传统匹配模型详解(附代码)
文本匹配是NLU中的一个核心问题,虽然基于深度学习的文本匹配算法大行其道,但传统的文本匹配算法在项目中也是必要的。本文详解了传统的文本匹配算法Jaccard、Levenshtein、Simhash、Bm25、VSM的原理及其代码分享给大家,若有不足之处,请大家指出。
1. 概述
在实际工程项目,不论是基于交互的还是基于表示的文本匹配,往往都会结合传统的字面匹配算法来综合评估两段文本的匹配程度。至此,“文本匹配”系列文章更新完结,后期会针对性解读某种文本匹配算法及其实操,敬请期待。
2. 算法解读
2.1 Jaccard相似度
-
算法描述
两句子分词后词语的交集中词语数与并集中词语数之比。
-
代码实现
def sim_jaccard(s1, s2):
"""jaccard相似度"""
s1, s2 = set(s1), set(s2)
ret1 = s1.intersection(s2) # 交集
ret2 = s1.union(s2) # 并集
sim = 1.0 * len(ret1) / len(ret2)
return sim2.2 编辑距离相似度
-
算法描述
一个句子转换为另一个句子需要的编辑次数,编辑包括删除、替换、添加,然后使用最长句子的长度归一化得相似度。
-
代码实现
def sim_edit(s1, s2):
"""编辑距离归一化后计算相似度"""
# def edit_sim(s1, s2):
# import Levenshtein # 第三方库实现
# maxLen = max(len(s1), len(s2))
# dis = Levenshtein.distance(s1, s2)
# sim = 1 - dis * 1.0 / maxLen
# return sim
def edit_distance(str1, str2):
len1, len2 = len(str1), len(str2)
dp = np.zeros((len1 + 1, len2 + 1))
for i in range(len1 + 1):
dp[i][0] = i
for j in range(len2 + 1):
dp[0][j] = j
for i in range(1, len1 + 1):
for j in range(1, len2 + 1):
temp = 0 if str1[i - 1] == str2[j - 1] else 1
dp[i][j] = min(dp[i - 1][j - 1] + temp, min(dp[i - 1][j] + 1, dp[i][j - 1] + 1))
return dp[len1][len2]
# 1. 计算编辑距离
res = edit_distance(s1, s2)
# 2. 归一化到0~1
maxLen = max(len(s1), len(s2))
sim = 1 - res * 1.0 / maxLen
return sim2.3 simhash相似度
-
算法描述
先计算两句子的simhash二进制编码,然后使用海明距离计算,最后使用两句的最大simhash值归一化得相似度。
-
代码实现
def sim_simhash(s1, s2):
"""先计算两文档的simhash值,然后使用汉明距离求相似度"""
# 1. 计算文本simhash值
a_simhash = Simhash(s1, f=64)
b_simhash = Simhash(s2, f=64)
max_hashbit = max(len(bin(a_simhash.value)), len(bin(b_simhash.value)))
# 2. 计算汉明距离汉明距离
distance = a_simhash.distance(b_simhash)
# 3. 归一化到0~1
sim = 1 - distance / max_hashbit
return sim2.4 Bm25相似度
-
算法描述
先计算查询问句中每个词语相对于候选文档的相似度分数scorei(qi, d),然后将每个scorei累加得查询问句与当前候选文档的相似度得分score。
![]()
其中wi为词语的逆文档频率,R(qi,d)为词语与候选文档的得分:
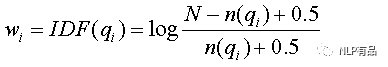

其中k1、b为调节因子,通常设为k1=2,b=0.75,f(qi, D)为单词在当前候选文档中的词频,|D|为当前候选文本长度,avgdl为语料库中所有文档的平均长度。
-
代码实现
def sim_bm25(s1, s2, s_avg=6.05, k1=2.0, b=0.75):
"""BM25算法计算文本相似度"""
def score_w(idf_w, fid, len_d):
"""计算query中某词与候选文档的相关度得分"""
ra = fid * (k1 + 1)
rb = fid + k1 * (1 - b + b * len_d / s_avg)
return idf_w * (ra / rb)
sim = 0
len_d = len(s2)
# 1. 分词
s1_list, s2_list = jieba.lcut(s1), jieba.lcut(s2)
# 2. 计算s1中每个词与s2的相关度得分并累加得s1与s2的相关度
for w in s1_list:
idf_w = idf.get(w, 1)
fid = s2_list.count(w)
score = score_w(idf_w, fid, len_d)
sim += score
return sim2.5 词向量平均求余弦相似度
-
算法描述
(1)使用词向量表示问句中的每一个单词;
(2)累加求平均词向量得句子的向量表示;
(3)最后计算两向量的余弦距离得相似度。
-
代码实现
def sim_vecave(s1, s2):
"""词向量平均后计算余弦距离"""
# 1.分词
s1_list, s2_list = jieba.lcut(s1), jieba.lcut(s2)
# 2.词向量平均得句向量
v1 = np.array([voc[s] for s in s1_list if s in voc])
v2 = np.array([voc[s] for s in s2_list if s in voc])
v1, v2 = v1.mean(axis=0), v2.mean(axis=0)
# 3.计算cosine,并归一化为相似度
sim = cosine(v1, v2)
return sim2.6 词向量通过词的idf加权平均求余弦相似度
-
算法描述
(1)使用词向量表示问句中的每一个单词;
(2)使用词的idf值对词向量进行加权,按理来说应该使用词的tfidf值进行加权来体现此的重要性程度,由于问句所有词几乎都出现一次,所以使用idf和使用tfidf是等价的;
(3)累加求平均词向量得句子的向量表示;
(4)最后计算两向量的余弦距离得相似度。
-
代码实现
def sim_vecidf(self, s1, s2):
"""词向量通过idf加权平均后计算余弦距离"""
v1, v2 = [], []
# 1. 词向量idf加权平均
for s in jieba.cut(s1):
idf_v = idf.get(s, 1)
if s in voc:
v1.append(1.0 * idf_v * voc[s])
v1 = np.array(v1).mean(axis=0)
for s in jieba.lcut(s2):
idf_v = idf.get(s, 1)
if s in voc:
v2.append(1.0 * idf_v * voc[s])
v2 = np.array(v2).mean(axis=0)
# 2. 计算cosine
sim = self.cosine(v1, v2)
return sim3. 总结
至此,“文本匹配”系列文章更新完结,其中基于交互的解读请阅读【基于交互模型的文本匹配方法】,基于表示的解读请阅读【基于表示模型的文本匹配方法】。
福利小放送:有需要的小伙伴文末扫码关注公众号,后台回复‘NLPTLS’,下载封装好的传统文本相似度算法代码。
更多NLP相关技术干货,请关注我的微信公众号【NLP有品】
