python爬虫:BeautifulSoup_搜索文档树
搜索文档树
1、Beautiful Soup定义了很多搜索方法,这里着重介绍2个: find() 和 find_all()
2、使用find_all()类似的方法可以查找到想要查找的文档内容
过滤器
1、介绍find_all()方法前,先介绍一下过滤器的类型,这些过滤器贯穿整个搜索的API。过滤器可以被用在tag的name中,节点的属性中,字符串中或他们的混合中
2、过滤器只能作为搜索文档的参数,或者说应该叫参数类型更为贴切(即需要查找什么,就将其作为find_all()类似方法的参数)
字符串
最简单的过滤器是字符串(标签对名)。在搜索方法中传入一个字符串参数,BeautifulSoup会查找与字符串完整匹配的内容
例1:查找文档中所有的标签
from bs4 import BeautifulSoup #导入bs4库
html = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html,"lxml")#指定解析器
tag_p = soup.find_all("p")
print(tag_p)
tag_b = soup.find_all("b")#b标签对是内嵌在第一个p标签对中的
print(tag_b)
tag_a = soup.find_all("a")#a标签对是内嵌在第二个p标签对中的
print(tag_a)
"""
[The Dormouse's story
,
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
, ...
]
[The Dormouse's story]
[,
Lacie,
Tillie]
"""注:由上面的例子可以看出
1、输入结果为所有符合要求的标签对组成的列表(元素的类型为tag对象),每一对符合要求的标签对为列表中的一个元素
2、不论标签对中有什么,只要符合查找要求都会将其整个输出:a标签对中内嵌了b标签对,在查找a标签对时,也会把a中内嵌的b标签对一起输出(当然内嵌的b标签对可能是整个b标签对中的一部分)
3、a标签对中内嵌了b标签对,在查找b标签对时:只会输入符合要求的b标签对,不会输入用于内嵌b的a标签对
4、如果传入字节码参数,Beautiful Soup会当作UTF-8编码,可以传入一段Unicode 编码来避免Beautiful Soup解析编码出错
5、我们遍历列表后就可以得到一个一个的类型为tag对象的标签对,因此我们也可以对其使用tag对象的方法
例1_1:
for i in tag_a:
print(i,type(i))
print(soup.a.get("href"))
"""
http://example.com/elsie
Lacie
http://example.com/elsie
Tillie
http://example.com/elsie
"""
正则表达式
如果传入正则表达式作为参数。Beautiful Soup会通过正则表达式的match()来匹配内容
例2:找出所有以b开头的标签
from bs4 import BeautifulSoup #导入bs4库
import re
html = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html,"lxml")#指定解析器
tag_b = soup.find_all(re.compile("^b"))#返回的也是一个列表
for i in tag_b:
print(i,type(i))
print(i.name)
"""
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
body
The Dormouse's story
b
""" 注:由上面的例子可以看出
1、find_all()的搜索条件(过滤器)为正则表达式(以b开头的标签对),则在整个HTML文件中符合条件的有body标签对和b标签对,因此分别输出了两个标签对的内容
2、返回的类型为tag对象,因此我们可以使用tag对象的方法
列表
如果传入列表参数。Beautiful Soup会将与列表中任一元素匹配的内容返回
例3:找到文档中所有标签和标签
from bs4 import BeautifulSoup #导入bs4库
html = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html,"lxml")#指定解析器
tag_a_b = soup.find_all(["a","b"])#返回的也是一个列表
print(tag_a_b,type(tag_a_b))
"""
[The Dormouse's story,
,
Lacie,
Tillie]
""" 注:由上面的例子可以看出
1、需要查找多个标签对时,可以将需要查找的内容组成一个列表传到find_all()方法中作为过滤器
2、返回的结果是所有符合条件的标签对组成的列表,且其原始的类型也为tag对象
True
True可以匹配任何值。下面代码查找到所有的tag,但是不会返回字符串节点
例4:
from bs4 import BeautifulSoup
html = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html,"lxml")#指定解析器
tag = soup.find_all(True)
print(tag)
#感觉这种方法用得不是很多,所以只是了解了下,知道有这种方法就好了
方法
1、如果没有合适过滤器,那么还可以定义一个方法,方法只接受一个元素参数,如果这个方法返回True表示当前元素匹配并且被找到,如果不是则反回False
2、元素参数:HTML文档中的一个tag节点,不能是文本节点
例5:包含class属性却不包含id属性,那么将返回True
from bs4 import BeautifulSoup
html = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id')
soup = BeautifulSoup(html,"lxml")
tag = soup.find_all(has_class_but_no_id)#这个方法作为参数传入find_all()方法
print(tag)
"""
[The Dormouse's story
,
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;and they lived at the bottom of a well.
,
...
]
"""注:
上面例子中的搜索条件为有class属性但不包含id属性,因此整个HTML中p标签对符合该条件(a标签对虽然不符合,但是其是内嵌在P标签对中的,因此在输入P时会有a)
find_all( )方法
语法:
find_all(name , attrs , recursive , text , **kwargs )描述:
1、find_all()方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件
2、这里的使用方法感觉跟前面说的过滤器差不多,只是这里用的是标签对内中的属性,而过滤器用得是标签对的名字
name 参数
1、name 参数可以查找所有名字为name的tag,字符串对象会被自动忽略掉
2、搜索name参数的值可以使任一类型的 过滤器 ,字符串,正则表达式,列表,方法或是True
例6:
from bs4 import BeautifulSoup
html = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html,"lxml")#指定解析器
tag_title = soup.find_all("title")
print(tag_title)
tag_a = soup.find_all("a")
print(tag_a)
"""
[The Dormouse's story ]
[,
Lacie,
Tillie]
"""注:
从上面的结果可以看出,其实这种方法跟前面说的过滤器是一样的,即name参数的值可以使任一类型的过滤器
keyword 参数
如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字tag的属性来搜索
例:如果包含一个名字为id的参数,Beautiful Soup会搜索每个tag的”id”属性
例7:
from bs4 import BeautifulSoup
import re
html = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html,"lxml")#指定解析器
tag_link = soup.find_all(id ="link2")#传入id参数
print(tag_link)
tag_href = soup.find_all(href=re.compile("example"))#传入href参数
print(tag_href)
tag_True = soup.find_all(id=True)#传入Trur参数
print(tag_True)
tag_all = soup.find_all(href=re.compile("example"), id='link1')#多个指定名字的参数
print(tag_all)
tag_class = soup.find_all(class_="sister")#传入class参数
print(tag_class)
"""
[Lacie]
[,
Lacie,
Tillie]
[,
Lacie,
Tillie]
[]
[,
Lacie,
Tillie]
"""注:
上面介绍了几种keyword 参数的搜索方式:搜索指定名字的属性时可以使用的参数值包括 字符串 , 正则表达式 , 列表, True,各种参数间可以相互组合
1、使用id关键字:包含一个名字为 id 的参数,Beautiful Soup会搜索每个tag的”id”属性
2、使用href关键字:如果传入href参数,Beautiful Soup会搜索每个tag的”href”属性
3、使用True关键字:在文档树中查找所有包含 id 属性的tag,无论id的值是什么
4、多个关键字组合:使用多个指定名字的参数可以同时过滤tag的多个属性
5、使用class关键字:class是python的关键词,所以在使用其作为关键字时需要加个下划线
6、多种过滤类型组合在一起可以进一步加强搜索(匹配)结果的准确性
按CSS搜索
1、按照CSS类名搜索tag的功能非常实用,但标识CSS类名的关键字class在Python中是保留字,使用class做参数会导致语法错误。从Beautiful Soup的4.1.1版本开始。可以通过 class_ 参数搜索有指定CSS类名的tag(在上面例子中也有讲解)
例8:
from bs4 import BeautifulSoup
html = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html,"lxml")#指定解析器
tag_class_1 = soup.find_all(class_="sister",id="link3")#class参数与id参数组合使用
print(tag_class_1)
"""
[Tillie]
"""2、class_ 参数同样接受不同类型的 过滤器 ,字符串,正则表达式,方法或 True
例8_1:
from bs4 import BeautifulSoup
import re
html = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html,"lxml")#指定解析器
tag_class_1 = soup.find_all(class_=re.compile("itl"))
print(tag_class_1)
#[The Dormouse's story
]
text 参数
1、通过 text 参数可以搜文档中的字符串内容与 name 参数的可选值一样, text 参数接受 字符串 , 正则表达式 , 列表, True
例9:
from bs4 import BeautifulSoup
import re
html = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html,"lxml")#指定解析器
more = soup.find_all(text=["Tillie", "Elsie", "Lacie"])
print(more)
all = soup.find_all(text=re.compile("story"))
print(all)
"""
['Lacie', 'Tillie']
["The Dormouse's story", "The Dormouse's story"]
"""2、虽然 text 参数用于搜索字符串,还可以与其它参数混合使用来过滤tag.Beautiful Soup会找到 .string 方法与 text 参数值相符的tag
例9_1:
from bs4 import BeautifulSoup
import re
html = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html,"lxml")#指定解析器
tag_a = soup.find_all("a",text= "Tillie")
print(tag_a)
#[Tillie]limit 参数
find_all() 方法返回全部的搜索结构,如果文档树很大那么搜索会很慢。如果我们不需要全部结果,可以使用 limit 参数限制返回结果的数量。效果与SQL中的limit关键字类似,当搜索到的结果数量达到 limit 的限制时,就停止搜索返回结果。
例10:文档树中有3个tag符合搜索条件,但结果只返回了2个,因为我们限制了返回数量
soup.find_all("a", limit=2)
"""
[Elsie,
Lacie]
"""
find( )方法
语法:
find( name , attrs , recursive , text , **kwargs )描述
1、find_all()方法将返回文档中符合条件的所有tag,尽管有时候我们只想得到一个结果。比如文档中只有一个
例11:下面两行代码是等价的
import re
from bs4 import BeautifulSoup
html = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html,"lxml")#指定解析器
print(soup.find_all('title', limit=1))#返回一个列表
print(soup.find('title'))#返回一个tag
"""
[The Dormouse's story ]
The Dormouse's story
"""注:
1、上面两段代码:唯一的区别是find_all()方法的返回结果是值包含一个元素的列表(未设置limit参数时则是全部满足要求的标签对),而find()方法直接返回结果
2、find_all() 方法没有找到目标是返回空列表, find()方法找不到目标时,返回 None
3、由输出结果可以看出find_all()方法返回的是一个列表,需要遍历后才是一个tag对象,而find()方法直接返回的就是一个tag对象
例:
from bs4 import BeautifulSoup # 导入bs4库
html = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html, "lxml") # 指定解析器,创建beautifulsoup对象
p_string = soup.p.string
print(r"直接查找标签对中的string:",p_string)
p = soup.find_all("p")
print(r"标签对:",p)
for i in p:
print(r"先查找标签对,再在标签对中找string:",i.string)
print(r"先查找标签对,再在标签对中找某个属性的值:",i["class"])
print(i.get("class"))
"""直接查找标签对中的string: The Dormouse's story
标签对: [The Dormouse's story
, Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
, ...
]
先查找标签对,再在标签对中找string: The Dormouse's story
先查找标签对,再在标签对中找某个属性的值: ['title']
['title']
先查找标签对,再在标签对中找string: None
先查找标签对,再在标签对中找某个属性的值: ['story']
['story']
先查找标签对,再在标签对中找string: ...
先查找标签对,再在标签对中找某个属性的值: ['story']
['story']
"""注:
1、find_all()方法返回的是:一个所有符合查找条件的tag对象组成的列表,需要遍历后才是具体的某个tag对象
2、find()方法返回的是:第一个符合查找条件的tag对象,直接返回的就是一个tag对象
3、查找标签对中字符串的方法 :
⑴直接使用"soup对象.标签对.string"的方法:这样查找出来的是第一个符合查找条件的标签对的字符串
⑵先找出所有符合查找条件的tag对象,在使用"tag对象.string"的方法:这样查找出来的就是全部符合条件的标签对的字符串
4、简析XML文档时,必须制定简析器为"xml",不能是"lxml",不然会报错
5、对于HTML文档和XML文档来说里面主要的就是:
⑴标签对:标签对里面的属性和属性值(key:value)。可通过找到的tag对象,再在tag对象中使用字典的方法,找出具体某个属性的值
⑵字符串:就是标签对之间的字符串,查找方法如3中所述
CSS选择器
1、Beautiful Soup支持大部分的CSS选择器,在Tag或BeautifulSoup对象的。select()方法中传入字符串参数,即可使用CSS选择器的语法找到tag
2、CSS选择器是一种单独的文档搜索语法, 参考 http://www.w3school.com.cn/css/css_selector_type.asp
3、CSS选择器的方法很多,这里重点介绍一种很常见的方法,其他方法请参考
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#id87步骤1:在原网页通过F12打开开发者模式,选中我们需要的东西,【右键】->copy->Copy Selector:复制我们需要的标签对的路径
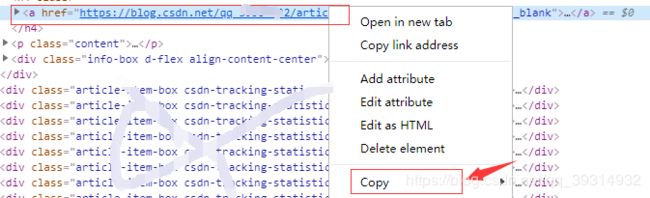
步骤2:将路径粘贴在任意文本中(我们可以多复制几条,进行对比),代码如下:
⑴#mainBox > main > div.article-list > div:nth-child(4) > h4 > a
⑵#mainBox > main > div.article-list > div:nth-child(5) > h4 > a步骤3:由步骤2中的路径我们可以发现:不同的部分为"nth-child(num)",因此需要将冒号后(包括冒号)的部分删掉,就得到的通用的路径
#mainBox > main > div.article-list > div > h4 > a例12:
import requests
from bs4 import BeautifulSoup
url = 'https://blog.csdn.net/qq_39********'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 UBrowser/6.1.2107.204 Safari/537.36'}
html = requests.get(url,headers = header)
#使用自带的html.parser解析,速度慢但通用
soup = BeautifulSoup(html.text,'html.parser')
tag = soup.select("#mainBox > main > div.article-list > div > h4 > a")
print(tag)
拓展
测试HTML








例13:
import requests
from bs4 import BeautifulSoup
url = 'http://www.mzitu.com'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 UBrowser/6.1.2107.204 Safari/537.36'}
html = requests.get(url,headers = header)
#使用自带的html.parser解析,速度慢但通用
soup = BeautifulSoup(html.text,'html.parser')
#方法1
"""
#实际上是第一个class = 'postlist'的div里的所有a 标签是我们要找的信息
all_a = soup.find('div',class_='postlist').find_all('a',target='_blank')
for a in all_a:
print(a["href"])
"""
#方法2
all_a = soup.find_all('a',target="_blank")
for a in all_a:
print(a["href"])注:在上面例子中我们使用了两种方法去找符合('a',target="_blank")的标签对,可以发现两种方法的输出结果不一致
1、一个HTML页面中可能会有一些标签对包含我们不需要的信息:符合我们的查找条件,但是实际是我们不需要的
2、通过观察HTML页面可以发现,我们需要的信息都是在一个叫 1、通过自己的学习,感觉经常用到的还是fing_all(标签对名参数,关键字参数),当然这种查找当然使用fing_all(标签对名参数)。加上关键字参数可以提高准确性 2、本文是参照BeautifulSoup官方文档写的。只是自己在学习过程中的记录,方便以后查找的,文中肯定有错误的和遗漏的,如果有幸被您看到,请不要介意。可以直接去看官方文档注:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#id87