sklearn自带数据集的使用以及特征提取、特征预处理
一、sklearn自带数据集的使用
1.导入鸢尾花数据集,查看你数据集的描述以及特征
from sklearn.datasets import load_iris
def datasets_demo():
iris = load_iris()
print("鸢尾花数据集:\n",iris)
print("查看数据集描述:\n",iris["DESCR"])
print("查看特征值的名字:\n",iris.feature_names)
print("查看特征值:\n",iris.data)
print("查看特征值形状:\n",iris.data.shape)
return None
if __name__ == "__main__":
datasets_demo()
2.划分数据集
sklearn.model_selection.train_test_split()方法用来划分数据集
参数:
- x:数据集的特征值
- y:数据集的标签值
- test_size:测试集的大小,默认为0.2
- random_state:随机数种子,不同的种子会造成不同的随机采样结果,相同的种子结果相同
返回:训练集特征值、测试集特征值、训练集标签值、测试集标签值
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def datasets_demo():
#获取数据集
iris = load_iris()
print("鸢尾花数据集:\n",iris)
print("查看数据集描述:\n",iris["DESCR"])
print("查看特征值的名字:\n",iris.feature_names)
print("查看特征值:\n",iris.data)
print("查看特征值形状:\n",iris.data.shape)
#数据集的划分
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.2,random_state=22)
print("训练集的特征值:\n",x_train,x_train.shape)
print("测试集的特征值:\n",x_test,x_test.shape)
return None
if __name__ == "__main__":
datasets_demo()
二、特征工程
数据和特征决定机器学期的上限、而模型和算法只是接近这个上限
- pandas:一个数据读取非常方便以及基本的处理格式的工具
- sklearn:对于特征的处理提供了强大接口
特征工程包含:特征提取、特征预处理、特征降维
2.1 特征提取
将任意数据(文本护着图像)转化为可用于机器学习的数字特征
sklearn.feature_extraction
2.1.1 字典特征提取
对字典数据进行特征值化
- sklearn.feature_extraction.DictVectorzier(sparse=True,…)
将特征值都处理成one-hot编码
DictVectorizer.fit_transform(x) 参数x:字典或者包含字典的迭代器,返回值:返回sparse矩阵
DictVectorizer.inverse_transform(x) 参数x:array数组或者sparse矩阵,返回值:转换之前数据格式
DictVectorizer.get_feature_names()返回类别名称
使用:
对一下数据进行特征提取
[{‘city’:‘北京’,‘temperature’:100},
{‘city’:‘上海’,‘temperature’:60},
{‘city’:‘深圳’,‘temperature’:30}]
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
def dict_demo():
data = [{'city':'北京','temperature':100},{'city':'上海','temperature':60},{'city':'深圳','temperature':30}]
#实例一个转换器类
transfer = DictVectorizer(sparse=False)
#调用fit_transform()
data_new = transfer.fit_transform(data)
print("data_new:\n",data_new)
print("特征名称:\n",transfer.get_feature_names())
return None
if __name__== "__main__":
dict_demo()
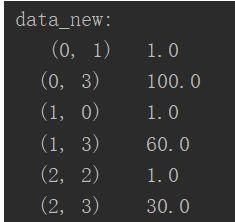
这里可以看到输出并不是我们想象中的二维数组,这是因为当我们实例化DictVectorizer时,他默认有一个参数sparse=True,如果想要得到二维数组形式,需要将sparse=False,但两者应该是等价的,前者对应后者在数组中的位置

2.1.2文本特征提取
- sklearn.feature_extraction.text.CountVectorizer()
统计每一个样本特征值出现的次数
例:英文文本分词
{"Life is short,i like like python",
"Life is too long,i dislike python"}
def count_demo():
"""
文本特征提取
"""
data = {"Life is short,i like like python","Life is too long,i dislike python"}
transfer=CountVectorizer()
data_new=transfer.fit_transform(data)
print(data_new)
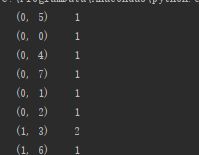
这里我们看到输出又不是我们想要的,这是我想同上面的例子一样在CountVectorizer中加入sparse=False发现行不通,但是sparse矩阵里面有一个默认的方法toarray(),我们可以直接调用这个方法
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
def count_demo():
data = {"Life is short,i like like python","Life is too long,i dislike python"}
#实例化一个转化器
transfer = CountVectorizer()
#调用transform
data_new = transfer.fit_transform(data)
print("data_new:\n",data_new.toarray())
print("特征名字:\n",transfer.get_feature_names())
return None
if __name__ == '__main__':
count_demo()

如果是中文的话,需要用到jieba分词
data = {"在北上广深,软考证书可以混个工作居住证,也是一项大的积分落户筹码。",
"升职加薪必备,很多企业人力资源会以此作为审核晋升的条件。",
"简历上浓彩重抹一笔,毕竟是国家人力部、工信部承认的IT高级人才。"}
data_new=[]
for sent in data:
data_new.append(" ".join(list(jieba.cut(sent))))
print(data_new)
使用jieba将中文文本分词后转换为列表,然后用空格拼接成字符串,然后把三句话的结果放到列表里。
剩下的和上面英文文本的分词一样
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def cut_word(text):
return " ".join(list(jieba.cut(text)))
def count_chinese_demo():
data = {"在北上广深,软考证书可以混个工作居住证,也是一项大的积分落户筹码。",
"升职加薪必备,很多企业人力资源会以此作为审核晋升的条件。",
"简历上浓彩重抹一笔,毕竟是国家人力部、工信部承认的IT高级人才。"}
data_new=[]
for sent in data:
data_new.append(cut_word(sent))
#实例化一个转化器
transfer = CountVectorizer()
#调用transform
data_final = transfer.fit_transform(data_new)
print("data_new:\n",data_final.toarray())
print("特征名字:\n",transfer.get_feature_names())
return None
if __name__ == '__main__':
count_chinese_demo()
![]()
- sklearn.feature_extraction.text.TfidfVectorizer()
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类
def Tfidf():
data = {"在北上广深,软考证书可以混个工作居住证,也是一项大的积分落户筹码。",
"升职加薪必备,很多企业人力资源会以此作为审核晋升的条件。",
"简历上浓彩重抹一笔,毕竟是国家人力部、工信部承认的IT高级人才。"}
data_new = []
for sent in data:
data_new.append(" ".join(list(jieba.cut(sent))))
transfer =TfidfVectorizer()
data_final = transfer.fit_transform(data_new)
print(data_final.toarray())
print(transfer.get_feature_names())
2.2 特征预处理
无量纲化,使不同规格的数据转换到同一规格
sklearn.preprocessing
2.2.1 归一化
通过原始数据进行变换把数据映射到 [0,1](默认)之间
sklearn.preprocessing.MinMaxScaler(feature_range=(0,1)…)
- MinMaxScalar.fit_transform(X)
参数X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后的形状相同的array

import pandas as pd
from sklearn.preprocessing import MinMaxScaler
def minmax_demo():
data=pd.read_csv("D:\\tools\python\pythondata.txt")
data=data.iloc[:,:3] #只取数据的前三列
print("data:\n",data)
transfer=MinMaxScaler() #默认0到1
data_new=transfer.fit_transform(data)
print("data_new:\n",data_new)
minmax_demo()

数据根据最大值和最小值进行计算,但这两个值非常容易受异常点影响,所有这种方法鲁棒性较差,只适合传统精确小数据场景。
2.2.2 标准化
通过对原始数据进行变换把数据变换到均值为0,标准差为1的范围内

sklearn.preprocessing.StandardScaler()
- StandardScaler.fit_transform(X)
参数X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后的形状相同的array
经过处理之后,对每列来说,所以体验数据都聚集在均值为0附近,标准差为1
def stand_demo():
data=pd.read_csv("D:\\tools\python\pythondata.txt")
data=data.iloc[:,:3] #只取数据的前三列
print("data:\n",data)
transfer=StandardScaler() #默认0到1
data_new=transfer.fit_transform(data)
print("data_new:\n",data_new)
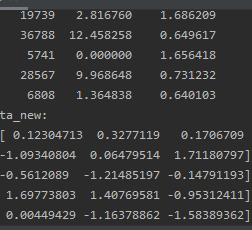
在已有样本足够多的的情况下比较稳定,适合现代嘈杂的大数据场景