day02 - Scrapy基本使用2
一、Scrapy之CrawlSpider
作用:可根据正则自动从响应中提取对应的url并可将响应传递给对应的解析函数处理
(区别于使用scrapy.Request()构造请求的方式)
- 生成爬虫文件方式
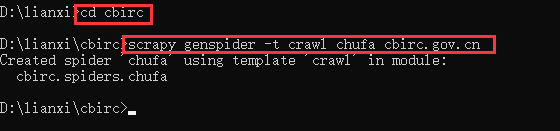
scrapy genspider –t crawl 爬虫名 允许爬虫的范围域名
- 提取url方式
Rule(LinkExtractor(allow=r’对应的url正则’), callback=‘函数名’,follow=True’),
参数:
callback:需要将提取到的url响应传递的解析函数名
follow:设置是否继续从提取的url响应中继续提取url
注
①crawlscrapy中不能再有以parse为名字的解析函数,这个方法被crawlspider用来实现基础url提取等功能
②一个Rule对象可以接受很多参数,首先第一个是包含url规则的LinkExtractor对象
③不指定callback函数的请求下,如果follow为True,汉族该rule的url还会被请求
③如果多个Rule都满足某个url,会从rules中选择第一个满足的额进行操作。
案例:提取中国银行保险监督管理委员会中监督动态的内容
1.创建爬虫项目
2.创建爬虫文件
3.编写爬虫文件
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
import re
class CfSpider(CrawlSpider):
name = 'cf'
allowed_domains = ['circ.gov.cn']
start_urls = ['http://www.circ.gov.cn/web/site0/tab5240/module14430/page1.html']
#定义提取url地址规则
rules = (
#LinkExtractor 连接提取器,提取url地址
#callback 提取出来的url地址的response会交给callback处理
#follow 当前url地址的响应是够重新进过rules来提取url地址,
Rule(LinkExtractor(allow=r'/web/site0/tab5240/info\d+\.htm'), callback='parse_item'),
Rule(LinkExtractor(allow=r'/web/site0/tab5240/module14430/page\d+\.htm'),follow=True),
)
#parse函数有特殊功能,不能定义
def parse_item(self, response):
item = {}
item["title"] = re.findall("(.*?)",response.body.decode())[0]
item["publish_date"] = re.findall("发布时间:(20\d{2}-\d{2}-\d{2})",response.body.decode())[0]
print(item)
二、下载中间件middleware的使用(定义类,并在setting中开启)
默认方法:
process_request() :当每个请求通过下载中间件时,此方法会被调用(处理请求)
process_response() :当下载器完成http请求,传递响应给引擎时会被调用(处理响应)
注
①process_request()方法需要return返回值,process_response()方法不需要返回值
②process_request()除添加随机user_agent,也可添加代理request.meta['proxy']="代理ip"
编写下载中间件middlewares文件
import random
class RandomUserAgentMiddleware:
def process_request(self,request,spider):
ua = random.choice(spider.settings.get("USER_AGENTS_LIST"))
request.headers["User-Agent"] = ua
class CheckUserAgent:
def process_response(self,request,response,spider):
# print(dir(response.request))
print(request.headers["User-Agent"])
return response
设置settings文件
USER_AGENTS_LIST = [ "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5" ]
三、scrapy模拟登陆
作用:一般用于用户只能登陆后才能访问的页面(例如:个人主页)
1.使用requests模块模拟登陆
- 使用session发送请求
- 使用post发送请求,并携带cookie值
- 使用selenium定位登录框并输入账号密码
2.重写start_requests函数使用scrapy.Resquest()构造cookie请求登录
案例: 登录人人网
- 创建爬虫项目
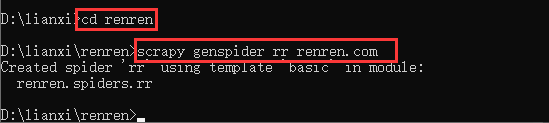
- 创建爬虫文件
- 编写爬虫文件
import scrapy
import re
class RrSpider(scrapy.Spider):
name = 'rr'
allowed_domains = ['renren.com']
start_urls = ['http://www.renren.com/974448504/profile']
def start_requests(self):
#b对应url请求头中的cookie值
cookies = "anonymid=k87hm4kj-rp9g49; _r01_=1; taihe_bi_sdk_uid=6c30e53112a131f638fc306513187e36; jebe_key=2ef75b9c-9822-4d6e-a522-b5015f535d1e%7Cf4e5c3486b211d6dcfb06ee4e8d4fda2%7C1585150502044%7C1%7C1585150501815; depovince=GW; _de=620394AD748BDF3F707A6D1BB4458FCA; ln_uact=15732683807; ln_hurl=http://head.xiaonei.com/photos/0/0/men_main.gif; jebecookies=3462f550-fabb-4765-a3ea-1b97cde9649a|||||; JSESSIONID=abcU_amPFmGMUgUfUnDix; ick_login=4089c86a-4a57-414f-91bd-ca577147e814; taihe_bi_sdk_session=ad7670f62bb52fb8aa765400a07fa007; p=36a33c567c3fac48401de815ae54383e4; first_login_flag=1; t=dc0ec8e0f495ed78ed2810913cf4b6a84; societyguester=dc0ec8e0f495ed78ed2810913cf4b6a84; id=974448504; xnsid=e2c34d4b; loginfrom=syshome; jebe_key=2ef75b9c-9822-4d6e-a522-b5015f535d1e%7Cbb55f4fbf3484c42721868809c89f900%7C1589628419420%7C1%7C1589628419490; wp_fold=0"
cookies = {i.split("=")[0]: i.split("=")[1] for i in cookies.split("; ")}
yield scrapy.Request(
self.start_urls[0], # 个人主页url
callback=self.parse,
cookies=cookies # start_url请求中携带cookie
)
def parse(self, response):
'''处理start_urls[0]的响应'''
print(re.findall("新用户83807", response.body.decode()))
yield scrapy.Request(
'http://www.renren.com/974448504/profile?v=info_timeline', # 个人资料页url
callback = self.parse_detail,
)
def parse_detail(self,response):
'''处理个人资料页url对应的响应'''
print(re.findall("新用户83807", response.body.decode()))
运行结果

注:
①如果不添加cookie值访问个人主页时,请求的url会被重定向到首页
②当第一次请求个人主页添加url后,第二次请求个人资料页时,会自动携带第一次请求设置的cookie值(原因:seting文件中默认设置会携带上次cookie值)

③可在setting文件中添加变量COOKIES_DEBUG = True来查看具体cookie传递的过程
3.使用scrapy.FormRequest()发送post请求
案例:发送post请求登录github
-
创建爬虫项目
-
创建爬虫文件

-
编写爬虫文件
import scrapy
import re
class GithubSpider(scrapy.Spider):
name = 'github'
allowed_domains = ['github.com']
start_urls = ['https://github.com/login']
def parse(self, response):
authenticity_token = response.xpath("//input[@name='authenticity_token']/@value").extract_first()
commit = "Sign in"
post_data = dict(
login="*****",
password="*****",
authenticity_token=authenticity_token,
commit=commit
)
yield scrapy.FormRequest(
"https://github.com/session",
formdata=post_data,
callback=self.after_login
)
def after_login(self,response):
print(re.findall("ZYZYLESA",response.body.decode()))
4.使用scrapy.FormRequest.from_response()方法发送post请求
作用:可以自动从url响应中寻找form表单并填写账号和密码再登录
案例:
import scrapy
import re
class Github2Spider(scrapy.Spider):
name = 'github'
allowed_domains = ['github.com']
start_urls = ['https://github.com/login']
def parse(self, response):
yield scrapy.FormRequest.from_response(
response, #自动的从response中寻找from表单
formdata={"login":"*****","password":"****"},
# 对应的键分别为账号输入框标签中name属性的值和密码输入框标签中name属性的值,值为用户的账号和密码
callback = self.after_login
)
def after_login(self,response):
print(re.findall("ZYZYLESA",response.body.decode()))