python之IO编程
什么是IO
由于程序和运行数据是在内存中驻留的,由CPU这个超快的计算核心来执行。当涉及到数据交换的地方,通常是磁盘、网络等,就需要IO接口。由于CPU和内存的速度远远高于外设的速度,那么在IO编程中就存在速度严重不匹配的问题。这时有2种解决办法,一是同步IO(CPU暂停直到数据重新写入完到磁盘中)二是,异步IO(CPU不等待,继续执行后续代码)。明显异步的复杂度高于同步IO,所以在这里只讨论同步的IO。
复习文件操作
我们都使用过文件读写,应该知道读写文件是最常见的IO操作,
所以,读写文件就是请求操作系统打开一个文件对象(文件描述符)
,然后通过操作系统提供的接口从这个文件对象中读取或写入文件。
读取文件:
with语句:
with open('xiao','w',encoding='utf-8') as e:
e.write('eric gevi')
e.write('\n')
e.write('ben,ten')
open函数:
f = open('yu.txt','a+',encoding='utf-8')
f.write('nihao')
f.close()
内存缓冲区操作StringIO和BytesIO
刚刚上面我们看到是读写文件到磁盘中,下面说在内存缓冲区中的读写操作
StringIO:
这个一眼我们就可以看出来,顾名思义,就是将文本字符串写入到内存缓冲区
然后创建一个StringIO对象,就可以像文件一样写入,这里我们用getvalue获取写入的str。
b = StringIO() #创建一个StringIO对象
b.write('你好') #写入数据
ret = b.getvalue() #获取数据
print(ret) #打印结果
也可以像文件一样读取,需要先初始化:
a = StringIO('nihao\nnihao') #初始化
while True:
f = a.readline() #这里文件操作的方法这里也可以用
if f: #判断是否有数据
print(f)
else:
break
BytesIO:
StringIO只能操作str数据,要操作我们二进制的数据就要用到我们的BytesIO了。
a = BytesIO()
a.write('一个测试数据'.encode('utf-8')) #注意:写入的不是str,是经过UTF-8编码的bytes
ret = b = a.getvalue() #同上获取
print(ret) #这里看下结果:b'\xe4\xb8\x80\xe4\xb8\xaa\xe6\xb5\x8b\xe8\xaf\x95\xe6\x95\xb0\xe6\x8d\xae'
解码这里就更简单了:
a = BytesIO()
a.write('一个测试数据'.encode('utf-8'))
ret = b = a.getvalue().decode('utf-8') #这里用什么编码的就用什么解码就可以了
print(ret) #一个测试数据
和StringIO一样我们也可以像文件一样读取:
a = BytesIO('hello,李开复'.encode('gbk'))
print(a.read())
序列化pickle和json
考虑几个问题:
1.为什么要序列化?
2.什么是序列化?
3.python中怎么使用序列化?
1.我们把数据在内存中传输的过程中或存储的时候称为序列化,也可以称为序列。
2.序列化后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
3.python提供了模块pickle和json来实现序列化。
下面我们来看一下:
pickle:
import pickle,json #先要导入两个内置模块
a = [1,2,3,4,5,6,7] #可序列化对象可以是:字典,列表 ,None,字符串,数字,浮点数,不支持set
ret = pickle.dumps(a) #python对象序列化产生一个字节流
print(ret) #b'\x80\x03]q\x00(K\x01K\x02K\x03K\x04K\x05K\x06K\x07e.'
c = pickle.loads(ret) #字节流序列转换为python对象
print(c) #[1,2,3,4,5,6,7]
f = open('yu.txt','wb')
a = {"name":'eric','age':18}
pickle.dump(a,f)
#dump将数据通过特殊的形式转换为只有python语言认识的字符串,并写入文件
f.close()
f = open('yu.txt','rb')
a = {"name":'eric','age':18}
ret = pickle.load(f)
#load从数据文件中读取数据,并转换为python的数据结构
print(ret)
f.close()
注意:dump、dumps和load、loads的区别
这里可以理解为dump操作文件对象,
dumps操作python对象,上面已经写得有了,
这里不一一赘述,load、loads就是对应的读文件对象和python对象。
json:
a = ['nihao',1,2,3,None,True,{'name':'eric'},2.31]
suam_ret = json.dumps(a) #将对象序列化
obj_python = json.loads(suam_ret) #将序列化字符串反序列化
print(obj_python)
a = ['nihao',1,2,3,None,True,{'name':'eric'},2.31]
with open('yu.txt','w+',encoding='utf-8') as f:
json.dump(a,f) #将对象序列化并保存到文件
with open('yu.txt','r',encoding='utf-8') as f:
print(json.load(f)) #将序列化字符串从文件读取并反序列化
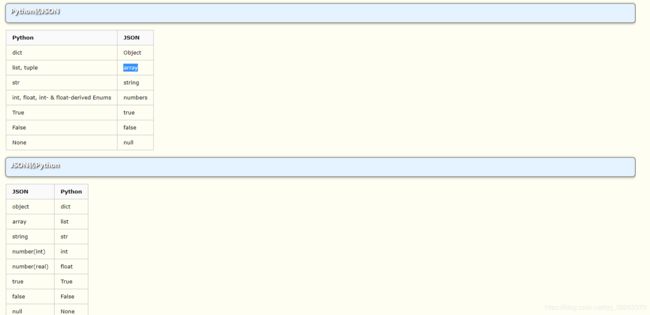
总结:
共同点: 都可以序列化和反序列化,python里面的基本数据类型
不同点:pickle可以序列化python所有的数据类型,
而json不能序列化我们的set类型,我们可能
经常听说过json,因为json是一门跨语言的数据类型
json数据遵循了共同的标准格式:xml/json(更多)
json可以在不同语言之间交换数据,这就是他的强大之处
而我们的pickle只能在python里面使用,这一点要记住。