整理总结:利用Python进行数据分析及思维导图
参考资料:机械工业出版社的《利用Python进行数据分析》(思维导图在最后面)
本篇目录
- 参考资料:机械工业出版社的《利用Python进行数据分析》(思维导图在最后面)
- 第一章 准备工作
- I、为何利用Python进行数据分析
- II、重要的Python库
- 第二章 Python语言基础、IPython及Jupyter notebook
- I、IPython基础
- II、Python语言基础
- 第三章 内建数据结构、函数及文件
- I、元组
- II、列表
- III、切片
- IV、内建序列函数
- V、字典
- VI、集合
- VI、列表、集合与字典的推导式
- VII、函数
- 第四章 Numpy基础
- I、Numpy ndarray——多维数组对象
- II、数组的通用函数
- III、数组的应用操作
- 第五章 Pandas入门
- I、Series
- II、DataFrame
- III、基本功能
- IV、描述性统计的概述与计算
- 第六章 数据载入和存储
- I、数据的载入
- II、 数据的存储
- 第七章 数据清洗与准备
- I、处理缺失值
- II、数据转换
- III、字符串操作
- 第八章 数据规整:连接、联合和重塑
- I、分层索引
- II、联合与合并数据集
- III、重塑和透视
- 第九章 绘图与可视化
- I、简明matplolib API入门
- II、使用pandas和seaborn绘图
- 第十章 数据聚合与分组操作
- I、GroupyBy机制
- II、数据聚合
- III、应用:通用拆分-应用-联合
- IV、数据透视表与交叉表
- 第十八章 思维导图
第一章 准备工作
I、为何利用Python进行数据分析
- Python作为胶水,很容易整合C、C++和FORTRAN等语言的代码
- Python不但适用于研究和原型实现,也适合搭建生产系统,可以同时兼顾研究人员和软件工程师
- Python简洁明了,同一任务可以用更少的代码实现并具有强大的代码可读性
II、重要的Python库
- Numpy:全称为Numerical Python,是Python数值计算的基石。它赋予了Python快速数组处理能力并充当算法和库之间作为数据传递的数据容器
- pandas:提供了高级数据结构和函数,使得表格化数据的工作快速、简单和有表现力,在数据分析中的数据操作、预处理、清洗等方面扮演重要的角色
- matplotlib:是最流行的用于制图及其他二维数据可视化的Python库,与生态系统的其他库良好整合,是一个安全的默认可视化工具
- SciPy:是科学计算领域针对不同标准问题域的包集合,如数值积分求解、概率分布等
- scikit-learn:Python编程者首选的机器学习工具包,包含分类、回归、降维、预处理等模块
- statsmodels:是一个统计分析包,相比scikit-learn,其包含了经典的统计学、经济学算法,如回归模型、时间序列分析等。
第二章 Python语言基础、IPython及Jupyter notebook
I、IPython基础
- Tab补全:对方法、对属性、对文件路径、对函数的关键字参数进行补全
- ?内省:在变量名、函数的前后使用问号?,可以显示一些关于该对象的概要信息
- ??内省:在函数名前后使用??,可以显示函数的源代码
- %run命令:在IPython会话中使用%run命令运行任意的Python程序文件
- %load命令:在IPython会话中将Python文件导入成一个独立的代码单元
- Ctril+C:强制中断Python进程
- %matplotlib inline:在使用matplotlib库函数绘画时,必须实现填写该命令,否则可能绘图失败
II、Python语言基础
- 在Python中使用缩进来组织代码,而非Java中使用大括号,推荐使用四个空格,而非Tab
- 使用‘#’作为注释符号,所在写在#号的文本会自动被Python解释器忽略
- 参数传递,默认使用的是如Java的引用,而非值拷贝
- 在Python编写过程中,使用import some_module as sm 来导入库,或者使用 from some_module import PI as pi来导入变量或函数
- 可以用is关键字来检查两个引用是否指向同一个对象,而==关键字只能判断值的是否相同
- Python的标量类型有None、str、bytes、float、bool和int
- Python的字符串是不可变的,因此无法修改一个字符串,否者会抛出异常
- 如果字符串中需要输出反斜杠符号,可以在字符串前面添加r符号,如r‘this\has’等价于’this\\has’
- 字符串编码成字节流,字节流解码成字符串
- Python的布尔值写作True和False,日期时间的类对应是datetime
- if-elif-else控制流:
if x < 0:
printf('XXX1')
elif x == 0:
printf('XXX2')
elif 0 < x < 5:
printf('XXX3')
else:
printf('XXX4')
- for循环控制流:
for value in sequence:
#用值做些什么
- while循环控制流:
while x > 0 :
#用值做些什么
- pass语句:
if x < 0:
print('XXX')
elif x == 0:
pass
else
print('XXX2')
第三章 内建数据结构、函数及文件
I、元组
- 元组是一个固定长度、不可变的Python对象序列
- 元组创建方法有:
1. tup = 4,5,6
2. tup = (4,5,6),(7,8)
3. tup = tuple([4,0,2])
4. tup = tuple('string')
5. tup = tuple(['foo',[1,2],True])
6. tup = (4,None,'foo') + (6,0) + ('bar',)
7. tup = ('foo','bar')*4
- 元组拆包操作有:
1. tup = 4,5,(6,7) a,b,(c,d) = tup
2. a,b = 1,2
3. a,b = b,a
4. seq = [(1,2,3),(4,5,6),(7,8,9)] for a,b,c in seq: XXXX
5. values = 1,2,3,4,5 a,b,*rest = values
- 元组自身的方法调用有:
1. a = (1,2,2,2,3,4,5) a.count(2)
II、列表
- 列表的长度是可变的,它所包含的内容也是可以修改的。
- 列表创建方法有:
1. a_list = [2,3,5,None]
2. a_list = list('foo','bar','baz')
3. a_list = list(range(10))
4. a_list = [2,3,5,None] + [8,0,(2,3)]
5. a_list = [2,3,5,None].extend([8,0,(2,3)])
- 列表自身的方法调用有:
1. a_list.append('dwarf')
2. a_list.insert(1,'read') 【注:1指的是索引1】
3. a_list.pop(2)
4. a_list.remove('foo')
5. a_list.sort()
6. a_list.sort(key=len)
7. 'dwarf' in a_list
III、切片
- 使用切片符号对大多数序列类型选取其子集,包括列表和元组
- 使用方法有:
1. seq[1:5] 【注:集合关系为[Start,stop)】
2. seq[:5]
3. seq[-4:] 【注:若seq为[9,4,3,2],那么它的索引数组分别有[0,1,2,3]和[-4,-3,-2,-1]】
4. seq[-6:-2]
5. seq[::2]
6. seq[::-1] 【可实现序列的翻转】
IV、内建序列函数
- enumerate函数:用于在遍历一个序列的同时追踪当前元素的索引
for i,value in enumerate(collection):
XXXX
- sorted函数:用于返回一个根据任意序列中的元素新建的已排序列表
sorted([7,1,4,2,0]) or sorted('horse race')
- zip函数:用于将列表、元组或其他序列的元素配对,新建一个元组构成的列表
seq1 = ['foo','bar','baz']
seq2 = ['one','two','three','four']
zipped = zip(seq1,seq2) 【注:它生成的列表长度由最短的子序列决定,在这里是指seq1的长度3】
list(zipped)
- reversed函数:用于将序列的元素倒序排列
list(reversed(range(10)))
V、字典
- 字典是拥有灵活尺寸的键值对集合,它采用了哈希表的算法,其中键和值可以都为Python对象,但要求键必须是不可变的对象,如元组
- 字典创建操作有:
1. a_dict = {'a':'some value','b':[1,2,3,4]}
2. a_dict = dict(zip(range(5),reversed(range(5)))) 【结果为{0:4,1:3,2:2,3:1,4:0}】
- 字典自带方法有:
1. a_dict[9] = 'an integer'
2. a_dict[tuple([1,2,3])] = 4
3. del a_dict['a']
4. ret = a_dict.pop('b')
5. list(a_dict.keys()) or list(a_dict.values())
6. 'b' in a_dict
VI、集合
- 集合是一种无序、元素唯一且不可变的容器,且仅当两个集合的内容完全一模一样时,两个集合才相等(==)
- 集合的创建操作有:
1. col = set([2,2,2,1,3,3]) 【结果为{1,2,3}】
2. col = {tuple([1,2,3,4)} 【结果为{(1,2,3,4)},注:元素只有一个】
3. newCol = col.copy()
- 集合自带的方法有:
1. a.union(b) or a|b
2. a&b
VI、列表、集合与字典的推导式
- 列表推导式允过滤一个容器的元素,用一种简明的表达式转换传递给过滤器的元素,从而生成一个新的列表
- 列表推导式的基本形式:[ expr for val in collection if condition ]
a_list = [ x.upper() for x in strings if len(x) > 2 ] 【给定一个字符串列表,过滤出长度大于2的,并且将字母改为大写】
- 集合推导式的基本形式:{ expr for value in collection if condition }
a_col = { len(x) for x in strings } 【生成包含列表中字符串的长度的集合】
- 字典推导式的基本形式:{ key-expr : value-expr for value in collection if condition }
a_dict = { val : index for index ,val in enumerate(strings) }
- 嵌套列表推导式:
all_data = [['John','Emily','Micha','Mary','Stevem'],
['Maria','Juan','Javier','Natalia','Pilar']]
result = [ name for names in all_data for name in names if name.count('e') >= 2] 【获得一个列表包含所有含有2个以上字母e的名字】
VII、函数
- 函数是Python中最重要、最基础的代码组织和代码复用方式,一般将多次执行的重复相同的或类似的代码构建成一个可复用的函数
- 如果Python达到函数的尾部时仍然没有遇到return语句,那么就会自动返回None
- 在Python中,支持函数的形参设置默认值
def my_function(x,y,z=1.5) 【其中,x和y被称作位置参数,z被称作关键字参数】
- 使用Python编程时,可以使用简单的语法就能实现从函数中返回多个值
1.
def f():
a = 5
b = 6
c = 7
return a,b,c 【注:返回一个元组】
a1,b1,c1 = f()
2.
def f():
a = 5
b = 6
c = 7
return {'a':a,'b':b,'c':c} 【注:返回一个字典】
- 由于Python的函数是对象,很多在其他语言中比较难的构造在Python中非常容易实现
def remove_punctuation(value):
return re.sub('[!@?]','',value)
clean_ops = [str.strip,remove_punctuation,str.title]
def clean_strings(strings,ops): 【将特定的列表操作应用到某个字符串的集合上】
result = []
for value in strings:
for function in ops:
value = function(value)
return result
- 匿名(Lambda)函数:它是一种通过单个语句生成函数的方式,其结果是返回值
1.
def short_function(x):
return x*2
equiv_anon = lambda x:x*2
2.
def apply_to_list(some_list,f):
return [f(x) for x in some_list]
ints = [4,0,1,4,6]
apply_to_list(ints,lambda x:x*2)
- 柯里化——部分参数应用:它表示通过部分参数应用的方式从已有的函数中衍生出新的函数
def add_numbers(x,y):
return x + y
add_five = lambda y : add_numbers(5,y)
- 生成器:它是通过迭代器协议来实现的,迭代器协议是一种令对象可遍历的通用方式,当我们写下for key in some_dict的语句时,Python解释器首先尝试根据some_dict生成一个迭代器,大部分以列表或列表型对象为参数的方法都可以接收任意的迭代器对象,其中生成器则“惰性”地返回一个多结果序列。
def squares(n=10):
print('XX {0}.format(n**2))
for i in range(1,n+1):
yield i**2
for x in squares():
print(x,end='')
- 生成器表达式
sum(x**2 for x in range(100)) 【结果为328350】
- 错误和异常处理
1.
def attempt_float(x):
try:
return float(x)
except:
return x
2.
def attempt_float(x):
try:
return float(x)
except ValueError:
return x
3.
def attempt_float(x):
try:
return float(x)
except (TypeError,ValueError):
return x
4.
f = open(path,'w')
try:
write_to_file(f)
finally:
f.close()
5.
f = open(path,'w')
try:
write_to_file(f)
except:
print('Failed')
else:
print('Succeeded')
finally:
f.close()
第四章 Numpy基础
Numpy的算法库是用C语言写的,所以在操作数据内存时,不需要任何类型检查或者其他管理操作,也使得Numpy数组使用的内存量也小于其他Python内建序列。同时Numpy可以针对全量数组进行复杂计算而不需要写Python循环。
具体而言,即np.arange(10000000)和list(range(10000000))同时执行遍历操作,前者的执行速度要比后者快10到100倍,且使用的内存更少。
I、Numpy ndarray——多维数组对象
- ndarray的生成操作有:
1. arr1 = np.array([6,7.5,8,0,1])
2. arr1 = np.array([[1,2,3,4],[5,6,7,8]]) 【以列表为参数,生成二维数组】
3. arr1 = np.zeros(10)
4. arr1 = np.zeros((3,5)) 【以元组为参数,生成全为0的二维数组】
5. arr1 = np.empty((2,3,2)) 【以元组为参数,生成全为0的三维数组。注:相比zeros方法而言,empty方法并不一定全为0】
6. arr1 = np.arange(15) 【注:需与全局函数range进行辩证分析】
- ndarray的数据类型:即元数据类型dtype,它是Numpy能够与其他系统数据灵活交互的原因
arr1 = np.array(['1.25','-9.6','43'],dtype=np.string_) 【创建元素类型为string_的多维数组对象】
arr1.astype(float) 【将arr的元素类型显式转化成float类型。注:若无法转换则抛出异常】
- Numpy数组算术:它允许用户进行逐元素的批量操作而无须任何for循环,这种特性也被称作向量化
1. arr1 * arr1
2. arr1 - arr1
3. 1/arr1
4. arr1 ** 0.5
5. arr1 > arr2 【逐元素进行比较,结果为布尔数组】
- 基础索引与切片:通过索引与切片所得到的视图,任何对其的修改都会反映到原数组上,除非在视图显式调用copy方法
1.
arr1 = np.arange(10)
arr[5:8]=12 【数值为下标索引,且集合关系为[)】
arr1[:]=32 【默认修改所有元素】
2.
arr1 = np.array([[1,2,3],[4,5,6],[7,8,9]])
arr1[2] 【返回一维数组,array([7,8,9])】
arr1[:2] 【返回二维数组,array([[1,2,3],[4,5,6]])】
arr1[:2,1:] 【返回部分二维数组,array([[2,3],[5,6]])】
arr1[0][2]
arr1[0,2] 【与arr1[0][2]等价,返回3】
- 布尔索引:
names = np.array(['Bob','Joe','Will','Bob','Will','Joe','Joe'])
data = np.random.randn(7,4)
data[~(names == 'Bob')] 【在布尔索引的基础上添加了取反的操作】
- 神奇索引:
1.
arr1 = np.empty((8,4))
arr1[[4,3,0,6]] 【利用列表,一行一行地选】
arr1[[-3,-5,-7]]
2.
arr1 = np.arange(32).reshape((8,4))
arr1[[1,5,7,2][0,3,1,2]] 【利用交叉点,一个一个地选】
- 数组转置和换轴
1.
arr1 = np.arange(15).reshape((3,5))
arr1.T 【数组转置】
np.dot(arr.T,arr) 【计算矩阵内积】
2.
arr1 = np.arange(16).reshape((2,2,4))
arr1.transpose((1,0,2)) 【将第一个轴与第二个轴进行交换,一开始默认顺序为(0,1,2)】
II、数组的通用函数
数组的通用函数是一种在ndarray数据中进行逐元素操作的函数,也被称作ufunc
1. np.sqrt(arr1)
2. np.exp(arr1)
3. np.maximum(x,y)
4. remainder,whole_part = np.modf(arr1)
5. np.sqrt(arr1,arr2) 【结果输出到arr2中】
III、数组的应用操作
- 将条件逻辑作为数组操作:
xarr = np.array([1.1,1.2,1.3,1.4,1.5])
yarr = np.array([2.1,2.2,2.3,2.4,2.5])
cond = np.array([True,False,True,True,False])
1. result = np.where(cond,xarr,yarr) 【若cond的元素为True时,选取xarr的对应元素,否则选取yarr的对应元素】
2. np.where(arr > 0,2,-2)
3. np.where(arr > 0,2,arr) 【仅将正值设为2】
- 数学与统计方法:
arr1 = np.random.randn(5,4)
1. arr1.mean() 【求全元素的均值】
2. arr1.mean(axis=1)
3. np.mean(arr)
4. arr1.sum()
5. arr1.sum(axis=0) 【X轴方向,每一列求和】
6. arr1.cumsum() 【从0开始元素累和】
7. arr1.cumprod() 【从1开始元素累积】
- 布尔值数组的方法
arr1 = np.random.randn(100)
1. (arr > 0).sum() 【将数值数组转化至布尔值数组,从而计算正值的个数】
2. (arr > 0).any() 【若数组中至少有一个True,那么返回True】
3. (arr > 0).all() 【若数组每个值都是True,那么才返回True】
- 排序
1.
arr1 = np.random.randn(6)
arr1.sort()
2.
arr1 = np.random.randn(5,3)
arr1.sort(1) 【以Y轴为方向,每一行内部进行由小到大的排序】
- 唯一值与其他集合逻辑
1.
names = np.array(['Bob','Joe','Will','Bob','Will','Joe','Joe'])
np.unique(names) 【返回数组中唯一值排序后形成的数组,结果为array(['Bob','Joe','Will'])】
2.
values = np.array([6,0,0,3,2,5,6])
np.in1d(values,[2,3,5]) 【检查一个数组的元素是否在另外一个数组中,并返回一个布尔值数组】
- 伪随机数生成
1.
np.random.seed(1234)
np.random.normal(size=(4,4)) 【生成4x4的正态分布随机样本数组】
2.
rng = np.random.RandomState(1234)
rng.randn(10)
第五章 Pandas入门
I、Series
- Series是一种一维的数组型对象,它包含了一个值序列并且包含了数据标签,称为索引,亦或者说是会显式展示索引列
- Series的创建操作有:
1. obj = pd.Series([4,7,-8,3])
2. obj = pd.Series([4,7,-5,3],index=['d','b','a','c'])
3. obj = pd.Series({'Ohio':35000,'Texas':71000,'Oregon':16000,'Utah':5000})
4. obj = pd.Series({'Ohio':35000,'Texas':71000,'Oregon':16000,'Utah':5000},index=['California','Ohio','Oregon','Texas']) 【添加index后,只会显示指定索引的数据,若原数据集没有,则默认填充值NaN】
- Series的操作方法有:
1. obj.index
2. obj.values
3. obj['d'] = 6
4. obj[['d','b','a','c']] = 6
5. obj[obj > 0]
6. obj * 2
7. pd.isnull(obj) 【检查数据项是否缺失,即为空】
8. pd.notnull(obj)
9. obj1 + obj2 【相加具有自动对齐索引的特性,即只相加具有相同标签的值,若一方没有则值为NaN】
10. obj.name = 'population' 【给Series对象设置名称】
11. obj.index.name = 'state' 【给Series对象的索引设置名称】
12. obj.index = ['Bob','Steve','Jeff','Ryan']
II、DataFrame
- DataFrame表示的是矩阵的数据表,它包含已排序的列集合,每一列可以是不同的类型,它也有行索引和列索引,可以被视为一个共享相同索引的Series的字典
- DataFrame的创建操作有:
data = {'state':['Ohio','Ohio','Ohio','Nevada','Nevada','Nevada'],
'year':[2000.2001,2002,2001,2002,2003]
'pop':[1.5,1.7,3.6,2.4,2.9,3.2]}
1. frame = pd.DataFrame(data)
2. frame = Pd.DataFrame(data,columns=['year','state','pop'])
3. frame = Pd.DataFrame(data,columns=['year','state','pop'],index=['one','two','three','four','five','six'])
- DataFrame的操作方法有:
1. frame.head()
2. frame['state']
3. frame.year
4. frame.loc['three'] 【选取某行】
5. frame['debt'] = 16.5 【可以直接通过这方式添加一列】
6. frame['debt'] = np.arange(6.)
7. val = pd.Series([-1.2,-1.5,-1.7],index=['two','four','five'])
frame['debt'] = val 【利用Series来填充DateFrame】
8. frame['eastern'] = frame.state == 'Ohio'
9. del frame2['eastern'] 【删除某一列】
10. frame.columns
11. 'Ohio' in frame.columns
12. 2003 in frame.index
III、基本功能
- 重建索引:
1.
obj = pd.Series([4.5,7.2,-5.3,3.6],index=['d','b','a','c'])
obj2 = obj.reindex(['a','b','c','d','e']) 【若原数据有一样的索引,则按指定顺序排序,否则默认值为NaN】
2.
obj = pd.Series(['blue','purple','yellow'],index=[0,2,4])
obj2 = obj.reindex(range(6),method='ffill') 【ffill方法会将默认值因地适宜得改成前面的值】
3.
frame = pd.DataFrame(np.arange(9).reshape((3,3)),
index=['a','c','d'],
columns=['Ohio','Texas','California'])
frame2 = frame.reindex(['a','b','c','d']) 【重建行索引,没有则全填充NaN值】
frame2 = frame.reindex(columns=['Texas','Utah','California']) 【重建列索引,没有则全填充NaN值】
frame2 = frame.loc[['a','b','c','d'],['Texas','Utah','California']] 【同时重建行列索引,没有则全填充NaN值】
- 轴向上删除条目:
1.
obj = pd.Series(np.arange(5.),index=['a','b','c','d','e'])
obj2 = obj.drop('c')
obj2 = obj.drop(['d','c'])
obj.drop('c',inplace=True) 【在原对象中删除列】
2.
frame = pd.DataFrame(np.arange(16).reshape((4,4)),
index=['Ohio','Colorado','Utah','New York'],
columns=['one','two','three','four'])
frame2 = frame.drop(['Colorado','Ohio']) 【清除行】
frame2 = frame.drop('two',axis=1) 【清除列】
frame2 = frame.drop(['two','four'],axis='columns') 【清除列】
- 索引、选择与过滤:
1.
obj = pd.Series(np.arange(4.),index=['a','b','c','d'])
obj['b']
obj[['b','a','d']]
obj[[1,3]] 【选取下标索引为1和3的行】
obj[obj<2]
obj['b':'c'] = 5 【注:集合关系为[],即结果包含'b','c'两行】
2.
frame = pd.DataFrame(np.arange(16).reshape((4,4)),
index=['Ohio','Colorado','Utah','New York'],
columns=['one','two','three','four'])
frame['two'] 【选列】
frame[['three','one']]
frame[:2] 【选取下标索引为0和1的行,集合关系为[)】
frame[frame['three']>5]
frame[frame < 5] = 0
frame.loc['Colorado',['two','three']] 【交叉选取】
frame.iloc[2,[3,0,1]]
frame.loc[:'Utah','two'] 【利用字符切片,注:包含了'Utah'代表的行】
frame.iloc[:,:3][frame.three > 5] 【嵌套筛选,注::3代表的选取0,1,2索引列】
- 算术和数据对齐:在Series和DataFrame中,当将两个相同类型对象相加时,会自动采用索引对齐相加的方式,若一方没有相应索引,则自动填充NaN。具体区别则是Series是行索引对齐,而DataFrame则是行索引和列索引分别对齐
1.
obj1 = pd.Series([7.3,-2.5,3.4,1.5],index=['a','c','d','e'])
obj2 = pd.Series([-2.1,3.6,-1.5,4,3.1],index=['a','c','e','f','g'])
obj1 + obj2
2.
frame1 = pd.DataFrame(np.arange(9.).reshape((3,3)),columns=list('bcd'),index=['Ohio','Texas','Colorado'])
frame2 = pd.DataFrame(np.arange(12.).reshape((4,3)),columns=list('bde'),index=['Utah','Ohio','Texas','Colorado'])
frame1 + frame2 【缺失默认填充值为NaN】
3.
frame1.add(frame2,fill_value=0) 【设置缺失默认填充值为0】
4.
1/frame1
frame1.rdiv(1)
5.
arr1 = np.arange(12.).reshape((3,4))
arr1 - arr1[0] 【arr1的每一行都对arr1[0]进行了减操作】
6.
frame2 = pd.DataFrame(np.arange(12.).reshape((4,3)),columns=list('bde'),index=['Utah','Ohio','Texas','Colorado'])
series = frame2.iloc[0] 【注:选取第一行作为Series对象】
frame2 - series 【frame2的每一列删除series的相应的索引值】
7.
frame2 = pd.DataFrame(np.arange(12.).reshape((4,3)),columns=list('bde'),index=['Utah','Ohio','Texas','Colorado'])
series = pd.Series(range(3),index=['b','e','f'])
frame2 + series 【双方都提前进行索引拓展,填充值默认为NaN,再最后进行相加】
8.
frame2 = pd.DataFrame(np.arange(12.).reshape((4,3)),columns=list('bde'),index=['Utah','Ohio','Texas','Colorado'])
series = frame2['d']
frame2.sub(series,axis='index') 【改成在列上进行广播,在行上匹配】
- 函数应用和映射:
frame = pd.DataFrame(np.random.randn(4,3),columns=list('bde'),index=['Utah','Ohio','Texas','Oregon'])
1.
np.abs(frame) 【注:Numpy的通用函数对pandas对象也有效】
2.
frame.apply(lambda x: x.max() - x.min()) 【每一列都应用函数】
3.
frame.apply(lambda x: x.max() - x.min(),axis='columns') 【每一行都应用函数】
4.
def f(x):
return pd.Series([x.min(),x.max()],index=['min','max'])
frame.apply(f) 【传递给apply的函数可以返回带有多个值的Series对象】
5.
format = lambda x: '%.2f' %x
frame.applymap(format) 【给每一个元素逐一应用函数】
6.
format = lambda x: '%.2f' %x
frame['e'].map(format) 【给某一列的所有元素逐一应用函数】
- 排序和排名:
1.
obj = pd.Series(range(4),index=['d','a','b','c'])
obj.sort_index() 【根据索引值来进行行排序】
2.
frame = pd.DataFrame(np.arange(8).reshape((2,4)),index=['three','one'],columns=['d','a','b','c'])
frame.sort_index()
frame.sort_index(axis=1)
frame.sort_index(axis=1,ascending=False) 【根据列索引进行列排序,且设置成降序排序】
3.
obj = pd.Series([4,np.nan,7,np.nan,-3,2])
obj.sort_values() 【根据Series值进行排序】
4.
frame = pd.DataFrame({'b':[4,7,-3,2],'a':[0,1,0,1]})
frame.sort_values(by='b') 【根据索引b的列的值来进行行排序】
frame.sort_values(by=['a','b']) 【根据多个指标的值来进行行排序】
5.
obj = pd.Series([7,-5,7,4,2,0,4])
obj.rank() 【允许名次重复,如7和7的值被计算成同一个名次。注:结果为名次值,而非原数据】
obj.rank(method='first') 【不允许名次重复,同值的对象根据在数据中的观测顺序进行分配】
obj.rank(ascending=False,method='max') 【按降序排序,即值越大名次越靠前,越小】
6.
frame = pd.DataFrame({'b':[4.3,7,-3,2],'a':[0,1,0,1],'c':[-2,5,8,-2.5]})
frame.rank(axis='columns') 【对每一行进行名次计算】
- 含有重复标签的轴索引:
obj = pd.Series(range(5),index=['a','a','b','b','c'])
obj.index.is_unique 【检查标签是否唯一】
obj['a'] 【注:由于标签重复,故最后可能会输出多行】
IV、描述性统计的概述与计算
1.
frame = pd.DataFrame([[1.4,np.nan],[7.1,-4.5],[np.nan,np.nan],[0.75,-1.3]],
index=['a','b','c','d'],columns=['one','two'])
frame.sum() 【依次计算每个列的总和】
frame.sum(axis='columns') 【依次计算每个行的总和】
frame.mean(axis='columns',skipna=False) 【计算均值时,不忽略NA值】
frame.indxmax() 【依次记录每个列的最大值的行索引】
frame.cumsum()
frame.describe() 【计算各列的汇总统计集合】
2.
obj = pd.Series(['c','a','d','a','a','b','b','c','c'])
uniques = obj.unique() 【返回序列中的所有不重复值】
count = obj.value_counts() 【返回序列中值的个数,包括重复值】
pd.value_counts(obj.values,sort=False) 【对结果进行排序】
mask = obj.isin(['b','c']) 【遍历各行,判断值是否包含在['b','c']中】
第六章 数据载入和存储
I、数据的载入
1. df = pd.read_csv('examples/ex1.csv')
2. df = pd.read_table('examples/ex1.csv',sep=',')
3. df = pd.read_csv('examples/ex2.csv',header=None)
4. df = pd.read_csv('examples/ex2.csv',names=['a','b','c','d','message']) 【显式设置数据集的列索引】
5. df = pd.read_csv('examples/ex2.csv',names=['a','b','c','d','message'],index_col='message') 【显式设置数据集的列索引,并把一项作为行索引】
6. df = pd.read_csv('examples/ex2.csv',index_col=['key1','key2'])
7. df = pd.read_table('exmaple/ex2.txt',sep='\s+')
8. df = pd.read_csv('examples/ex2.csv',skiprows=[0,2,3]) 【跳跃下标索引为0、2和3的行】
9. df = pd.isnull(pd.read_csv('examples/ex2.csv')
10. df = pd.read_csv('examples/ex2.csv',na_values=['NULL']) 【数据集中若元素值等于NULL,那么就设置它为NA】
11. df = pd.read_csv('examples/ex2.csv',na_values={'message':['foo','NA'],'something':['two']})
12. df = pd.read_csv('examples/ex2.csv',nrows=5) 【只读取五行】
II、 数据的存储
1. data.to_csv('example/ex2.csv')
2. data.to_csv(sys.stdout,sep='|') 【存储时元素用分隔符分开】
3. data.to_csv(sys.stdout,na_rep='NULL')
4. data.to_csv(sys.stdout,index=False,header=False) 【不存储数据集的行索引和列索引】
5. data.to_csv(sys.stdout,index=False,columns=['a','b','c'])
第七章 数据清洗与准备
在进行数据分析和建模的过程中,大量的时间花在数据准备上:加载、清理、转换和重新排列,这样的工作占用了分析师80%以上的时间。
I、处理缺失值
- 在统计学应用中,NA数据可以是不存在的数据或者是存在但不可观测的数据
- 过滤缺失值
from numpy import nan as NA
1.
data = pd.Series([1,NA,3.5,NA,7])
cleaned = data[data.notnull()]
cleaned = data.dropna() 【清理掉包含NA值的行】
2.
data = pd.DataFrame([[1.,6.5,3.],[1.,NA,NA],[NA,NA,NA],[NA,6.5,3.]])
cleaned = data.dropna()
cleaned = data.dropna(how='all') 【清理掉所有值都是NA值的行】
cleaned = data.dropna(axis=1,how='all') 【清理掉所有值都是NA值的列,注:和arr1.sum(axis=1)有理念区别】
cleaned = data.dropna(thresh=2) 【保留最多包含1个NA值的行】
- 补全缺失值
1.
data = pd.Series([1.,NA,3.5,NA,7])
res = data.fillna(data.mean()) 【用数据集的均值来代替NA值】
2.
data = pd.DataFrame(np.random.randn(7,3))
res = data.fillna(0)
res = data.fillna({1:0.5,2:0}) 【分别用0.5,0来代替第二列、第三列的NA值】
res = data.fillna(method='ffill')
res = data.fillna(method='ffill',limit=2) 【只允许填充2行】
data.fillna(0,inplace=True) 【原地修改,用0代替NA值】
II、数据转换
- 删除重复值
data = pd.DataFrame({'k1':['one','two']*3+['two'],'k2':[1,1,2,3,3,4,5]})
data.duplicated() 【检测每一行是否存在重复(与之前出现过的行相同)的情况,返回布尔数组】
data.drop_duplicates() 【返回duplicated函数中为False的行,即返回不含重复行的数据集】
data.drop_duplicates(['k1']) 【利用K1列来去除重复值,即只保留K1列中不同值第一次出现的行】
data.drop_duplicates(['k1','k2'],keep='last') 【只保留K1和K2列不同组合最后出现的行】
- 使用函数或映射进行数据转换
data = pd.DataFrame({'food':['bacon','pulled pork','bacon','Pastrami','corned beef','Bacon','pastrami','honey ham','nova lox'],'ounces':[4,3,12,6,7.5,8,3,5,6]})
meat_to_animal = {'bacon':'pig','pulled pork':'pig','pastrami':'cow','corned beef':'cow','honey ham':'pig','nova lox':'salmon'}
1.
lowercased = data['food'].str.lower()
data['animal'] = lowercased.map(meat_to_animal)
2.
data['food'].map(lambda x:meat_to_animal[x.lower()])
- 替代值
data = pd.Series([1.,-999.,2.,-999.,-1000.,3.])
data.replace(-999,np.nan) 【用NA值来替代-999】
data.replace([-999,-1000],np.nan) 【用NA值同时替代-999和-1000】
data.replace([-999,-1000],[np.nan,0]) 【用NA值替代-999,用0替代-1000】
data.replace({-999:np.nan,-1000:0}) 【同上】
- 重命名轴索引
data = pd.DataFrame(np.arange(12).reshape((3,4)),
index=['Ohio','Colorado','New York'],
columns=['one','two','three','four'])
transform = lambda x: x[:4].upper()
7. data.index = data.index.map(transform) 【改变索引格式】
8. data.rename(index=str.title,columns=str.upper)
9. data.rename(index={'OHIO':'INDIANA'},columns={'three':'peekaboo'}) 【将'OHIO'改成'INDIANA'】
4.data.rename(index={'OHIO':'INDIANA'},inplace=True) 【原地修改】
- 离散化和分箱
1.
ages = [20,22,25,27,21,23,37,31,61,45,41,32]
bins = [18,25,35,60,100]
cats = pd.cut(ages,bins) 【输出每个数值所在箱对应的区间,切割时默认是集合关系(]】
cats.codes 【输出每个数值所在箱的索引】
cats.categories
pd.value_counts(cats)
pd.cut(ages,[18,26,36,61,100],right=False) 【更改集合关系为[)】
pd.cut(ages,bins,labels=['Youth','YoungAdult','MiddleAged','Senior']) 【同时设置每个箱的名称】
2.
data = np.random.rand(20)
pd.cut(data,4,precision=2) 【设置箱对应区间边界的精度,保留后二位】
3.
data = np.random.randn(1000)
cats = pd.qcut(data,4) 【qcut相比cut方法,会使每个箱具有相同数据量的数据点,因此可以通过该方法获得等长的箱】
pd.value_counts(cats)
pd.qcut(data,[0,0.1,0.5,0.9,1.]) 【根据自定义的样本分位数来切割】
- 检测与过滤异常值
data = pd.DataFrame(np.random.randn(1000,4))
col = data[2]
col[np.abs(col)>3] 【找出一列中绝对值大于三的值】
data[(np.abs(data)>3).any(1)] 【找出所有值大于3或小于-3的行】
np.sign(data) 【根据数据中的值的正负分别生成1和-1的数值】
- 置换和随机抽样
1.
df = pd.DataFrame(np.arange(5*4).reshapes((5,4)))
sampler = np.random.permutation(5)
df.take(sampler) 【调整行顺序】
df.sample(n=3) 【随机选出一个不含替代值的随机子集】
2.
choices = pd.Series([5,7,-1,6,4])
draws = choices.sample(n=10,replace=True) 【随机从五个数据中抽取十个样本,允许重复值】
- 计算指标/虚拟变量
df = pd.DataFrame({'key':['b','b','a','c','a','b'],'data1':range(6)})
pd.get_dummies(df['key']) 【将数据集转换成值为1和0的矩阵】
III、字符串操作
- 字符串对象方法
val = 'a,b, guido'
val.split(',')
pieces = [x.strip() for x in val.split(',')]
first,second,third = pieces
first + '::' + second + '::' + third
'::'.join(pieces)
'guido' in val
val.index(',') OR val.find(':')
val.count(',')
val.replace(',','::')
- 正则表达式
text = "foo bar\t baz \tqux"
1.
re.split('\s+',text)
2.
regex = re.compile('\s+') 【产生正则表达式对象,有利于节约CPU周期】
regex.split(text)
regex.findall(text) 【返回所有与正则表达式匹配的部分】
regex.search(text) 【返回第一个与正则表达式匹配的部分】
regrex.match(text) 【只在文本开头进行匹配】
regrex.sub('READCTED',text) 【用字符串'READCTED'来代替匹配到的部分】
- pandas中的向量化字符串函数(用于批量正则表达式应用)
data = {'Dave':'[email protected]','Steve':'[email protected]','Rob':'[email protected]','Wes':np.nan}
data = pd.Series(data) 【字典转化至Series对象,其中键成为值的索引】
data.str.contains('gmail') 【为每个对象都同时应用一个正则表达式,其中使用该类函数可以避免原数据中可能包含的NA值的影响,而不直接报错】
第八章 数据规整:连接、联合和重塑
I、分层索引
- 分层索引允许在一个轴上拥有多个(两个及以上)索引层级,笼统的说,分层索引提供了一种在更低维度的形式中处理更高维度数据的方式
1.
data = pd.Series(np.random.randn(9),index=[['a','a','a','b','b','c','c','d','d'],[1,2,3,1,3,1,2,2,3]])
data['b'] 【默认指的是第一级索引】
data['b':'c']
data.loc[['b','d']]
data.loc[:,2] 【不限第一级索引,限制第二级索引的第二索引】
data.unstack() 【DataFrame重新排列】
dat.unstack().stack()
2.
frame = pd.DataFrame(np.arrange(12).reshape((4,3)),index=[['a','a','b','b'],[1,2,1,2]],columns=[['Ohio','Ohio','Colorado'],['Green','Red','Green']])
frame.index.names = ['key1','key2']
frame.columns.names = ['state','color']
frame['Ohio']
- 重排序和层级排序
frame.swaplevel('key1','key2') 【交换行的两级索引】
frame.sort_index(level=1) 【根据第二级索引来数据集进行行排列】
frame.swaplevel(0,1).sort_index(level=0)
- 按层级进行汇总统计
frame.sum(level='key2') 【参数为某级索引名称,对特定行轴上的相同标签类型进行行累和】
frame.sum(level='color',axis=1) 【对特定列轴的相同标签进行列累和】
- 使用DataFrame的列进行索引
frame = pd.DataFrame({'a':range(7),'b':range(7,0,-1),'c':['one','one','one','two','two','two','two'],'d':[0,1,2,0,1,2,3]})
frame2 = frame.set_index(['c','d'] 【将'c'、'd'两列移动,并作为行索引】
frame2 = frame.set_index(['c','d'],drop=False) 【将'c'、'd'两列拷贝作为行索引】
frame2.reset_index() 【是set_index方法的反操作,即将行索引转换成列】
II、联合与合并数据集
- 数据库风格的DataFrame连接
1.
df1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],'data1': range(7)})
df2 = pd.DataFrame({'key': ['a', 'b', 'd'],'data2': range(3)})
pd.merge(df1, df2) 【默认把重叠列名作为连接的键,且仅保留双方匹配列值一致的行,注:默认做“内连接”】
pd.merge(df1, df2, on='key') 【显式指定要匹配的列】
pd.merge(df1, df2, how='outer') 【设置合并以“外连接”为策略】
2.
df3 = pd.DataFrame({'lkey': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],'data1': range(7)})
df4 = pd.DataFrame({'rkey': ['a', 'b', 'd'],'data2': range(3)})
pd.merge(df3, df4, left_on='lkey', right_on='rkey') 【分别指定双方进行匹配的列,并保留该两列】
3.
df1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'b'], 'data1': range(6)})
df2 = pd.DataFrame({'key': ['a', 'b', 'a', 'b', 'd'],'data2': range(5)})
pd.merge(df1, df2, on='key', how='left')
pd.merge(df1, df2, how='inner')
4.
left = pd.DataFrame({'key1': ['foo', 'foo', 'bar'],'key2': ['one', 'two', 'one'],'lval': [1, 2, 3]})
right = pd.DataFrame({'key1': ['foo', 'foo', 'bar', 'bar'],'key2': ['one', 'one', 'one', 'two'],'rval': [4, 5, 6, 7]})
pd.merge(left, right, on=['key1', 'key2'], how='outer') 【使用多个键进行合并】
pd.merge(left, right, on='key1')
pd.merge(left, right, on='key1', suffixes=('_left', '_right')) 【即当两个合并集同时拥有多个非连接键重名时,为了防止混淆时使用,第一个集合重名列添加'_left',第二个集合添加'_right'】
- 根据索引合并
1.
left1 = pd.DataFrame({'key': ['a', 'b', 'a', 'a', 'b','c'], 'value': range(6)})
right1 = pd.DataFrame({'group_val': [3.5, 7]}, index=['a', 'b'])
pd.merge(left1, right1, left_on='key', right_index=True) 【第一集合的‘key’列值和第二集合的索引值进行匹配,而非列值与列值的匹配了】
pd.merge(left1, right1, left_on='key', right_index=True, how='outer')
2.
lefth = pd.DataFrame({'key1': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'], 'key2': [2000, 2001, 2002, 2001,2002],'data': np.arange(5.)})
righth = pd.DataFrame(np.arange(12).reshape((6, 2)),index=[['Nevada', 'Nevada', 'Ohio', 'Ohio','Ohio', 'Ohio'], [2001, 2000, 2000, 2000, 2001, 2002]],columns=['event1', 'event2'])
pd.merge(lefth, righth, left_on=['key1', 'key2'], right_index=True)
pd.merge(lefth, righth, left_on=['key1', 'key2'], right_index=True, how='outer')
3.
left2 = pd.DataFrame([[1., 2.], [3., 4.], [5., 6.]], index=['a', 'c', 'e'],columns=['Ohio', 'Nevada'])
right2 = pd.DataFrame([[7., 8.], [9., 10.], [11., 12.],[13, 14]],index=['b', 'c', 'd', 'e'], columns=['Missouri', 'Alabama'])
pd.merge(left2, right2, how='outer', left_index=True, right_index=True)
left2.join(right2, how='outer')
left1.join(right1, on='key')
4.
another = pd.DataFrame([[7., 8.], [9., 10.], [11., 12.], [16., 17.]], index=['a', 'c', 'e', 'f'],columns=['New York','Oregon'])
left2.join([right2, another])
left2.join([right2, another], how='outer')
- 沿轴向连接
1.
arr = np.arange(12).reshape((3, 4))
np.concatenate([arr, arr], axis=1) 【类似于arr与arr的横向拼接】
2.
s1 = pd.Series([0, 1], index=['a', 'b'])
s2 = pd.Series([2, 3, 4], index=['c', 'd', 'e'])
s3 = pd.Series([5, 6], index=['f', 'g'])
pd.concat([s1, s2, s3]) 【默认沿着axis=0的轴向生效的,类似于行的上下拼接】
pd.concat([s1, s2, s3], axis=1) 【列的左右拼接,不存在的值自动填充NA】
s4 = pd.concat([s1, s3])
pd.concat([s1, s4], axis=1)
pd.concat([s1, s4], axis=1, join='inner')
pd.concat([s1, s4], axis=1, join_axes=[['a', 'c', 'b','e']]) 【在pd.concat([s1, s4], axis=1)的结果上继续处理,即仅保留a、c、b、e标签的行,而由于c、e本来就没有该标签,所以这两行的值都默认为NA】
result = pd.concat([s1, s1, s3], keys=['one','two', 'three']) 【仅仅是用'one','two','three'来创建第一级索引(外围索引),用于区分上下拼接的行原先是属于哪个集合】
result.unstack()
pd.concat([s1, s2, s3], axis=1, keys=['one','two', 'three'])
3.
df1 = pd.DataFrame(np.arange(6).reshape(3, 2), index=['a', 'b', 'c'], columns=['one', 'two'])
df2 = pd.DataFrame(5 + np.arange(4).reshape(2, 2), index=['a', 'c'],columns=['three', 'four'])
pd.concat([df1, df2], axis=1, keys=['level1', 'level2']) 【'level1'、'level2'成为列轴上的第一级索引(外围索引),用于区别列属于原先哪个集合】
pd.concat({'level1': df1, 'level2': df2}, axis=1) 【效果与上语句相同】
pd.concat([df1, df2], axis=1, keys=['level1', 'level2'],names=['upper', 'lower']) 【设置第一级索引名称'upper'和第二级索引名称'lower'】
4.
df1 = pd.DataFrame(np.random.randn(3, 4), columns=['a', 'b', 'c', 'd'])
df2 = pd.DataFrame(np.random.randn(2, 3), columns=['b', 'd', 'a'])
pd.concat([df1, df2], ignore_index=True) 【若原集合没有设置行索引,则会默认设置行索引为整数索引,并执行行的上下拼接操作】
- 联合重叠数据
1.
a = pd.Series([np.nan, 2.5, np.nan, 3.5, 4.5, np.nan],index=['f', 'e', 'd', 'c', 'b', 'a'])
b = pd.Series([0.,np.nan,2.,np.nan,np.nan,5.],index=['a','b','c','d','e','f'])
np.where(pd.isnull(a), b, a)
b.combine_first(a[2:]) 【当两个集合的索引局部甚至全部一致时,用集合a来修补集合b的缺失值】
2.
df1 = pd.DataFrame({'a': [1., np.nan, 5., np.nan], 'b': [np.nan, 2., np.nan, 6.],'c': range(2, 18, 4)})
df2 = pd.DataFrame({'a': [5., 4., np.nan, 3., 7.], 'b': [np.nan, 3., 4., 6., 8.]})
df1.combine_first(df2)
III、重塑和透视
- 使用多层索引进行重塑
1.
data = pd.DataFrame(np.arange(6).reshape((2, 3)), index=pd.Index(['Ohio','Colorado']
, name='state'), columns=pd.Index(['one', 'two', 'three'], name='number'))
result = data.stack() 【将DataFrame中的列索引转换成带二级行索引的Series】
result.unstack() 【默认将带二级行索引的Series的第二级行索引(内层索引)转换成DataFrame列索引】
result.unstack(0) 【将带二级行索引的Series的第一级行索引(外层索引)转换成DataFrame列索引】
result.unstack('state') 【利用索引名称来选择移动的索引轴】
2.
s1 = pd.Series([0, 1, 2, 3], index=['a', 'b', 'c', 'd'])
s2 = pd.Series([4, 5, 6], index=['c', 'd', 'e'])
data2 = pd.concat([s1, s2], keys=['one', 'two'])
data2.unstack() 【Series转成DataFrame】
data2.unstack().stack() 【在逆操作过程中默认只显示有值的索引行显示】
data2.unstack().stack(dropna=False) 【显示设置所有的所有行显示,即NA值行也显示】
3.
df = pd.DataFrame({'left': result, 'right': result + 5},columns=pd.Index(['left', 'right'],name='side'))
df.unstack('state')
df.unstack('state').stack('side')
- 将“长”透视成“宽”:将原先的许多列的数据集中的列索引旋转成某一列的列值,这样就使数据集的宽度变窄了,但同样的,高度也比以往高了些许
data = pd.read_csv('examples/macrodata.csv')
data.head() 【显示前五行】
periods = pd.PeriodIndex(year=data.year, quarter=data.quarter, name='date')
columns = pd.Index(['realgdp', 'infl', 'unemp'], name='item')
data = data.reindex(columns=columns)
data.index = periods.to_timestamp('D', 'end')
ldata = data.stack().reset_index().rename(columns={0:'value'})
pivoted = ldata.pivot('date', 'item', 'value')
ldata['value2'] = np.random.randn(len(ldata))
pivoted = ldata.pivot('date', 'item')
pivoted['value'][:5]
unstacked = ldata.set_index(['date', 'item']).unstack('item')
- 将“宽”透视成“长”
df = pd.DataFrame({'key': ['foo', 'bar', 'baz'],'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]})
melted = pd.melt(df, ['key'])
reshaped = melted.pivot('key', 'variable', 'value')
reshaped.reset_index()
pd.melt(df, id_vars=['key'], value_vars=['A', 'B'])
pd.melt(df, value_vars=['A', 'B', 'C'])
pd.melt(df, value_vars=['key', 'A', 'B'])
第九章 绘图与可视化
I、简明matplolib API入门
- 图片与子图
1.
import matplotlib.pyplot as plt
fig = plt.figure()
ax1 = fig.add_subplot(2, 2, 1)
ax2 = fig.add_subplot(2, 2, 2)
ax3 = fig.add_subplot(2, 2, 3)
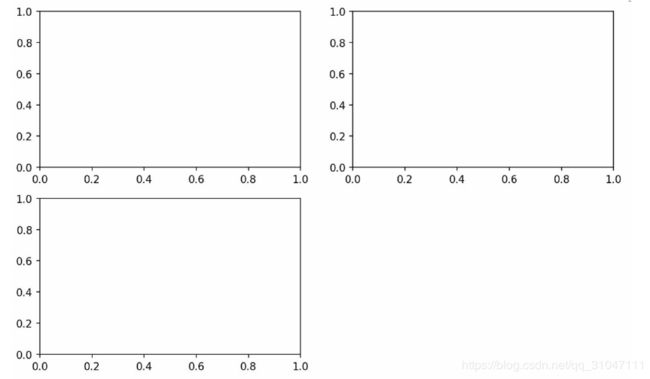
plt.plot(np.random.randn(50).cumsum(), 'k--')

ax1.hist(np.random.randn(100), bins=20, color='k', alpha=0.3)
ax2.scatter(np.arange(30), np.arange(30) + 3 * np.random.randn(30))
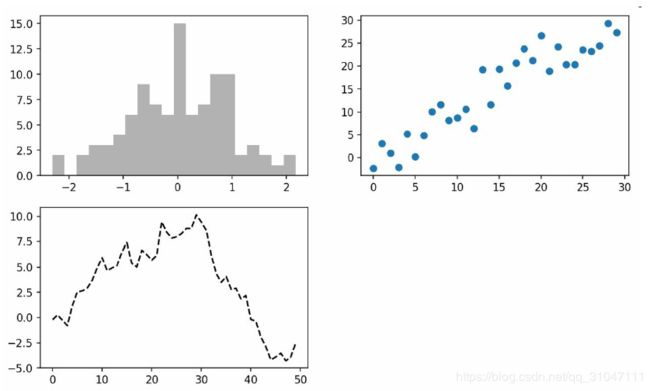
2.
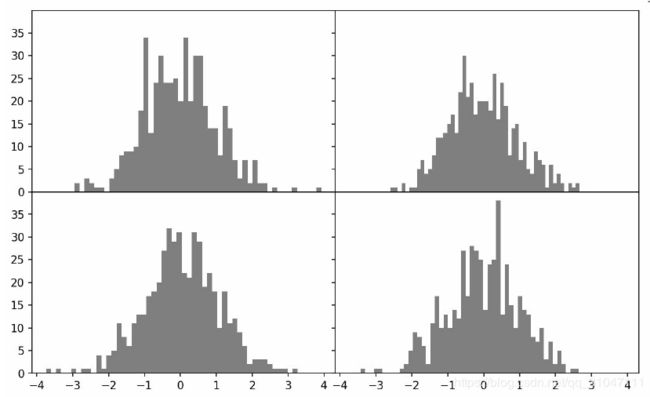
fig, axes = plt.subplots(2, 2, sharex=True, sharey=True)
for i in range(2):
for j in range(2):
axes[i, j].hist(np.random.randn(500), bins=50, color='k', alpha=0.5)
plt.subplots_adjust(wspace=0, hspace=0)
3. 颜色、标记和线类型
1.
from numpy.random import randn
In [31]: plt.plot(randn(30).cumsum(), 'ko--')
2.
data = np.random.randn(30).cumsum()
plt.plot(data, 'k--', label='Default')
plt.plot(data, 'k-', drawstyle='steps-post', label='steps-post')
plt.legend(loc='best')

5. 刻度、标签和图例
1.
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(np.random.randn(1000).cumsum())

ticks = ax.set_xticks([0, 250, 500, 750, 1000])
labels = ax.set_xticklabels(['one', 'two', 'three', 'four', 'five'],
rotation=30, fontsize='small')
ax.set_title('My first matplotlib plot')
ax.set_xlabel('Stages')

2.
from numpy.random import randn
fig = plt.figure(); ax = fig.add_subplot(1, 1, 1)
ax.plot(randn(1000).cumsum(), 'k', label='one')
ax.plot(randn(1000).cumsum(), 'k--', label='two')
ax.plot(randn(1000).cumsum(), 'k.', label='three')
ax.legend(loc='best')

7. 注释与子图加工
1.
from datetime import datetime
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
data = pd.read_csv('examples/spx.csv', index_col=0, parse_dates=True)
spx = data['SPX']
spx.plot(ax=ax, style='k-')
crisis_data = [
(datetime(2007, 10, 11), 'Peak of bull market'),
(datetime(2008, 3, 12), 'Bear Stearns Fails'),
(datetime(2008, 9, 15), 'Lehman Bankruptcy')
]
for date, label in crisis_data:
ax.annotate(label, xy=(date, spx.asof(date) + 75),xytext=(date, spx.asof(date) + 225),arrowprops=dict(facecolor='black',headwidth=4,width=2,headlength=4),horizontalalignment='left', verticalalignment='top')
# Zoom in on 2007-2010
ax.set_xlim(['1/1/2007', '1/1/2011'])
ax.set_ylim([600, 1800])
ax.set_title('Important dates in the 2008-2009 financial crisis')

2.
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
rect = plt.Rectangle((0.2, 0.75), 0.4, 0.15, color='k', alpha=0.3)
circ =plt.Circle((0.7, 0.2), 0.15, color='b', alpha=0.3)
pgon = plt.Polygon([[0.15, 0.15], [0.35, 0.4], [0.2, 0.6]],color='g', alpha=0.5)
ax.add_patch(rect)
ax.add_patch(circ)
ax.add_patch(pgon)

9. 将图片保存到文件
1.
plt.savefig('figpath.svg')
2.
plt.savefig('figpath.png', dpi=400, bbox_inches='tight') 【得到一张带有最小白边且分辨率为400DPI的PNG图片】
3.
from io import BytesIO 【savefig并非一定要写入磁盘,也可以写入任何文件型的对象】
buffer = BytesIO()
plt.savefig(buffer)
plot_data = buffer.getvalue()
- matplotlib设置
1.
plt.rc('figure', figsize=(10, 10)) 【将全局的图像默认大小设置为10×10】
2.
font_options = {'family' : 'monospace','weight' : 'bold','size' : 'small'}
plt.rc('font', **font_options)
II、使用pandas和seaborn绘图
- 折线图
1.
s = pd.Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10))
s.plot()

2.
df = pd.DataFrame(np.random.randn(10, 4).cumsum(0), columns=['A', 'B', 'C', 'D'],index=np.arange(0, 100, 10))
df.plot()
3. 柱状图
1.
fig, axes = plt.subplots(2, 1)
data = pd.Series(np.random.rand(16), index=list('abcdefghijklmnop'))
data.plot.bar(ax=axes[0], color='k', alpha=0.7)
data.plot.barh(ax=axes[1], color='k', alpha=0.7)

2.
In [69]:df = pd.DataFrame(np.random.rand(6, 4),index=['one', 'two', 'three', 'four',
'five', 'six'],columns=pd.Index(['A', 'B', 'C', 'D'], name='Genus'))
In [70]: df
Out[70]:
Genus A B C D
one 0.370670 0.602792 0.229159 0.486744
two 0.420082 0.571653 0.049024 0.880592
three 0.814568 0.277160 0.880316 0.431326
four 0.374020 0.899420 0.460304 0.100843
five 0.433270 0.125107 0.494675 0.961825
six 0.601648 0.478576 0.205690 0.560547
In [71]:df.plot.bar()

df.plot.barh(stacked=True, alpha=0.5)
3.
In [75]:tips = pd.read_csv('examples/tips.csv')
In [76]:party_counts = pd.crosstab(tips['day'], tips['size'])
In [77]: party_counts
Out[77]:
size 1 2 3 4 5 6
day
Fri 1 16 1 1 0 0
Sat 2 53 18 13 1 0
Sun 0 39 15 18 3 1
Thur 1 48 4 5 1 3
# Not many 1- and 6-person parties
In [78]: party_counts = party_counts.loc[:, 2:5]
In [79]: party_pcts = party_counts.div(party_counts.sum(1), axis=0)
In [80]: party_pcts
Out[80]:
size 2 3 4 5
day
Fri 0.888889 0.055556 0.055556 0.000000
Sat 0.623529 0.211765 0.152941 0.011765
Sun 0.520000 0.200000 0.240000 0.040000
Thur 0.827586 0.068966 0.086207 0.017241
In [81]: party_pcts.plot.bar()

4.
In [83]: import seaborn as sns
In [84]: tips['tip_pct'] = tips['tip'] / (tips['total_bill'] - tips['tip'])
In [85]: tips.head()
Out[85]:
total_bill tip smoker day time size tip_pct
0 16.99 1.01 No Sun Dinner 2 0.063204
1 10.34 1.66 No Sun Dinner 3 0.191244
2 21.01 3.50 No Sun Dinner 3 0.199886
3 23.68 3.31 No Sun Dinner 2 0.162494
4 24.59 3.61 No Sun Dinner 4 0.172069
In [86]: sns.barplot(x='tip_pct', y='day', data=tips, orient='h')

In [88]: sns.barplot(x='tip_pct', y='day', hue='time', data=tips, orient='h')
5. 直方图和密度图
1.
In [92]: tips['tip_pct'].plot.hist(bins=50)

2.
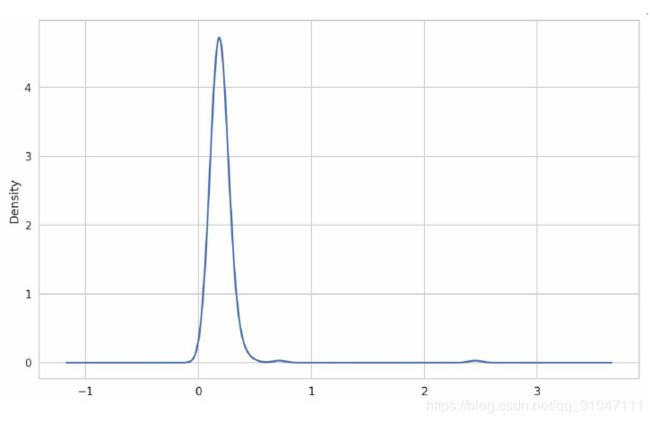
In [94]: tips['tip_pct'].plot.density()
3.
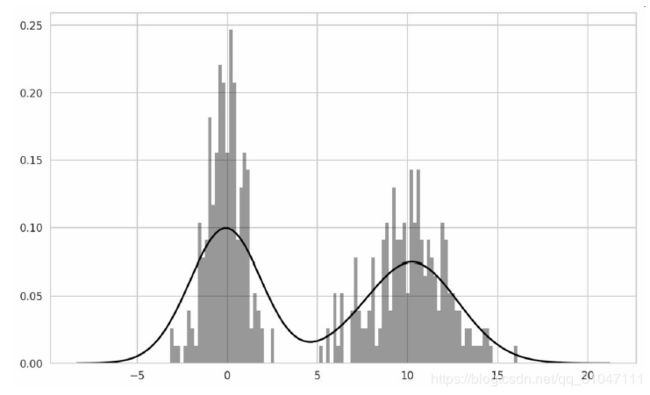
In [96]: comp1 = np.random.normal(0, 1, size=200)
In [97]: comp2 = np.random.normal(10, 2, size=200)
In [98]: values = pd.Series(np.concatenate([comp1, comp2]))
In [99]: sns.distplot(values, bins=100, color='k')
7. 散点图或点图
1.
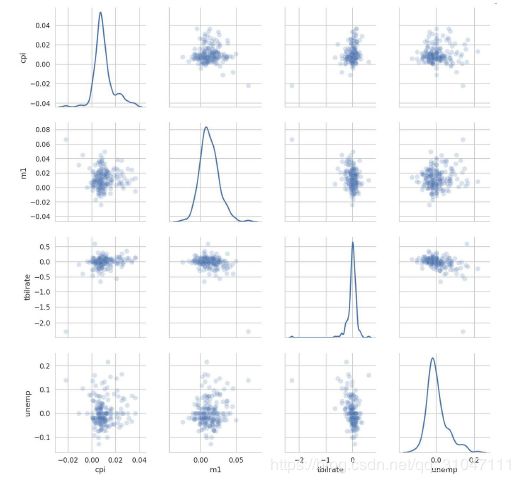
In [100]: macro = pd.read_csv('examples/macrodata.csv')
In [101]: data = macro[['cpi', 'm1', 'tbilrate', 'unemp']]
In [102]: trans_data = np.log(data).diff().dropna()
In [103]: trans_data[-5:]
Out[103]:
cpi m1 tbilrate unemp
198 -0.007904 0.045361 -0.396881 0.105361
199 -0.021979 0.066753 -2.277267 0.139762
200 0.002340 0.010286 0.606136 0.160343
201 0.008419 0.037461 -0.200671 0.127339
202 0.008894 0.012202 -0.405465 0.042560
In [105]: sns.regplot('m1', 'unemp', data=trans_data)
Out[105]: <matplotlib.axes._subplots.AxesSubplot at 0x7fb613720be0>
In [106]: plt.title('Changes in log %s versus log %s' % ('m1', 'unemp'))

In [107]: sns.pairplot(trans_data, diag_kind='kde', plot_kws={'alpha': 0.2})
9. 分面网格和分类数据
1.
In [108]: sns.factorplot(x='day', y='tip_pct', hue='time', col='smoker', kind='bar', data=tips[tips.tip_pct < 1])

2.
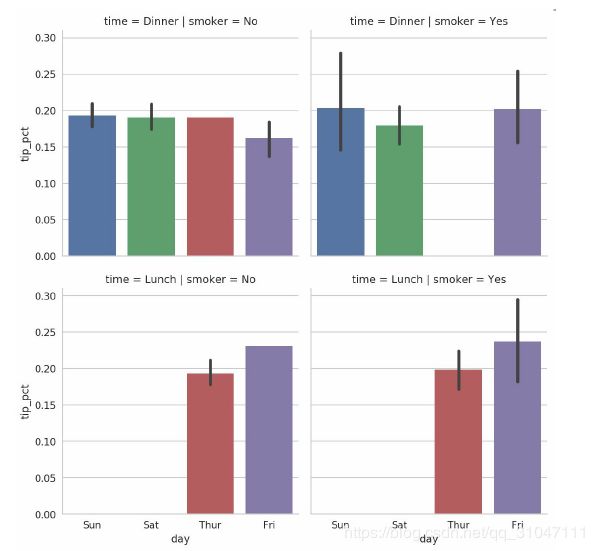
In [109]: sns.factorplot(x='day', y='tip_pct', row='time',col='smoker',kind='bar', data=tips[tips.tip_pct < 1])
3.
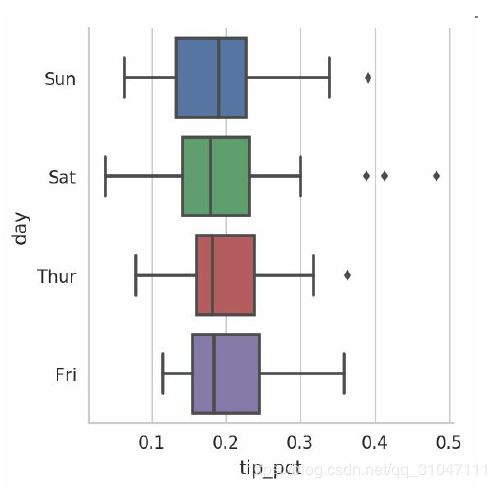
In [110]: sns.factorplot(x='tip_pct', y='day', kind='box',data=tips[tips.tip_pct < 0.5])
第十章 数据聚合与分组操作
I、GroupyBy机制
df = pd.DataFrame({'key1' : ['a', 'a', 'b', 'b', 'a'],'key2' : ['one', 'two', 'one', 'two', 'one'], 'data1' : np.random.randn(5), 'data2' : np.random.randn(5)})
1.
grouped = df['data1'].groupby(df['key1'])
grouped.mean() 【按key1进行分组,并计算data1列的平均值】
2.
means = df['data1'].groupby([df['key1'], df['key2']]).mean() 【按key1、key2进行分组,并计算data1列的平均值,得到具有一个层次化索引的Series】
means.unstack()
3.
states = np.array(['Ohio', 'California', 'California','Ohio', 'Ohio'])
years = np.array([2005, 2005, 2006, 2005, 2006])
df['data1'].groupby([states, years]).mean() 【利用自定义数组的位置与值来分组】
4.
df.groupby('key1').mean() 【注:这儿变成DataFrame来进行分组】
df.groupby(['key1', 'key2']).mean()
df.groupby(['key1', 'key2']).size()
- 遍历各分组
1.
for name, group in df.groupby('key1'):
print(name)
print(group)
2.
for (k1, k2), group in df.groupby(['key1', 'key2']):
print((k1, k2))
print(group)
3.
pieces = dict(list(df.groupby('key1'))) 【利用分组搭建字典】
4.
grouped = df.groupby(df.dtypes, axis=1) 【groupby默认是在axis=0上进行分组的,通过设置也可以在其他任何轴上进行分组,这里根据类型分组】
for dtype, group in grouped:
print(dtype)
print(group)
- 选择一列或所有列的子集
1.
df.groupby('key1')['data1']
df.groupby('key1')[['data2']]
2.
df['data1'].groupby(df['key1']) 【等价于上面语句】
df[['data2']].groupby(df['key1'])
3.
df.groupby(['key1', 'key2'])[['data2']].mean()
- 使用字典和Series分组
1.
people = pd.DataFrame(np.random.randn(5, 5),columns=['a', 'b', 'c', 'd', 'e']
,index=['Joe', 'Steve', 'Wes', 'Jim', 'Travis'])
people.iloc[2:3, [1, 2]] = np.nan
mapping = {'a': 'red', 'b': 'red', 'c': 'blue','d': 'blue', 'e': 'red', 'f' : 'orange'}
by_column = people.groupby(mapping, axis=1) 【用字典分组】
by_column.sum()
2.
map_series = pd.Series(mapping) 【将字典转变成Series】
people.groupby(map_series, axis=1).count() 【用Series分组】
- 使用函数分组
1.
people.groupby(len).sum() 【任何被当做分组键的函数都会在各个索引值上被调用一次,其返回值就会被用作分组名称。】
2.
key_list = ['one', 'one', 'one', 'two', 'two']
people.groupby([len, key_list]).min() 【在以len为分组键的基础上,再根据key_list的位置和值进行二次分组,即结果有二级行索引】
- 根据索引层级分组
columns = pd.MultiIndex.from_arrays([['US', 'US', 'US','JP', 'JP'], [1, 3, 5, 1, 3]], names=['cty', 'tenor'])
hier_df = pd.DataFrame(np.random.randn(4, 5), columns=columns)
hier_df.groupby(level='cty', axis=1).count() 【当DataFrame有两级列索引时,可以显式选择一个列索引进行分组】
II、数据聚合
1.
grouped = df.groupby('key1')
grouped['data1'].quantile(0.9) 【使用quantile聚合函数计算样本分位数】
2.
def peak_to_peak(arr):
....: return arr.max() - arr.min()
grouped.agg(peak_to_peak) 【使用自定义函数来聚合】
- 逐列及多函数应用
1.
tips = pd.read_csv('examples/tips.csv')
tips['tip_pct'] = tips['tip'] / tips['total_bill']
grouped = tips.groupby(['day', 'smoker']) 【分组】
grouped_pct = grouped['tip_pct'] 【选列】
grouped_pct.agg('mean') 【聚合】
2.
grouped_pct.agg(['mean', 'std', peak_to_peak]) 【传入一组函数或函数名,列名默认函数名】
grouped_pct.agg([('foo', 'mean'), ('bar', np.std)]) 【显示设置列名】
3.
functions = ['count', 'mean', 'max']
result = grouped['tip_pct', 'total_bill'].agg(functions) 【对tipp_pct和totaol_bill列同时执行多个相同的函数,默认列名为函数名】
ftuples = [('Durchschnitt', 'mean'),('Abweichung', np.var)]
grouped['tip_pct', 'total_bill'].agg(ftuples) 【显式设置列名】
grouped.agg({'tip' : np.max, 'size' : 'sum'}) 【使用字典来为多个列分别制定特定的函数聚合操作】
grouped.agg({'tip_pct' : ['min', 'max', 'mean', 'std'], 'size' : 'sum'})
- 返回不含行索引的聚合数据
tips.groupby(['day', 'smoker'], as_index=False).mean()
III、应用:通用拆分-应用-联合
def top(df, n=5, column='tip_pct'):
return df.sort_values(by=column)[-n:]
top(tips, n=6)
tips.groupby('smoker').apply(top) 【top函数在DataFrame的各个片段上调用,然后结果由
pandas.concat组装到一起,并以分组名称进行了标记,即将由smoker得到的分组分别应用函数top】
tips.groupby(['smoker', 'day']).apply(top, n=1, column='total_bill') 【在上条语句的基础上,显式设置了top函数的实参】
result = tips.groupby('smoker')['tip_pct'].describe()
result.unstack('smoker')
- 压缩分组键
tips.groupby('smoker', group_keys=False).apply(top)
- 分位数与桶分析
1.
frame = pd.DataFrame({'data1': np.random.randn(1000),'data2':np.random.randn(1000)})
quartiles = pd.cut(frame.data1, 4) 【利用cut获得范围】
def get_stats(group):
return {'min': group.min(), 'max': group.max(),'count': group.count(), 'mean': group.mean()}
grouped = frame.data2.groupby(quartiles)
grouped.apply(get_stats).unstack() 【利用分位数(范围)来对数据集进行分组,并在组内应用函数】
2.
grouping = pd.qcut(frame.data1, 10, labels=False) 【利用qcut获得范围】
grouped = frame.data2.groupby(grouping)
grouped.apply(get_stats).unstack()
- 示例:使用指定分组值填充缺失值
1.
s = pd.Series(np.random.randn(6))
s[::2] = np.nan
s.fillna(s.mean())
2.
states = ['Ohio', 'New York', 'Vermont', 'Florida', 'Oregon', 'Nevada', 'California', 'Idaho']
group_key = ['East'] * 4 + ['West'] * 4
data = pd.Series(np.random.randn(8), index=states)
data[['Vermont', 'Nevada', 'Idaho']] = np.nan
data.groupby(group_key).mean()
fill_mean = lambda g: g.fillna(g.mean()) 【用分组内的值来填充分组中的NA值,利用对象的自带方法】
data.groupby(group_key).apply(fill_mean)
fill_values = {'East': 0.5, 'West': -1}
fill_func = lambda g: g.fillna(fill_values[g.name]) 【同样的功能,但利用的是外部字典和分组的名字】
data.groupby(group_key).apply(fill_func)
- 示例:随机采样与排列:从一个大数据集中随机抽取(进行替换或不替换)样本以进行蒙特卡罗模拟(Monte Carlo simulation)或其他分析工作。
suits = ['H', 'S', 'C', 'D']
card_val = (list(range(1, 11)) + [10] * 3) * 4
base_names = ['A'] + list(range(2, 11)) + ['J', 'K', 'Q']
cards = []
for suit in ['H', 'S', 'C', 'D']:
cards.extend(str(num) + suit for num in base_names)
deck = pd.Series(card_val, index=cards)
def draw(deck, n=5):
return deck.sample(n) 【随机从样本集中采取5行】
draw(deck)
get_suit = lambda card: card[-1]
deck.groupby(get_suit).apply(draw, n=2)
deck.groupby(get_suit, group_keys=False).apply(draw, n=2)
- 示例:分组加权平均和相关性
df = pd.DataFrame({'category': ['a', 'a', 'a', 'a','b', 'b', 'b', 'b'],'data': np.random.randn(8), 'weights': np.random.rand(8)})
grouped = df.groupby('category')
get_wavg = lambda g: np.average(g['data'], weights=g['weights']) 【加权平均】
grouped.apply(get_wavg)
- 示例:逐组线性回归
IV、数据透视表与交叉表
tips.pivot_table(index=['day', 'smoker'])
tips.pivot_table(['tip_pct', 'size'], index=['time', 'day'], columns='smoker') 【选取tip_pct和size列作为数据列】
tips.pivot_table(['tip_pct', 'size'], index=['time', 'day'],columns='smoker', margins=True) 【传入margins=True添加分项小计。这将会添加标签为All的行和列,其值对应于单个等级中所有数据的分组统计】
tips.pivot_table('tip_pct', index=['time', 'smoker'],columns='day', aggfunc=len, margins=True) 【使用其他的聚合函数,将其传给aggfunc即可。例如,使用count或len可以得到有关分组大小的交叉表(计数或频率):】
tips.pivot_table('tip_pct', index=['time', 'size', 'smoker'],columns='day', aggfunc='mean', fill_value=0)
- 交叉表:是一种用于计算分组频率的特殊透视表(crosstab)
pd.crosstab(data.Nationality, data.Handedness, margins=True) 【利用Nationality的值来作为行索引,Handedness列的值作为列索引】
pd.crosstab([tips.time, tips.day], tips.smoker, margins=True) 【将time和day列的值作为二级行索引】
第十八章 思维导图