2019.3。
A brief introduction to how Unity builds and runs our game 简单介绍Unity如何构建和运行我们的游戏 为了理解为什么我们的代码不能很好地执行,我们首先需要理解当Unity构建我们的游戏时会发生什么。了解幕后发生的事情将帮助我们做出明智的决定,即如何提高游戏的性能。构建过程当我们构建游戏时,Unity会将运行游戏所需的所有内容都打包到一个可以由我们的目标设备执行的程序中 。cpu只能运行用非常简单的语言编写的代码,即机器码或本机代码;它们不能运行用更复杂的语言(如c#)编写的代码。这意味着Unity必须将我们的代码翻译成其他语言。这个翻译过程称为编译。Unity首先把我们的脚本编译成一种叫做通用中间语言(CIL)的语言。CIL是一种很容易被编译成各种不同的本地代码语言的语言。然后,CIL被编译为我们特定目标设备的本地代码。第二步发生在我们构建游戏时(即所谓的提前编译或AOT编译),或者在目标设备本身上,即在代码运行之前(即所谓的just in time编译或JIT编译)。我们的游戏使用AOT还是JIT编译通常取决于目标硬件。(比如安卓是JIT PC端是AOT)
The relationship between the code we write and compiled code 我们编写的代码和编译的代码之间的关系 尚未编译的代码称为源代码。我们编写的源代码决定了编译后的代码的结构和内容。在大多数情况下,结构良好且高效的源代码将生成结构良好且高效的已编译代码。然而,对我们来说了解一些本机代码是很有用的,这样我们就可以更好地理解为什么有些源代码被编译成更有效的本机代码。首先,某些CPU指令的执行时间比其他指令长。这方面的一个例子是计算平方根。执行此计算所需的CPU时间比(例如)两个数字相乘所需的CPU时间要多。一条快速的CPU指令和一条缓慢的CPU指令之间的区别确实非常小,但它有助于我们理解,从根本上说,有些指令就是比其他指令快。我们需要理解的下一件事是,一些在源代码中看起来非常简单的操作,在编译为代码时可能会非常复杂。一个例子是将一个元素插入到一个列表中。执行此操作所需的指令要比(例如)按索引从数组中访问元素多得多。同样,当我们考虑一个单独的例子时,我们讨论的是很短的时间,但是重要的是要理解一些操作比其他操作产生更多的指令。理解这些思想将帮助我们理解为什么有些代码比其他代码执行得更好,即使这两个示例所做的事情非常相似。即使是对事物在较低水平下如何工作的有限背景理解也能够帮助我们编写出表现出色的游戏。 Run time communication between Unity Engine code and our script code 运行时通信Unity引擎代码和我们的脚本代码 对于我们来说,理解用c#编写的脚本与组成Unity引擎的代码以稍微不同的方式运行是很有用的。Unity引擎的大部分核心功能都是用c++编写的,并且已经编译为本地代码。这个编译后的引擎代码是我们安装Unity时安装的一部分。为CIL而编译的代码,如我们的源代码,被称为托管代码。当托管代码编译为本机代码时,它与所谓的托管运行时集成。托管运行时负责自动内存管理和安全检查等工作,以确保代码中的错误将导致异常而不是设备崩溃。当CPU在运行引擎代码和托管代码之间进行转换时,必须完成设置这些安全检查的工作。当将数据从托管代码传递回引擎代码时,CPU可能需要将数据从托管运行时使用的格式转换为引擎代码所需的格式。这种转换称为封送处理。同样,来自托管代码和引擎代码之间的任何单个调用的开销并不是特别昂贵,但重要的是我们要理解这种开销的存在。
The causes of poorly-performing code 导致代码性能不佳的原因
现在我们已经了解了当Unity构建并运行我们的游戏时我们的代码会发生什么,我们也能够理解当我们的代码执行得很糟糕时,那是因为它在运行时为CPU创造了太多的工作。让我们考虑一下不同的原因。第一种可能性是,我们的代码仅仅是浪费或者是结构糟糕。这方面的一个例子可能是,代码在只能调用一次的情况下重复调用同一个函数。本文将介绍几个常见的糟糕结构示例,并给出示例解决方案。第二种可能性是,我们的代码看起来结构很好,但是对其他代码进行了不必要的昂贵调用。这方面的一个例子可能是导致托管代码和引擎代码之间不必要的调用的代码。本文将给出一些Unity API调用的例子,这些调用可能会出乎意料的昂贵,但是建议使用一些更有效的替代方法。下一种可能性是,我们的代码是有效的,但它是在不必要的时候被调用的。这方面的一个例子可能是模拟敌人视线的代码。代码本身可能执行得很好,但在玩家离敌人很远的时候运行这段代码是很浪费的。本文包含的技术示例可以帮助我们编写只在需要时才运行的代码。最后一种可能是我们的代码要求太高了。这方面的一个例子可能是一个非常详细的模拟,其中大量的代理使用复杂的AI。 如果我们已经尝试了其他的可能性并尽可能地优化了这段代码,那么我们可能只需要重新设计我们的游戏以降低它的要求:例如,假装我们的模拟元素而不是计算它们。实现这种优化超出了本文的范围,因为它非常依赖于游戏本身,但阅读本文并考虑如何使我们的游戏尽可能地具有性能仍然对我们有好处。
Improving the performance of our code 改进代码的性能
一旦我们确定游戏中的性能问题是由于我们的代码造成的,我们就必须仔细考虑如何解决这些问题。优化一个要求很高的函数似乎是一个不错的起点,但问题中的函数可能已经是最优的了,而且从本质上来说,它的代价是昂贵的。而不是改变那个功能,可能有一个小的效率节省,我们可以在一个脚本中使用的数百个游戏对象,这给我们提供了一个更有用的性能提高。 上面这段的意思是可以做一个小的效率节省,这个脚本被数百个游戏对象使用,那么这将带来巨大的性能提高 。
此外,提高代码的CPU性能可能要付出代价:更改可能会增加内存使用量或将工作转移给GPU。由于这些原因,本文并不是一组简单的步骤。本文是一系列改进代码性能的建议,并提供了应用这些建议的示例。与所有性能优化一样,没有硬性的规则。最重要的事情是分析我们的游戏,理解问题的本质,尝试不同的解决方案并衡量我们的改变的结果
Writing efficient code 编写高效的代码
编写有效的代码并合理地组织代码能够提高游戏的性能。虽然所展示的例子是在Unity游戏的上下文中,但是这些通用的最佳实践建议并不是特定于Unity项目或Unity API调用的。
Move code out of loops when possible 尽可能的将代码移除循环
循环是效率低下的常见现象,特别是当它们被嵌套时。如果是在一个非常频繁运行的循环中,特别是在我们的游戏中的许多游戏对象中发现了这段代码,那么效率低下的问题就会增加。在下面的简单示例中,无论是否满足条件,我们的代码都会在每次调用Update()时遍历循环。
void Update()
{
for(int i = 0; i < myArray.Length; i++)
{
if(exampleBool)
{
ExampleFunction(myArray[i]);
}
}
}通过简单的更改,只有在满足条件时,代码才会遍历循环。
void Update()
{
if(exampleBool)
{
for(int i = 0; i < myArray.Length; i++)
{
ExampleFunction(myArray[i]);
}
}
}这是一个简单的例子,但它说明了我们可以真正节约。我们应该检查代码中循环结构不好的地方。考虑代码是否必须运行每一帧。Update()是一个由Unity每帧运行一次的函数。 Update()是放置需要频繁调用的代码或必须响应频繁更改的代码的方便位置。但是,并不是所有这些代码都需要运行每一帧。将代码移出Update()以便只在需要时才运行,这是提高性能的好方法。
Only run code when things change 只有在事情发生变化时才运行代码
让我们来看一个非常简单的优化代码的例子,以便只在事情发生变化时才运行它。在下面的代码中,在Update()中调用DisplayScore()。然而,分数的值可能不会随着每一帧的变化而变化。这意味着我们不必要地调用DisplayScore()。
private int score;
public void IncrementScore(int incrementBy)
{
score += incrementBy;
}
void Update()
{
DisplayScore(score);
}通过一个简单的更改,我们现在确保只在分数的值发生更改时调用DisplayScore()。
private int score;
public void IncrementScore(int incrementBy)
{
score += incrementBy;
DisplayScore(score);
}
同样,上面的例子是有意简化的,但原则是明确的。如果在我们的代码中应用这种方法,我们可能会节省CPU资源。
Run code every [x] frames 每X帧运行一次代码
如果代码需要频繁地运行,并且不能由事件触发,这并不意味着它需要运行每一帧。在这些情况下,我们可以选择每[x]帧运行一次代码。在本例代码中,一个昂贵的函数每帧运行一次。
void Update()
{
ExampleExpensiveFunction();
}事实上,每3帧运行一次代码就足够了。在下面的代码中,我们使用了模数运算符来确保昂贵的函数仅在每三帧上运行一次。
private int interval = 3;
void Update()
{
if(Time.frameCount % interval == 0)
{
ExampleExpensiveFunction();
}
}种技术的另一个好处是,可以很容易地将昂贵的代码分散到不同的帧上,避免出现峰值。在下面的例子中,每个函数每3帧调用一次,并且从不在同一帧上调用。
private int interval = 3;
void Update()
{
if(Time.frameCount % interval == 0)
{
ExampleExpensiveFunction();
}
else if(Time.frameCount % 1 == 1)
{
AnotherExampleExpensiveFunction();
}
}Use caching 使用缓存机制
如果我们的代码反复调用返回结果的昂贵函数,然后丢弃这些结果,这可能是一个优化的机会。存储和重用对这些结果的引用可能更有效。种技术称为缓存。在Unity中,通常调用GetComponent()来访问组件。在下面的示例中,我们在Update()中调用GetComponent()来访问一个呈现器组件,然后将其传递给另一个函数。这段代码可以工作,但是由于重复的GetComponent()调用,它的效率很低。
void Update()
{
Renderer myRenderer = GetComponent();
ExampleFunction(myRenderer);
} 面的代码只调用GetComponent()一次,因为函数的结果是缓存的。缓存的结果可以在Update()中重用,而无需进一步调用GetComponent()。
private Renderer myRenderer;
void Start()
{
myRenderer = GetComponent();
}
void Update()
{
ExampleFunction(myRenderer);
}
我们应该检查代码中频繁调用返回结果的函数的情况。我们可以通过使用缓存来降低这些调用的成本
Use the right data structure 使用正确的数据结构
我们如何构造数据对代码的执行有很大的影响。没有适合所有情况的单一数据结构,所以为了在游戏中获得最佳性能,我们需要为每个任务使用正确的数据结构。为了正确地决定使用哪种数据结构,我们需要了解不同数据结构的优缺点,并仔细考虑我们希望代码做什么。我们可能有数千个元素需要在每一帧上迭代一次,或者我们可能有少量元素需要频繁地添加和删除。这些不同的问题最好由不同的数据结构来解决。在这里做出正确的决定取决于我们对这个主题的知识。如果这是一个新的知识领域,最好的起点是学习大O符号。 大O符号是讨论算法复杂度的方式,理解它将帮助我们比较不同的数据结构。 This article is a clear and beginner-friendly guide to the subject.然后,我们可以更多地了解可用的数据结构,并对它们进行比较,以找到针对不同问题的正确数据解决方案。This MSDN guide to collections and data structures in C# 提供了选择适当数据结构的一般指导,并提供了到更深入文档的链接。关于数据结构的单一选择不太可能对我们的游戏产生很大的影响。然而,在一个包含大量此类集合的数据驱动游戏中,这些选择的结果实际上是可以累加的。理解算法的复杂性和不同数据结构的优缺点将帮助我们创建性能良好的代码。
Minimize the impact of garbage collection 最小化垃圾收集的影响
垃圾收集是Unity管理内存的一部分。我们的代码使用内存的方式决定了垃圾收集的频率和CPU成本,因此理解垃圾收集是如何工作的非常重要。在下一个步骤中,我们将深入讨论垃圾收集的主题,并提供几种不同的策略来最小化垃圾收集的影响。
Use object pooling 使用对象池
实例化和销毁一个对象通常比禁用和重新激活它的成本更高。如果对象包含启动代码,例如调用Awake()或Start()函数中的GetComponent(),则尤其如此。如果我们需要生成和处理相同对象的多个副本,比如射击游戏中的子弹,那么我们可能会从对象池中受益。对象池是一种技术,它不是创建和销毁对象的实例,而是临时停用对象,然后根据需要回收和重新激活对象。虽然众所周知,对象池是一种管理内存使用的技术,但它也可以作为一种减少过多CPU使用的技术。关于对象池的完整指南超出了本文的范围,但它确实是一种非常有用的技术,值得学习。This tutorial on object pooling on the Unity Learn site 是一个伟大的指南实现一个对象池系统在Unity。
Avoiding expensive calls to the Unity API 避免昂贵的调用Unity API
有时,我们的代码对其他函数或api的调用可能会出乎意料地昂贵。这可能有很多原因。看起来像变量的东西实际上可以是一个访问器。它包含附加代码、触发事件或从托管代码调用引擎代码。在这一节中,我们将会看到一些Unity API调用的例子,它们的代价比它们看起来的要高。:我们将考虑如何减少或避免这些费用。这些例子说明了成本的不同潜在原因,并且建议的解决方案可以应用于其他类似的情况。重要的是要明白没有一个Unity API调用的列表是我们应该避免的。 每个API调用在某些情况下有用,而在另一些情况下用处不大。在任何情况下,我们都必须仔细分析我们的游戏,找出导致昂贵代码的原因,并仔细思考如何以最适合我们游戏的方式解决问题。
SendMessage() 发送消息
SendMessage()和BroadcastMessage()是非常灵活的函数,它们几乎不需要了解项目的结构,并且实现起来非常快。因此,这些函数对于原型设计或初学者级别的脚本编写非常有用。然而,他们是非常昂贵的使用。这是因为这些函数利用了反射。反射是指代码在运行时(而不是在编译时)对自身进行检查和决策的术语。使用反射的代码比不使用反射的代码为CPU带来更多的工作。建议仅将SendMessage()和BroadcastMessage()用于原型设计,并尽可能使用其他函数。 例如,如果我们知道我们想要在哪个组件上调用一个函数,那么我们应该直接引用该组件并以这种方式调用该函数。如果我们不知道希望在哪个组件上调用函数,我们可以考虑使用事件或委托。 Find() Find()和相关函数功能强大,但代价昂贵。这些函数需要Unity来遍历内存中的每个GameObject和组件。这意味着它们在小型、简单的项目中不是特别有要求,但是随着项目复杂性的增长,它们的使用成本也会越来越高。最好不经常使用Find()和类似的函数,并尽可能缓存结果。一些简单的技术可以帮助我们减少代码中Find()的使用,包括在可能的情况下使用Inspector面板设置对对象的引用,或者创建脚本来管理对经常搜索的对象的引用。 Transform
设置transform 的位置或旋转将导致内部的OnTransformChanged事件传播到该转换的所有子事件。这意味着设置一个transform 的位置和旋转值相对比较昂贵,特别是在有很多子元素的变换中。为了限制这些内部事件的数量,我们应该避免不必要地频繁地设置这些属性的值。例如,我们可以执行一个计算来设置transform 的x位置,然后在Update()中执行另一个计算来设置transform 的z位置。在本例中,我们应该考虑将transform 的位置复制到Vector3,对该Vector3执行所需的计算,然后将transform 的位置设置为该Vector3的值。这只会导致一个OnTransformChanged事件。transform。position是一个在后台计算结果的访问器示例。这可以与Transform.localPosition相比较。localPosition的值存储在transform 和调用transform 中。localPosition只返回这个值。然而,每次调用transform .position时,都会计算transform的世界位置。如果我们的代码经常使用Transform.position ,然后使用transform 。这将减少CPU指令的数量,并最终提高性能。如果我们经常使用Transform.position,我们应该尽可能的缓存它。
Update() Update()、LateUpdate()和其他event functions 看起来很简单,但是它们有隐藏的开销。这些函数每次调用时都需要在引擎代码和托管代码之间进行通信。除此之外,在调用这些函数之前,Unity会执行一些安全检查。安全检查确保GameObject处于有效状态,没有被销毁,等等。这个开销对于任何一个单独的调用来说都不是特别大,但是对于一个有成千上万个单行为的游戏来说,这个开销是可以累加的。出于这个原因,空的Update()调用可能特别浪费。我们可以假设,因为函数是空的,并且我们的代码不包含对它的直接调用,所以空函数将不会运行。情况并非如此:在后台,即使Update()函数体为空,这些安全检查和本机调用仍然会发生。为了避免浪费CPU时间,我们应该确保游戏不包含空的Update()调用。如果我们的游戏有很多带有Update()调用的活动单行为,我们可能会从构建不同的代码来减少这种开销中受益。This Unity blog post on this subject goes into much more detail on this topic.
Vector2 and Vector3 我们知道,某些操作只会比其他操作产生更多的CPU指令。向量数学运算就是这样一个例子:它们只是比浮点运算或整型运算更复杂。尽管两种计算所花费的实际时间差别很小,但是在足够大的范围内,这种操作可以影响性能。使用Unity的Vector2和Vector3结构进行数学运算是很常见和方便的,特别是在处理转换的时候。如果我们在代码中执行许多频繁的Vector2和Vector3数学操作,例如在许多GameObjects的Update()中的嵌套循环中,我们可能会为CPU创建不必要的工作。在这些情况下,我们可以通过执行int或float计算来节省性能。在本文的前面,我们了解了执行平方根计算所需的CPU指令要比简单乘法的CPU指令慢。Both Vector2.magnitude and Vector3.magnitude are examples of this, as they both involve square root calculations. Additionally, Vector2.Distance and Vector3.Distance use magnitude behind the scenes。如果我们的游戏广泛而频繁地使用大小或距离,那么我们就有可能通过使用Vector2.sqrMagnitude 和Vector3.sqrMagnitude 来避免相对昂贵的平方根计算。同样,替换单个调用只会产生很小的差异,但是在足够大的范围内,可能会节省有用的性能。 Camera.main Camera.main 是一个方便的Unity API调用,它返回对第一个启用的摄像机组件的引用,该组件被标记为“main Camera”。这是另一个看起来像变量但实际上是附属品的例子。在本例中,访问器调用一个内部函数,类似于幕后的Find()。Camera.main, 因此,遇到了与Find()相同的问题:它搜索内存中的所有游戏对象和组件,并且使用起来非常昂贵。为了避免这种潜在的昂贵调用,我们应该缓存Camera.main的结果。主或避免它的使用完全和手动管理参考我们的相机。
Other Unity API calls and further optimizations 其他unity APi调用和进一步优化 们已经考虑了一些常见的Unity API调用的例子,它们可能会出乎意料的昂贵,并且了解了这种昂贵背后的不同原因。然而,这并不是一个提高Unity API调用效率的详尽方法列表。This article on performance in Unity 是一个关于Unity优化的内容广泛的指南,它包含了许多我们可能会发现有用的其他Unity API优化。另外,那篇文章深入讨论了进一步的优化,这超出了这篇相对高级的入门文章的范围。
Running code only when it needs to run 只在需要运行代码时才运行代码
编程中有句话:“最快的代码是不用运行的代码”。通常,解决性能问题最有效的方法不是使用一种高级技术:而是简单地删除一开始就不需要的代码。让我们看几个例子,看看我们可以在哪些地方进行这种节省。 Culling
Unity包含检查对象是否在摄像机的截锥体中的代码。如果它们不在摄像机的视锥体中,则与呈现这些对象相关的代码将不运行。这个术语叫做视锥体剔除。我们可以对脚本中的代码采取类似的方法。如果我们有一个与对象的可视状态相关的代码,我们可能不需要在玩家看不到对象时执行这个代码。在有许多对象的复杂场景中,这可能导致相当大的性能节省。在下面的简化示例代码中,我们有一个巡逻敌人的示例。每次调用Update()时,控制这个敌人的脚本都会调用两个示例函数:一个与移动敌人有关,另一个与它的可视状态有关。
void Update()
{
UpdateTransformPosition();
UpdateAnimations();
}在下面的代码中,我们现在检查敌人的渲染器是否在任何相机的截锥体中。与敌人的可视状态相关的代码只在敌人可见的情况下运行。
private Renderer myRenderer;
void Start()
{
myRenderer = GetComponent();
}
void Update()
{
UpdateTransformPosition();
if (myRenderer.isVisible)
{
UpateAnimations();
}
}
在玩家看不到的情况下禁用代码可以通过几种方式实现。如果我们知道场景中的某些对象在游戏中的特定点是不可见的,我们可以手动禁用它们。当我们不确定并且需要计算可见性时,我们可以使用一个粗略的计算(例如,检查玩家后面的对象),函数如OnBecameInvisible()和OnBecameVisible(),或者更详细的raycast。最好的实现在很大程度上取决于我们的游戏,而实验和分析是必不可少的。
Level of detail 细节层次
细节级别,也称为LOD,是另一种常见的渲染优化技术。离玩家最近的物体会使用详细的网格和纹理以完全保真的方式呈现。远处的物体使用较少细节的网格和纹理。我们的代码也可以使用类似的方法。例如,我们可能有一个敌人,它的AI脚本决定了它的行为。这种行为的一部分可能涉及昂贵的操作,以确定它可以看到和听到什么,以及它应该如何对这种输入做出反应。我们可以根据敌人与玩家的距离来使用一个详细的系统去启用或禁用这些昂贵的操作。在一个有许多敌人的场景中,如果最近的敌人正在执行最昂贵的操作,我们可以节省相当多的性能。Unity的 CullingGroup API允许我们连接到Unity的LOD系统来优化我们的代码。CullingGroup API的手册页面包含了一些如何在我们的游戏中使用它的例子.一如既往,我们应该测试,分析并找到适合我们游戏的解决方案。我们已经了解了当Unity游戏被构建并运行时我们所写的代码会发生什么,为什么我们的代码会导致性能问题,以及如何最小化游戏开销的影响。我们已经了解了代码中性能问题的一些常见原因,并考虑了一些不同的解决方案。利用这些知识和我们的分析工具,我们现在应该能够诊断、理解和修复游戏中与代码相关的性能问题。
2.Optimizing garbage collection in Unity games 优化垃圾回收
当我们的游戏运行时,它使用内存来存储数据。当不再需要此数据时,将释放存储该数据的内存,以便可以重用它。“垃圾”是指已经被用来存储数据但不再使用的内存。垃圾收集是使该内存再次可用以进行重用的进程的名称。
unity使用垃圾收集作为它管理内存的一部分。如果垃圾收集发生得太频繁或者有太多工作要做,我们的游戏可能会表现得很差,这意味着垃圾收集是导致性能问题的一个常见原因。 在本文中,我们将学习垃圾收集是如何工作的,什么时候发生垃圾收集,以及如何有效地使用内存,从而最小化垃圾收集对游戏的影响
Diagnosing problems with garbage collection 诊断垃圾收集的问题
由垃圾收集引起的性能问题可以表现为低帧速率、不稳定的性能或间歇性冻结。然而,其他问题也会引起类似的症状。如果我们的游戏有这样的性能问题,我们应该做的第一件事是使用Unity的Profiler窗口来确定我们所看到的问题是否真的是由于垃圾收集造成的。 要了解如何使用Profiler窗口查找性能问题的原因,请遵循 this tutorial.
A brief introduction to memory management in Unity 简单介绍unity中的内存管理
为了理解垃圾收集是如何工作的,以及当垃圾收集发生时,我们必须首先理解Unity中内存使用是如何工作的。首先,我们必须理解Unity在运行自己的核心引擎代码和运行我们在脚本中编写的代码时使用了不同的方式。
当Unity运行它自己的核心Unity引擎代码时,Unity管理内存的方式被称为手动内存管理。这意味着核心引擎代码必须显式地声明如何使用内存。手动内存管理不使用垃圾收集,本文将不再深入讨论。 当运行我们的代码时,Unity管理内存的方式被称为自动内存管理。这意味着我们的代码不需要明确地告诉Unity如何详细地管理内存。团结为我们解决了这个问题。 在最基本的层面上,Unity的自动内存管理是这样工作的:
1.Unity可以访问两个内存池:栈和堆(也称为托管堆)。栈用于小块数据的短期存储,而堆用于长期存储和大块数据。
2.当一个变量被创建时,Unity会从堆栈或堆中请求一块内存。
3.只要变量在作用域内(我们的代码仍然可以访问),分配给它的内存就仍然在使用中。我们说这个内存已经被分配了。我们将栈内存中的变量描述为栈上的对象,将堆内存中的变量描述为堆上的对象。
4.当变量超出作用域时,就不再需要内存,可以将其返回到它原来所在的池中。当内存被返回到它的池时,我们说内存已被释放。一旦所引用的变量超出作用域,栈中的内存就会被释放。但是,堆中的内存此时没有释放,并且仍然处于分配状态,即使它所引用的变量超出了作用域。
5.垃圾收集器标识和释放未使用的堆内存。垃圾收集器定期运行以清理堆。 现在我们已经了解了事件流,接下来让我们进一步了解栈的分配和释放,堆的分配和释放
What happens during stack allocation and deallocation? 在栈的分配和释放期间发生了什么 栈分配和释放是快速和简单的。这是因为栈只用于在短时间内存储小数据。分配和释放总是以可预测的顺序发生,并且具有可预测的大小。
栈的工作方式类似于栈数据类型:它是元素(在本例中是内存块)的简单集合,其中元素只能按严格的顺序添加和删除。这种简单性和严格性使它如此迅速:当一个变量存储在栈上时,它的内存只是从栈的“末端”分配。当栈变量超出范围时,用于存储该变量的内存将立即返回到栈中进行重用。
What happens during a heap allocation? 堆内存分配时发生了什么
堆分配比栈分配复杂得多。这是因为堆可用于存储长期和短期数据,以及许多不同类型和大小的数据。分配和回收并不总是以可预测的顺序发生,并且可能需要非常不同大小的内存块。 在创建堆变量时,需要执行以下步骤:
1.Unity必须检查堆中是否有足够的空闲内存。如果堆中有足够的空闲内存,则分配变量的内存。
2.如果堆中没有足够的空闲内存,Unity会触发垃圾收集器来释放未使用的堆内存。这可能是一个缓慢的操作。如果堆中现在有足够的空闲内存,则分配变量的内存。
3.如果在垃圾收集之后堆中没有足够的空闲内存,Unity会增加堆中的内存。这可能是一个缓慢的操作。然后分配变量的内存。 堆分配可能很慢,特别是在必须运行垃圾收集器和必须扩展堆的情况下。
What happens during garbage collection? 垃圾回收期间发生了什么
当堆变量超出作用域时,用于存储它的内存不会立即释放。未使用的堆内存仅在垃圾回收器运行时释放。 每次垃圾收集器运行时,都会执行以下步骤:
1.垃圾收集器检查堆上的每个对象。
2.垃圾收集器将搜索所有当前对象引用,以确定堆上的对象是否仍然在作用域中。
3.任何不在作用域中的对象都被标记为要删除。
4.被标记的对象被删除,分配给它们的内存被返回到堆。 垃圾收集可能是一项昂贵的操作。堆上的对象越多,它必须做的工作就越多,代码中的对象引用越多,它必须做的工作就越多。
When does garbage collection happen? 垃圾回收什么时候发生
有三种情况会导致垃圾收集器运行:
1.每当请求堆分配时,如果使用堆中的空闲内存无法完成,垃圾收集器就会运行。
2.垃圾收集器不时地自动运行(尽管频率随平台而变化)。
3.垃圾收集器可以强制手动运行。
垃圾收集可能是一个频繁的操作。当可用堆内存无法完成堆分配时,就会触发垃圾收集器,这意味着频繁的堆分配和回收可能会导致频繁的垃圾收集。
Problems with garbage collection
既然我们已经了解了垃圾收集在Unity内存管理中所扮演的角色,我们就可以考虑可能出现的问题类型了。 最明显的问题是垃圾收集器可能需要相当长的运行时间。如果垃圾收集器在堆上有很多对象和/或需要检查很多对象引用,那么检查所有这些对象的过程可能会很缓慢。这可能导致我们的游戏结巴或运行缓慢。
另一个问题是垃圾收集器可能在不方便的时间运行。如果CPU已经在游戏的性能关键部分努力工作了,那么即使垃圾收集带来的少量额外开销也会导致帧率下降和性能显著变化。 另一个不太明显的问题是堆碎片。当从堆中分配内存时,它是从空闲空间中根据必须存储的数据大小以不同大小块的形式分配的。当这些内存块返回到堆时,堆可以被分割成许多由分配的块分隔的小块。 这意味着,尽管空闲内存总量可能很高,但如果不运行垃圾收集器和/或扩展堆,我们就无法分配大内存块,因为现有的块都不够大。 碎片堆有两个后果。第一个是我们的游戏的内存使用将高于它所需要的,第二个是垃圾收集器将运行得更频繁。有关堆碎片的更详细讨论,请参阅this Unity best practice guide on performance.
Finding heap allocations 发现堆分配 如果我们知道垃圾收集在我们的游戏中造成了问题,我们需要知道代码的哪些部分正在生成垃圾。当堆变量超出范围时将生成垃圾,因此,首先,我们需要知道是什么原因导致在堆上分配变量。
What is allocated on the stack and the heap? 栈和堆上分配了什么
在Unity中,值类型的局部变量是在栈上分配的,其他的一切都是在堆上分配的。下面的代码是堆栈分配的一个示例,因为变量localInt是本地类型和值类型的。为该变量分配的内存将在该函数运行结束后立即从栈中释放。
void ExampleFunction()
{
int localInt = 5;
}
下面的代码是堆分配的一个示例,因为变量localList是本地的,但是是引用类型的。为该变量分配的内存将在垃圾收集器运行时释放。
void ExampleFunction()
{
List localList = new List();
}
Using the Profiler window to find heap allocations 使用profile窗口查找堆分配
我们可以使用Profiler窗口查看代码在何处创建堆分配。您可以通过转到窗口>分析>分析器来访问该窗口(图01)。
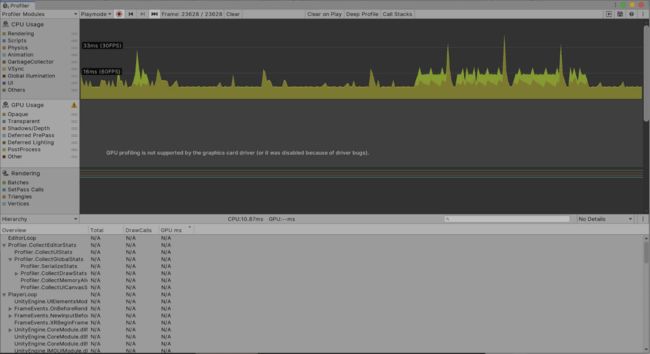
选择CPU使用情况分析器后,我们可以在分析器窗口的底部选择任何一帧来查看关于该帧的CPU使用情况数据。其中一列数据称为GC分配。这一列显示了在该帧中进行的堆分配。如果我们选择列标题,我们就可以根据这个统计数据对数据进行排序,这样就很容易看出游戏中哪些函数导致了最多的堆分配。一旦我们知道哪个函数导致堆分配,就可以检查该函数。 一旦我们知道了函数中的哪些代码会导致垃圾生成,我们就可以决定如何解决这个问题,并最小化生成的垃圾数量。
Reducing the impact of garbage collection 减少垃圾收集的影响
一般来说,我们可以通过以下三种方式来减少垃圾收集对游戏的影响:
1.我们可以减少垃圾收集器运行所需的时间
2.我们可以减少垃圾收集器运行的频率。
3.我们可以故意触发垃圾收集器,使其在非性能关键的时候运行,例如在加载屏幕期间。 考虑到这一点,这里有三个策略可以帮助我们:
1.我们可以组织我们的游戏,这样我们就有更少的堆分配和更少的对象引用。堆上的对象更少,需要检查的引用更少,这意味着触发垃圾收集时,运行所需的时间更少。
2.我们可以减少堆分配和释放的频率,特别是在性能关键时刻。更少的分配和回收意味着触发垃圾收集的机会更少。这也降低了堆碎片的风险。
3. 我们可以尝试对垃圾收集和堆扩展进行计时,以便在可预测和方便的时间进行。这是一种更困难、更不可靠的方法,但是当作为整体内存管理策略的一部分使用时,可以减少垃圾收集的影
Reducing the amount of garbage created 减少产生的垃圾数量
Caching 缓存
如果我们的代码反复调用导致堆分配的函数,然后丢弃结果,这将创建不必要的垃圾。相反,我们应该存储对这些对象的引用并重用它们。这种技术称为缓存。 在下面的示例中,每次调用该代码都会导致堆分配。这是因为创建了一个新数组。
void OnTriggerEnter(Collider other)
{
Renderer[] allRenderers = FindObjectsOfType();
ExampleFunction(allRenderers);
} 下面的代码只导致一个堆分配,因为数组只创建和填充一次,然后缓存。缓存的数组可以反复使用,而不会产生更多的垃圾。
private Renderer[] allRenderers;
void Start()
{
allRenderers = FindObjectsOfType();
}
void OnTriggerEnter(Collider other)
{
ExampleFunction(allRenderers);
}
Don’t allocate in functions that are called frequently 不要在频繁调用的函数中进行分配
如果必须在MonoBehaviour中分配堆内存,最糟糕的情况是在频繁运行的函数中。例如,Update()和LateUpdate()每帧调用一次,因此,如果我们的代码在这里生成垃圾,那么它很快就会累积起来。我们应该考虑在可能的情况下缓存对Start()或Awake()中的对象的引用,或者确保导致分配的代码只在需要的时候运行。
让我们来看一个非常简单的移动代码的例子,这样它只在事情发生变化时才会运行。在下面的代码中,每次调用Update()都会调用一个导致分配的函数,从而频繁地创建垃圾:
void Update()
{
ExampleGarbageGeneratingFunction(transform.position.x);
}通过一个简单的更改,我们现在可以确保只有在transform.position的值发生变化时才调用分配函数。x已经改变了。我们现在只在必要时进行堆分配,而不是在每一帧中进行。
private float previousTransformPositionX;
void Update()
{
float transformPositionX = transform.position.x;
if (transformPositionX != previousTransformPositionX)
{
ExampleGarbageGeneratingFunction(transformPositionX);
previousTransformPositionX = transformPositionX;
}
}减少Update()中生成的垃圾的另一种技术是使用计时器。这适用于生成垃圾的代码必须定期运行,但不一定是每一帧。 在下面的示例代码中,生成垃圾的函数每帧运行一次:
void Update()
{
ExampleGarbageGeneratingFunction();
}在下面的代码中,我们使用一个计时器来确保生成垃圾的函数每秒运行一次
private float timeSinceLastCalled;
private float delay = 1f;
void Update()
{
timeSinceLastCalled += Time.deltaTime;
if (timeSinceLastCalled > delay)
{
ExampleGarbageGeneratingFunction();
timeSinceLastCalled = 0f;
}
}对频繁运行的代码进行这样的小更改时,可以极大地减少生成的垃圾数量。
Clearing collections 清除集合
创建新的集合会导致堆上的分配。如果我们发现在代码中不止一次地创建新集合,那么应该缓存对集合的引用,并使用Clear()清空其内容,而不是重复调用new。 在下面的示例中,每次使用new时都会发生新的堆分配。
void Update()
{
List myList = new List();
PopulateList(myList);
}在下面的示例中,仅在创建集合或必须在后台调整集合大小时才进行分配。这大大减少了生成的垃圾数量。
private List myList = new List();
void Update()
{
myList.Clear();
PopulateList(myList);
}Object pooling 对象池
即使我们在脚本中减少了分配,如果我们在运行时创建和销毁了很多对象,我们仍然会有垃圾收集问题。对象池是一种通过重用对象而不是重复创建和销毁对象来减少分配和回收的技术。对象池在游戏中被广泛使用,最适合我们频繁产生和破坏相似对象的情况;例如,当从枪中射出子弹时 关于对象池的完整指南超出了本文的范围,但它确实是一种非常有用的技术,值得学习。本教程的对象池在https://learn.unity.com/tutorial/introduction-to-object-pooling-2019-3?language=en
Common causes of unnecessary heap allocations 不必要的堆分配的常见原因 我们知道局部的、值类型的变量是在栈上分配的,而其他的一切都是在堆上分配的。然而,在很多情况下,堆分配可能会让我们感到意外。让我们来看看一些造成不必要的堆分配的常见原因,并考虑如何最好地减少这些因素。
Strings 字符串
在c#中,字符串是引用类型,而不是值类型,即使它们似乎包含字符串的“值”。这意味着创建和丢弃字符串会产生垃圾。由于字符串在很多代码中都是常用的,所以这种垃圾真的会越来越多。 c#中的字符串也是不可变的,这意味着它们的值在第一次创建之后不能改变。每次我们操作一个字符串(例如,通过使用+运算符连接两个字符串),Unity都会创建一个新字符串,并使用更新后的值丢弃旧的字符串。这就产生了垃圾。 我们可以遵循一些简单的规则来将字符串中的垃圾降到最低。让我们考虑一下这些规则,然后看一个如何应用它们的示例。 1.我们应该减少不必要的字符串创建。如果我们多次使用同一个字符串值,我们应该创建该字符串一次并缓存该值。
2.我们应该减少不必要的字符串操作。例如,如果我们有一个经常更新的文本组件,并且包含一个连接的字符串,那么我们可以考虑将它分成两个文本组件。
3.如果我们必须在运行时构建字符串,我们应该使用StringBuilder类。StringBuilder类是为构建没有分配的字符串而设计的,它将节省连接复杂字符串时产生的垃圾数量。
4.如果我们必须在运行时构建字符串,我们应该使用StringBuilder类。StringBuilder类是为构建没有分配的字符串而设计的,它将节省连接复杂字符串时产生的垃圾数量。 让我们检查一个代码示例,该代码通过低效地使用字符串生成不必要的垃圾。在下面的代码中,我们通过结合字符串“TIME:”和浮动计时器的值来为Update()中显示的分数创建一个字符串。这会产生不必要的垃圾。
public Text timerText;
private float timer;
void Update()
{
timer += Time.deltaTime;
timerText.text = "TIME:" + timer.ToString();
}在下面的例子中,我们已经大大改进了事情。我们将单词“TIME:”放在一个单独的文本组件中,并在Start()设置它的值。这意味着在Update()中,我们不再需要组合字符串。这大大减少了生成的垃圾数量。
public Text timerHeaderText;
public Text timerValueText;
private float timer;
void Start()
{
timerHeaderText.text = "TIME:";
}
void Update()
{
timerValueText.text = timer.toString();
}
Unity function calls Unity函数调用
当我们调用我们自己没有写的代码时,不管是在Unity本身还是在插件中,我们都可能产生垃圾,这一点很重要。一些Unity函数调用会创建堆分配,因此应该谨慎使用,以避免生成不必要的垃圾。 没有我们应该避免的函数列表。每个函数在某些情况下有用,在另一些情况下不太有用。和以往一样,最好仔细分析我们的游戏,识别垃圾是在哪里产生的,并仔细考虑如何处理它。在某些情况下,缓存函数的结果可能是明智的;在其他情况下,更少地调用函数可能是明智的;在其他情况下,最好重构代码以使用不同的函数。说了这些之后,让我们看几个导致堆分配的Unity函数的常见示例,并考虑如何最好地处理它们。 每次我们访问一个返回数组的Unity函数时,都会创建一个新的数组并将其作为返回值传递给我们。这种行为并不总是明显的或预期的,特别是当函数是一个访问器时(例如Mesh.normals)。 访问器即get
在下面的代码中,将为循环的每个迭代创建一个新数组。
void ExampleFunction()
{
for (int i = 0; i < myMesh.normals.Length; i++)
{
Vector3 normal = myMesh.normals[i];
}
}3.Optimizing garbage collection in Unity games
在这种情况下很容易减少分配:我们可以简单地缓存对数组的引用。当我们这样做时,只创建一个数组,所创建的垃圾数量也相应减少。 下面的代码演示了这一点。在这种情况下,我们称之为网格。在循环运行和缓存引用之前进行法线运算,以便只创建一个数组。
void ExampleFunction()
{
Vector3[] meshNormals = myMesh.normals;
for (int i = 0; i < meshNormals.Length; i++)
{
Vector3 normal = meshNormals[i];
}
}堆分配的另一个意外原因可以在函数GameObject.name或GameObject.tag中找到。这两个访问器都返回新的字符串,这意味着调用这些函数将产生垃圾。缓存值可能很有用,但是在这种情况下,我们可以使用一个相关的Unity函数。为了在不产生垃圾的情况下检查GameObject.tag()的值,我们可以使用GameObject. comparetag()。 在下面的示例代码中,垃圾是通过调用GameObject.tag来创建的:
private string playerTag = "Player";
void OnTriggerEnter(Collider other)
{
bool isPlayer = other.gameObject.tag == playerTag;
}如果我们使用GameObject.CompareTag(),这个函数将不再生成任何垃圾:
private string playerTag = "Player";
void OnTriggerEnter(Collider other)
{
bool isPlayer = other.gameObject.CompareTag(playerTag);
}GameObject.CompareTag不是唯一的;许多Unity函数调用都有替代版本,它们不会导致堆分配。For example, we could use Input.GetTouch() and Input.touchCount in place of Input.touches, or Physics.SphereCastNonAlloc() in place of Physics.SphereCastAll().
Boxing 装箱
装箱是指当使用值类型变量代替引用类型变量时所发生的情况。装箱通常发生在我们将值类型的变量(如int或float)传递给带有对象参数(如object . equals())的函数时。 例如,函数string . format()接受一个字符串和一个对象参数。当我们给它传递一个字符串和一个整数时,这个整数必须被装箱。因此,下面的代码包含一个装箱的例子:
void ExampleFunction()
{
int cost = 5;
string displayString = String.Format("Price: {0} gold", cost);
}由于在幕后发生的事情,装箱产生了垃圾。当一个值类型的变量被装箱时,Unity会创建一个临时系统。对象包装值类型的变量。一个System.Object 是引用类型的变量,因此当这个临时对象被释放时,就会产生垃圾。 装箱是造成不必要的堆分配的一个非常常见的原因。即使我们不直接在代码中封装变量,我们也可能使用导致装箱的插件,或者它可能在其他函数的后台发生。最佳实践是尽可能避免装箱,并删除导致装箱的任何函数调用。
Coroutines 协同程序
调用StartCoroutine()会产生少量垃圾,因为Unity必须创建类的实例来管理协同程序。考虑到这一点,对StartCoroutine()的调用应该是有限的,而我们的游戏是交互式的,性能是一个问题。为了减少以这种方式创建的垃圾,必须在性能关键时刻运行的任何协程都应该提前启动,并且在使用嵌套的协程时应该特别小心,因为嵌套的协程可能包含对StartCoroutine()的延迟调用。 协程中的yield语句本身并不创建堆分配;但是,我们在yield语句中传递的值可能会创建不必要的堆分配。例如,下面的代码创建垃圾:
yield return 0;
这段代码创建了垃圾,因为值为0的int被装箱了。在这种情况下,如果我们希望在不引起任何堆分配的情况下简单地等待一个帧,最好的方法是使用以下代码:
yield return null;
协同程序的另一个常见错误是在不止一次产生相同的值时使用new。例如,下面的代码将在每次循环迭代时创建并释放一个WaitForSeconds对象:
while (!isComplete)
{
yield return new WaitForSeconds(1f);
}如果我们缓存并重用WaitForSeconds对象,那么创建的垃圾就会少得多。下面的代码显示了一个例子
WaitForSeconds delay = new WaitForSeconds(1f);
while (!isComplete)
{
yield return delay;
}如果我们的代码由于协程而产生了大量的垃圾,我们可能会考虑重构我们的代码来使用协程以外的其他东西。重构代码是一个复杂的主题,每个项目都是独特的,但是我们可能希望记住协程的一些常见替代方案。例如,如果我们主要使用协程来管理时间,我们可能希望简单地在Update()函数中跟踪时间。如果我们主要使用协同程序来控制游戏中事件发生的顺序,我们可能希望创建某种消息传递系统来允许对象进行通信。 对于这个问题,没有一种万能的方法,但是要记住,通常有多种方法可以在代码中实现相同的事情,记住这一点是很有用的。
Foreach loops 在Unity 5.5之前的版本中,foreach循环在数组以外的任何地方迭代,每次循环终止时都会生成垃圾。这是由于装箱发生在幕后。一个System.Object 在循环开始时在堆上分配,在循环终止时释放。这个问题在Unity 5.5中得到了解决。例如,在Unity 5.5之前的版本中,下面代码中的循环会产生垃圾:
void ExampleFunction(List listOfInts)
{
foreach (int currentInt in listOfInts)
{
DoSomething(currentInt);
}
}只要你有Unity 2019.3你是安全的,但如果我们不能升级我们的Unity版本,有一个简单的解决方案。for和while循环不会导致后台装箱,因此不会生成任何垃圾。当迭代非数组的集合时,我们应该支持使用它们 下面代码中的循环不会产生垃圾:
void ExampleFunction(List listOfInts)
{
for (int i = 0; i < listOfInts.Count; i ++)
{
int currentInt = listOfInts[i];
DoSomething(currentInt);
}
}Function references 函数引用
对函数的引用,无论是引用匿名方法还是命名方法,在Unity中都是引用类型的变量。它们将导致堆分配。将匿名方法转换为闭包(其中匿名方法在创建时可以访问范围内的变量)会显著增加内存使用和堆分配的数量。 函数引用和闭包如何分配内存的具体细节取决于平台和编译器设置,但如果垃圾收集是一个问题,那么最好在游戏过程中尽量减少函数引用和闭包的使用。https://docs.unity3d.com/Manual/BestPracticeUnderstandingPerformanceInUnity4-1.html?_ga=2.173677475.1457923406.1588487957-163088388.1588307012 将更详细地介绍这个主题的技术细节
LINQ and Regular Expressions LINQ和正则表达式
LINQ和正则表达式都会产生垃圾,因为装箱是在幕后进行的。最好的做法是在涉及到性能的情况下避免使用它们。
Structuring our code to minimize the impact of garbage collection
构造代码以最小化垃圾收集的影响
我们代码的结构方式可能会影响垃圾收集。即使我们的代码没有创建堆分配,它也会增加垃圾收集器的工作负载。 我们的代码可能不必要地增加垃圾收集器的工作负载的一种方法是,要求它检查不应该检查的东西。结构体是值类型的变量,但是如果我们的结构体包含引用类型的变量,那么垃圾收集器必须检查整个结构体。如果我们有大量的这些结构,那么这会为垃圾收集器创建大量的额外工作。 在本例中,结构体包含一个字符串,它是引用类型的。垃圾收集器现在必须在运行时检查整个结构数组。
public struct ItemData
{
public string name;
public int cost;
public Vector3 position;
}
private ItemData[] itemData;在本例中,我们将数据存储在单独的数组中。当垃圾收集器运行时,它只需要检查字符串数组,可以忽略其他数组。这减少了垃圾收集器必须做的工作
private string[] itemNames;
private int[] itemCosts;
private Vector3[] itemPositions;
我们的代码不必要地增加垃圾收集器工作负载的另一种方式是使用不必要的对象引用。当垃圾收集器在堆中搜索对对象的引用时,它必须检查代码中的每个当前对象引用。代码中的对象引用越少,意味着要做的工作就越少,即使我们不减少堆上的对象总数。 在本例中,我们有一个填充对话框的类。当用户查看对话框时,将显示另一个对话框。我们的代码包含了一个对下一个应该显示的DialogData实例的引用,这意味着垃圾收集器必须在它的操作中检查这个引用:
public class DialogData
{
private DialogData nextDialog;
public DialogData GetNextDialog()
{
return nextDialog;
}
}在这里,我们重新构造了代码,以便它返回一个标识符,该标识符用于查找下一个DialogData实例,而不是实例本身。这不是一个对象引用,因此不会增加垃圾收集器所花费的时间。
public class DialogData
{
private int nextDialogID;
public int GetNextDialogID()
{
return nextDialogID;
}
}就其本身而言,这个示例相当简单。但是,如果我们的游戏包含大量的对象,这些对象包含对其他对象的引用,那么我们可以通过以这种方式重组代码来大大降低堆的复杂性。
Timing garbage collection 垃圾收集时间
Manually forcing garbage collection 手动强制垃圾收集
最后,我们可能希望自己触发垃圾收集。如果我们知道堆内存被分配,但不再使用(例如,我们的代码在加载资源产生垃圾)而且我们知道垃圾收集冻结不会影响玩家(例如,当加载界面仍然显示)我们可以使用以下代码请求垃圾回收:
System.GC.Collect(); 这将强制垃圾收集器运行,在我们方便的时候释放未使用的内存。 我们已经学习了在Unity中垃圾收集是如何工作的,为什么它会导致性能问题,以及如何最小化垃圾收集对游戏的影响。利用这些知识和我们的分析工具,我们可以修复与垃圾收集相关的性能问题,并构建我们的游戏,以使它们能够有效地管理内存。
4.Optimizing graphics rendering in Unity games 优化unity中的图形渲染
Introduction 在这篇文章中,我们将学习Unity渲染一个帧时会发生什么,在渲染时会出现什么样的性能问题,以及如何修复与渲染相关的性能问题。 在阅读这篇文章之前,有一点很重要,那就是没有一种万能的方法可以提高渲染性能。渲染性能受到游戏内部许多因素的影响,同时也高度依赖于游戏所运行的硬件和操作系统。最重要的是要记住,我们通过调查、实验和严格分析实验结果来解决性能问题。 本文包含关于最常见的呈现性能问题的信息,以及如何修复这些问题的建议和进一步阅读的链接。我们的游戏可能会有一个问题——或者是一系列问题——在这里没有涉及。然而,这篇文章仍然会帮助我们理解我们的问题,并给我们知识和词汇来有效地寻找解决方案。
A brief introduction to rendering 渲染的简单介绍
在我们开始之前,让我们快速地简单地看一下Unity渲染一个帧时会发生什么。理解事件流和事物的正确术语将帮助我们理解、研究和解决性能问题。 在最基本的层面,渲染可以描述如下:
1.中央处理器,即CPU,计算出必须绘制什么以及如何绘制。
2.CPU向图形处理单元(即GPU)发送指令
3.GPU根据CPU的指令来绘制图形。 现在让我们仔细看看发生了什么。我们将在本文后面更详细地介绍这些步骤,但是现在,让我们先熟悉一下所用的单词,并理解CPU和GPU在呈现中所扮演的不同角色。 经常用来描述渲染的短语是渲染管道,这是一个需要记住的有用图像;高效的渲染是关于保持信息流动的。
1.对于每一帧渲染,CPU做以下工作: CPU检查场景中的每个对象,以确定是否应该呈现它。只有符合特定条件的对象才被呈现;例如,它的边界框的某些部分必须位于摄像机的视锥框内。不被渲染的对象被称为被剔除。有关视锥体和视锥体剔除的更多信息,请参见此页。this page.
2.CPU收集关于将要呈现的每个对象的信息,并将这些数据排序到称为draw call的命令中。draw调用包含关于单个网格的数据以及该网格应该如何呈现;例如,应该使用哪些纹理。在某些情况下,共享设置的对象可以合并到同一个draw调用中。将不同对象的数据组合到同一个draw调用中称为批处理
3.CPU为每个draw调用创建一个称为批处理的数据包。批处理有时可能包含调用之外的数据,但这些情况不太可能导致常见的性能问题,因此本文不会考虑这些问题。 对于每一个包含draw call的批处理,CPU现在必须执行以下操作:
1.CPU可以向GPU发送一个命令来改变一些变量,这些变量统称为渲染状态。此命令称为SetPass调用。一个SetPass调用告诉GPU使用哪个设置来渲染下一个网格。只有当要呈现的下一个网格需要对前一个网格的呈现状态进行更改时,才会发送SetPass调用
2.CPU将draw调用发送给GPU。draw调用指示GPU使用最近一次SetPass调用中定义的设置来渲染指定的网格。
3. 在某些情况下,可能需要一次以上的批处理。一个通道是一段着色器代码,一个新的通道需要改变渲染状态。对于批处理中的每个传递,CPU必须发送一个新的SetPass调用,然后必须再次发送draw调用。 同时,GPU做以下工作:
1.GPU按照发送任务的顺序处理来自CPU的任务
2.如果当前任务是一个SetPass调用,GPU会更新渲染状态
3.如果当前任务是绘制调用,GPU渲染网格。这是分阶段进行的,由着色器代码的单独部分定义。这部分呈现是复杂的,我们不会详细讨论它,但它有助于我们理解这一段代码被称为顶点着色器告诉GPU如何处理网格的顶点,然后一段代码称为片段着色器告诉GPU如何画出每个像素。
4. 这个过程不断重复,直到所有从CPU发送的任务都被GPU处理完。 现在我们已经了解了Unity渲染一个帧时发生了什么,让我们来考虑一下渲染时可能出现的问题。
Types of rendering problems 渲染问题的类型
关于渲染最重要的一点是:为了渲染帧,CPU和GPU都必须完成它们的所有任务。如果这些任务中的任何一个需要太长时间才能完成,就会导致帧的呈现延迟。 渲染问题有两个根本原因。第一类问题是由低效的管道引起的。当渲染管道中的一个或多个步骤耗时过长而无法完成时,就会出现低效的管道,从而中断数据的流畅流动。管道内的低效被称为瓶颈。第二种类型的问题是由于试图通过管道推送太多的数据而导致的。即使是最有效的管道,在一帧中所能处理的数据量也是有限的。
当我们的游戏花了太长时间去渲染一帧是因为CPU花了太长时间去执行它的渲染任务,我们的游戏就是所谓的CPU瓶颈
当我们的游戏花了太长时间去渲染一帧是因为GUP花了太长时间去执行它的渲染任务,我们的游戏就是所谓的GPU瓶颈
Understanding rendering problems 理解渲染问题
在进行任何更改之前,使用分析工具来了解性能问题的原因是非常重要的。不同的问题需要不同的解决方案。衡量我们所做的每一项改变的影响也是非常重要的;修复性能问题是一种平衡行为,改进性能的一个方面可能会对另一个方面产生负面影响 我们将使用两个工具来帮助我们理解和修复渲染性能问题:Profiler窗口和框架调试器。这两个工具都内置在Unity中。
The Profiler window 分析器窗口
Profiler窗口允许我们查看关于游戏执行情况的实时数据。我们可以使用Profiler窗口查看游戏的许多方面的数据,包括内存使用、呈现管道和用户脚本的性能。this page of the Unity Manual is a good introduction.
The Frame Debugger 帧调试器
帧调试器允许我们一步一步地查看一帧是如何呈现的。使用帧调试器,我们可以看到详细的信息,如在每次绘制调用期间绘制什么,每个绘制调用的着色器属性和发送到GPU的事件顺序。这些信息帮助我们理解游戏是如何呈现的,以及我们可以在哪里提高性能。If you are not yet familiar with using the Frame Debugger, this page of the Unity Manual is a very useful guide to what it does and this tutorial video shows it in use.
Finding the cause of performance problems 查找性能问题的原因
在我们尝试提高游戏的渲染性能之前,我们必须确定我们的游戏由于渲染问题而运行缓慢。如果问题的真正原因是过于复杂的用户脚本,那么尝试优化我们的渲染性能是没有意义的! 一旦我们确定我们的问题与渲染有关,我们也必须了解我们的游戏是CPU绑定还是GPU绑定。这些不同的问题需要不同的解决方案,所以在试图解决问题之前,了解问题的原因是至关重要的。如果你还不确定你的游戏是CPU绑定还是GPU绑定,你应该遵循this tutorial. 如果我们确定我们的问题与渲染有关,并且我们知道我们的游戏是CPU绑定还是GPU绑定,我们就可以继续阅读了。
If our game is CPU bound 如果我们的游戏是CPU瓶颈 一般来说,CPU渲染帧所必须完成的工作分为三类:
1.决定要绘制什么
2.为GPU准备命令
3.向GPU发送命令
这些广泛的类别包含许多单独的任务,这些任务可以跨多个线程执行。线程允许独立的任务同时发生;当一个线程执行一个任务时,另一个线程可以执行一个完全独立的任务。这意味着工作可以更快地完成。
当渲染任务被分割到不同的线程时,这称为多线程渲染。 在Unity的渲染过程中有三种类型的线程:主线程,渲染线程和工作线程。主线程是我们游戏中大部分CPU任务发生的地方,包括一些渲染任务。渲染线程是一个专门向GPU发送命令的线程。每个工作线程执行单个任务,例如筛选或网格剥皮。哪些任务由哪个线程执行取决于游戏的设置和游戏运行的硬件。例如,我们的目标硬件拥有的CPU内核越多,可以产生的工作线程就越多。因此,在目标硬件上介绍我们的游戏非常重要;我们的游戏可能在不同的设备上执行非常不同。 因为多线程渲染是复杂的,并且依赖于硬件,所以在我们尝试提高性能之前,我们必须了解是哪些任务导致我们的游戏受到CPU的限制。如果我们的游戏运行缓慢,因为剔除操作在一个线程上花费的时间太长,那么它将不能帮助我们减少在不同线程上向GPU发送命令的时间。 注:不是所有的平台都支持多线程渲染;在撰写本文时,WebGL不支持此功能。在不支持多线程呈现的平台上,所有CPU任务都在同一个线程上执行。如果我们被CPU限制在这样的平台上,优化任何CPU工作都将提高CPU性能。如果我们的游戏是这种情况,我们应该阅读下面的所有章节并考虑哪些优化最适合我们的游戏。
Graphics jobs 图形工作
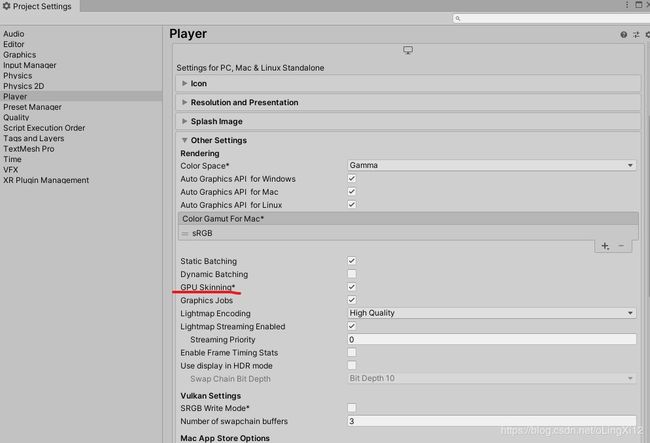
播放器设置中的图形作业选项决定了Unity是否使用工作线程来执行渲染任务,而这些任务本来是在主线程上完成的,在某些情况下,是在渲染线程上完成的。在提供该特性的平台上,它可以提供相当大的性能提升。如果我们希望使用这个特性,我们应该在启用和不启用图形作业的情况下对游戏进行配置,并观察它对性能的影响。
Finding out which tasks are contributing to problems 找出那些任务导致了问题
我们可以通过使用Profiler窗口来确定是哪些任务导致我们的游戏受到CPU的限制。本教程将展示如何确定问题所在。 现在我们已经了解了是哪些任务导致我们的游戏受到CPU限制,让我们来看看一些常见的问题及其解决方案。
Sending commands to the GPU 向GPU发送命令
向GPU发送命令所花费的时间是游戏受CPU限制的最常见原因。此任务在大多数平台上的渲染线程上执行,尽管在某些平台(例如PlayStation 4)上可能由工作线程执行。 向GPU发送命令时代价最大的操作是SetPass调用。如果我们的游戏由于向GPU发送命令而受到CPU的限制,那么减少SetPass调用的次数可能是提高性能的最佳方法。 我们可以看到有多少SetPass调用和批量被发送在渲染Unity的profiler窗口的profiler。在性能受到影响之前可以发送的SetPass调用的数量在很大程度上取决于目标硬件;在性能受到影响之前,高端PC机可以发送比移动设备多得多的SetPassCall。 SetPass调用的数量及其与批量数量的关系取决于几个因素,我们将在本文后面更详细地讨论这些主题。然而,通常的情况是:
1.在大多数情况下,减少批次数量和/或使更多对象共享相同的呈现状态将减少SetPass调用的数量。
2.在大多数情况下,减少SetPass调用的数量将提高CPU性能。 如果减少批的数量并不能减少SetPass调用的数量,那么它本身仍然可能导致性能的改进。这是因为CPU处理单个批处理比处理多个批处理更有效,即使它们包含相同数量的网格数据。 总的来说,有三种方法可以减少批量调用和SetPass调用的数量。我们将更深入地看看每一个:
1.减少要呈现的对象的数量可能会减少batch和SetPass调用。
2.减少每个对象必须呈现的次数通常会减少SetPass调用的次数。
3.将必须渲染的对象的数据合并为更少的批将减少批的数量。 不同的技术将适用于不同的游戏,所以我们应该考虑所有这些选项,决定哪些可以在我们的游戏和实验中工作。 Reducing the number of objects being rendered 减少要呈现的对象的数量 减少必须呈现的对象的数量是减少batch和SetPass调用数量的最简单方法。我们可以使用几种技术来减少呈现对象的数量。 1.简单地减少场景中可见物体的数量是一个有效的解决方案。例如,如果我们在人群中呈现大量不同的角色,我们可以尝试在场景中减少这些角色的数量。如果场景看起来仍然不错,并且性能有所提高,这可能是比更复杂的技术更快的解决方案。 2.我们可以使用相机的远距剪切平面属性来减少相机的绘制距离。此属性是相机不再呈现对象的距离。如果我们想要掩盖远处的物体不再可见的事实,我们可以尝试使用雾来掩盖远处物体的缺失。https://docs.unity3d.com/Manual/lighting-window.html
3.对于基于距离隐藏对象的更细粒度方法,我们可以使用我们的相机的图层剔除距离属性Layer Cull Distances 来为位于不同图层layers 上的物体提供自定义的剔除距离。 这种方法可以是有用的,如果我们有很多小前景装饰细节;我们可以隐藏这些细节在一个更短的距离比起大型地形特征。
4.我们可以使用一种称为遮挡剔除occlusion culling 的技术来禁用被其他对象隐藏的对象的渲染。例如,如果在我们的场景中有一个大型建筑,我们可以使用遮挡剔除来禁用它背后的对象渲染。Unity的遮挡剔除并不适用于所有场景,可能会导致额外的CPU开销,而且设置起来也很复杂,但是它可以在一些场景中极大地提高性能。This Unity blog post on occlusion culling best practices is a great guide to the subject.除了使用Unity的遮挡剔除,我们还可以实现我们自己的遮挡剔除,通过手动去激活那些我们知道玩家看不到的对象。例如,如果我们的场景包含用于过场动画的对象,但在之前或之后都不可见,我们应该禁用它们。使用我们自己的游戏知识总是比让Unity动态解决问题更有效。
Reducing the number of times each object must be rendered 减少每个对象必须渲染的次数
实时照明,阴影和反射增加了大量的现实主义游戏,但可能是非常昂贵的。使用这些特性可能导致多次呈现对象,从而极大地影响性能。 这些特性的确切影响取决于我们为游戏选择的渲染路径。渲染路径是描述绘制场景时执行计算的顺序的术语,渲染路径之间的主要区别是它们如何处理实时灯光、阴影和反射。一般来说,如果我们的游戏运行在高端硬件上,并使用大量实时灯光、阴影和反射,那么延迟渲染可能是更好的选择。如果我们的游戏运行在低端硬件上,并且不使用这些特性,那么前向渲染可能会更合适。然而,这是一个非常复杂的问题,如果我们希望利用实时的灯光、阴影和反射,最好是研究课题和实验 This page of the Unity Manual gives more information on the different rendering paths available in Unity and is a useful jumping-off point. This tutorial contains useful information on the subject of lighting in Unity. 不管渲染路径如何选择,实时灯光、阴影和反射的使用都会影响游戏的性能,因此了解如何优化它们是非常重要的。
1.Unity中的动态照明是一个非常复杂的主题,深入讨论它超出了本文的范围,but this page of the Unity Manual has details on common lighting optimizations that could help you understand it.
2.动态照明是昂贵的。当我们的场景包含不移动的对象时,比如风景,我们可以使用一种叫做烘烤的技术来预先计算场景的照明,这样运行时的照明计算就不需要了。This tutorial gives an introduction to the technique, and this section of the Unity Manual covers baked lighting in detail.
3.如果我们希望在游戏中使用实时阴影,这可能是我们能够提高性能的一个领域。This page of the Unity Manual is a good guide to the shadow properties that 可以调整的质量设置,以及这些将如何影响外观和性能。:例如,我们可以使用阴影距离属性来确保只有附近的物体可以投射阴影。就是说距离摄像机较近的物体投射阴影,较远的物体则不投射阴影 ,
Additionally, the Scene often looks better without distant shadows
4.Reflection probes 反射探头可以产生真实的反射,但在批量方面可能非常昂贵。最好将反射的使用控制在性能需要考虑的最小范围内,并在使用反射时尽可能地优化反射。
Combining objects into fewer batches 将对象组合成较少的批 当满足某些条件时,批处理可以包含多个对象的数据。要获得批处理资格,对象必须:
1.共享相同材质的相同实例
2.具有相同的材质设置(即,纹理,着色器和着色器参数) 批处理合适的对象可以提高性能,尽管与所有优化技术一样,我们必须仔细分析以确保批处理的成本不会超过性能收益。 有一些不同的技术批量处理合格的对象:
1.静态批处理是一种技术,它允许Unity批处理附近不移动的合适对象。可以从静态批处理中获益的一个很好的例子是一堆类似的对象,例如巨石。This page of the Unity Manual contains instructions on setting up static batching in our game。 静态批处理会导致更高的内存使用,所以我们在分析游戏时应该考虑到这一成本 。
2.动态批处理是另一种技术,它允许Unity批处理合适的对象,不管它们是否移动。使用此技术可以批量处理的对象有一些限制。These restrictions are listed, along with instructions, on this page of the Unity Manual.动态批处理对CPU使用有影响,可能导致CPU时间的开销大于节省的CPU时间。在试验这种技术时,我们应该牢记这一成本,并谨慎使用。
3.批量处理Unity的UI元素有点复杂,因为它会受到UI布局的影响。This video from Unite Bangkok 2015 gives a good overview of the subject and this guide to optimizing Unity UI provides in-depth information on how to ensure that UI batching works as we intend it to.
4.GPU实例化是一种技术,它允许大量相同的对象被非常有效地批处理。它的使用是有限制的,并不是所有的硬件都支持它,但如果我们的游戏在屏幕上同时有许多相同的对象,我们可能会受益于这种技术。This page of the Unity Manual 包含一个介绍GPU实例在Unity中如何使用它的细节,哪些平台支持它,以及在什么情况下它可能有利于我们的游戏。
5.纹理图集是一种技术,其中多个纹理结合成一个更大的纹理。它通常用于2D游戏和UI系统,但也可以用于3D游戏。 如果我们在为我们的游戏创建美术时使用了这一技术,我们便能够确保对象共享纹理并因此有资格进行批量处理。Unity有一个内置的纹理图集工具,叫做Sprite Packer,用于2D游戏。
6.可以在Unity编辑器中或运行时通过代码手动合并共享相同材质和纹理的网格。当以这种方式组合网格时,我们必须意识到阴影、光照和剔除仍将在每个对象级别上进行;这意味着,合并网格带来的性能提升可以通过不再能够剔除那些本来无法呈现的对象来抵消。If we wish to investigate this approach, we should examine the Mesh.CombineMeshes function. The CombineChildren script in Unity’s Standard Assets package is an example of this technique.
7.我们必须非常小心的访问 Renderer.material in scripts.这将复制材料并返回对新副本的引用。如果渲染器是批处理的一部分,那么这样做会中断批处理,因为渲染器不再引用相同的材料实例。如果我们希望在脚本中访问批处理对象的材料,我们应该使用Renderer.sharedMaterial
Culling, sorting and batching 剔除,分类和批处理
剔除、收集将要绘制的对象上的数据、将这些数据进行分批排序以及生成GPU命令,这些都可能导致CPU受限。这些任务要么在主线程上执行,要么在单独的工作线程上执行,这取决于游戏的设置和目标硬件。
1.剔除本身不太可能非常昂贵,但减少不必要的剔除可能有助于提高性能。对于所有活动的场景对象,甚至那些在没有渲染的层上的对象,都有每个对象-每个相机的开销。为了减少这一点,我们应该禁用相机和禁用或禁用目前不使用的渲染器。
2.批处理可以极大地提高向GPU发送命令的速度,但有时也会在其他地方增加不必要的开销。如果批处理操作导致我们的游戏受到CPU限制,我们可能希望限制游戏中手动或自动批处理操作的数量。
Skinned meshes 蒙皮网格
使用SkinnedMeshRenderers 时,我们使用一种叫做骨骼动画的技术来变形一个网格。它最常用于动画角色中。与呈现皮肤网格相关的任务通常会在主线程或单独的工作线程上执行,这取决于游戏的设置和目标硬件。渲染蒙皮网格可能是一个昂贵的操作。如果我们能在Profiler窗口中看到皮肤网格渲染会导致我们的游戏受到CPU限制,我们可以尝试做一些事情来提高性能:
1.我们应该考虑是否需要为当前使用SkinnedMeshRenderer组件的每个对象使用它。可能我们已经导入了一个使用SkinnedMeshRenderer组件的模型,但是我们并没有真正地让它动起来。在这种情况下,用MeshRenderer组件替换SkinnedMeshRenderer组件将有助于提高性能。当将模型导入Unity时,如果我们选择不导入模型的the model’s Import Settings 中的动画,模型将会有一个MeshRenderer而不是SkinnedMeshRenderer。
2.如果我们只是在某些时候(例如,仅在启动时或仅在相机的一定距离内)动画对象,我们可以将其mesh转换为一个不太详细的版本,或者将其SkinnedMeshRenderer组件转换为MeshRenderer组件。
3.SkinnedMeshRenderer组件有一个BakeMesh 函数,它可以在一个匹配的姿态中创建一个网格,这对于在不同的网格或渲染器之间进行交换是非常有用的,并且不会对对象产生任何可见的变化。
4.This page of the Unity Manual 包含了关于优化使用皮肤网格的动画角色的建议,the Unity Manual page on the SkinnedMeshRenderer component 包含了一些可以提高性能的调整。除了这些网页上的建议,值得记住的是,网格皮肤的成本增加每个顶点;因此,在我们的模型中使用较少的顶点可以减少必须完成的工作量。
5.在某些平台上,蒙皮可以由GPU而不是CPU来处理。如果我们在GPU上有很大的容量,这个选项可能值得一试。我们可以在Player Settings 中为当前的平台和质量目标启用GPU蒙皮。
Main thread operations unrelated to rendering 主线程操作与渲染无关
重要的是要理解许多与渲染无关的CPU任务发生在主线程上。这意味着如果我们的CPU被限制在主线程上,那么我们可以通过减少CPU在与渲染无关的任务上花费的时间来提高性能。 例如,我们的游戏可能会在游戏中的某个时间点在主线程上执行昂贵的渲染操作和昂贵的用户脚本操作,这使我们受到CPU的限制。如果我们在不丢失视觉保真度的前提下尽可能多地优化了渲染操作,那么我们就有可能降低脚本的CPU成本来提高性能。
If our game is GPU bound 如果我们的游戏是GPU瓶颈
如果我们的游戏是GPU绑限制,首先要做的是找出是什么导致了GPU瓶颈。GPU的性能通常受到填充率的限制,尤其是在移动设备上,但是内存带宽和顶点处理也会受到影响。让我们检查一下这些问题,并了解它的原因、如何诊断和如何修复。
Fill rate 填充率
填充率是指GPU每秒可以渲染到屏幕上的像素数量。如果我们的游戏受到填充率的限制,这意味着我们的游戏试图在每一帧中绘制比GPU所能处理的更多的像素。 检查填充率是否导致我们的游戏GPU绑定很简单:
1.Profile游戏并注意GPU时间。
2.降低Player Settings的显示分辨率
3.重新Profile游戏。如果性能有所改善,那么填充率可能就是问题所在。
如果填充率是问题的原因,那么有一些方法可以帮助我们解决这个问题。
1.片段着色器是着色器代码的一部分,它告诉GPU如何绘制单个像素。这段代码是由GPU为它必须绘制的每个像素执行的,因此如果代码效率低下,那么性能问题就很容易堆积起来。复杂的片段着色器是导致填充率问题的一个非常常见的原因。 2.如果我们的游戏使用内置的着色器,我们应该致力于使用最简单和最优化的着色器来获得我们想要的视觉效果。
3.例如,与the mobile shaders that ship with Unity 是高度优化的;我们应该尝试使用它们,看看是否能够在不影响游戏外观的情况下提高性能。这些着色器是为在移动平台上使用而设计的,但是它们适用于任何项目。在非移动平台上使用“移动”着色器来提高性能是非常好的,如果它们提供了项目所需的视觉保真度。
4.如果在我们的游戏对象使用Unity的Standard Shader ,理解Unity编译这个基于当前材质设置的着色器是很重要的。 只有当前使用的功能才会被编译。这意味着删除诸如细节映射之类的特性可以大大减少复杂的片段着色器代码,从而极大地提高性能。同样,如果在我们的游戏中是这种情况,我们应该尝试设置并看看我们是否能够在不影响视觉质量的情况下提高性能。
5.如果我们的项目使用定制的着色器,我们应该尽可能地优化它们。Optimizing shader is a complex subject, but this page of the Unity Manual and the Shader optimization section of this page of the Unity Manual contains useful starting points for optimizing our shader code.
6.Overdraw是指同一个像素被多次绘制。当对象被绘制在其他对象之上时,就会发生这种情况,这对填充率问题有很大帮助。为了理解overdraw,我们必须理解Unity在场景中绘制对象的顺序。一个对象的着色器决定它的绘制顺序,通常通过指定对象所在的渲染队列 render queue 来决定。Unity使用这些信息按照严格的顺序绘制对象,详情请参阅page of the Unity Manual 此外,在绘制之前,不同呈现队列中的对象排序是不同的。例如,Unity在几何队列中将项目从前到后排序以最小化透支,而在透明队列中将对象从后到前排序以获得所需的视觉效果。这种前后排序的实际效果是最大化透明队列中对象的透支。Overdraw是一个复杂的主题,没有一种解决Overdraw问题的通用方法,但是减少Unity不能自动排序的重叠对象的数量是关键。最好的地方开始调查这个问题是在Unity的场景视图;有一个绘制模式Draw Mode ,让我们看到叠加绘制*(Overdraw)在我们的场景中,并从那里,确定我们可以在哪里工作,以减少它。过度Overdraw最常见的罪魁祸首是透明材料、未着色的颗粒和重叠的UI元素,因此我们应该尝试优化或减少这些。This article on the Unity Learn site 主要关注的是Unity的用户界面,但也包含了关于透支的很好的一般指导。
7.使用图像效果image effects 可以大大有助于填充率的问题,特别是如果我们使用一个以上的图像效果。如果我们的游戏使用了图像效果,并且正在与填充率问题作斗争,我们可能希望尝试不同的设置或更优化的图像效果版本(如Bloom(优化)Bloom (Optimized) 代替BloomBloom )。如果我们的游戏在同一个相机上使用多个图像效果,这将导致多个着色器pass。 在这种情况下,将图像效果的着色器代码合并成一个单一的通道可能是有益的,例如在Unity的后处理堆栈Unity’s PostProcessing Stack 中。如果我们已经优化了图像效果,但仍然存在填充率问题,我们可能需要考虑禁用图像效果,特别是在低端设备上。
Memory bandwidth 内存带宽 内存带宽指的是GPU读写专用内存的速度。如果我们的游戏受到内存带宽的限制,这通常意味着我们使用的纹理太大,GPU无法快速处理。 要检查内存带宽是否有问题,我们可以做以下工作:
1.配置游戏并注意GPU时间。
2.在质量设置中降低当前平台和质量目标的纹理质量。
3.再次配置游戏并注意GPU时间。如果性能有所改善,很可能是内存带宽的问题。 如果内存带宽是我们的问题,我们需要减少游戏中纹理内存的使用。同样,每个游戏的最佳技术也会有所不同,但我们可以通过一些方法来优化我们的纹理
1.纹理压缩是一种可以大大减少磁盘和内存中纹理大小的技术。如果内存带宽在我们的游戏中是一个问题,那么使用纹理压缩来减少内存中纹理的大小可以提高性能。Unity中有很多不同的纹理压缩格式和设置,每个纹理都可以有单独的设置。
一般来说,应尽可能使用某种形式的纹理压缩;然而,尝试和错误的方法找到最佳的设置为每个纹理的效果最好。 This page in the Unity Manual 包含了关于不同压缩格式和设置的有用信息。
2.Mipmaps是Unity可以在远距离物体上使用的低分辨率纹理版本。如果我们的场景包含了远离摄像机的对象,我们就可以使用mipmaps来缓解内存带宽的问题。场景视图中的Mipmaps绘制模式The Mipmaps Draw Mode 允许我们查看场景中的哪些对象可以从Mipmaps中受益,this page of the Unity Manual 包含了更多关于为纹理启用mipmaps的信息。
Vertex processing 顶点处理
顶点处理是指GPU渲染网格中每个顶点所必须做的工作。顶点处理的成本受到两个因素的影响:必须呈现的顶点的数量,以及必须对每个顶点执行的操作的数量。
如果我们的游戏是GPU限制的,并且我们已经确定它不受填充率或内存带宽的限制,那么很可能是顶点处理导致的问题。如果是这样的话,尝试减少GPU必须做的顶点处理的数量可能会导致性能的提高。 有一些方法我们可以考虑来帮助我们减少顶点的数量或我们在每个顶点上执行的操作的数量。
1.:首先,我们应该致力于减少任何不必要的网格复杂性。如果我们使用的网格具有在游戏中无法看到的细节级别,或者网格效率低下,因为创建错误而有太多的顶点,这对GPU来说是浪费工作。降低顶点处理成本的最简单方法是在我们的3D美术程序中创建具有较低顶点数的网格。
2.我们可以尝试一种叫做法线贴图的技术,在这种技术中,纹理被用来在网格上创建更大的几何复杂性的错觉。虽然这项技术有一些GPU开销,但在很多情况下它会带来性能提升。 This page of the Unity Manual 有一个有用的指南,使用法线映射来模拟复杂的几何网格。
3.如果一个网格在我们的游戏中没有使用法线映射,我们可以在网格的导入设置import settings 中禁用顶点切线的使用。这减少了每个顶点发送到GPU的数据量
4.细节层次 (Level of detail,也称为LOD)是一种优化技术,它可以减少远离摄像机的网格的复杂性。这减少了GPU渲染的顶点数量,而不会影响游戏的视觉质量。The LOD Group page of the Unity Manual contains more information on how to set up LOD in our game.
5.顶点着色器是着色器代码块,告诉GPU如何绘制每个顶点。如果我们的游戏受到顶点处理的限制,那么减少顶点着色器的复杂性可能会有所帮助。
6.如果我们的游戏使用内置的着色器,我们应该致力于使用最简单和最优化的着色器来获得我们想要的视觉效果。例如, the mobile shaders that ship with Unity是高度优化的;我们应该尝试使用它们,看看是否能够在不影响游戏外观的情况下提高性能。
7.如果我们的项目使用定制的着色器,我们应该尽可能地优化它们。优化着色器是一个复杂的问题,但是 this page of the Unity Manual 和this page of the Unity Manual 的着色器优化部分包含了优化我们的着色器代码的有用的起点。
5.Conclusion 结论
我们已经学习了在Unity中渲染是如何工作的,在渲染时会出现什么样的问题,以及如何在我们的游戏中提高渲染性能。利用这些知识和我们的分析工具,我们可以修复与渲染相关的性能问题,并组织我们的游戏,使它们拥有一个流畅而高效的渲染管道。