现在出现了很多关于流行语“网络规模”的宣传。人们使用大量时间,通过重新组织他们的应用架构来获取系统“规模化”。
但是什么是规模化,我们应该怎样确定能够规模化?
规模化的不同方面
宣传中主要提到关于负载的规模化。比如,只要系统可以为1 个用户工作,就能保证为 10 个用户、100 个用户或者成千上万的用户工作。想像一下,你的系统可以做到“状态无关”,那么少数真正保留的状态就能在网络中的任何处理单元进行传输和转换。如果负载是你的短板而延迟不是,那么个别需要 50-100ms 的请求就不会有问题。
另一个完全不同的方面是关于性能的规模化。比如,只要某个算法能处理1 个信息片段,它就同样能处理 10个片段、100 个片段或成千上万个片段。这个类型的规模化最适合用大O 符号 [译者注:大O表示时间复杂度 ] 来描述。延迟是规模化性能的杀手。你想尽一切可能把所有计算放在一台机器上进行,这通常称为 按比例扩大规模 。
如果有免费的午餐(并没有),我们可以无限度的联合扩展规模。先不管这个,今天我们要看看如何通过一些简单的事情改善性能。
大O 符号
Java 7 的ForkJoinPool 和 Java 8 的 并行 Stream有助于并行程序,如果你的Java 程序发布在多核处理器的机器上,这会非常有用。与在网络中不同机器间的规模化架构相比,并行的优势在于它几乎可以完全消除延迟的影响,因为所有内核都能访问相同的内存。
但不要被并行计算的效果欺骗!一定要记住两件事情:
并行消耗核心。这对于批处理来说很好,但对异步服务器(比如HTTP)简直就是噩梦。在过去的几十年中,我们有很好的理由来使用单线程 Servlet 模型。所以并行只对规模扩展有帮助。
并行不会对算法的大O符号产生影响。如果算法的时间复杂度是 O(n log n),让这个算法在 c 个核心上运行,时间复杂度会是 O(n log n / c),由于 c 在算法的复杂度中是一个微不足道的常量,你会节省一些时间,但不会降低复杂度。
·
提升性能最好的方式当然是减少复杂度。目标是获得O(1) 或者接近 O(1) 的复杂度。当然,HashMap 查找就是一个例子。但这并不总是可能的,十分不易。
如果不能降低复杂度,仍然有可能调整有问题的算法来获得更好的性能,当然你得找到问题所在。假设下面是一个算法的图示:
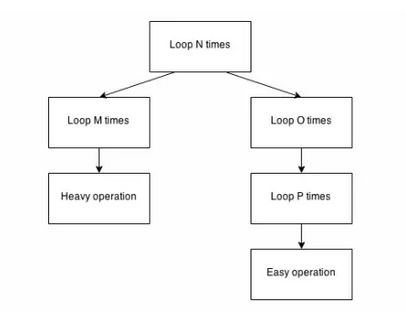
这个算法整体的复杂度是O(N 3 ),或者如果我们想处理个别的订单,复杂度是 O(N x O x P)。不过,在分析这个代码的时候,你会发现一个有趣的现象:
在你的开发矩形中,左边的分支(N -> M -> Heavy operation) 是在分析中唯一关注的分支,因为 O 和 P 的值在样本数据中都很小。
而在生产环境,右边的分支(N -> O -> P -> Easy operationor 或者 N.O.P.E. ) 才是真正出现问题的地方。你的操作团队可能使用AppDynamics 或 DynaTrace 或一些模拟软件,指出了这一点。
·
没有生产数据的情况下,你可能会迅速得出结论,需要优化“heavy operation”。然而把修改应用到生产中却毫无作用。
除了以下事实,没有任何优化方面的金科玉律:
设计良好的应用程序更容易优化
过早的优化不能解决任何性能问题,但如果应用程序设计得不好,反过来又会使它变得难以优化。
·
理论已经足够了。假设你已经发现了右边的分支才是问题所在。可能是一个简单的操作爆发了这个问题,因为它被调用了很多很多次(比如 N、O、P 很大)。 这篇文章中有一个在叶节点上必然存在 O(N 3 ) 算法的问题,请阅读它。这些优化对你的规模没有帮助。它们能快速有效地帮你提升性能,但整体算法的改善还需日后解决。
这里有10 条在 Java 中简单地进行性能优化的技巧:
1. 使用 StringBuilder
几乎所有Java 代码中你都应该考虑这个问题。避免使用 + 号。你可能会认为StringBuilder 只是个语法糖,比如:
String x = "a" + args.length + "b";
会编译成
0 new java.lang.StringBuilder [16]
3 dup
4 ldc [18]
6 invokespecial java.lang.StringBuilder(java.lang.String) [20]
9 aload_0 [args]10 arraylength11 invokevirtual java.lang.StringBuilder.append(int) : java.lang.StringBuilder [23]14 ldc [27]16 invokevirtual java.lang.StringBuilder.append(java.lang.String) : java.lang.StringBuilder [29]19 invokevirtual java.lang.StringBuilder.toString() : java.lang.String [32]22 astore_1 [x]
但是之后你需要根据条件来修改字符串,会发生什么事情呢?
String x = "a" + args.length + "b";
if (args.length == 1)
x = x + args[0];
你现在会有第二个StringBuilder,这个 StringBuilder 本来没有存在的必要,它会消耗堆内存,给 GC 增加负担。你应该这样写:
StringBuilder x = new StringBuilder("a");
x.append(args.length);
x.append("b");
if (args.length == 1);
x.append(args[0]);
分析
在上面的例子中,显式地使用StringBuilder 实例,和 Java 编译器隐式使用 StringBuilder 实例是没有关联的。但是记住,我们在 N.O.P.E 分支 。我们在每个 CPU 周期对 GC 和为 StringBuilder 分配空间所产生的浪费,都会浪费 N x O x P 倍。
总是使用StringBuilder ,不用 + 运算符是一个不错的规则。如果你的字符串构建起来很复杂,尽可能在多个方法间使用同一个 StringBuilder。这就是你在生成复杂的 SQL 时 jOOQ 所做的事情。只有一个 StringBuilder 在整个 SQL AST (Abstract Syntax Tree) 中“游走”。
如果你还有StringBuffer 引用,大声哭吧,把它们换成StringBuilder,因为你很少需要同步创建一个字符串。[译者注:StringBuffer 与 StringBuilder 的区别就在于 StringBuilder 是线程安全的,但在同步代码中没必要使用 StringBuffer,它会带来额外的性能开销。]
2. 避免正则表达式
正则表达式相对 便宜和方便。但是如果你在 N.O.P.E 分支 ,那很糟糕了。如果你必须在计算机密集的代码段中使用正则表达式,至少把Pattern的引用缓存下来,避免每次都对其重新编译:
static final Pattern HEAVY_REGEX =
Pattern.compile("(((X)*Y)*Z)*");
但是如果你的正则表达式真的很简单,就像
String[] parts = ipAddress.split("\\.");
然后你真的最好诉诸普通的char[] 或基于索引的操作。例如下面很信读的一段代码做了同样的事情:
int length = ipAddress.length();int offset = 0;int part = 0;for (int i = 0; i < length; i++) { if (i == length - 1 ||
ipAddress.charAt(i + 1) == '.') {
parts[part] =
ipAddress.substring(offset, i + 1); part++;
offset = i + 2;
}
}
这也说明了为什么你不应该过早进行优化。与split() 的版本相比,这简直不可维护。
挑战:请读者们找到更快的 方法。
分析
正则表达式很有用,但需要代价。如果你在N.O.P.E 分支 ,就必须避免正则表达式的代价。小心使用各种 JDK String 那些使用正则表达式的方法,比如String.replaceAll() 、 String.split()等。
请使用像Apache Commons Lang 这样的知名类库来操作字符串。
3. 不要使用 iterator()
这个建议不太适用于常规用例,只适用于N.O.P.E. 分支,但你也可以用用看。编写 Java-5 风格的 foreach 循环很方便。 你可以完全忽略循环内部变量,并编写:
for (String value : strings) { // Do something useful here}
然而,每当你运行到循环内部时,如果string 是一个 Iterable ,你就要创建一个新的 Iterator实例。如果你正在使用 ArrayList ,这将会在堆上分配一个含 3 个 int 的对象:
private class Itr implements Iterator { int cursor; int lastRet = -1; int expectedModCount = modCount; // ...
相反,你可以编写以下代码——等价循环体,并且在栈上仅“浪费”一个 int 值,开销低:
int size = strings.size();for (int i = 0; i < size; i++) {
String value : strings.get(i);
// Do something useful here
}
或者,你可以选择不改变链表,在数组版本上使用同样的操作:
for (String value : stringArray) { // Do something useful here}
关键点
从可写性和可读性以及从API 设计的角度来看,Iterators、Iterable 和 foreach 循环都是非常有用的。但它们在堆上为每次单独的迭代创建一个小的新实例。 如果你运行这个迭代许多次,又想避免创建这个无用的实例,可以使用基于索引的迭代。
讨论
关于上面观点相反的有趣意见(特别是使用索引访问替代迭代器)已在Reddit 上讨论研究。
4. 不要调用这些方法
一些方法简单但开销不小。在N.O.P.E.分支示例中, 我们没有在叶节点上使用这样的方法,但你可能使用到了。我们假设 JDBC 驱动程序需要耗费大量资源来计算ResultSet.wasNull() 的值。你可能会用下列代码开发SQL 框架:
if (type == Integer.class) {
result = (T) wasNull(rs,
Integer.valueOf(rs.getInt(index)));
}
// And then...static final T wasNull(ResultSet rs, T value)
throws SQLException { return rs.wasNull() ? null : value;
}
此处逻辑每次都会在你从结果集中获得一个int 之后立即调用 ResultSet.wasNull()。但getInt() 的约定是:
返回: 列的数目;如果这个值是 SQL NULL,这个值将返回 0。
因此,对上述问题的简单但可能有效的改进将是:
static final T wasNull(
ResultSet rs, T value)
throws SQLException { return (value == null ||
(value.intValue() == 0 && rs.wasNull()))
? null : value;
}
因此,这不需要过多考虑。
关键点
不要在算法的“叶节点”中调用开销昂贵的方法,而是缓存该调用,或者如果方法规约允许则规避之。
5. 使用基本类型和栈
上面的例子来自jOOQ ,它大量使用了泛型。泛型会强制对 byte、short、int 和 long 这些类型进行装箱 —— 至少在这之前: 泛型会在 Java 10 和 Valhalla 项目中实现专业化 。不过现在你的代码里并没实现这种约束,所以你得采取措施:
// Goes to the heapInteger i = 817598;
替换为下面这个:
// Stays on the stackint i = 817598;
如果你使用数组的话,情况不太妙:
// Three heap objects!
Integer[] i = { 1337, 424242 };
替换成这个:
// One heap object.int[] i = { 1337, 424242 };
关键点
当你在深入N.O.P.E. 分支时 ,要小心使用装箱类型。你可能会给 GC 制造很大的压力,因为它必须一直清理你的烂摊子。
有一个特别有效的办法对此进行优化,即使用某些基本类型,并为它创建一个巨大的一维数组,以及相应的定位变量来明确指出编码后的对象放在数组的哪个位置。
如果你对Java编程有兴趣,想要成为优秀的Java程序员,那么动力节点Java零基础班现已开启免费试学阶段,对于想学习Java编程的同学无疑是好消息,亲自考察教学质量,机会就在眼前,点击报名,针对不方便前来的同学,可以关注动力节点Java全套免费视频,赶快学起来吧