为什么说神经网络可以逼近任意函数?
本文主要介绍神经网络万能逼近理论,并且通过PyTorch展示了两个案例来说明神经网络的函数逼近功能。
大多数人理解“函数”为高等代数中形如“f(x)=2x”的表达式,但是实际上,函数只是输入到输出的映射关系,其形式是多样的。

拿个人衣服尺寸预测来说,我们用机器学习来实现这个功能,就是将个人身高、体重、年龄作为输入,将衣服尺寸作为输出,实现输入-输出映射。
具体来说,需要以下几个步骤:
- 收集关键数据(大量人口的身高/体重/年龄,已经对应的实际服装尺寸)。
- 训练模型来实现输入-输出的映射逼近。
- 对未知数据进行预测来验证模型。
如果输出是输入特征的线性映射,那么模型的训练往往相对简单,只需要一个线性回归就可以实现;size = a*height + b*weight + c*age + d。
但是,通常假设输出是输入特征的线性映射是不够合理和不完全准确的。现实情况往往很复杂,存在一定的特例和例外。常见的问题(字体识别、图像分类等)显然涉及到复杂的模式,需要从高维输入特征中学习映射关系。
但是根据万能逼近理论,带有单隐藏的人工神经网络就能够逼近任意函数,因此可以被用于解决复杂问题。
人工神经网络
本文将只研究具有输入层、单个隐藏层和输出层的完全连接的神经网络。在服装尺寸预测器的例子中,输入层将有三个神经元(身高、体重和年龄),而输出层只有一个(预测尺寸)。在这两者之间,有一个隐藏层,上面有一些神经元(下图中有5个,但实际上可能更大一些,比如1024个)。

网络中的每个连接都有一些可调整的权重。训练意味着找到好的权重,使给定输入集的预测大小与实际大小之间存在微小差异。
每个神经元与下一层的每个神经元相连。这些连接都有一定的权重。每个神经元的值沿着每个连接传递,在那里它乘以权重。然后所有的神经元都会向前反馈到输出层,然后输出一个结果。训练模型需要为所有连接找到合适的权重。万能逼近定理的核心主张是,在有足够多的隐藏神经元的情况下,存在着一组可以近似任何函数的连接权值,即使该函数不是像f(x)=x²那样可以简洁地写下来的函数。即使是一个疯狂的,复杂的函数,比如把一个100x100像素的图像作为输入,输出“狗”或“猫”的函数也被这个定理所覆盖。
非线性关系
神经网络之所以能够逼近任意函数,关键在于将非线性关系函数整合到了网络中。每层都可以设置激活函数实现非线性映射,换言之,人工神经网络不只是进行线性映射计算。常见的非线性激活函数有 ReLU, Tanh, Sigmoid等。
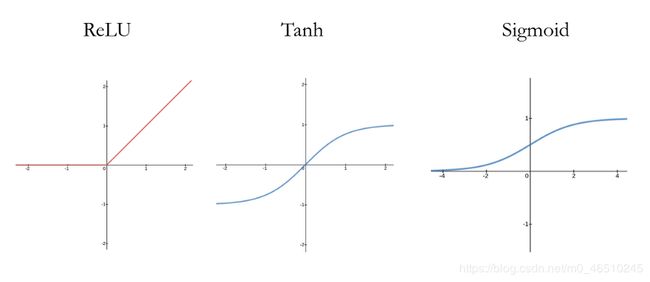
ReLU是一个简单的分段线性函数-计算消耗小。另外两个都涉及到指数运算,因此计算成本更高
为了展示人工神经网络的万能逼近的能力,接下来通过PyTorch实现两个案例。
案例一:任意散点曲线拟合
神经网络可能面临的最基本的情况之一就是学习两个变量之间的映射关系。例如,假设x值表示时间,y坐标表示某条街道上的交通量。在一天中的不同时间点都会出现高峰和低谷,因此这不是一种线性关系。
下面的代码首先生成符合正态分布的随机点,然后训练一个网络,该网络将x坐标作为输入,y坐标作为输出。有关每个步骤的详细信息,请参见代码注释:
import torch
import plotly.graph_objects as go
import numpy as np
# Batch Size, Input Neurons, Hidden Neurons, Output Neurons
N, D_in, H, D_out = 16, 1, 1024, 1
# Create random Tensors to hold inputs and outputs
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
# Use the nn package to define our model
# Linear (Input -> Hidden), ReLU (Non-linearity), Linear (Hidden-> Output)
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out),
)
# Define the loss function: Mean Squared Error
# The sum of the squares of the differences between prediction and ground truth
loss_fn = torch.nn.MSELoss(reduction='sum')
# The optimizer does a lot of the work of actually calculating gradients and
# applying backpropagation through the network to update weights
learning_rate = 1e-4
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# Perform 30000 training steps
for t in range(30000):
# Forward pass: compute predicted y by passing x to the model.
y_pred = model(x)
# Compute loss and print it periodically
loss = loss_fn(y_pred, y)
if t % 100 == 0:
print(t, loss.item())
# Update the network weights using gradient of the loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Draw the original random points as a scatter plot
fig = go.Figure()
fig.add_trace(go.Scatter(x=x.flatten().numpy(), y=y.flatten().numpy(), mode="markers"))
# Generate predictions for evenly spaced x-values between minx and maxx
minx = min(list(x.numpy()))
maxx = max(list(x.numpy()))
c = torch.from_numpy(np.linspace(minx, maxx, num=640)).reshape(-1, 1).float()
d = model(c)
# Draw the predicted functions as a line graph
fig.add_trace(go.Scatter(x=c.flatten().numpy(), y=d.flatten().detach().numpy(), mode="lines"))
fig.show()
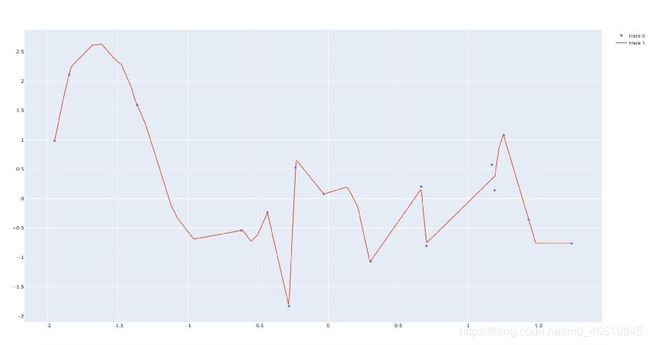
请注意右边的两点,即模型没有完全拟合。我们可以通过运行更多的训练步骤或增加隐藏神经元的数量来解决这个问题。
案例二:二值分类
函数不一定是在代数中看到的那种“一个数进去,另一个数出来”的函数。现在让我们尝试一个二进制分类任务。数据点有两个特征,可以分为两个标签中的一个。也许这两个特征是经纬度坐标,而标签是环境污染物的存在。或者,这些特征可能是学生的数学和阅读测试成绩,并且标签对应于他们是右撇子还是左撇子。重要的是模型必须实现两个输入到一个输出(0或1)的映射。
下面的代码与前面的代码非常相似。唯一的差异是输入层现在有两个神经元,输出层之后是一个Sigmoid激活,它将所有输出压缩到范围(0,1)。
import torch
import plotly.express as px
import pandas as pd
# Batch Size, Input Neurons, Hidden Neurons, Output Neurons
N, D_in, H, D_out = 128, 2, 1024, 1
# Create random Tensors to hold inputs and outputs
x = torch.rand(N, D_in)
y = torch.randint(0, 2, (N, D_out))
# Plot randomly generated points and color by label
df = pd.DataFrame({"x": x[:, 0].flatten(), "y": x[:, 1].flatten(), "class": y.flatten()})
fig = px.scatter(df, x="x", y="y", color="class", color_continuous_scale="tealrose")
fig.show()
# define model: Linear (Input->Hidden), ReLU, Linear (Hidden->Output), Sigmoid
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out),
torch.nn.Sigmoid()
)
# define loss function: Binary Cross Entropy Loss (good for binary classification tasks)
loss_fn = torch.nn.BCELoss()
learning_rate = 0.002
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# Store losses over time
ts, losses = ([], [])
# run training steps
for t in range(60000):
y_pred = model(x)
loss = loss_fn(y_pred.float(), y.float())
if t % 100 == 0:
ts.append(t)
losses.append(loss.data.numpy())
optimizer.zero_grad()
loss.backward()
optimizer.step()
# generate a bunch of random points to cover the sample space, then call model
c = torch.rand(32000, D_in)
d = model(c)
# store random data and predicted classifications in a DataFrame and plot with Plotly Express
df2 = pd.DataFrame({"x": c[:, 0].flatten(),
"y": c[:, 1].flatten(),
"class": d.flatten().detach().numpy()})
fig2 = px.scatter(df2, x="x", y="y", color="class", color_continuous_scale="tealrose")
fig2.show()
# plot the loss as a function of training step
fig3 = px.scatter(x=ts, y=losses)
fig3.show()

在单位正方形中随机均匀生成的点,随机指定给标签0(青色)和标签1(粉红色)。
首先,在单位正方形内随机均匀生成数据点,并且随机指点每个数据点的标签为0/1。从图中可以看出,显然不存在线性关系。本案例的目的在于训练模型使其通过坐标判断标签。

模型分类结果
过拟合
以上两个案例似乎都给出了很可观的结果,但是这是不是我们真正想要的呢?
值得注意的是,这两个案例都存在过拟合的现象。过拟合表现为模型在训练数据集表现优秀,但是在未知数据集表现不足。
在案例一中,假设其中一个点是由于错误的数据收集而导致的异常值。考虑到要学习的训练数据量如此之少,模型对这些数据的拟合度过高,只看到了一个信号,而实际上只是噪声。一方面,令人印象深刻的是,模型能够学习一个考虑到这个异常值的函数。另一方面,当将此模型应用于真实世界的数据时,这可能会导致不良结果,在该点附近产生错误的预测。
在案例二中,模型学习了一个漂亮的分类预测。但是,请注意最靠近右下角的蓝绿色点。尽管这是唯一的一点,它导致模型将整个右下角标记为青色。仅仅是一些错误的数据点就可能严重扭曲模型。当我们尝试将模型应用于测试数据时,它的工作效果可能比预期的差得多。
为了避免过度拟合,重要的是要有大量的训练数据来代表模型预期面对的样本。如果你正在建立一个工具来预测普通人群的衣服尺寸,不要只从你大学朋友那里收集训练数据。此外,还有一些先进的技术可以别用于帮助减少过拟合的发生(例如:权重下降 weight decay)。
结语
总之,神经网络是强大的机器学习工具,因为它们(理论上)能够学习任何函数。然而,这并不能保证你很容易找到一个给定问题的最优权重!实际上,在合理的时间内训练一个精确的模型取决于许多因素,例如优化器、模型体系结构、数据质量等等。特别是,深度学习涉及具有多个隐藏层的神经网络,它们非常擅长学习某些困难的任务。
作者:Thomas Hikaru Clark
deephub翻译组 Oliver Lee