HBase之Phoenix与HBase简介以及安装部署和使用
文章目录
- 1.HBase与Phoenix简介
- 2.HBase入们
- 2.1 (重要)版本选择
- 2.2 单点部署
- 2.2.1 解压
- 2.2.2 修改hbase-env.sh 配置
- 2.2.3 修改hbase-site.sh 配置
- 2.2.4 添加环境变量
- 2.2.5 启动以及命令行使用
- 2.3 HBase shell窗口命令简单使用
- 2.4HBase的读写流程
- 3.Phoenix入们
- 3.1 (重要)版本选择
- 3.2部署
- 3.2.1解压
- 3.2.2拷贝server的jar包并重启HBase
- 3.2.3使用DBeaver连接Phoenix
- 3.3使用DBeaver进行增删改查
- 3.4 Mysql到Phoenix的数据类型转换
- 3.5 Phoenix 结合 Hadoop Prouducts开发
1.HBase与Phoenix简介
-
Phoenix和HBase都是Apache的顶级项目。
-
HBase用于数据存储以及快速查询,不适合数据分析
-
HBase是列式存储数据库,它的列是动态的列,号称一张表能存储百亿行,百万列
-
HBase数据存储格式都是字符串
-
HBase是通过rowkey、column(特定cf)、timestamp 来确定一个列的值
-
HBase的put操作相当于upsert操作
-
Phoenxi是具有OLTP和OLAP的功能的SQL框架组件
-
Phoenxi数据存储是HBase,通过它可以解决HBase客户端难操作、HBase无法创建二级索引的问题
-
Phoenix可以对接Spark、Hive、Pig, Flume, and Map Reduce,生产上主要是对接Spark
-
Phoenix的OLTP功能在生产上不用,大数据分析事务功能是个鸡肋也必然是个坑,任务失败,需解决问题并重跑。
2.HBase入们
2.1 (重要)版本选择
为了契合生产上的CDH-5.12.0,故选择Hbase-1.2.0-CDH5.12.0,注意CDH的1.2.0是Cloudera上的,它在开源基础上做了一些BUG修复以及功能添加,可能兼容了更高的一些版本的新功能。
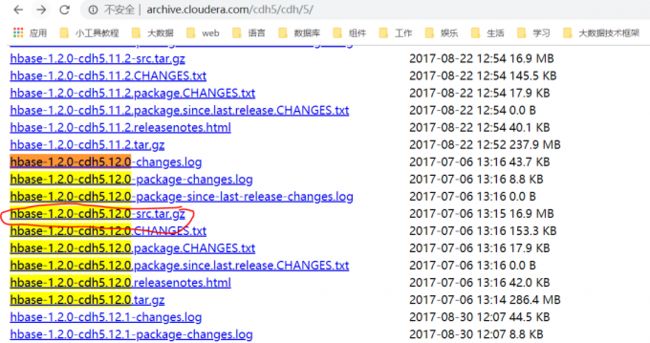
2.2 单点部署
部署详细过程可参考官网
2.2.1 解压
[hadoop@hadoop001 ~]$ cd ~/soft/
[hadoop@hadoop001 soft]$ tar -zxvf hbase-1.2.0-cdh5.12.0.tar.gz -C ~/app/
[hadoop@hadoop001 soft]$ cd ~/app/hbase-1.2.0-cdh5.12.0/
2.2.2 修改hbase-env.sh 配置
#添加JAVA_HOME
[hadoop@hadoop001 hbase-1.2.0-cdh5.12.0]$ vim conf/hbase-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_45
2.2.3 修改hbase-site.sh 配置
[hadoop@hadoop001 hbase-1.2.0-cdh5.12.0]$ mkdir -p /home/hadoop/app/hbase-1.2.0-cdh5.12.0/hbasedata
[hadoop@hadoop001 hbase-1.2.0-cdh5.12.0]$ mkdir -p /home/hadoop/app/hbase-1.2.0-cdh5.12.0/zkdata
[hadoop@hadoop001 hbase-1.2.0-cdh5.12.0]$ vim conf/hbase-site.xml
hbase.rootdir
file:///home/hadoop/app/hbase-1.2.0-cdh5.12.0/hbasedata
hbase.zookeeper.property.dataDir
/home/hadoop/app/hbase-1.2.0-cdh5.12.0/zkdata
hbase.unsafe.stream.capability.enforce
false
2.2.4 添加环境变量
[hadoop@hadoop001 hbase-1.2.0-cdh5.12.0]$ vim ~/.bash_profile
export HBASE_HOME=/home/hadoop/app/hbase-1.2.0-cdh5.12.0
export PATH=$HBASE_HOME/bin:$PATH
[hadoop@hadoop001 hbase-1.2.0-cdh5.12.0]$ source ~/.bash_profile
[hadoop@hadoop001 hbase-1.2.0-cdh5.12.0]$ which start-hbase.sh
~/app/hbase-1.2.0-cdh5.12.0/bin/start-hbase.sh
2.2.5 启动以及命令行使用
HMaster访问页面:http://192.168.175.135:60010
#启动,启动成功JPS会出现一额HMaster的进程
[hadoop@hadoop001 hbase-1.2.0-cdh5.12.0]$ bin/start-hbase.sh
#关闭HBase服务
[hadoop@hadoop001 hbase-1.2.0-cdh5.12.0]$ bin/stop-hbase.sh
若是CDH环境,先找到HMaster的机器,然后找到切换大hbase用户,若无法切换用户,则在passwd文件修改用户目录以及执行脚本。切换hbase用户后,which hbase可查看hbase命令的软连接指向,通过alternatives --config xxx查询该命令的真正指向,若没问题,则可直接hbase shell。当然若该节点有gateway权限则可直接hbase shell运行。
2.3 HBase shell窗口命令简单使用
命令+回车键,就去显示命令帮助以及案列
#进入HBase shell命令行窗口
[hadoop@hadoop001 hbase-1.2.0-cdh5.12.0]$ bin/hbase shell
#HTable的增删该查
hbase(main):001:0> create 'test', 'cf'
hbase(main):002:0> list 'test'
hbase(main):003:0> describe 'test'
hbase(main):004:0> put 'test', 'row1', 'cf:a', 'value1'
hbase(main):005:0> put 'test', 'row1', 'cf:a', 'value1'
hbase(main):006:0> put 'test', 'row1', 'cf:a', 'value1'
hbase(main):006:0> get 'test', 'row1'
hbase(main):008:0> disable 'test'
hbase(main):011:0> drop 'test'
#退出HBase shell命令行窗口
hbase(main):016:0> quit
2.4HBase的读写流程
HBase读写是直接请求region server节点,而HMaster主要有表的DDL操作、以及region的分割和合并。
3.Phoenix入们
3.1 (重要)版本选择
由于Cloudear没有Phoenix组件,过我们选择Apache的Phoenix,为了契合HBase1.2.0,我只能从Apache中选择了,但是上面选择的HBase1.2.0和Apache是有差别的,这就比较头疼了,肯定会在部分功能上需要改代码进行整合的。 幸好,apache推出了CDH版本的Phoenix,根据向下相对兼容以及取相近版本规则(CDH Vsersion >=phoenix cdh version),选择了phoenix-4.14.0-cdh5.11.2。
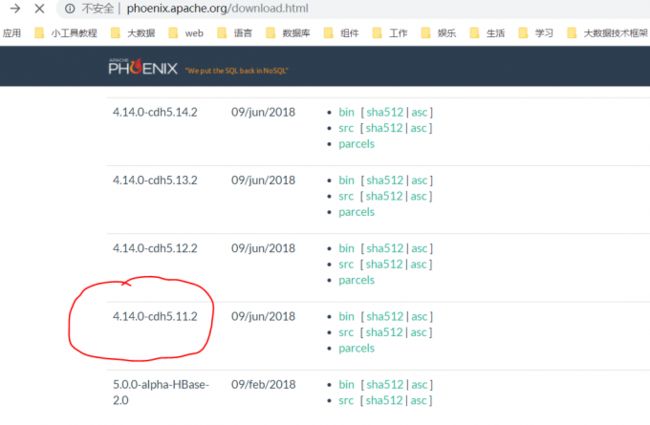
3.2部署
3.2.1解压
[hadoop@hadoop001 ~]$ cd ~/soft/
[hadoop@hadoop001 soft]$ tar -zxvf apache-phoenix-4.14.0-cdh5.11.2-bin.tar.gz -C ~/app/
[hadoop@hadoop001 soft]$ cd ~/app/apache-phoenix-4.14.0-cdh5.11.2-bin/
3.2.2拷贝server的jar包并重启HBase
将phoenix-[version]-server.jar考到所有的Region server节点的hbase lib目录下。若是Cloudera安装的HBase,则lib默认在:/opt/cloudera/parcels/CDHlib/hbase/lib
[hadoop@hadoop001 apache-phoenix-4.14.0-cdh5.11.2-bin]$ cp phoenix-4.14.0-cdh5.11.2-server.jar ~/app/hbase-1.2.0-cdh5.12.0/lib/
重启HBase
[hadoop@hadoop001 apache-phoenix-4.14.0-cdh5.11.2-bin]$ ~/app/hbase-1.2.0-cdh5.12.0/bin/stop-hbase.sh
[hadoop@hadoop001 apache-phoenix-4.14.0-cdh5.11.2-bin]$ ~/app/hbase-1.2.0-cdh5.12.0/bin/start-hbase.sh
3.2.3使用DBeaver连接Phoenix
连接的过程: phoenix client–>phoenix server–>HBase Region Server
这里我先将phoenix-[version]-client.jar sz下载到windos,然后使用DBeaver进行Phoenix链接。
第一步:打开DBeaver的Phoenix的链接配置
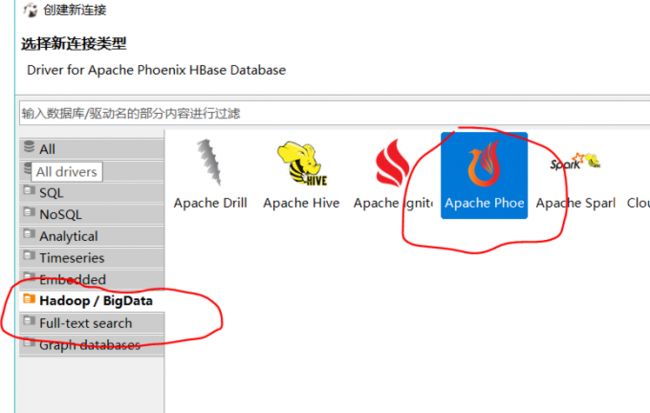
第二步:将驱动设置为phoenix-[version]-client.jar
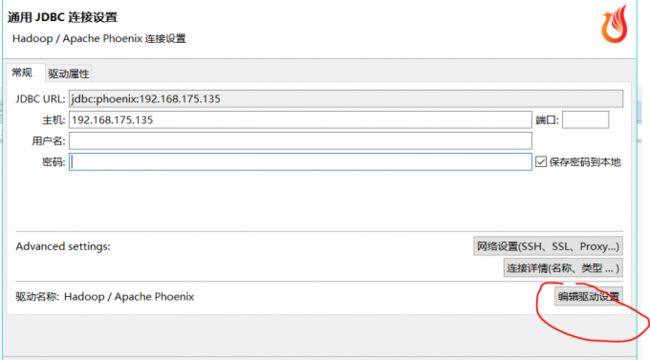
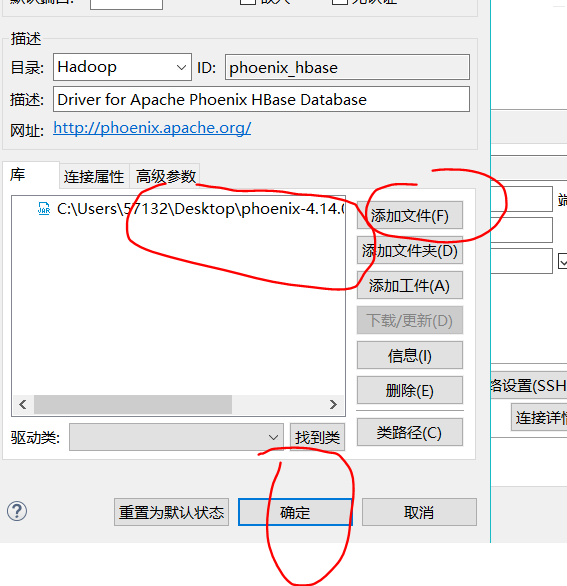
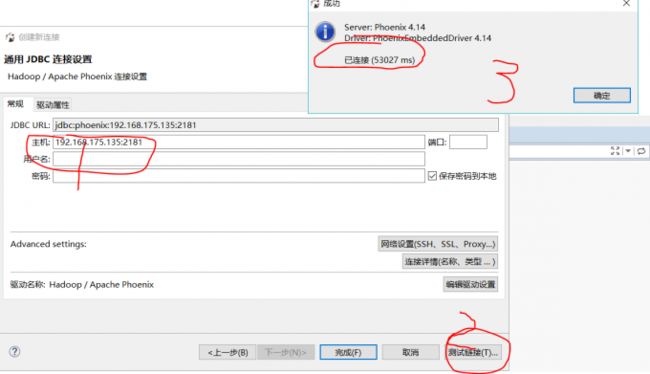
第三步:连接测试,注意一定是要写zk的地址,Phoenix以及HBase的通信都是通过ZK进行协调的。
- 若我么们代码开发中涉及phoenix,则也需要拷贝此jar包到工程中
3.3使用DBeaver进行增删改查
#创建表
CREATE TABLE wsktest(
id integer PRIMARY KEY,
name varchar(20)
)
#插入或更新数据,注意若PRIMARY KEY 的id记录存在即更新,否则是插入
UPSERT INTO WSKTEST VALUES(1,'大王');
UPSERT INTO WSKTEST VALUES(2,'二王');
UPSERT INTO WSKTEST VALUES(3,'三弟');
UPSERT INTO WSKTEST VALUES(1,'二傻');
#查询
SELECT * FROM WSKTEST;
SELECT * FROM WSKTEST WHERE ID=2
#删除数据
DELETE FROM WSKTEST WHERE id = 2;
#删除表
DROP TABLE WSKTEST;
观察HBase中的对应的表数据,rowkey就是PRIMARY KEY,且多了一个列,值为x
\x80\x00\x00\x01 column=0:\x00\x00\x00\x00, timestamp=1559261964835, value=x
\x80\x00\x00\x01 column=0:\x80\x0B, timestamp=1559261964835, value=\xE4\xBA\x8C\xE5\x82\xBB
- 采坑,HBase的表是区分大小写,但是DBeaver是不区分的。
- 采坑,Phoenix 的timezone(时区)默认是国外了,而国内的是上海时区,这样导致时间类型数据入Phoenix后时间戳对不上。
- 采坑,使用Phoenix 进行select时及其小概率会出现两行一模一样的数据,重复数据,过会儿查就没了
- 采坑,
- Phoenix 结合HBase 使用起来像是操作mysql,但是HBase强大的动态列功能Phoenix貌似不行,个人觉得它有点儿阉割了HBase,故并不是任何场景都适合使用HBase整合Phoenix,对关系型数据入Hive倒是挺好用的。
3.4 Mysql到Phoenix的数据类型转换
char/varchar --> varchar
int --> integer
datatime/timestamp --> timestamp
注意:1、采坑,db中的char/varchar转到Phoenix时长度要放长两倍,不然可能放不进去。
3.5 Phoenix 结合 Hadoop Prouducts开发
由于Phoenix的底层时HBase,故并不适合使用Phoenix进行数据,但是我们可以使用Spark SQL、Hive等进行数据分析(注意,该分析方式速度并没有数据直接列式存储hdfs并使用那些分析引擎快,大批量数据还是老老实实直接怼数据,不要绕一圈那么麻烦)
Phoenix的github上提供了很多结合这个组件的的开发代码案列,如结合Spark开发