zeppelin在CDH上的安装及使用 -- 填坑
zeppelin可以跟spark、flink、kylin等直接访问,将结果可视化显示。在安装zeppelin的过程中碰到各种问题,跟陈大神一起研究了好几天,终于把问题解决。我们安装zeppelin的目的主要是用spark快速的验证kylin的统计的可视化结果是否跟spark直接计算的可视化结果一致。
刚开始选择下载二进制文件(zeppelin-0.7.3-bin-all.tgz)直接安装,很简单,直接解压后运行./bin/zeppelin-daemon.sh start即可。运行官方案例时报如下错误:
.......
报scala中的方法找不到,查看了下scala2.11的源码没有此方法,我们的用的是CDH5.12.1自带的scala是2.10版本。因此,我们选择自己编译安装。
编译过程中又是各种报错。源文件:zeppelin-0.7.3.tgz
编译:
[C:\Users\yiming\Desktop\zeppelin-0.7.3]$ mvn clean package -Pbuild-distr -Pyarn -Dspark.version=1.6.0 -Dhadoop.version=2.6.0-cdh5.12.1 -Pscala-2.10 -Ppyspark -Psparkr -Pvendor-repo -DskipTests
报错:
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-antrun-plugin:1.7:run (zip-pyspark-files) on project zeppelin-spark-dependencies_2.10: An Ant BuildException has occured: Warning: Could not find file C:\Users\yiming\Desktop\zeppelin2\zeppelin-0.7.3\zeppelin-0.7.3\spark-dependencies\target\spark-1.6.0\python\lib\py4j-0.8.2.1-src.zip to copy.
[ERROR] around Ant part ...
[ERROR] -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn
报没有找到对应的py4j包,进入对应的目录可以看到对应的是py4j-0.9-src.zip,在maven仓库中找到对应版本的包拷贝过来即可。
再次编译又报错了:
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------[INFO] Total time: 03:24 min
[INFO] Finished at: 2018-04-20T14:39:52+08:00
[INFO] Final Memory: 135M/1506M
[INFO] ------------------------------------------------------------------------
in-spark-dependencies_2.10:jar:0.7.3: Could not find artifact org.apache.hadoop:hadoop-client:jar:2.6.0-cdh5.7.0-SNAPSHOT in nexus (http://192.168.30.112:8081/nexus/content/groups/public) -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
这个坑一直没找到问题的原因,查看了源码也没搞清楚我指定的是cdh5.12.1的包,它却给我下cdg5.6.0的快照包。
接下来把编译命令中的-Dspark.version=1.6.0去掉之后再次编译:
[C:\Users\yiming\Desktop\zeppelin-0.7.3]$mvn clean package -Pbuild-distr -Pyarn -Pspark-1.6 -Ppyspark -Dhadoop.version=2.6.0-cdh5.12.1 -Phadoop-2.6 -DskipTests
又报如下错误:
[WARNING] warning [email protected]: Deprecated[WARNING] warning [email protected]: ?? Thanks for using Babel: we recommend using babel-preset-env now: please read babeljs.io/env to update!
[WARNING] warning grunt > [email protected]: CoffeeScript on NPM has moved to "coffeescript" (no hyphen)
[WARNING] warning grunt > [email protected]: Please update to minimatch 3.0.2 or higher to avoid a RegExp DoS issue
[WARNING] warning grunt > glob > [email protected]: Please update to minimatch 3.0.2 or higher to avoid a RegExp DoS issue
[WARNING] warning grunt > findup-sync > glob > [email protected]: Please update to minimatch 3.0.2 or higher to avoid a RegExp DoS issue
[WARNING] warning grunt > glob > [email protected]: please upgrade to graceful-fs 4 for compatibility with current and future versions of Node.js
[WARNING] warning load-grunt-tasks > multimatch > [email protected]: Please update to minimatch 3.0.2 or higher to avoid a RegExp DoS issue
[WARNING] warning grunt-wiredep > wiredep > glob > [email protected]: Please update to minimatch 3.0.2 or higher to avoid a RegExp DoS issue
[WARNING] warning grunt-google-fonts > cssparser > [email protected]: Package no longer supported. Contact [email protected] for more info.
[WARNING] warning grunt-htmlhint > htmlhint > jshint > [email protected]: Please update to minimatch 3.0.2 or higher to avoid a RegExp DoS issue
[WARNING] warning grunt-replace > applause > cson-parser > [email protected]: CoffeeScript on NPM has moved to "coffeescript" (no hyphen)
[WARNING] warning grunt-wiredep > wiredep > bower-config > [email protected]: please upgrade to graceful-fs 4 for compatibility with current and future versions of Node.js
[ERROR] error An unexpected error occurred: "https://registry.yarnpkg.com/autoprefixer: connect ETIMEDOUT 104.16.63.173:443".
[INFO] info If you think this is a bug, please open a bug report with the information provided in "C:\\Users\\yiming\\Desktop\\zeppelin2\\zeppelin-0.7.3\\zeppelin-0.7.3\\zeppelin-web\\yarn-error.log".
[INFO] info Visit https://yarnpkg.com/en/docs/cli/install for documentation about this command.
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary:
[INFO]
[INFO] Zeppelin ........................................... SUCCESS [ 4.689 s]
[INFO] Zeppelin: Interpreter .............................. SUCCESS [ 20.595 s]
[INFO] Zeppelin: Zengine .................................. SUCCESS [ 16.617 s]
[INFO] Zeppelin: Display system apis ...................... SUCCESS [ 15.265 s]
[INFO] Zeppelin: Spark dependencies ....................... SUCCESS [03:20 min]
[INFO] Zeppelin: Spark .................................... SUCCESS [ 26.079 s]
[INFO] Zeppelin: Markdown interpreter ..................... SUCCESS [ 2.110 s]
[INFO] Zeppelin: Angular interpreter ...................... SUCCESS [ 1.747 s]
[INFO] Zeppelin: Shell interpreter ........................ SUCCESS [ 1.081 s]
[INFO] Zeppelin: Livy interpreter ......................... SUCCESS [ 15.909 s]
[INFO] Zeppelin: HBase interpreter ........................ SUCCESS [ 9.540 s]
[INFO] Zeppelin: Apache Pig Interpreter ................... SUCCESS [ 12.706 s]
[INFO] Zeppelin: PostgreSQL interpreter ................... SUCCESS [ 2.039 s]
[INFO] Zeppelin: JDBC interpreter ......................... SUCCESS [ 2.582 s]
[INFO] Zeppelin: File System Interpreters ................. SUCCESS [ 2.553 s]
[INFO] Zeppelin: Flink .................................... SUCCESS [ 12.948 s]
[INFO] Zeppelin: Apache Ignite interpreter ................ SUCCESS [ 4.426 s]
[INFO] Zeppelin: Kylin interpreter ........................ SUCCESS [ 1.072 s]
[INFO] Zeppelin: Python interpreter ....................... SUCCESS [ 8.722 s]
[INFO] Zeppelin: Lens interpreter ......................... SUCCESS [ 8.945 s]
[INFO] Zeppelin: Apache Cassandra interpreter ............. SUCCESS [ 48.842 s]
[INFO] Zeppelin: Elasticsearch interpreter ................ SUCCESS [ 5.995 s]
[INFO] Zeppelin: BigQuery interpreter ..................... SUCCESS [ 2.445 s]
[INFO] Zeppelin: Alluxio interpreter ...................... SUCCESS [ 5.870 s]
[INFO] Zeppelin: Scio ..................................... SUCCESS [ 42.271 s]
[INFO] Zeppelin: web Application .......................... FAILURE [01:14 min]
[INFO] Zeppelin: Server ................................... SKIPPED
[INFO] Zeppelin: Packaging distribution ................... SKIPPED
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 09:10 min
[INFO] Finished at: 2018-04-20T15:55:23+08:00
[INFO] Final Memory: 452M/1686M
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal com.github.eirslett:frontend-maven-plugin:1.3:yarn (yarn install) on project zeppelin-web: Failed to run task: 'yarn install --no-lockfile' failed. (error code 1) -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoFailureException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn
日志中报了很多版本过期的错误,因此我们打开源码web Application的目录下的pom文件,发现yarn的版本设定太低,将
export JAVA_HOME=/opt/java
export HADOOP_CONF_DIR=/etc/hadoop/conf:/etc/hive/conf
export HADOOP_HOME=/opt/cloudera/parcels/CDH-5.12.1-1.cdh5.12.1.p0.3/lib/hadoop
export SPARK_HOME=/opt/cloudera/parcels/CDH-5.12.1-1.cdh5.12.1.p0.3/lib/spark
export MASTER=yarn-client
export ZEPPELIN_LOG_DIR=/var/log/zeppelin
export ZEPPELIN_PID_DIR=/var/run/zeppelin
export ZEPPELIN_WAR_TEMPDIR=/var/tmp/zeppelin我是在window下编译的,然后linux服务器上安装的。
接下来使用又是各种问题。。。。
打开zeppelin web ,http://192.168.xxx.xxx:8080/ ,新建一个notebook,用官方的一个以spark为编译器的例子:
import org.apache.commons.io.IOUtils
import java.net.URL
import java.nio.charset.Charset
// Zeppelin creates and injects sc (SparkContext) and sqlContext (HiveContext or SqlContext)
// So you don't need create them manually
// load bank data
// val bankText = sc.parallelize(
// IOUtils.toString(
// new URL("https://s3.amazonaws.com/apache-zeppelin/tutorial/bank/bank.csv"),
// Charset.forName("utf8")).split("\n"))
val bankText = sc.textFile("/tmp/bank.csv")
case class Bank(age: Integer, job: String, marital: String, education: String, balance: Integer)
val bank = bankText.map(s => s.split(";")).filter(s => s(0) != "\"age\"").map(
s => Bank(s(0).toInt,
s(1).replaceAll("\"", ""),
s(2).replaceAll("\"", ""),
s(3).replaceAll("\"", ""),
s(5).replaceAll("\"", "").toInt
)
).toDF()
bank.registerTempTable("bank")
bank.show(10)发现此过程调用的是zeppelin lib目录下的hadoop-common-2.6.0.jar包,查看源码,确实没有getRpcTimeout(configuration)方法,只有getRpcTimeout()方法。getRpcTimeout(configuration是CDH包装的方法,此方法不需要再指定hadoop namenode的地址,直接访问yarn-site.xml和hdfs-core.xml文件读取yarn和namenode的地址。解决办法是在zeppelin lib的目录下建立一个软连接,将hadoop-*-2.6.0.jar包指向CDH的包并备份原来的包:
[root@xxx-7 lib]#mv /opt/zeppelin/lib/hadoop-common-2.6.0.jar /opt/zeppelin/lib/hadoop-common-2.6.0.jar.bak
[root@xxx-7 lib]#mv /opt/zeppelin/lib/hadoop-auth-2.6.0.jar /opt/zeppelin/lib/hadoop-auth-2.6.0.jar.bak
[root@xxx-7 lib]#mv /opt/zeppelin/lib/hadoop-annotations-2.6.0.jar /opt/zeppelin/lib/hadoop-annotations-2.6.0.jar.bak
[root@xxx-7 lib]#ln -s /opt/cloudera/parcels/CDH/jars/hadoop-common-2.6.0-cdh5.12.1.jar /opt/zeppelin/lib/hadoop-common-2.6.0.jar
[root@xxx-7 lib]#ln -s /opt/cloudera/parcels/CDH/jars/hadoop-auth-2.6.0-cdh5.12.1.jar /opt/zeppelin/lib/hadoop-auth-2.6.0.jar
[root@xxx-7 lib]#ln -s /opt/cloudera/parcels/CDH/jars/hadoop-annotations-2.6.0-cdh5.12.1.jar /opt/zeppelin/lib/hadoop-annotations-2.6.0.jar
接下来运行又报如下错误:
同样的问题,还是包的问题,将zeppelin lib下面的几个包替换为CDH下面的几个包,并备份原来的包。这里可以参考文章:https://www.iteblog.com/archives/1570.html
[root@xxx-7 lib]#ln -s /opt/cloudera/parcels/CDH-5.12.1-1.cdh5.12.1.p0.3/jars/jackson-annotations-2.3.1.jar ../lib/jackson-annotations-2.3.1.jar
[root@xxx-7 lib]#ln -s /opt/cloudera/parcels/CDH-5.12.1-1.cdh5.12.1.p0.3/jars/jackson-core-2.3.1.jar ../lib/jackson-core-2.3.1.jar
[root@xxx-7 lib]#ln -s /opt/cloudera/parcels/CDH-5.12.1-1.cdh5.12.1.p0.3/jars/jackson-databind-2.3.1.jar ../lib/jackson-databind-2.3.1.jar

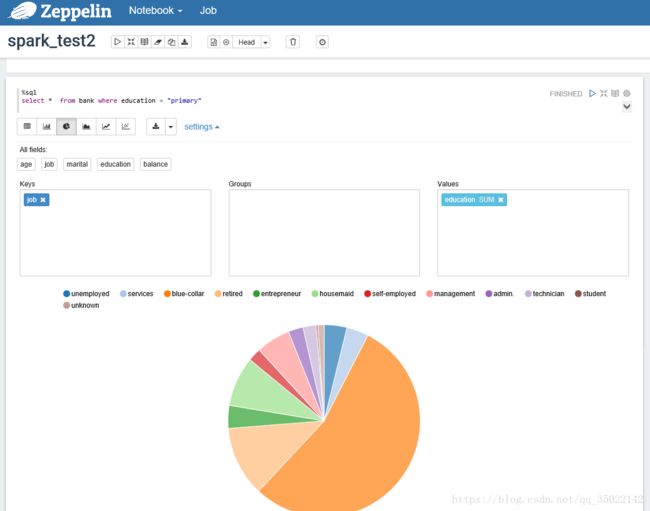
来,炫一下zeppelin的图!!受教育程度为初级的员工为蓝领的占比一半。。。。几种常用的满足一般的需要!!
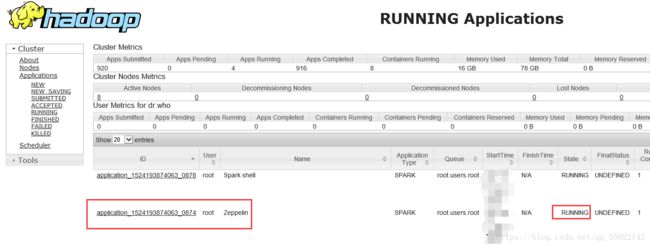
zeppelin notebook提交的任务如下,一直是running状态。。。。
参考文章:
在Cloudera CDH上部署Zeppelin和SparkR Interpreter:
https://rui.sh/deploy_zeppelin_on_CDH_with_Spark_R_Interpreter.html
How-to: Install Apache Zeppelin on CDH(CDH官网):http://blog.cloudera.com/blog/2015/07/how-to-install-apache-zeppelin-on-cdh/?_ga=1.149178290.504978146.1467271525
从源码编译安装(zeppelin官网):https://zeppelin.apache.org/docs/0.7.3/install/build.html#build-profiles
Spark交互式开发平台Zeppelin部署:http://www.bihell.com/2016/08/31/Zeppelin-Setup/