CDH重启服务cloudera-scm-agent启动失败( MainThread agent ERROR Heartbeating to 172.16.66.242:7182 )
今天我登陆cdh监控页面172.16.66.242:7180界面时发现拒绝访问,发现我的cdh服务挂掉了。
这个没啥,我就准备重启服务嘛,按照正常流程,先检查下mysql服务
如果没有开启重启下
然后进入
然后主节点
我的3台从节点242,243,244,245IP地址依次启动
./cloudera-scm-agent restart
问题来了,先是报错我的设备空间不够
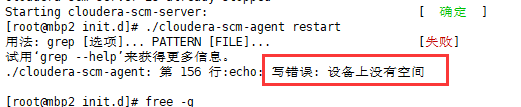
我一开始以为是服务器的运行内存不够,
用free -g查看了下,31g的机器内存,光cache就用了21个g,可用才有3个g,百度网上文章得到以下解决方法
echo 1 > /proc/sys/vm/drop_caches
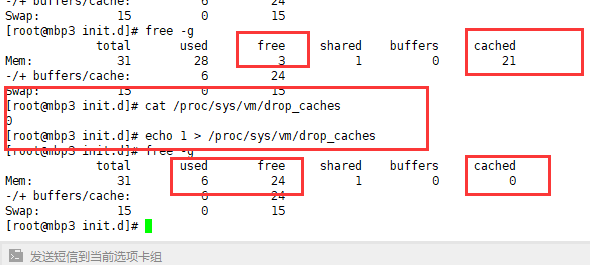
命令解释如下,参考链接https://www.cnblogs.com/rocky-AGE-24/p/7629500.html

可是我发现还是没有解决问题,启动agent服务还是报错设备没有空间。
网上百度了文章,得知报这种错误设备没有空间应该是2种错误引起的,要么磁盘空间不够,要么inode过多,
参考以下文章
http://blog.51cto.com/php2012web/1828097
我用命令查看了下,果然磁盘要超载了,磁盘和inode都是100%了
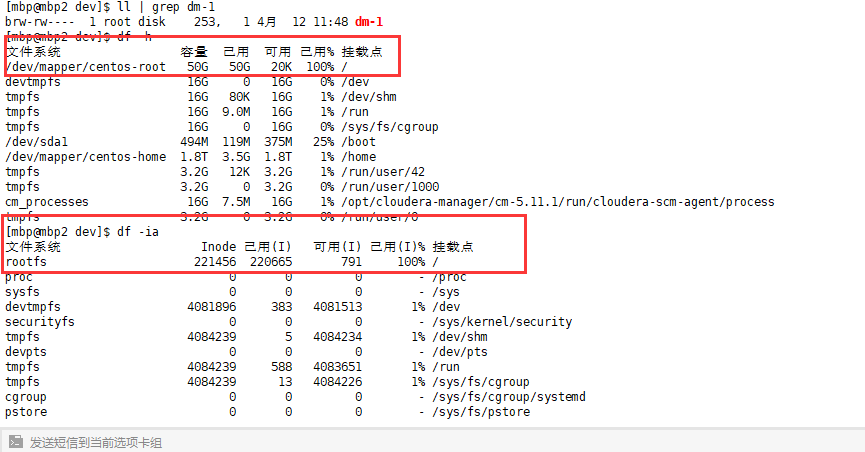
请教了我的一个前辈(马可老师)后得知大概起始给系统挂载分盘时候分配的磁盘太小,然后随着日后使用,磁盘不够,有2种解决方法,第一种治标的,采用删除日志方法,linux系统所有文件的日志保存在/var/log下,可以删日志把空间腾出来,
另一种治本的方法,涉及到一个概念LVM,不过操作比较困难,建议大家现在虚拟机里练熟了再操作,老师给的2篇链接如下
http://www.cnblogs.com/xiaoluo501395377/archive/2013/05/22/3093405.html
http://www.cnblogs.com/xiaoluo501395377/archive/2013/05/24/3096087.html
我比较投机,采用第一种,
查看var/log下面各个目录占用磁盘大小
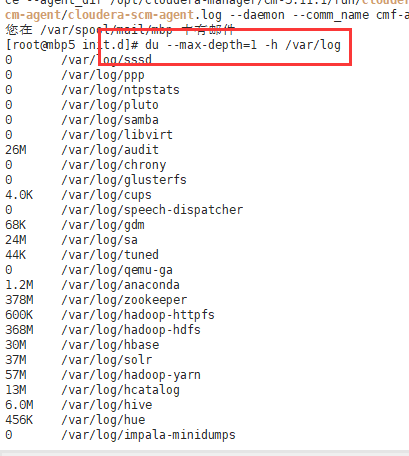
然后进入各自的目录下,把一些占用空间大的日志目录子文件全部rm -rf掉,这时候再看我的磁盘空间,一开始占用100%的只占80%左右了。
我以为问题解决掉了,继续重启agent服务,发现还是不行。真的很糟糕,当时那个心情。
然后只能查看agent启动日志,在我的机器上,目录大概如下,我查看了日志的最后100行内容
cd /opt/cloudera-manager/cm-5.11.1/log/cloudera-scm-agent

多次查看,发现大概报的错误和网上的一种错误一致,都含有连接主节点心跳失败的信息,大概如下
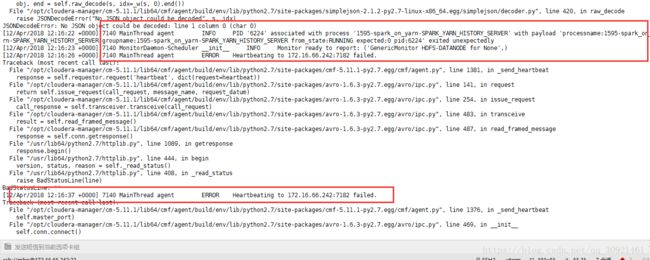
MainThread agent ERROR Heartbeating to 172.16.66.242:7182
网上这种错误很多,可是我按照他们方式没有解决掉,于是我尝试的敲了下命令。
./cloudera-scm-agent status,而不是用start或者restart
这时候系统提示我
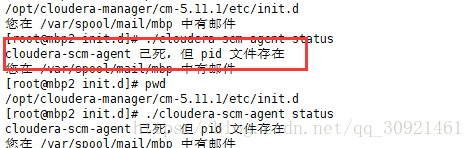
pid文件存在??纳尼?我就用进程查看了下,(注意,此时我的4台机器,242server主节点启动成功,242,243两台ip的机器agent没有启动成功,244,245的agent启动成功了)
敲如ps -ef | grep cloudera-scm-agent
得到一系列关于cloudera-scm-agent的进程信息,因为242agent启动失败了,我都全部用kill -9杀死。
然后我以为我重启agent可以成功,发现还是不行,还是报错pid文件存在,
我百度了下pid文件的存放位置,然后敲cd /proc,然后ls 下,发现很多目录,都是我们机器正在运行的进程的pid目录

不过之前我已经kill掉的agent进程已经找不到目录了,我真的是脑袋都要炸了,还是没搞定,,,,
我想了下242提示agent的pid文件还存在,245不是agent启动成功了嘛,他应该也有pid文件的,我在245机器上
ps -ef | grep cloudera-scm-agent,发现了一个重要信息,
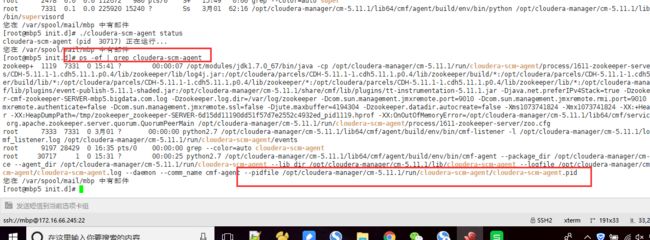
终于让我找到了pid文件的位置,我找到这个目录文件,

然后删了这个pid文件,这时候重启agent服务,终于不报错了,我依次删了243机器关于agent的pid文件,重启成功,

这时候所有的server和agent都启动成功了,进入172.16.66.242:7180,终于可以重启大数据集群服务了

那个忽略掉我的警告太多的界面,我也很无奈,重启2次了,嘿嘿,好了,希望这篇博客对大家有帮助。
大概知识点如下:
1如何重启cm服务
2设备空间不足的解决方法
3系统进程的pid文件位置
4如何解决掉agent启动失败的问题(agent已死,但pid文件存在)
谢谢大家