1.关于int和Integer的问题区别分析
- 1.1 编译阶段、运行时,自动装箱 / 自动拆箱是发生在什么阶段?
- 1.2使用静态工厂方法 valueOf 会使用到缓存机制,那么自动装箱的时候,缓存机制起作用吗?
- 1.3为什么我们需要原始数据类型,Java 的对象似乎也很高效,应用中具体会产生哪些差异?
- 1.4 阅读过 Integer 源码吗?分析下类或某些方法的设计要点?
- 1.5 int和Integer的区别
- 1、Integer是int的包装类,int则是java的一种基本数据类型
- 2、Integer变量必须实例化后才能使用,而int变量不需要
- 3、Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值
- 4、Integer的默认值是null,int的默认值是0
**关于Integer和int的比较 **
1、由于Integer变量实际上是对一个Integer对象的引用,所以两个通过new生成的Integer变量永远是不相等的(因为new生成的是两个对象,其内存地址不同)。
Integer i = new Integer(100);
Integer j = new Integer(100);
System.out.print(i == j); //false
2、Integer变量和int变量比较时,只要两个变量的值是向等的,则结果为true(因为包装类Integer和基本数据类型int比较时,java会自动拆包装为int,然后进行比较,实际上就变为两个int变量的比较)
Integer i = new Integer(100);
int j = 100;
System.out.print(i == j); //true
3、非new生成的Integer变量和new Integer()生成的变量比较时,结果为false。(因为非new生成的Integer变量指向的是java常量池中的对象,而new Integer()生成的变量指向堆中新建的对象,两者在内存中的地址不同)
Integer i = new Integer(100);
Integer j = 100;
System.out.print(i == j); //false
4、对于两个非new生成的Integer对象,进行比较时,如果两个变量的值在区间-128到127之间,则比较结果为true,如果两个变量的值不在此区间,则比较结果为false
Integer i = 100;
Integer j = 100;
System.out.print(i == j); //true
Integer i = 128;
Integer j = 128;
System.out.print(i == j); //false
对于第4条的原因:
java在编译Integer i = 100 ;时,会翻译成为Integer i = Integer.valueOf(100);,而java API中对Integer类型的valueOf的定义如下:
public static Integer valueOf(int i){
assert IntegerCache.high >= 127;
if (i >= IntegerCache.low && i <= IntegerCache.high){
return IntegerCache.cache[i + (-IntegerCache.low)];
}
return new Integer(i);
}
java对于-128到127之间的数,会进行缓存,Integer i = 127时,会将127进行缓存,下次再写Integer j = 127时,就会直接从缓存中取,就不会new了
2.Integer的值缓存的原理
2.1 Java 5 中引入缓存特性
在 Java 5 中,为 Integer 的操作引入了一个新的特性,用来节省内存和提高性能。整型对象在内部实现中通过使用相同的对象引用实现了缓存和重用。
这种 Integer 缓存策略仅在自动装箱(autoboxing)的时候有用,使用构造器创建的 Integer 对象不能被缓存。
2.2 Integer类中的IntegerCache类
在创建新的 Integer 对象之前会先在 IntegerCache.cache (是个Integer类型的数组)中查找。有一个专门的 Java 类来负责 Integer 的缓存。
这个类是用来实现缓存支持,并支持 -128 到 127 之间的自动装箱过程。最大值 127 可以通过 JVM 的启动参数 -XX:AutoBoxCacheMax=size 修改。 缓存通过一个 for 循环实现。从小到大的创建尽可能多的整数并存储在一个名为 cache 的整数数组中。这个缓存会在 Integer 类第一次被使用的时候被初始化出来。以后,就可以使用缓存中包含的实例对象,而不是创建一个新的实例(在自动装箱的情况下)。
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
2.3 其他整型类型的缓存机制
这种缓存行为不仅适用于Integer对象。我们针对所有整数类型的类都有类似的缓存机制。
有 ByteCache 用于缓存 Byte 对象
有 ShortCache 用于缓存 Short 对象
有 LongCache 用于缓存 Long 对象
有 CharacterCache 用于缓存 Character 对象
Byte,Short,Long 有固定范围: -128 到 127。对于 Character, 范围是 0 到 127。除了 Integer 可以通过参数改变范围外,其它的都不行。
3.理解自动装箱和拆箱
3.1 什么是装箱?什么是拆箱?
装箱就是 自动将基本数据类型转换为包装器类型;拆箱就是 自动将包装器类型转换为基本数据类型。
//拆箱
int yc = 5;
//装箱
Integer yc = 5;
3.2 装箱和拆箱是如何实现的
以Interger类为例,下面看一段代码来了解装箱和拆箱的实现
public class Main {
public static void main(String[] args) {
Integer y = 10;
int c = i;
}
}
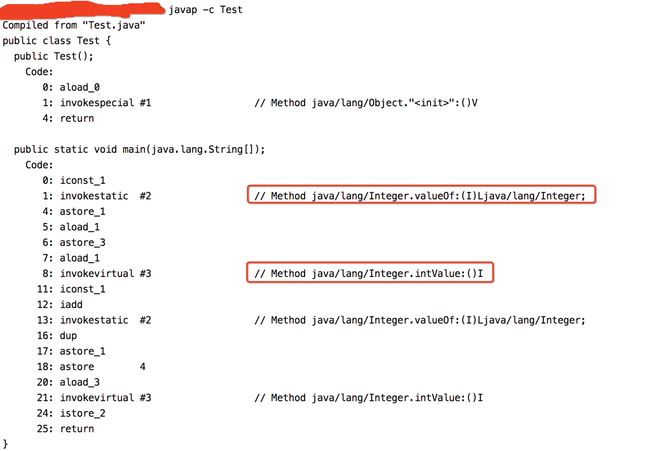
然后来编译一下,看下图所示:
从反编译得到的字节码内容可以看出,在装箱的时候自动调用的是Integer的valueOf(int)方法。而在拆箱的时候自动调用的是Integer的intValue方法。
因此可以用一句话总结装箱和拆箱的实现过程:装箱过程是通过调用包装器的valueOf方法实现的,而拆箱过程是通过调用包装器的 xxxValue方法实现的。(xxx代表对应的基本数据类型)。
3.3 装箱和拆箱在编程实际中注意点
建议避免无意中的装箱、拆箱行为,尤其是在性能敏感的场合,创建 10 万个 Java 对象和 10 万个整数的开销可不是一个数量级的,不管是内存使用还是处理速度,光是对象头的空间占用就已经是数量级的差距了。
4.原始类型线程安全问题
4.1 那些类型是线程安全的
Java自带的线程安全的基本类型包括:
- AtomicInteger,
- AtomicLong,
- AtomicBoolean,
- AtomicIntegerArray,
- AtomicLongArray等
4.2 如何验证int类型是否线程安全
200个线程,每个线程对共享变量 count 进行 50 次 ++ 操作
int 作为基本类型,直接存储在内存栈,且对其进行+,-操作以及++,–操作都不是原子操作,都有可能被其他线程抢断,所以不是线程安全。int 用于单线程变量存取,开销小,速度快
int count = 0;
private void startThread() {
for (int i = 0;i < 200; i++){
new Thread(new Runnable() {
@Override
public void run() {
for (int k = 0; k < 50; k++){
count++;
}
}
}).start();
}
// 休眠10秒,以确保线程都已启动
try {
Thread.sleep(1000*10);
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
Log.e("打印日志----",count+"");
}
}
//期望输出10000,最后输出的是9818
//注意:打印日志----: 9818
4.3 AtomicInteger线程安全版
AtomicInteger类中有有一个变量valueOffset,用来描述AtomicInteger类中value的内存位置 。
当需要变量的值改变的时候,先通过get()得到valueOffset位置的值,也即当前value的值.给该值进行增加,并赋给next
compareAndSet()比较之前取到的value的值当前有没有改变,若没有改变的话,就将next的值赋给value,倘若和之前的值相比的话发生变化的话,则重新一次循环,直到存取成功,通过这样的方式能够保证该变量是线程安全的
value使用了volatile关键字,使得多个线程可以共享变量,使用volatile将使得VM优化失去作用,在线程数特别大时,效率会较低。
private static AtomicInteger atomicInteger = new AtomicInteger(1);
static Integer count1 = Integer.valueOf(0);
private void startThread1() {
for (int i = 0;i < 200; i++){
new Thread(new Runnable() {
@Override
public void run() {
for (int k = 0; k < 50; k++){
// getAndIncrement: 先获得值,再自增1,返回值为自增前的值
count1 = atomicInteger.getAndIncrement();
}
}
}).start();
}
// 休眠10秒,以确保线程都已启动
try {
Thread.sleep(1000*10);
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
Log.e("打印日志----",count1+"");
}
}
//期望输出10000,最后输出的是10000
//注意:打印日志----: 10000
//AtomicInteger使用了volatile关键字进行修饰,使得该类可以满足线程安全。
private volatile int value;
/**
* Creates a new AtomicInteger with the given initial value.
*
* @param initialValue the initial value
*/
public AtomicInteger(int initialValue) {
value = initialValue;
}
5.Java 原始数据类型和引用类型局限性
5.1 原始数据类型和 Java 泛型并不能配合使用
Java 的泛型某种程度上可以算作伪泛型,它完全是一种编译期的技巧,Java 编译期会自动将类型转换为对应的特定类型,这就决定了使用泛型,必须保证相应类型可以转换为Object。
5.2 无法高效地表达数据,也不便于表达复杂的数据结构
Java 的对象都是引用类型,如果是一个原始数据类型数组,它在内存里是一段连续的内存,而对象数组则不然,数据存储的是引用,对象往往是分散地存储在堆的不同位置。这种设计虽然带来了极大灵活性,但是也导致了数据操作的低效,尤其是无法充分利用现代 CPU 缓存机制。
Java 为对象内建了各种多态、线程安全等方面的支持,但这不是所有场合的需求,尤其是数据处理重要性日益提高,更加高密度的值类型是非常现实的需求。
6.关于其他知识延伸
6.1 对象的内存结构
对象在内存中存储的布局可以分为3块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
6.2 对象头的结构
HotSpot虚拟机的对象头包括两部分信息,第一部分用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等,这部分数据的长度在32位和64位的虚拟机(未开启压缩指针)中分别为32bit和64bit,官方称它为"Mark Word"。
对象头的另外一部分是类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。并不是所有的虚拟机实现都必须在对象数据上保留类型指针,换句话说,查找对象的元数据信息并不一定要经过对象本身。另外,如果对象是一个Java数组,那在对象头中还必须有一块用于记录数组长度的数据,因为虚拟机可以通过普通Java对象的元数据信息确定Java对象的大小,但是从数组的元数据中却无法确定数组的大小。
6.3 如何计算或者获取某个Java对象的大小
获取一个JAVA对象的大小,可以将一个对象进行序列化为二进制的Byte,便可以查看大小
//获取一个JAVA对象的大小,可以将一个对象进行序列化为二进制的Byte,便可以查看大小
Integer value = 10;
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos ;
try {
oos = new ObjectOutputStream(bos);
oos.writeObject(value);
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
// 读出当前对象的二进制流信息
Log.e("打印日志----",bos.size()+"");
//打印日志----: 81