[Redis]zset数据结构(不涉及score排序)
目录
1.zset
2. 跳表的结构
level的计算
跳跃链表是什么?
跳表具有如下性质:
插入结点
跳表的搜索
删除
3. 压缩链表
4.总结ziplist和skiplist的选择
1.zset
zset是redis中的string类型元素有序集合,每个元素都有一个double型的score,集合通过这个score将元素从小到大排列。zset中可以有多个相同的score。zset有两种实现方式,分别是skiplist和ziplist。
但是注意:
zset不允许重复的成员,有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
| ZADD key score1 member1 [score2 member2] 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
member只能是string
2. 跳表的结构
跳表总结:
跳跃表,可以达到平衡树的插入、删除、查找时间复杂度,即O(logn),但又比平衡树实现简单,采用链表实现,方便依序遍历。
数据结构
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;跳跃链表有头和尾结点。
和一个长度 level
header和tail分别指向头结点和尾结点,length表示表中的结点数量,level为表中结点的最高等级。
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned int span;
} level[];
} zskiplistNode;
这里面有的是对应set的元素的定义,
ele为该结点的string类型的值,score用于结点排序,backward指向按score排序后的前一个结点,level是一个动态数组,数组长度即为该结点在跳跃表中的等级,forward指向对应等级中的下一个结点,span为该等级中与下一结点之间在level[0]中的结点数。
level的计算
在跳跃表中插入结点时需要确定该结点的level,redis采用了一个随机算法:
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level其中ZSKIPLIST_P为0.25,所以创建结点时level=2的概率为1/4,level=3的概率为1/16,依此类推,level的取值范围为1-32。
![[Redis]zset数据结构(不涉及score排序)_第1张图片](http://img.e-com-net.com/image/info8/fd05aee9b2ae45cf83a85ebce78f094e.jpg)
如图是一个skiplist的示意图,第一层有3个结点,第2层有1个结点,第3层有一个结点,括号中的数据即为span。
跳跃链表是什么?
跳跃链表是为了快速查询一个有序连续元素的数据链表。
跳跃列表的平均查找和插入时间复杂度都是O(log n),优于普通队列的O(n)。
跳跃列表是在很多应用中有可能替代平衡树而作为实现方法的一种数据结构。(平衡树的复杂度? )
注意红黑树
可以作为查找数据结构的包括:
- 线性结构:数组、链表
- 非线性结构:平衡树
因为普通链表有着严重的缺陷,需要顺序扫描才能找到所需要的的元素。查找从链表头部开始,只有找到所需的元素或者找到链表尾部都没有找到这个元素才会停下来,将链表元素排序,可以加块查找速度,但是仍然是顺序查找,效率仍然是一个问题。
排序数组结构,查找元素可以通过分而治之(二分查找)的思想,提高查找效率,参考这种思想,跳跃链表作为一种有趣的链表结构,容许进行非顺序查找,跳跃链表本质上进行了空间换时间,均摊时间复杂度。
跳表是一种随机化的数据结构,但是跳表的效率很高(媲美红黑树)。
因为有序,所以把一些节点提出来作为一级索引,然后还可以从一级索引中提取一些元素出来作为二级索引。
跳表具有如下性质:
(1) 由很多层结构组成
(2) 每一层都是一个有序的链表
(3) 最底层(Level 1)的链表包含所有元素(最低层是level1)
(4) 如果一个元素出现在 Level i 的链表中,则它在 Level i 之下的链表也都会出现。
(5) 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
插入结点
//让我一个java看这个头条
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x; //update指向每一层需要修改的结点
unsigned int rank[ZSKIPLIST_MAXLEVEL]; //每一层要修改的结点在整个zset中的排名(根据score从小到大排序)
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
//从最顶层开始,一层一层往下找
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
//在每一层中找到新结点要插入的位置的前一个结点,记录到update[i]中
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
level = zslRandomLevel(); //按照随机算法计算新结点的level
//如果新结点的level大于所有结点,则将header结点的新增level的span设为总结点数,此时forward指向NULL
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
x = zslCreateNode(level,score,ele);//创建新结点
//更新每一层的链表
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
//rank[0]表示update[0]结点的排名,rank[i]表示update[i]结点的排名
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}
先确定该元素要占据的层数 K(采用丢硬币的方式,这完全是随机的)
然后在 Level 1 ... Level K 各个层的链表都插入元素。
例子:插入 119, K = 2
跳表的搜索

例子:查找元素 117
(1) 比较 21, 比 21 大,往后面找
(2) 比较 37, 比 37大,比链表最大值小,从 37 的下面一层开始找
(3) 比较 71, 比 71 大,比链表最大值小,从 71 的下面一层开始找
(4) 比较 85, 比 85 大,从后面找
(5) 比较 117, 等于 117, 找到了节点。
/* 如果存在 x, 返回 x 所在的节点,
* 否则返回 x 的后继节点 */
find(x)
{
p = top;
while (1) {
while (p->next->key < x)
p = p->next;
if (p->down == NULL)
return p->next;
p = p->down;
}
} 删除
//x为待删除的结点
//update为每一层需要修改的结点,即每一层中比x->score小的最大结点
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
//从第一层开始修改每一层的结点
for (i = 0; i < zsl->level; i++) {
//比x低的每一层需要修改链表
if (update[i]->level[i].forward == x) {
update[i]->level[i].span += x->level[i].span - 1;
update[i]->level[i].forward = x->level[i].forward;
} else {
//比x高的层只需将span减1
update[i]->level[i].span -= 1;
}
}
if (x->level[0].forward) {
x->level[0].forward->backward = x->backward;
} else {
zsl->tail = x->backward;
}
//若x为最高层中的唯一结点,则删除后减小跳跃表的level
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
zsl->length--;
}
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
x = zsl->header;
//找到每一层需要修改的结点
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
x = x->level[i].forward;
}
update[i] = x;
}
/* We may have multiple elements with the same score, what we need
* is to find the element with both the right score and object. */
x = x->level[0].forward;
if (x && score == x->score && sdscmp(x->ele,ele) == 0) {
zslDeleteNode(zsl, x, update);
if (!node)
zslFreeNode(x);
else
*node = x;
return 1;
}
return 0; /* not found */
}
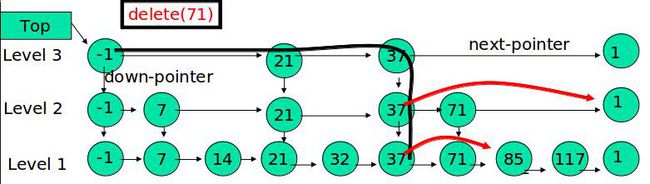
在各个层中找到包含 x 的节点,使用标准的 delete from list 方法删除该节点。
例子:删除 71
3. 压缩链表
ziplist是一个双向链表,特点是节省内存空间,结构如下图所示:
![]()
zlbytes: 4字节,表示整个ziplist的总大小
zltail: 4字节,表示最后一个元素在ziplist中的偏移
zllen: 2字节,表示ziplist中的元素个数,当ziplist中有超过65535个元素时
zllen=65535,此时需要遍历整个列表才能得到元素的总个数
entry: 每个entry包括三个部分:
prevlen: 表示前一个元素的长度,当前一个元素的长度超过253时,prevlen=254,然后用接下来的4个字节表示实际长度
encoding: 包含了该元素的数据类型及长度,具体编码规则参见ziplist.c
entry-data: 实际数据
zlend: ziplist的结束标志,固定为255
查找、插入、删除
zset的每个元素在ziplist中以两个相邻entry的形式保存,第一个保存key, 第二个保存score,ziplist中的元素以score升序排列,所以查找、插入、删除等操作都很简单,时间复杂度为O(n), 此处不再赘述。
4.总结ziplist和skiplist的选择
ziplist节省内存,但是增删改查等操作较慢,而skiplist正好相反,增删改查非常快,但是相比ziplist会占用更多内存。redis在保存zset时按如下的规则进行选择:
当元素个数超过128或最大元素的长度超过64时用skiplist,其他情况下用ziplist,每次对zset进行插入、删除元素时都会重新判断是否需要转换保存格式。(元素个数很多或者单个元素长度很长的时候,超过64用跳表,其他情况使用ziplist)
当选择skiplist时,还需要一个dict来完成key->score的映射,skiplist本身完成score->key的映射。而ziplist因为所有操作都需要从头遍历,所以不需要增加另外的存储成本。
转载:redis源码分析——zset
跳跃表原理