mybatis 注解方式,增,删,改,全查,单查,模糊,总数,CRUD操作,mybatis逆向工程
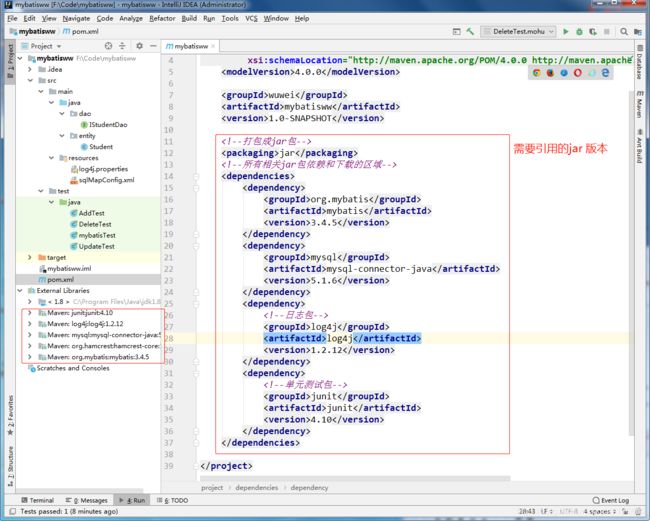
1.搭建maven ,导入相关jar依赖
jar
org.mybatis
mybatis
3.4.5
mysql
mysql-connector-java
5.1.6
log4j
log4j
1.2.12
junit
junit
4.10
 2.导入log4j的固定日志文件,具体参照,https://mp.csdn.net/mdeditor/95371441# 文档中有这个知识点。
2.导入log4j的固定日志文件,具体参照,https://mp.csdn.net/mdeditor/95371441# 文档中有这个知识点。
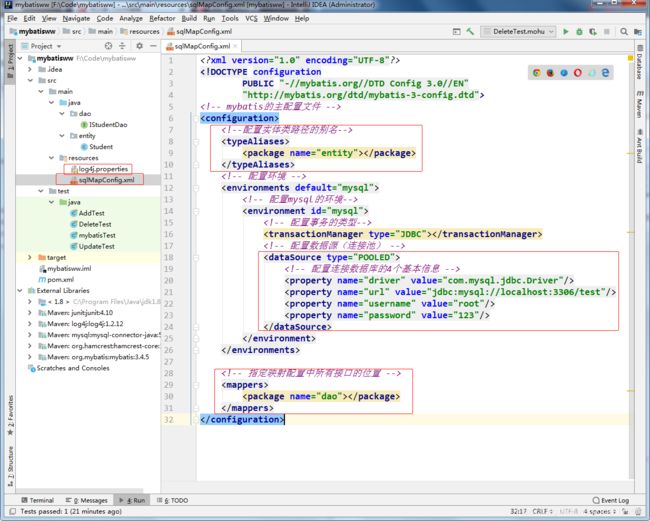
配置连接数据库信息的mybatis 主配置文件 名:sqlMapConfig.xml
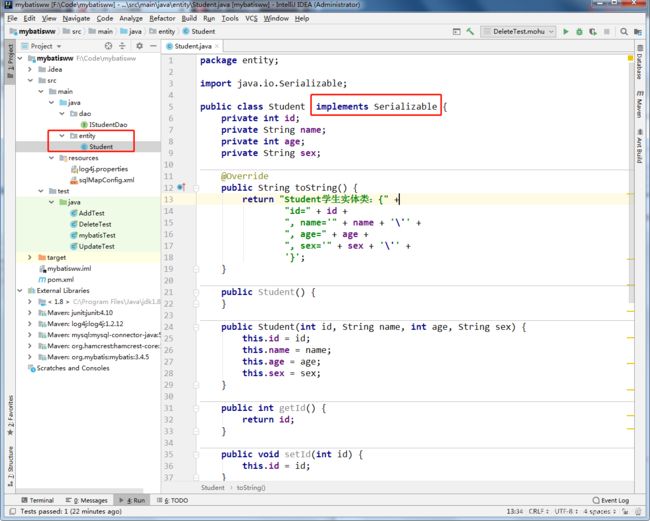
 3.创建实体类包和类。并实现序列化接口。
3.创建实体类包和类。并实现序列化接口。
 4.写接口类里面的方法,和注解,和sql 指令
4.写接口类里面的方法,和注解,和sql 指令
public interface IStudentDao {
//查询所有学生
@Select("select * from student")
List query();
// 新增学生
@Insert( "insert into student (id,name,age,sex) " +
" values(#{id},#{name},#{age},#{sex});")
void add(Student student);
//修改
@Update("update student set name = #{name},age = #{age},sex = #{sex} where id = #{id};")
void update(Student student);
//删除
@Delete("delete from student where id = #{id};")
void delete(int id);
//单查学生
@Select("select * from student where id = #{id}")
Student findbyid(int id);
//名字模糊查询
//1.模糊条件需要,在前台,组装为 《'%经%'》 格式
@Select("select * from student where name like(#{name});")
//2.模糊条件前台传入值为value,后台语句,定义好的格式,直接引用值
// @Select("select * from student where name like '%${value}%' ")
List mohu(String name);
//查询学生数量
@Select("select count(*) from student")
int count();
}

5.生成相应的测试方法。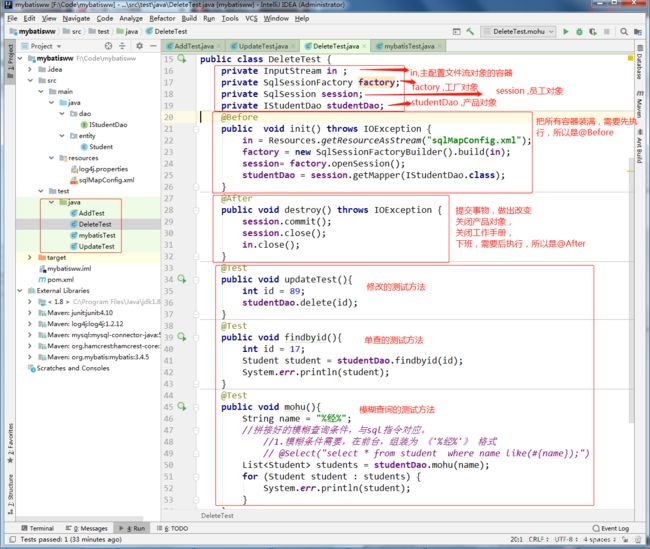
day02,补充
1.表间关系,一对一的操作。
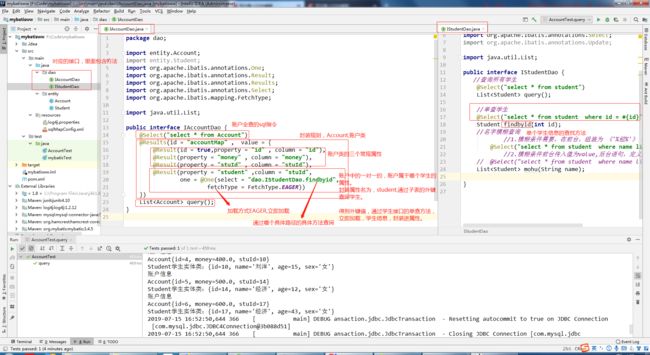
@Select("select * from Account")
@Results(id = "accountMap" , value = {
@Result(id = true,property = "id" , column = "id"),
@Result(property = "money" , column = "money"),
@Result(property = "stuId" , column = "stuId"),
@Result(property = "student" ,column = "stuId",
one = @One(select = "dao.IStudentDao.findbyid",
fetchType = FetchType.EAGER))
})
List query();
2.表间关系,一对多的操作。
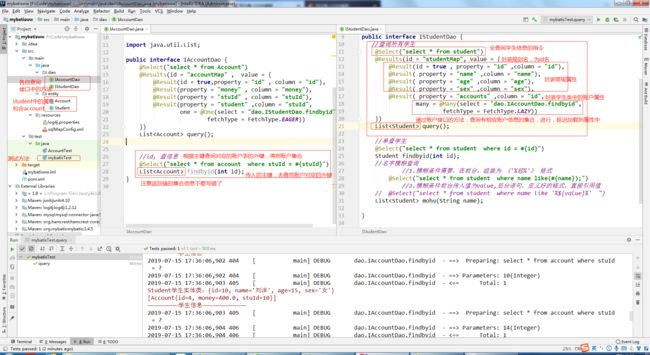
//查询所有学生
@Select("select * from student")
@Results(id = "studentMap", value = {
@Result(id = true , property = "id" ,column = "id"),
@Result( property = "name" ,column = "name"),
@Result( property = "age" ,column = "age"),
@Result( property = "sex" ,column = "sex"),
@Result( property = "accounts" ,column = "id",
many = @Many(select = "dao.IAccountDao.findbyid",
fetchType = FetchType.LAZY))
})
List query();
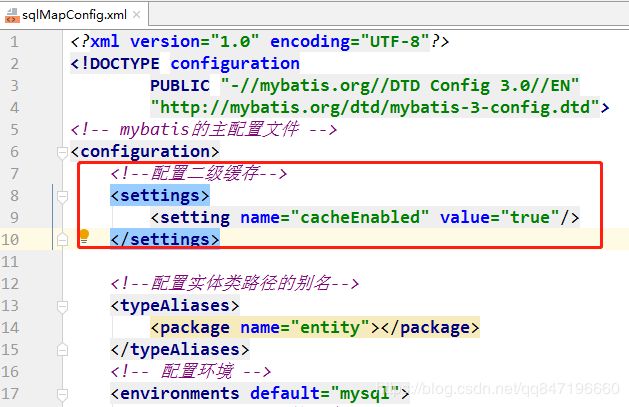
3.配置二级缓存
先去主配置文件中,把cacheEnabled ,的值设为true ,开启二级缓存
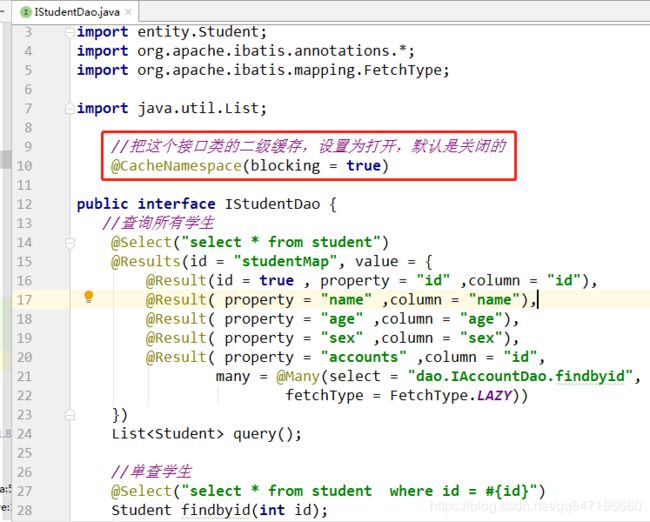
再把接口类的二级缓存,设置为打开,默认是关闭的
@CacheNamespace(blocking = true)
day29 2019-08-28 理论知识点:
注意:
selectList :查询返回一个集合对象
selectOne 查询返回一个对象
${}: 直接拼接, 不会转换类型的, 不能防注入 , 当传入的简单类型, ${value}
#{}: 可以转换类型,可以防注入,相当于 ? ,当传入简单类型:#{随便写}
参数类型
简单类型:
pojo类型:${属性} #{属性}
复杂类型(包装类型): 一个pojo中有另一pojo的属性 ${属性} #{属性.属性}
Map集合:#{key}
多个参数: #{param1},#{param2} ........
传统模式:接口UserDao 实现类:UserDaoImpl , 映射配置文件
代理模式:接口UserDao 映射配置文件UserDao.xml
规范:namespace 必须接口的全限类名
配置的文件的路径必须与接口的包名路径一致
子标签(select,insert ,update ,delete) id 必须是接口的中的方法
参数类型必须与parameterType 是一致的
返回值类型必须与resultType 是一致的
核心配置文件
properties: 引入属性文件的
typeAliaes :别名映射
mappers: 引入配置文件
resouce="xxxx/XXXMapper.xml"
class="com.itheima.mapper.XXXMapper"
url="file:///xxx.xml"
返回值类型
resultType="pojo类型" 列名与属性名一致
列名与属性名不一致
day30 2019-08-29 理论知识点:
1. 连接池(数据源):
type: POOLED,UNPOOLED ,JNDI
2. 事务问题
1) 设置手动提交(开启事务)
2) 提交(提交事务)
3) 回滚事务
4) 设置自动提交(还原状态)
openSession() -- 不可以自动提交事务的SqlSession对象
openSession(true) -- 可以自动提交事务的SqlSession对象
3. 动态sql语句
if 多条件查询
where 帮助程序员处理第一个and符号,结合if语句使用
sql片段: 提取常用的代码
foreach: 循环
属性:collection="list | array", item="循环中每一个对象" open="前缀" close="后缀" seperator="分隔符"
4. 关系映射-- 一对一: 一个账户对应一个用户
1) 声明一个pojo,包含账户和用户所有的属性
2) 在account声明一个User的属性
3)在account声明一个User的属性
5. 关系映射-- 一对多: 一个用户对应多个账户
1) 在user类中声明一个账户的集合属性
2)
6. 关系映射-- 多对多:两个一对多
day31 2019-08-30 理论知识点:
开启全局的延迟加载
动态sql
1. UserDao.java
public interface UserDao {
/**
* 根据姓名模糊查询,性别等于查询
*
* Provider:提供者
* @SelectProvider: sql语句提供者
*
* Type: sql语句提供者的类的字节码
* method: 提供者类中的方法
* @return
*/
// @Select("select * from user where sex = #{sex} and uname like \"%\"#{username}\"%\" ")
@SelectProvider(type = UserSqlProvider.class ,method = "findAll")
@Results({
@Result(id=true, column = "uid",property = "id"),
@Result(column = "uname",property = "username")
})
public List findByCondition(User user);
}
2. UserSqlProvider.java
/**
* user sql 语句的提供者
*
* 在匿名内部类中访问的局部变量必须是final修饰的局部变量
* jdk 1.8以上版本,会默认添加final
* jdk 1.7以下版本,必须手动添加final
*/
public class UserSqlProvider {
public String findAll(User user){
StringBuffer sb = new StringBuffer();
sb.append("select * from user where 1 = 1 ");
if(user.getSex() != null){
sb.append(" and sex = #{sex} ");
}
if(user.getUsername() != null){
sb.append(" and uname like \"%\"#{username}\"%\" ");
}
return sb.toString();
}
}
mybatis 框架 原理图:
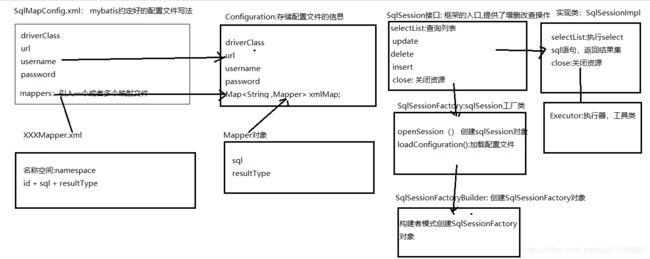
day46 品优购电商项目 2019-09-25 逆向工程知识点:
mybatis逆向工程说明:
mybatis官方推出逆向工程, 用来连接数据库根据表结构生成pojo实体类, 生成映射文件和接口文件, 但是只有
单表的增删改查, 如果多表增删改查还是需要自己动手写.
注意: mybatis生成这些文件的方式是追加和不是覆盖.如果想重新生成需要将原来文件全部删除再重新运行生成,
不然会造成文件损坏无法使用
mybatis逆向工程生成:
idea导入,逆向工程,把dao,resources,pojo目录结构,创建为和使用项目的目录包为一致。
并且要求项目目录没有其他多余文件,并且只能生成一次,二次生成,就会损坏文件
接着修改逆向工程配置文件中的,1.数据库信息,2.生成的文件名映射(比较麻烦,要参照着写),前提是数据库中有相应的表。
生成好后,复制进项目相应目录之下。即可使用。
mybatis逆向工程使用:
@Test
public void testfindBrandByWhere() {
//创建查询对象
BrandQuery brandQuery = new BrandQuery();
//设置查询的字段名,如果不写默认是* 查询所有
brandQuery.setFields("id, name");
//不设置,默认是false,不去重复的数据,true,去重
brandQuery.setDistinct(true);
//设置排序, 设置根据id降序排序
brandQuery.setOrderByClause("id desc");
//创建where查询条件对象,中的where属性内部类,通过查询对象的方法创建
BrandQuery.Criteria criteria = brandQuery.createCriteria();
//查询id等于1的
criteria.andIdEqualTo(1L);
//根据name字段模糊查询
criteria.andNameLike("%联%");
//根据首字母字段模糊查询
criteria.andFirstCharLike("%L%");
List brands = brandDao.selectByExample(brandQuery);
System.out.println("=======" + brands);
}
mybatis逆向工程中生成方法的常用方法:
insert 新增数据:
//插入数据, 插入的时候不会判断传入对象中的属性是否为空, 所有字段都参与拼接sql语句执行效率低
brandDao.insert();
//插入数据, 插入的时候会判断传入对象中的属性是否为空, 如果为空, 不参与拼接sql语句, sql语句会变短执行效率会提高.
brandDao.insertSelective(brand);
修改操作数据
public void update(Brand brand) {
//根据主键作为条件修改, 这个方法带selective说明传入的对象会进行判断, 如果传入的对象属性为null则不会拼接到sql语句中
brandDao.updateByPrimaryKeySelective(brand);
//根据组件作为条件修改, 这个方法不带selective, 所以传入对象中的属性如果为null也会参与拼接sql语句, 修改完如果有属性为null则数据库中的值也会被修改为null
//brandDao.updateByPrimaryKey(brand);
//根据非主键条件修改, 第一个参数传入需要修改的对象, 第二个参数传入修改的条件对象. 不带selective说明传入的对象属性不管是否为null都会参与修改
//brandDao.updateByExample(, );
//根据非主键条件修改, 第一个参数传入需要修改的对象, 第二个参数传入修改的条件对象. 带selective说明如果传入的修改对象中的属性为null不参与修改.
//brandDao.updateByExampleSelective(, )
}