resnet的演化(res2net,resnext,se-resnet,sk-resnet,resnest)
resnet的演化(res2net,resnext,se-resnet,sk-resnet,resnest)
1. 总体演化过程
演化方向主要为两种: split-transform-merge、squeeze-and-attention。
split-transform-merge:通过卷积的可分离性质,增加网络宽度,从而在不增加算力的情况下增加网络的表征能力(不同维度通道特征的融合)。
squeeze-and-attention:核心想法是应用全局上下文预测 channel-wise 的注意力因素(孰轻孰重)。
黄色箭头为演化方向和过程(颜色的深浅代表借鉴的程度),resnest完美的借鉴了两种思想。
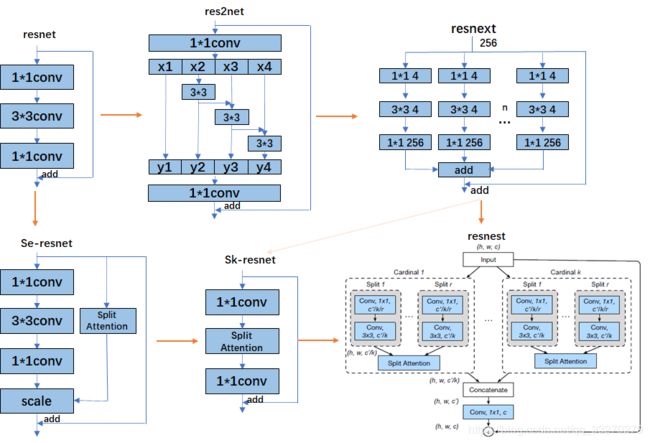
2. split Attention
2.1 se-split Attention:
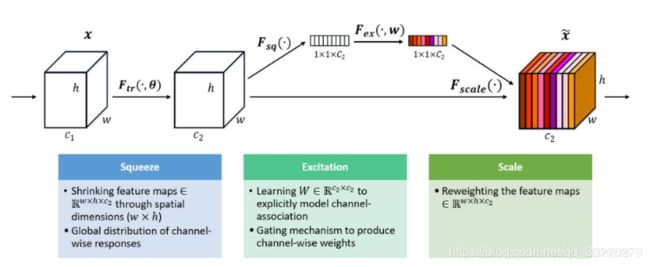
上图是SE 模块的示意图。给定一个输入 x,其特征通道数为 c_1,通过一系列卷积等一般变换后得到一个特征通道数为 c_2 的特征。与传统的 CNN 不一样的是,接下来通过三个操作来重标定前面得到的特征。
Squeeze 操作:
顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。

公式非常简单,就是一个global average pooling,将H * W * C的输入转换成1 * 1 * C的输出。
Excitation 操作:
它是一个类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。
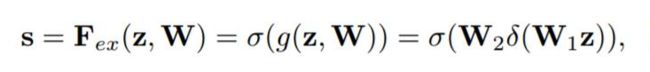
直接看最后一个等号,前面squeeze得到的结果是z,这里先用W1乘以z,就是一个全连接层操作,W1的维度是C/r * C,这个r是一个缩放参数,在文中取的是16(yolo-nano网络中取的8),这个参数的目的是为了减少channel个数从而降低计算量。又因为z的维度是1 * 1 * C,所以W1z的结果就是1 * 1 * C/r;然后再经过一个ReLU层,输出的维度不变;然后再和W2相乘,和W2相乘也是一个全连接层的过程,W2的维度是C * C/r,因此输出的维度就是1 * 1 *C;最后再经过sigmoid函数,得到s。
s其实是本文的核心,它是用来刻画tensor U中C个feature map的权重。而且这个权重是通过前面这些全连接层和非线性层学习得到的,因此可以end-to-end训练。这两个全连接层的作用就是融合各通道的feature map信息,因为前面的squeeze都是在某个channel的feature map里面操作。
Reweight 的操作:
将 Excitation 的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
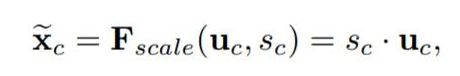
就是channel-wise multiplication,uc是一个二维矩阵,sc是一个数,也就是权重,因此相当于把uc矩阵中的每个值都乘以sc。
具体的应用案例:
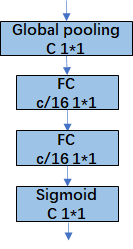
这里我们使用 global average pooling 作为 Squeeze 操作。紧接着两个 Fully Connected 层组成一个 Bottleneck 结构去建模通道间的相关性,并输出和输入特征同样数目的权重。我们首先将特征维度降低到输入的 1/16,然后经过 ReLu 激活后再通过一个 Fully Connected 层升回到原来的维度。这样做比直接用一个 Fully Connected 层的好处在于:1)具有更多的非线性,可以更好地拟合通道间复杂的相关性;2)极大地减少了参数量和计算量。然后通过一个 Sigmoid 的门获得 0~1 之间归一化的权重,最后通过一个 Scale 的操作来将归一化后的权重加权到每个通道的特征上。
2.2 sk-split Attention:
SKNet同样是一个轻量级嵌入式的模块,其灵感来源是,我们在看不同尺寸不同远近的物体时,视觉皮层神经元接受域大小是会根据刺激来进行调节的。那么对应于CNN网络,一般来说对于特定任务特定模型,卷积核大小是确定的,那么是否可以构建一种模型,使网络可以根据输入信息的多个尺度自适应的调节接受域大小呢?
基于这种想法,作者提出了Selective Kernel Networks(SKNet)。结构图如下
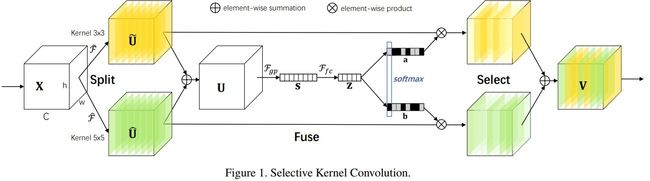
这个网络主要分为Split,Fuse,Select三个操作
Split:
这里的Split是指对输入向量X进行不同卷积核大小的完整卷积操作。如结构图所示,对X进行Kernel3×3和Kernel5×5的卷积操作。
Fuse:
这部分和SE模块的处理大致相同。Fgp为全局平均池化操作,Ffc为先降维再升维的两层全连接层。需要注意的是输出的两个矩阵a和b,其中矩阵b为冗余矩阵,在如图两个分支的情况下b=1-a。
Select:
Select操作对应于SE模块中的Scale。区别是Select使用a和b两个权重矩阵对split的两部分特征图进行加权操作,然后求和得到最终的输出向量V。
2.3 resnest-split Attention:

第一步:
输入的特征图可以根据通道维数被分为几组,特征图组的数量由一个基数超参数 K 给出,得到的特征图组被称为基数组(cardinal group)。研究者引入了一个新的底数超参数 R,该参数规定了基数组的 split 数量。
input1,2,…,r为split分的特征组合,全局平均池化操作,实现跨通道融合。
第二步:
为先降维再升维的两层全连接层(dense为全连接层),升维的dense做了分组操作,来预测输入不同组卷积的注意力因素。较于se、sk的注意力机制,更加细腻。
第三步:
不同的组的注意力因素权重,加权到原始的分组特征中,并进行特征融合,实现注意力的分配任务。
3.性能表现
ImageNet 2012 数据集上的图像分类性能:
| para(M) | Gflops | top-1 acc(%)244* | |
|---|---|---|---|
| resnet-50 | 25.5 | 4.14 | 76.15 |
| res2net-50 | – | 4.20 | 77.99 |
| resnext-50 | 25.0 | 4.24 | 77.77 |
| se-resnet-50 | 27.7 | 4.25 | 78.88 |
| sk-resnet-50 | 27.5 | 4.47 | 79.21 |
| resnest-50 | 27.5 | 5.39 | 81.13 |