《Spring in Action》第3章-使用数据库
Spring与数据库
使用JDBC读写数据
使用JDBC(Java Database Connectivity)完成一次查询:
Connection connection = null;
PreparedStatement statement = null;
ResultSet resultSet = null;
try{
connection = dataSource.getConnection();
statement = connection.prepareStatement("select id, name, type from Ingredient");
statement.setString(1,id);
resultSet = statement.executeQuery();
Ingredient ingredient = null;
if (resultSet.next){
ingredient = new Ingredient(resultSet.getString("id"),resultSet.getString("name"),Ingredient.Type.valueOf(resultSet.getString("type")));
}
return ingredient;
}catch(SQLException e){
}finally{
if (resultSet != null){
try{
resultSet.close();
}cathc(SQLException e){}
}
if (statemnt != null){
try{
statemnt.close();
}catch(SQLException e){}
}
if (connection != null){
try{
connection.close();
}catch(SQLException e){}
}
}
我们需要创建与数据库的连接,创建查询语句,执行查询,然后将查询结果映射为对象,最后还要依次关闭结果集,执行语句和与数据库的连接。此外我们还要捕获异常,但是大多数的异常在捕获块中都无法处理。这里存在大量的模板代码。使用Spring 的 JDBCTemplate可以消除大量的模板代码:
privaate JdbcTemplate jdbc;
@Override
public Ingredient findOne(String id){
return jdbc.queryForObject("select id, name, type from Ingredient where id = ?",this::mapRowToIngredient,id);
}
private Ingredient mapRowToIngredient(ResultSet rs, int rowNum) throws SQLException{
return new Ingredient(rs.getString("id"),rs.getString("name"),Ingredient.Type.valueOf(rs.getString("type")));
}
使用Spring JdbcTemplate
-
要使用JdbcTemplate,我们需要加入它的依赖包:
<dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-jdbcartifactId> dependency> -
另外我们还需要数据库,在开发时我们使用嵌入的H2数据库是一个不错的选择,同样需要加入依赖:
<dependency> <groupId>com.h2databasegroupId> <artifactId>h2artifactId> <scope>runtimescope> dependency> -
查询数据:
我们使用
@Repository注解类,这个注解包括:@Controller和@Component两个注解。@Repository public class IngredientRepositoryImpl{ private JdbcTemplate jdbc; //将JdbcTemplate注入 @Autowired public IngredientRepositoryImpl(JdbcTemplate jdbc){ this.jdbc = jdbc; } //查询多条记录 public Iterator<Ingredient> findAll(){ return jdbc.query(sql,rowMapper); } //查询一条记录 public Ingredient findOne(String id){ return jdbc.queryForObject(sql,rowMapper,id); } }使用
JdbcTemplate的查询方法期望直接返回对象是,需要传入一个RowMapper,有两种传入方式,一种传入实现了RowMapper的实例;一种是传入一个方法引用(java8)。更多的查询方法:JdbcTemplate API
-
数据库表与预加载数据
我们可以应用的classpath的根目录下(src/main/resources)创建一个名为"schema.sql"的文件,在应用启动时,SpringBoot会自动在对应数据库中执行文件中的sql语句,在数据库中创建表。
我们也可以在根目录下创建一个名为"data.sql"的文件,应用启动时,SpringBoot会自动执行文件内的sql语句,向数据库插入预加载数据。
如果我们使用的是H2数据库,那么通过
/h2-console访问它的控制台,其中登录时,JDBC URL在项目启动日志中,密码为空。 -
插入数据
public Ingredient save(){ jdbc.update(sql,values); }这是一个简单的插入语句。如果我们需要获取由数据库生成的id,那么我们应该使用
PreparedStatementCreator。private long saveTacoInfo(Taco taco){ taco.setCreateAt(new Date()); PreparedStatementCreatorFactory factory = new PreparedStatementCreatorFactory("insert into Taco (name,createAt) values(?,?)", Types.VARCHAR,Types.TIMESTAMP); PreparedStatementCreator creator = factory.newPreparedStatementCreator(Arrays.asList(taco.getName(),new Timestamp(taco.getCreateAt().getTime()))); KeyHolder keyHolder = new GeneratedKeyHolder(); factory.setReturnGeneratedKey(true); //允许返回主键值 jdbc.update(creator,keyHolder); return keyHolder.getKey().longValue(); }其中,
PreparedStatementCreatorFactory接收sql语句以及其中占位符所表示字段的类型。PreparedStatementCreator接收占位符对应的具体值。keyHolder用于获取数据库生成的主键。JdbcTemplate的
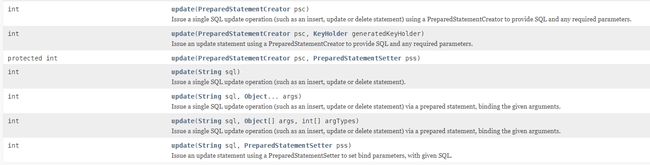
update方法:
使用SimpleJdbcInsert插入数据
使用JdbcTemplate构建SimpleJdbcInsert实例,并指定其要插入的表名
@Repository
public class OrderRepositoryImpl implements OrderRepository {
private SimpleJdbcInsert orderInsert;
private SimpleJdbcInsert orderTacoInsert;
private ObjectMapper objectMapper;
@Autowired
public OrderRepositoryImpl(JdbcTemplate jdbcTemplate) {
//指定表名及自增主键名
this.orderInsert = new SimpleJdbcInsert(jdbcTemplate).withTableName("Taco_Order").usingGeneratedKeyColumns("id");
this.orderTacoInsert = new SimpleJdbcInsert(jdbcTemplate).withTableName("Taco_Order_Tacos");
//Jackson,用于将对象转换为一个Map
objectMapper = new ObjectMapper();
}
}
SimpleJdbcInsert的方法:
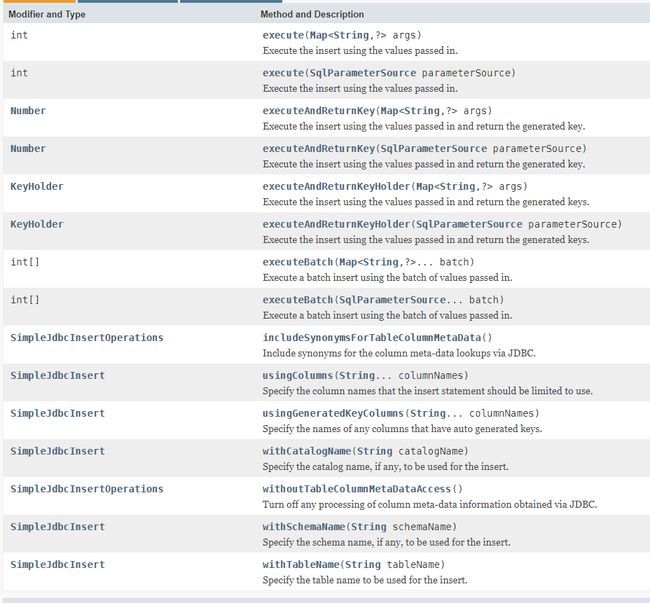
它的插入方法啊全是将一个Map或者一个Map数组插入到对应数据库,key值与字段名对应,value对应该字段的值。
使用JPA(Java Presistence API/Java持久化API)
添加依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-jpaartifactId>
dependency>
SpringBoot 默认使用Hibernate,如果想使用其它的JPA实现框架,可以排除Hibernate的依赖并引入其它框架的依赖:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-jpaartifactId>
<exclusions>
<exclusion>
<artifactId>hibernate-entitymanagerartifactId>
<groupId>org.hibernategroup>
exclusion>
exclusions>
dependency>
注解实体类
@Data
@RequiredArgsConstructor
@NoArgsConstructor(access=AccessLevel.PRIVATE,force=true)
@Entity
public class Ingredient {
@Id
private final String id;
private final String name;
@Enumerated(EnumType.STRING)
private final Type type;
public static enum Type{
WRAP, PROTEIN, VEGGIES, CHEESE, SAUCE
}
}
-
实体类需要一个无参构造函数:
手动编写,若使用了Lombok,则可使用
@NoArgsConstructor(access=AccessLevel.PRIVATE,force=true)。Lombok会在运行时自动生成一个无参构造函数,access指定该构造函数的访问修饰符;上面实体类的域全为final域,实例化类时必须初始化,使用force=true,无参的构造函数将初始化这些域为null。 -
@RequiredArgsConstructor:@Date隐式的声明需要一个带参数的构造器,但是添加了@@NoArgsConstructor注解后,就不会生成带参数构造器,所以需要使用@RequiredArgsConstructor来显示的声明需要带参数构造器。 -
@Entity:指定该类为一个实体类,对应的表名为默认表名(ingredient)。 -
@Id:指定该属性为实体类的唯一标识。 -
@Emuberated(EnumType.STRING):注解一个枚举类型,指定将名称存入数据库中。若不使用该注解,或注解为@Enumerated(EnumType.ORDINAL)则将枚举对应的序列号存入数据库。
@Data
@Entity
@Table(name="Taco_Order")
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private Date createAt;
...
@NotNull
@Size(min=1)
@ManyToMany(targetEntity = Taco.class)
private List<Taco> designs = new ArrayList<>();
public void addDesign(Taco taco){
designs.add(taco);
}
@PrePersist
void createAt(){
this.createAt = new Date();
}
}
-
@ManyToMany(targetEntity=Ingredient.class):多对多关系 -
@PrePersist:在数据持久化之前执行该方法 -
@Table(name="Taco_Order"):指定表名,若Order类不指定表名的话,将会使用默认的Order作为表名,但是"Order"是Sql中的关键字,不能用作表名。
声明 JPA Repository
使用JDBC时,在dao层,每一个接口都对应操作一张表。我们自己定义接口方法并实现。但是,使用Spring Data,我们只需要定义接口,让接口继承org.springframework.data.repository.CrudRepository接口。该接口是一个泛型接口,第一个参数是实体类型,第二个参数是实体id的类型。我们甚至不需要实现这个接口,当应用启动时,Spring Data JPA将会自动生成接口的实现,我们只需要将接口注入到需要用到它的地方。下面的实例表示一个Order实体(主键类型为Long)的Repository:
public interface OrderRepository extends CrudRepository<Order,Long>{
}
CrudRepository定义的方法如下:
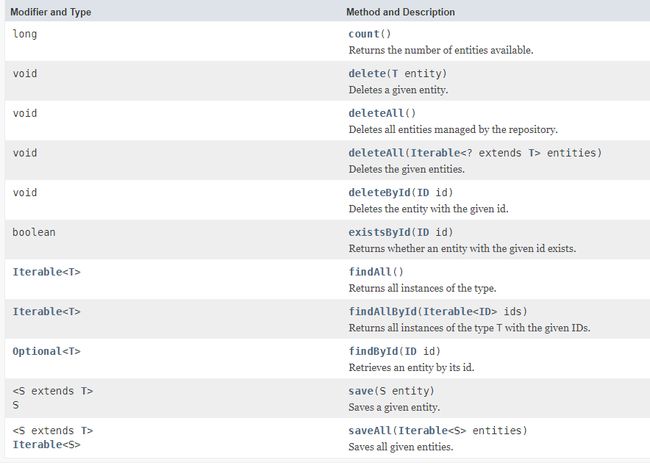
自定义JPA Repository
Spring Data API 检查接口方法,解析方法名,并尝试理解方法的意图,我们不需要对方法进行实现,只需要在继承了CrudRepository接口的接口中定义自己的方法,应用启动后Spring Data API会自动实现这些方法。
方法的命名规则如下:
动词 + subject(domain)+ by + predicate(描述语)
-
其中动词包括:find,read,get
-
subject可以显式声明也可以省略,因为我们在继承
CrudRepository时已经指定了实体,如CrudRepository,我们此时及时将subject写为Taco,该接口定义的方法也不会去操作Taco表而是Order表。 -
by后面是对查询条件的描述,支持的语法如下表所示:
Keyword Sample JPQL snippet AndfindByLastnameAndFirstname… where x.lastname = ?1 and x.firstname = ?2OrfindByLastnameOrFirstname… where x.lastname = ?1 or x.firstname = ?2Is,EqualsfindByFirstname,findByFirstnameIs,findByFirstnameEquals… where x.firstname = ?1BetweenfindByStartDateBetween… where x.startDate between ?1 and ?2LessThanfindByAgeLessThan… where x.age < ?1LessThanEqualfindByAgeLessThanEqual… where x.age <= ?1GreaterThanfindByAgeGreaterThan… where x.age > ?1GreaterThanEqualfindByAgeGreaterThanEqual… where x.age >= ?1AfterfindByStartDateAfter… where x.startDate > ?1BeforefindByStartDateBefore… where x.startDate < ?1IsNull,NullfindByAge(Is)Null… where x.age is nullIsNotNull,NotNullfindByAge(Is)NotNull… where x.age not nullLikefindByFirstnameLike… where x.firstname like ?1NotLikefindByFirstnameNotLike… where x.firstname not like ?1StartingWithfindByFirstnameStartingWith… where x.firstname like ?1(parameter bound with appended%)EndingWithfindByFirstnameEndingWith… where x.firstname like ?1(parameter bound with prepended%)ContainingfindByFirstnameContaining… where x.firstname like ?1(parameter bound wrapped in%)OrderByfindByAgeOrderByLastnameDesc… where x.age = ?1 order by x.lastname descNotfindByLastnameNot… where x.lastname <> ?1InfindByAgeIn(Collectionages) … where x.age in ?1NotInfindByAgeNotIn(Collectionages) … where x.age not in ?1TruefindByActiveTrue()… where x.active = trueFalsefindByActiveFalse()… where x.active = falseIgnoreCasefindByFirstnameIgnoreCase… where UPPER(x.firstame) = UPPER(?1) -
@Query:上面所描述的查询方法可能无法支持我们需要的查询,那么我们可以在方法上使用@Query进行注解并显式的声明查询语句:@Query("Order o where o.city='Seattle'") List<Order> readOrdersDeliverdInSeattle();