Apache Zeppelin学习记录2
Apache Zeppelin学习记录2
文章目录
- Apache Zeppelin学习记录2
- 前言
- 一、基础调用
- 二、带参数调用
-
- 1.代码块要增加一行z.textbox("folder_path", "input")
- 2.读取result
- 总结
前言
上一章讲了如何使用zeppelin来接入python,本节我们来看看如何使用RESTful API操作zeppelin的paragraph。
提示:官方API文档见https://zeppelin.apache.org/docs/0.10.1/usage/rest_api/notebook.html
一、基础调用
-
anonymous模式不需要用户名密码即可直接访问。如图,
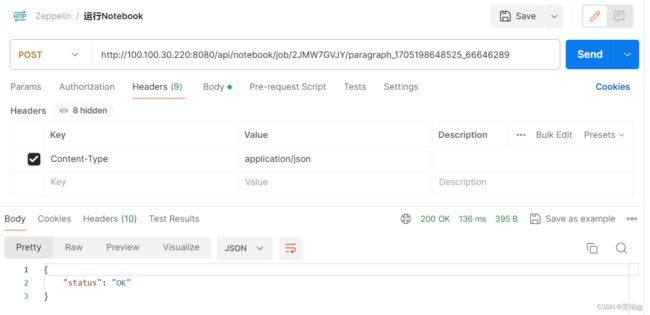
根据API文档我们知道,运行模式有两种,同步和异步,区别在于url不同,
同步是run:http://[zeppelin-server]:[zeppelin-port]/api/notebook/run/[noteId]/[paragraphId]
异步是job:http://[zeppelin-server]:[zeppelin-port]/api/notebook/job/[noteId]/[paragraphId] -
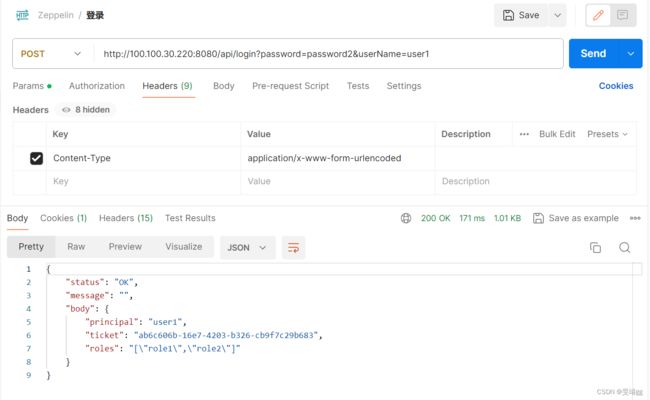
shiro模式,需要先调用/api/login,然后再调用相应的接口,如图,
二、带参数调用
1.代码块要增加一行z.textbox(“folder_path”, “input”)
具体API说明参考:
https://zeppelin.apache.org/docs/0.10.1/usage/rest_api/notebook.html#run-a-paragraph-synchronously
https://zeppelin.apache.org/docs/0.10.1/usage/dynamic_form/intro.html#text-input-form-1
代码如下(示例):
%python
import pandas as pd
import os
# 文件夹路径
folder_path = z.textbox("folder_path", "input")
# 读取文件夹中的所有 CSV 文件
csv_files = [f for f in os.listdir(folder_path) if f.endswith('.csv')]
。。。
请求发送时如下,增加body
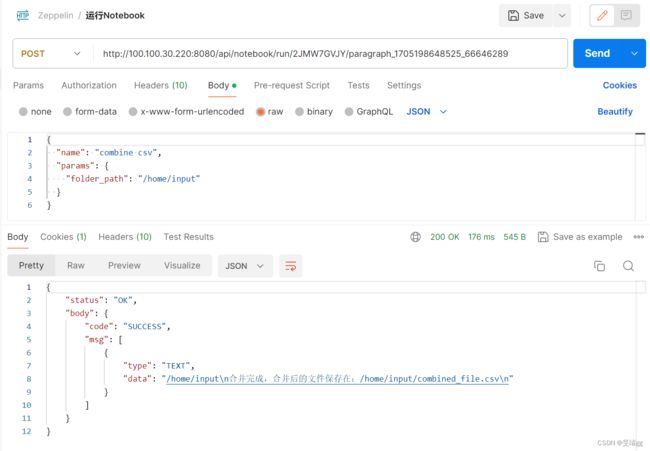
2.读取result
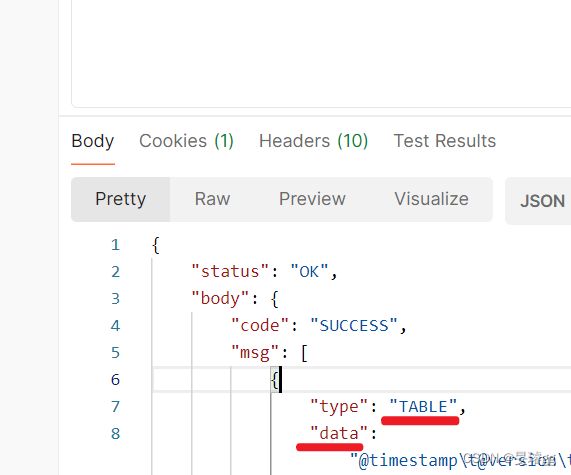
在 Apache Zeppelin 中,同步方式请求执行paragraph的返回值会把paragraph的输出放在msg.data里,如下截图,需要根据msg.type对data进行进一步分析处理。

异步方式没有直接提供获取某个段落(paragraph)执行结果的特定 API ,如果想要获取段落执行结果,可以考虑以下4种方法:
-
通过 Zeppelin Web 页面手动导出结果: 在 Zeppelin 的 Web 界面中,执行你感兴趣的段落,然后手动导出结果。通常,你可以在段落执行后找到一个导出按钮或选项,以将执行结果保存为文件(如 JSON、CSV 等)。这样,你可以手动导出并保存结果数据。
-
直接查询 Zeppelin 的数据库: Zeppelin 通常使用数据库(如 Derby)来存储笔记本(notebook)和段落的元数据。你可以直接查询 Zeppelin 的数据库,获取相关段落的执行结果。请注意,直接查询数据库需要对 Zeppelin 的数据库结构有一定的了解,并且这种方法可能涉及到一些安全性和稳定性的考虑。
-
将paragraph的输出写入某个特定的文件或数据库中,然后用第三方API去读取这个结果。
-
通过notebook获取paragraph的执行结果,执行GET /api/notebook/[notebook id],在得到的response里解析paragraphs的results。
总结
以上就是今天要讲的内容,后面我们可以对zeppelin进行更深入的使用。