wechatpy开发微信公众号(实现自定义菜单,翻译)
今天来学习通过wechatpy 来开发微信公众号。
准备工作:
1.申请一个微信公众号
2.pip install wechatpy
如是自己没有服务器,下载ngrok :ngrok 是一个反向代理,通过在公共端点和本地运行的 Web 服务器之间建立一个安全的通道,实现内网主机的服务可以暴露给外网
有兴趣的可以先看WeChatpy的官方文档
1.打开ngrok,复制图中所示代码,点击确认
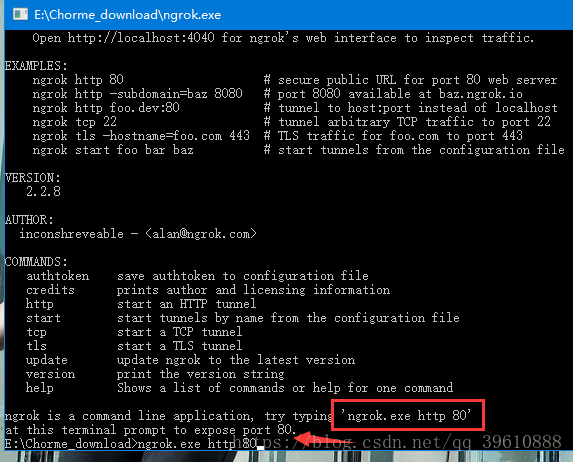
出现下列结果,将图示网址复制到浏览器打开如图所示:
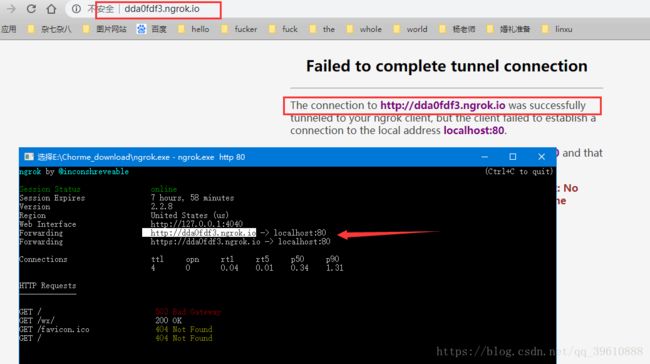
2 新建一个Django项目,并在里面新建一个名字为wechat的app. 在settings.py 文件里,添加wechat的app,更改host = [’*’],在wechat 的view.py 文件里进行如下先添加如下代码:
from wechatpy.utils import check_signature
from wechatpy.exceptions import InvalidSignatureException
from django.http import HttpResponse
from wechatpy import WeChatClient
# 这里的token 取自微信公众号自己设置的
token = 'fan'
def handle_wx(request):
# GET 方式用于微信公众平台绑定验证
if request.method == 'GET':
signature = request.GET.get('signature', '')
timestamp = request.GET.get('timestamp', '')
nonce = request.GET.get('nonce', '')
echo_str = request.GET.get('echostr', '')
try:
check_signature(token, signature, timestamp, nonce)
except InvalidSignatureException:
echo_str = '错误的请求'
response = HttpResponse(echo_str)
return response
在urls.py 文件里加入路由,并在主文件的urls 文件里include(‘wechat.urls’)
在命令行以80端口启动该文件:python manage.py runserver 80
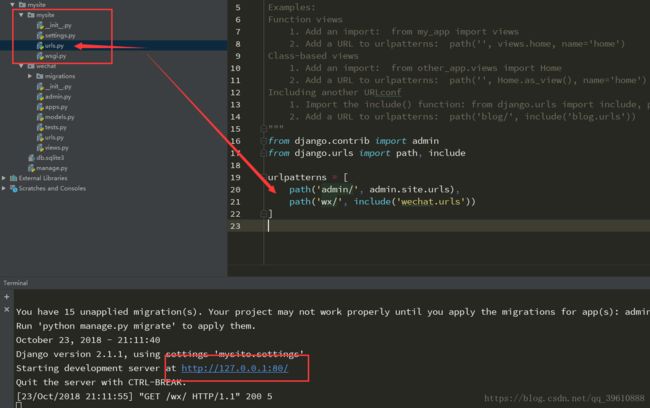
因为我们还没有在微信公众号设置,所以这里暂时返回的是错误的
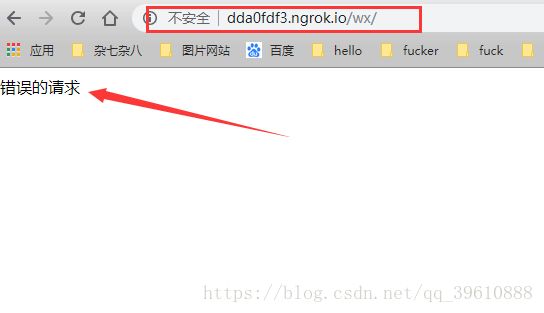
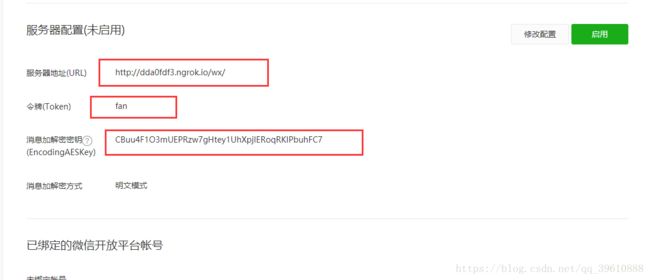
配置公众号
进入到公众号页面后,左边的菜单栏有一个基本配置,点击,输入刚才的网址,令牌自己写,我这里是fan,随机生成秘钥,点击确认,如图所示
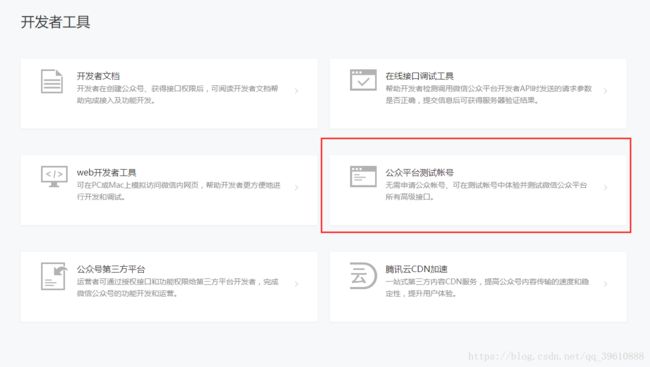
在左边点击开发者工具, 点击公众平台测试账号
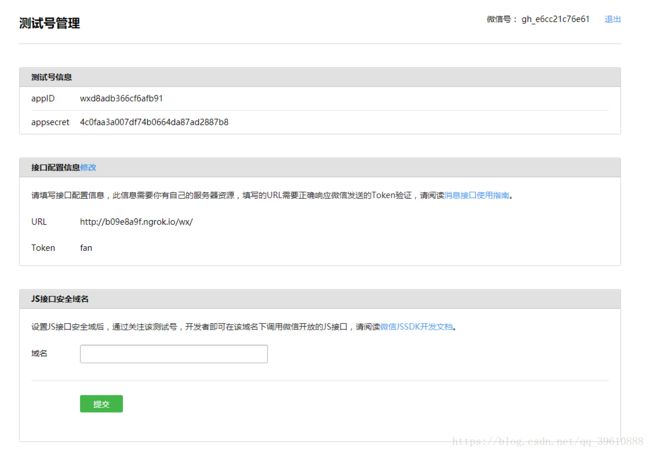
用微信扫码登录后如图所示;
一 自定义菜单
还是上面的网页,接着往下拉,会看到图中所示
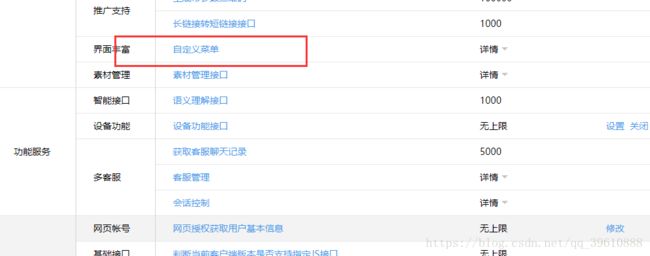
点进去之后,可以看到有很多关于菜单的操作,这里只介绍如何创建新菜单

现在切换到Django项目,在wechat的views.py 文件中,接着上面的函数,我们重新定义一个函数,把自定义菜单的创建接口代码复制过去,可以进行改动,如下所示
def create_menu(request):
# 第一个参数是公众号里面的appID,第二个参数是appsecret
client = WeChatClient("wxd8adb366cf6afb91", "4c0faa3a007df74b0664da87ad2887b8")
client.menu.create({
"button": [
{
"type": "click",
"name": "今日歌曲",
"key": "V1001_TODAY_MUSIC"
},
{
"type": "click",
"name": "歌手简介",
"key": "V1001_TODAY_SINGER"
},
{
"name": "菜单",
"sub_button": [
{
"type": "view",
"name": "搜索",
"url": "http://www.soso.com/"
},
{
"type": "view",
"name": "视频",
"url": "http://v.qq.com/"
},
{
"type": "click",
"name": "赞一下我们",
"key": "V1001_GOOD"
}
]
}
],
"matchrule": {
"group_id": "2",
"sex": "1",
"country": "中国",
"province": "广东",
"city": "广州",
"client_platform_type": "2"
}
})
return HttpResponse('ok')
书写完毕,把该函数添加到路由,重启服务,打开浏览器,输入:
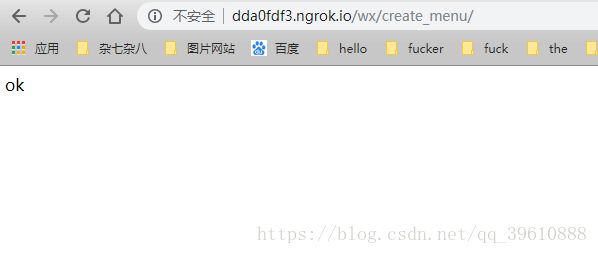
http://dda0fdf3.ngrok.io/wx/create_menu/, 显示如下图所示,表示成功
(网址每个人都不一样,但是后面的配置是一样的)
扫描并关注测试号二维码,可以看到如下界面,表示已经成功。

二 接入外部的API
上面的菜单可以连接到外部不同的接口,传回不同的数据,这里取免费的腾讯AI平台文本翻译,现在该平台进行相应的注册与登录,创建应用,接入能力,如图所示, 记得保存好自己App_ID 与 App_Key 后面会用到
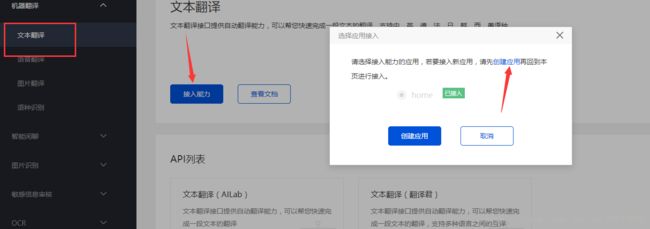
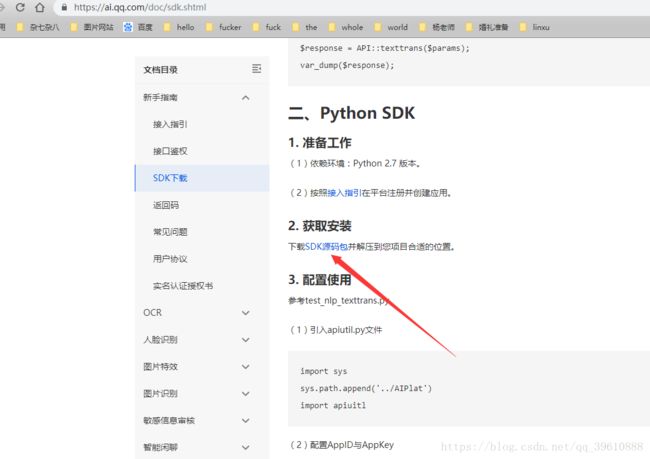
走到这一步,我们可以先下载源码看看,这样可以省去好多事
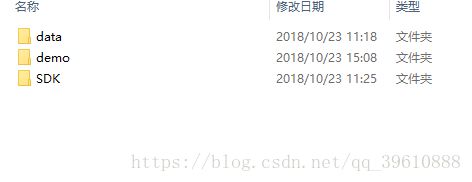
解压之后,发现有三个文件夹,一会我们要用到的东西就在这里面
我们在wechat这个app 里新建一个py文件。名为utils ,将如下代码复制进去,
import apiutil
from wechatpy import create_reply
def translate(msg):
app_id = '2109327500'
app_key = 'K6oaVJvL7oUmA1co'
str_text = msg.content
type = 0
ai_obj = apiutil.AiPlat(app_id, app_key)
rsp = ai_obj.getNlpTextTrans(str_text, type)
str_rsp = create_reply(rsp, msg)
return str_rsp
如果你看了源码的话,你会发现,这个文件就是上面那个文件夹demo 里面的test_npl_texttrans.py文件,只是做了一些改动。
test_npl_texttrans.py 里str_text 的字符串是写死的,因为这里是用作翻译,所以是用一个变量来接受。
一会在view.py 文件中,接受到这个参数。
代码飘红不要紧,
暂时将上面的SDK文件夹中的apiutil.py 文件复制到项目的主目录,因为上面的代码要导入模块就在这个文件里。 这里只是暂时导入,因为这个文件使用Python2 写的,但是我们用的是Python3 ,所以一会要做些许改动,这里暂时先放着。
改动后的apiutil.py 文件:
其中将urlib2 删除,改为用requests,
将暂时不需要的函数删除,因为是做测试用,所以也将一些try: except 的内容进行简略处理。
这个文件最后的一个返回值是翻译过后的值
import hashlib
import urllib
import time
import requests
url_preffix = 'https://api.ai.qq.com/fcgi-bin/'
def setParams(array, key, value):
array[key] = value
# 这个parser 就是下面传进来的字典
def genSignString(parser):
uri_str = ''
for key in sorted(parser.keys()):
if key == 'app_key':
continue
uri_str += "%s=%s&" % (key, urllib.parse.quote(str(parser[key]), safe=''))
sign_str = uri_str + 'app_key=' + parser['app_key']
sign_str = sign_str.encode()
hash_md5 = hashlib.md5(sign_str)
return hash_md5.hexdigest().upper()
class AiPlat(object):
def __init__(self, app_id, app_key):
self.app_id = app_id
self.app_key = app_key
# 设置一个字典,把以后的参数都以键值对的形式展现出来
self.data = {}
# 这里的params 也是字典
def invoke(self, params):
self.url_data = urllib.parse.urlencode(params)
print(self.url_data)
# 下来该执行API调用
try:
req = requests.get(self.url, self.url_data).json()
str_rsp = req['data']['trans_text']
return str_rsp
except Exception as e:
dict_error = {}
if hasattr(e, "code"):
dict_error = {}
dict_error['ret'] = -1
dict_error['httpcode'] = e.code
dict_error['msg'] = "sdk http post err"
return dict_error
if hasattr(e, "reason"):
dict_error['msg'] = 'sdk http post err'
dict_error['httpcode'] = -1
dict_error['ret'] = -1
return dict_error
def getNlpTextTrans(self, text, type):
self.url = url_preffix + 'nlp/nlp_texttrans'
setParams(self.data, 'app_id', self.app_id)
setParams(self.data, 'app_key', self.app_key)
setParams(self.data, 'time_stamp', int(time.time()))
setParams(self.data, 'nonce_str', int(time.time()))
setParams(self.data, 'text', text)
setParams(self.data, 'type', type)
sign_str = genSignString(self.data)
# 大键是sigh,后面又是字典嵌套
setParams(self.data, 'sign', sign_str)
return self.invoke(self.data)
在views.py 文件的handle_wx 函数补上下面的代码:
因为这次是Post 请求
from wechatpy import parse_message
from .utils import translate
token = 'fan'
def handle_wx(request):
# GET 方式用于微信公众平台绑定验证
if request.method == 'GET':
signature = request.GET.get('signature', '')
........
.......
......
response = HttpResponse(echo_str)
return response
else:
msg = parse_message(request.body)
if msg.type == 'text':
reply = translate(msg)
response = HttpResponse(reply.render(), content_type='application/xml')
return response
这时,我们扫描这个测试公众号二维码,输入一些汉子,可以看到,它已经返回了相应的英文
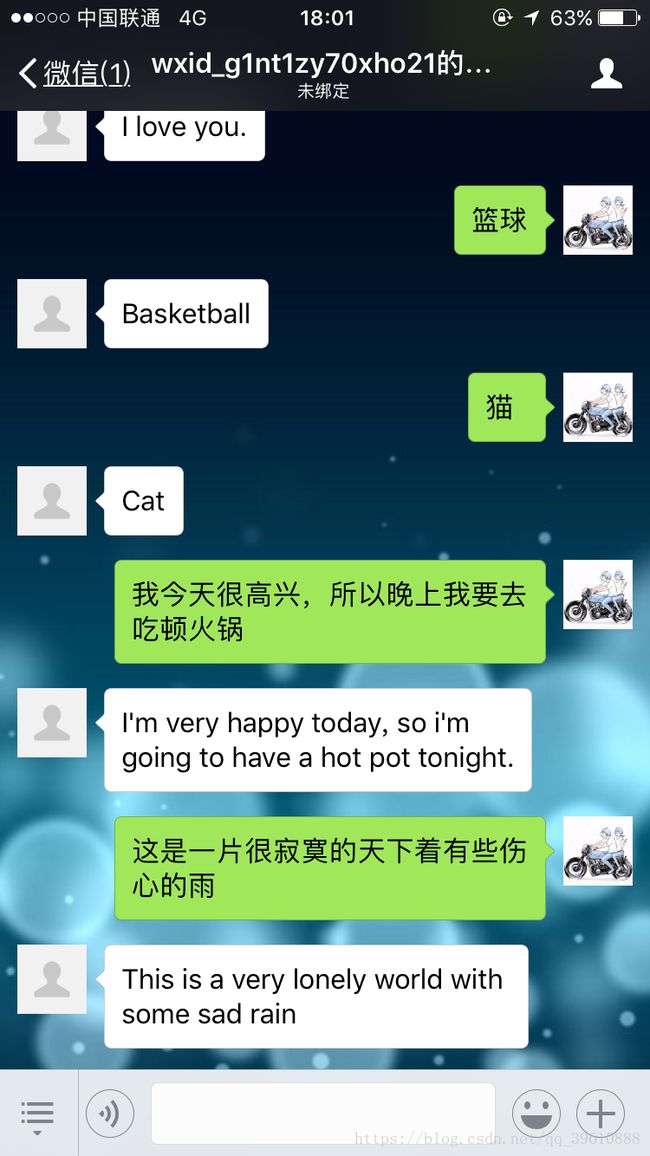
至此,所有的问题已经解决。当然在上面的代码中肯定会遇到很多问题,要学会找出问题在哪。
比如,在输入了相应的文字后,没有返回值,我们就要去判断,是哪个环节出了问题,先看后端能接受到这个数据嘛,最简单的方法就是通过print()来打印判断。如果能接受到,再判断能否将数据封装好,传递给腾讯翻译后端,后端再返回数据,能接受到数据吗…这都是一系列问题,要慢慢的去测试,一步步的的判断问题出在哪里。