hbase上传大文件遇到的错误
1.本地运行环境Java heap space
(1)idea配置-Xms6024m -Xmx6024m -XX:MaxPermSize=6024m
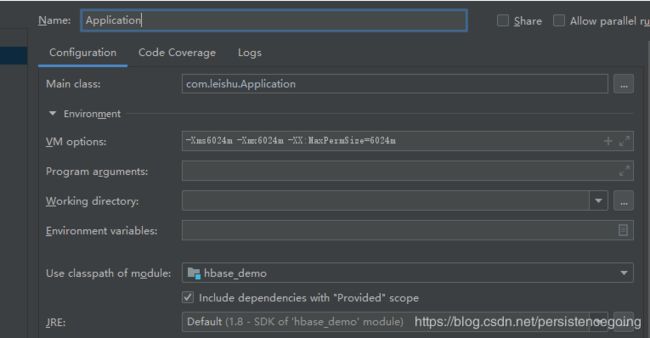
(2)windows 执行 mvn install 出现 java.lang.OutOfMemoryError: Java heap space
配置环境变量:MAVEN_OPTS = -Xms512m -Xmx1024m
然后在 path中加入%MAVEN_OPTS%
(3)IDEA 打包出现 Java heap space
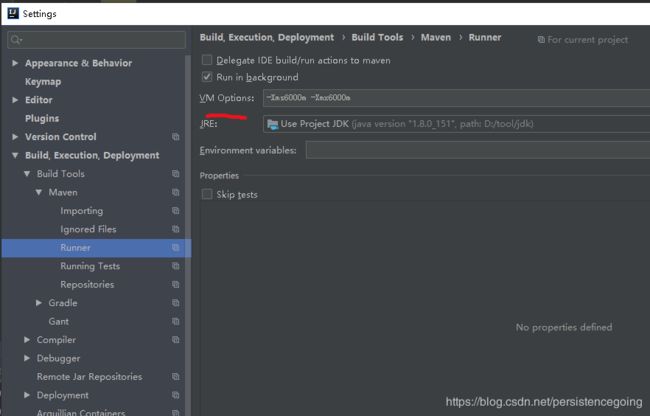
找到 FIile - Settings - Build,Execution,Deployment - Build Tools -Maven - Runner
然后在右侧 VM Options 加入 -Xms512m -Xmx1024m
2.Detected pause in JVM or host machine (eg GC): pause of approximately 1305ms
解决:
打开hadoop-env.sh文件
找到HADOOP_HEAPSIZE= 和HADOOP_NAMENODE_INIT_HEAPSIZE= 调整这两个参数,具体调整多少,视情况而定,默认是1000m,也就是一个g,我这里调整如下:
export HADOOP_HEAPSIZE=32000
export HADOOP_NAMENODE_INIT_HEAPSIZE=16000 这两个参数去掉前面的#号,两台namenode节点都要调整
3.向Hbase插入时,报错java.lang.IllegalArgumentException: KeyValue size too large的解决办法
hbase.client.keyvalue.maxsize 的默认大小是10M,
如果cell的大小超过10M,那么就会报 KeyValue size too large的错误
方法一、根据官网提示,修改配置文件hbase-default.xml ,调大hbase.client.keyvalue.maxsize 的值:
不建议通过直接修改配置文件的方式修改。改完后,需重启hbase
方法二:修改代码,使用configuration对象修改此配置:
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.client.keyvalue.maxsize","209715200");
推荐此种方式。
hbase中文文档:http://abloz.com/hbase/book.html
4.Cannot get replica 0 location for {"totalColumns":6,"row":""
5.zookeeper.ClientCnxn: Client session timed out, have not heard from server in 9174ms for sessionid 0x1732e3964c90004, closing socket connection and attempting reconnect
6.hbase.ScheduledChore: Chore: SplitLogManager Timeout Monitor missed its start time
7.RetriesExhaustedWithDetailsException: Failed 1 action: RetriesExhaustedException: 1 time,
(1)首先看看是不是某个datanode下线了,或者空间不足
(2)可能是客户端的writebuffer舍的过大,把writebuffer关闭,可能会解决问题
8.一段时间后zookeeper+hbase都停掉了
(1)、JVM的垃圾回收,如果配置hbase的heap经常发生垃圾回收,暂停状态会导致心跳失败,可以从hbase JVM GC日志来识别这一点,HBase还将在服务日志中包含消息。
(2)、Host-level停顿。节点将JVM的部分移出内存并转换为交换(由磁盘支持),会导致整个JVM没有任何垃圾收集。HBase通常也会注意到这一点,但是在不发生任何垃圾收集的情况下报告暂停。
(3)、zookeepr连接数超出,可以用netstat命令对比maxClientCnxns值,调整zoo.cfg中的maxClientCnxns值大小
(4)、超时时间过小,可以设置zookeepr中minSessionTimeout和maxSessionTimeout来调节,而且要注意,hbase也有连接zk超时的session设置,hbase-site.xml中设置如下:
zookeeper.session.timeout
180000
(5)、
咨询开发修改hbase-env.sh后:
export HBASE_OPTS="$HBASE_OPTS -verbose:gc -Xloggc:$HBASE_LOG_DIR/hbase.gc.log -XX:ErrorFile=$HBASE_LOG_DIR/hs_err_pid.log -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:CMSInitiatingOccupancyFraction=70"
-XX UseConcMarkSweepGC :设置年老代为并发收集。(新老都有)
老:-XX:+CMSIncrementalMode :设置为增量模式。适用于单CPU情况。
新:-XX:+UseParNewGC:设置年轻代为并行收集。可与 CMS 收集同时使用。
-XX:CMSInitiatingOccupancyFraction=70:这个参数是我觉得产生最大作用的。因为最终的目的是减少FULL GC,因为full gc是会block其他线程的。
默认触发GC的时机是当年老代内存达到90%的时候,这个百分比由 -XX:CMSInitiatingOccupancyFraction=N 这个参数来设置。concurrent mode failed发生在这样一个场景:
当年老代内存达到90%的时候,CMS开始进行并发垃圾收集,于此同时,新生代还在迅速不断地晋升对象到年老代。当年老代CMS还未完成并发标记时,年老 代满了,悲剧就发生了。CMS因为没内存可用不得不暂停mark,并触发一次全jvm的stop the world(挂起所有线程),然后采用单线程拷贝方式清理所有垃圾对象,也就是full gc。而我们的bulk的最开始的操作就是各种删表,建表频繁的操作,就会使用掉大量master的年轻代的内存,就会发生上面发生的场景,发生full gc。
解决办法:CMSInitiatingOccupancyFraction=70表示年老代占到约70%时就开始执行CMS,这样就不会出现(或很少出现)Full GC了。
博主强烈推荐:https://blog.csdn.net/persistencegoing/article/details/84376427
希望大家关注我一波,防止以后迷路,有需要的可以加群讨论互相学习java ,学习路线探讨,经验分享与java求职
群号:721 515 304