HBaseCon Asia 2019 Track 3 概要回顾

HBaseCon 没来参加怎么办?
三个Track没法同时听,分身乏术怎么办?
没关系!“小米云技术”将用三期时间带你回顾
全部精华!
往期回顾:Track1干货回顾 / Track 2 干货回顾
![]()
Track 3:Application
Track3是关于HBase应用的分享,来自腾讯、快手、滴滴、Pinterest、中国移动、中国人寿等多家公司的工程师为我们分享了HBase在应用和实践中遇到的问题和经验。
1、HBase at Tencent
PPT下载链接:http://t.cn/AijgoTGY
来自腾讯的工程师程广旭为我们带来了 HBase 在腾讯的业务中的应用场景和经验。

腾讯目前有90多个 HBase 集群,最大的集群有500多台节点。腾讯内部多个业务包括腾讯视频,微信支付和腾讯云等都在使用 HBase 服务。其首先分享了使用 HBase 进行数据迁移的经验:Replication 和 ExportSnapshot.在实际使用中,业务每天的数据量都很大,这些数据需要保存的周期要么很大,要么很小。因此采取了按天分表的方式,也就是每天会创建一个新的表,对于过期的数据,直接把当天的表删掉即可。其次分享了对带宽的优化。
写入 HBase 的流量主要有五个部分:
写入
WAL
Flush
Small Compaction
Major Compaction
优化的方法有:
开启 CellBlock 的压缩。
WAL 的压缩。
增大 memstore,减少 Flush,减少 Compaction.
减少 Compaction 的线程数目。
关闭 Major Compaction.
按天建表。
最后介绍了如何共享 RestServer.当每个 HBase 集群搭建一个 RestServer 时,如果读取集群的请求很少,那么集群的 RestServer 资源比较浪费。腾讯做了一个改进,配置一个 RestServer 可以访问多个 HBase 集群,同时在 MySQL 里记了哪些表可以通过这种方式访问。
2、HBase at Kuaishou
PPT下载链接:http://t.cn/AijgodXA
来自快手的工程师徐明为我们分享了 HBase 在快手的应用和实践。

快手每天有大量的用户上传大量的视频,这部分视频大部分是几 MB 的对象,其存储方案是:数据直接存储在 HDFS 上,数据的索引存储在 HBase 上,而最新的数据则存储在 memcache 中。
为了提高 HBase 的可用性,加快故障恢复速度,快手自研了 hawk 系统,其包括master,agent,sniffer 三个组件,由多个 agent 投票来确认一个节点是否挂了,然后由 sniffer 来处理挂的节点,并将有问题的节点迅速的从 zk 上删掉。同时快手做了一些优化来加速 split log 和 assign region 的过程。在 Client 端,则主要是确保有问题节点的 region location 能被快速清理掉。
RSGroup 功能也在快手被大量使用,并做了一些优化。一个是添加了 FallBack RSGroup,如果某个 RSGroup 的全部节点都挂了,就从这个 FallBack RSGroup中选择机器;一个是添加了 Global RSGroup,主要是满足监控需求,因为 HBase的 canary 表需要分布在各个机器上。
快手还分享了其如何使用 HBase 来存储和分析海量数据的案例。比如要解决计算用户留存的问题,如果使用 SQL 的话执行很慢,快手使用了 Bitmap 的解决方案。把需要提取的维度转化成 Bitmap,使用空间来减少消耗的时间。使用MR把选择的维度转成 Bitmap,把 Bitmap 切成小块,Bitmap 的数据及 meta 都导入到HBase 中。
3、HBase at DiDi
PPT下载链接:http://t.cn/AijgK2qq
来自滴滴的工程师唐天航为我们带来了 HBase 在滴滴的业务中的应用场景和经验。
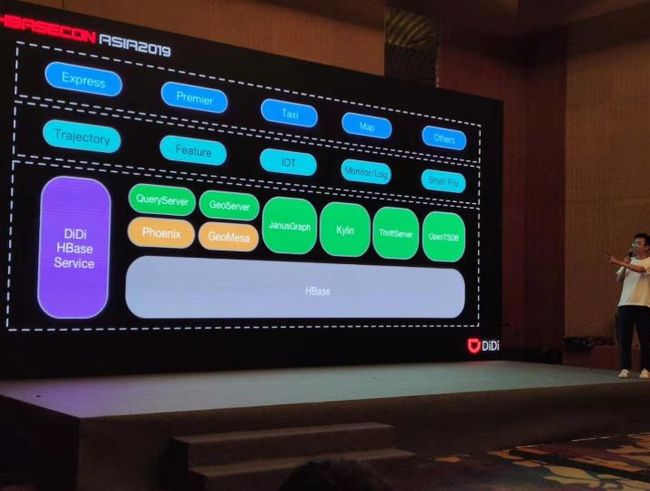
滴滴国内的 HBase 集群有7个,海外国际化集群有4个。覆盖了滴滴全部的业务线,目前服务的项目大概有200多个,数据级是 PB 级。
滴滴使用 HBase 主要有两个场景:
离线数据查询,包括 Phoenix,Kylin,openTSDB 的使用;
GeoMesa 系统构建的轨迹数据系统,可用于实时查询、监控和特征工程的数据挖掘。
GeoMesa 系统提供导入和导出接口,导入接口支持 Native API,MR/BulkLoad,StreamingSQL,导出接口支持 SparkCore,SparkSQL,CQL,GeoServer.这样使用 GeoMesa 可以有以下好处:
开箱即用;
类 SQL 文本语言支持;
横向可扩张;
基于 Hadoop 生态。
滴滴在实践中对 zookeeper 的改进为:分离 server 和 client 所依赖 ZK,当client 端的突发大量访问造成 zk 不可用时,不会影响到服务端。(HBASE-20159,ZOOKEEPER-832)。滴滴在 HBase/Phoenix 上的改进,主要是 Quota设置、replication 以及查询优化(HBASE-21964,HBASE-22620,PHOENIX-5242)
最后, 滴滴建立了从 Client 端到 HAProxy,然后到 Thriftserver 和 QueryServer上,之后再到 HBase 的多元用户全链路追踪,能够更加有效提升运维效率。
4、Phoenix Best Practice In China Life Insurance Company
PPT下载链接:http://t.cn/AijgKfM4
来自中国人寿的工程师袁利鸥为我们分享了 Phoenix 在中国人寿的最佳实践。

中国人寿目前总的节点数有200多个,Phoenix 集群的节点是30多个。集群整体的数据量是1300T,HBase 单表最大30T,每天大概会有上百个脚本运行。
Phoenix 在中国人寿的应用场景:数据源是从核心的交易系统上产生,然后通过SharePlex,打到 Kafka 上,数据从 Kafka 实时接入到 Phoenix 集群上,通过查询服务,为 APP 提供权益信息访问。从物理架构上看,最底层是 Phoenix 集群,向上有两条链路,一条是 Phoenix Gateway,另一条是实时查询服务,通过负载平衡,承接到 Weblogic 集群上。
袁利鸥介绍了 Spark Streaming 的设计:
(1)对于整合后的表,会加入一些控制字段,记录更新时间、删除还是插入操作等。
(2)实时同步程序,按照表名或者统计字段做区分。
袁利鸥接着介绍了关于 Phoenix 的优化,把 Phoenix 的系统表做为一个分组,数据表放在另一个分组中。客户端访问时,每天会拉去一次元数据,随后就不用去访问 Phoenix 系统表,可以降低负载。基于 HBase 的一些优化包括:
Region Balance By Table。
G1GC
Manual MajorCompaction
5、HBase Practice in China Mobile
PPT下载链接:http://t.cn/AijgOxGa
来自中国移动苏州研发中心 HBase 负责人陈叶超介绍了 HBase 在中国移动的实践

中国移动目前大概有6000个物理节点,100多个集群,几十PB数据,单集群最大600多个节点,单表最大1.6PB,最大3000万并发访问,存储的数据采用较高压缩比进行压缩,减少存储空间。
HBase 在中国移动的几个应用场景:
(1)北京移动的流量清单,比如手机使用流量,这个在掌上营业厅是可以查到的。
(2)DPI数据,主要是信令相关的,有一些网络优化的设计。
(3)监控和日志,包括小图片、用户标签、爬虫和市场营销等。
中国移动在实践中通过数据抽样解决 BulkLoad 中数据倾斜问题。数据压缩在Flush 和 BulkLoad 阶段都不开启,只在 compaction 阶段使用,提高读写性能。混合使用 SSD/HDD 磁盘,compaction 后数据存储在 HDD 磁盘。对于更好的使用 SSD,中国移动做了如下工作:
backport HSM To HBase 1.2.6版本。
所有用户过来的写入路径都是SSD的,写性能提高50%。
此外,中国移动还开发了 HBase 集群智能运维工具:Slider 和RegionServerGroup,可以控制资源的分配,并基于 Region 做了一套权限认证体系。
6、Recent work on HBase at Pinterest
PPT下载链接:http://t.cn/AijgO0KU
来自 Pinterest 的技术lead徐良鸿分享了 HBase 在 Pinterest 的最新进展

Pinterest 目前集群规模50台,都部署在 AWS 上,数据量大概在 PB 级。2013年开始使用 HBase 0.94 , 2016年升级为1.2版本。
Pinterest 通过 Apache Omid 实现 HBase 对事务的支持,使用中发现 Omid 存在性能瓶颈,随后自研 Sparrow 系统,主要改进有:
将 commit 操作移到客户端,解决 Transaction Manager 单点问题。
将 Transaction Manager 改为多线程实现,begin 操作可以不用等待 commit 完成。Sparrow 与 Omid 相比,对于 P99 延时,Begin 阶段有100倍降低,commit 阶段也有3倍降低。
Pinterest 自研了 Argus 系统,与 Kafka 结合使用,提供 WAL 通知机制。大概的实现为:需要通知机制的数据会在 client 写入时添加标记,这些标记会被传到WAL 层面,通过 Kafka 将 WAL 提供给 Argus Observer 进行数据处理,处理方式是用户自定义的。
Pinterest 基于开源 Lily 实现 Ixia,用于实时构建 HBase 二级索引,同时整合了Muse,实现类 SQL 查询。大概的实现:写入 HBase 的数据会传到 Replication Proxy,通过 Kafka 打到 Indexer 中,index manager 会读取 HBase 数据的列,如果需要建索引,会将数据写入 Muse 中,Muse 会根据数据的 schema 做检索,query 会在 Muse 中查询,需要时会查询HBase。
徐良鸿介绍了 Argus 和 Ixia 设计的好处:
基于异步的复制机制,对写入的影响很小。
与 HBase 系统独立,分开运行,可以很快的进行数据处理。
7、HBase at Tencent Cloud
PPT下载链接:http://t.cn/AijgOeGJ
来自腾讯的工程师陈龙为我们分享了 HBase 在腾讯云上的经验。

云上服务会遇到很多管理和用户相关的问题。陈龙说明了云服务的3个挑战:
大量的技术咨询工作。
紧急情况的处理。
故障定位分析。
并结合两个案例分析云服务的挑战。
腾讯云在监控方面,通过 OpenTSDB 收集 table 和 region 的 metirc, 用户可以登录云监控,设置 Qps 到某一阈值后,做反向通知。
陈龙分析了云上的故障有4类原因:
外部因素:例如资源泄露,大量请求,coprocessor 问题
硬件因素:磁盘、网络、CVM、资源
存储因素:块丢失、读写超时
配置因素:jvm、memstore、blockcache、flushsize
腾讯云通过提供文档,工具和监控等三个方式,解决在云上遇到的多种问题。陈龙最后分享了监控系统的架构。分享了云上管理服务的架构,比如需要快速的扩容或者缩容集群等。
完
通过三期的更新
小编已经把本次HBaseCon的全部精华呈现给你啦
什么?还没过瘾?想看现场视频?想要完整版的PPT?
点击“阅读原文”到官网获取吧!

我就知道你“在看”
