知识图谱在深度学习目标检测中的应用
知识图谱是什么?深度学习的目标检测怎么和它相结合?我将带大家一起来解读其中奥秘——阿波,2020.4.16
检索摘要
- 写在前面
- 知识图谱
- Abstract
- Introduction
- Base Detecter
- Knowledge Graph
- Feature Map
- 回顾Faster RCNN
- Model
- Adaptive Attention
- 应用介绍
- 原理说明
- 目标检测
写在前面
知识图谱:Reasoning-RCNN: Unifying Adaptive Global Reasoning —— 推理RCNN:统一自适应全局推理
应用介绍:Bootstrapping Knowledge GraphsFrom Images and Text —— 从图像和文本中引导知识图形
我将从先从知识图谱的介绍着手,浅要分析在深度学习目标检测任务中,各目标之间的相对关系是如何提升检测器精度的,并给出一篇论文范例。
先说结论:知识图谱将检测器中的类别之间的关系进行训练,确实能够提高我们的检测算法准确度,并且在很大程度上对目标之间的关系进行了解释。步骤是通过三元(object、predicate、subject )组合来进行分析的,有一个并行的语义池来单独训练,最后合并到原来的算法输出的特征图上(得到 Enhanced feature )。但是对于它错综复杂的关系网络和干扰,如何“因地适宜”正确使用便非常重要。
知识图谱
本文的亮点是将knowledge graph引入进来,增强对检测效果的识别。从信息论的角度,引入额外的信息,可以做到更好的结果。而从人的角度来说,人在对一件事物进行推理的时候,是将大脑中的已知信息结合起来,再进行推理思考。
Abstract
与一般的检测不同的是,本文的检测目标是大规模的数据检测,然而,传统的一些检测算法只是进行了检测,每个区域之间都是相互独立的,而这篇文章中,考虑一些语义的联系,对检测出来的物体之间进行推理,本文提出的方法是RCNN。在几个检测数据集上,取得了很好的提升。
Introduction
目前的大规模目标检测算法倾向于是学习数量很多的类别,一些数据类别的数量很少,严重不均衡,现如今的检测方法缺乏像人类一样的常识推理能力,因此如何去将当前的检测系统与reason结合在一起。(引入额外的信息是非常必要的。)
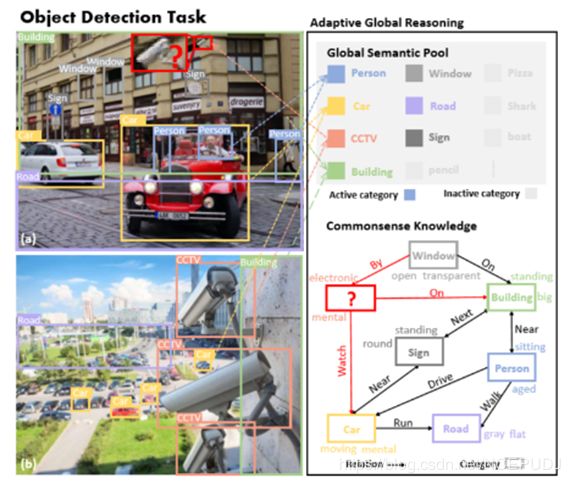
如上图 a 中的右上角部分,有一个模糊的白色的物体,我们人的思维方式就是去思考:
首先它很像一个CCTV(也就是闭路是摄像机),我们之前在 b 图中看到过。 其次再观察他的周围,是马路车,一个小的金属设备在监视着着车,所以他应该就是一个CCTV。 b 图中展示了其对象之间的图谱关系,这个就可以放到知识图谱里面去并且合并到 detection pipline 中。

Base Detecter
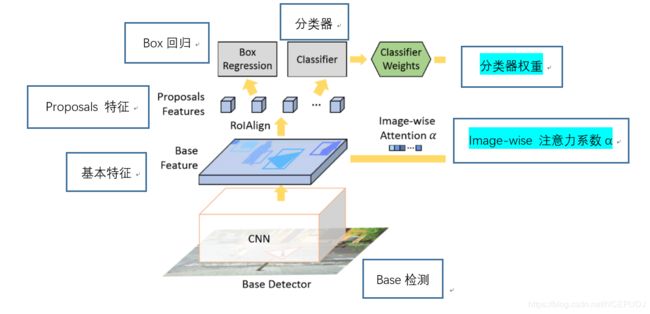
这部分的意思是将原本检测器中Proposal部分的类别进行提取,送入右边的全局语义池进行处理,传递的参数为分类器权重和注意力系数。
Knowledge Graph

我们可以看到在这一部分自动生成了全局语义池,将注意力系数和分类器权重和注意力系数导入其中进行向量关系的建立和训练。并将结果——自适应全局推理输出给右边的 Feature Map
(分类器关于每个类别的权重实际上包含了高层次的语义信息,因为在训练这个分类器的时候,其是整个图片进行了参与,分类器的参数不断更新,global pool也不断被训练),然后知识图谱被引入,并将其输入到自适应推理模块。
Feature Map

通过refine的模块去产生一个增强的特征。 这个增强的模块是通过拼接而形成的。 图中是蓝色与绿色。
其实可以看出,通过将全局语义池的结果拼接到原本的RCNN特征中,起到了一个特征增强的效果,从某种程度上来说,确实可以起到提高准确度的效果。
回顾Faster RCNN
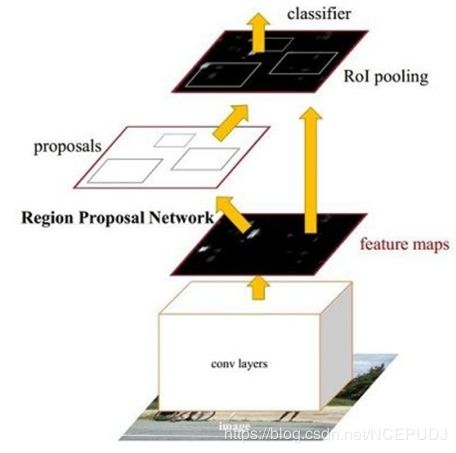
Region Proposal Networks。RPN网络用于生成region proposals。该层通过softmax判断anchors属于foreground或者background,再利用bounding box regression修正anchors获得精确的proposals。
将RPN的输出转变为Object Proposals。提名候选区域,以备后面进行分类。
Roi Pooling。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
Model

令 f = { f i } i = 1 N r , f i ∈ R D \mathbf{f}=\left\{f_{i}\right\}_{i=1}^{N_{r}}, f_{i} \in R^{D} f={fi}i=1Nr,fi∈RD为所有的region proposals的一个特征集合,其长度是D,表示region的个数。本文方法的目的就是去增强region feature,将确定的常识推理的形式如成对的关系知识(man ride bicycles)或者属性知识(apple is red)。其实就是通过成对的关系或者物体的属性的联系,将这些先验知识利用起来用于增强特征。
Adaptive Attention
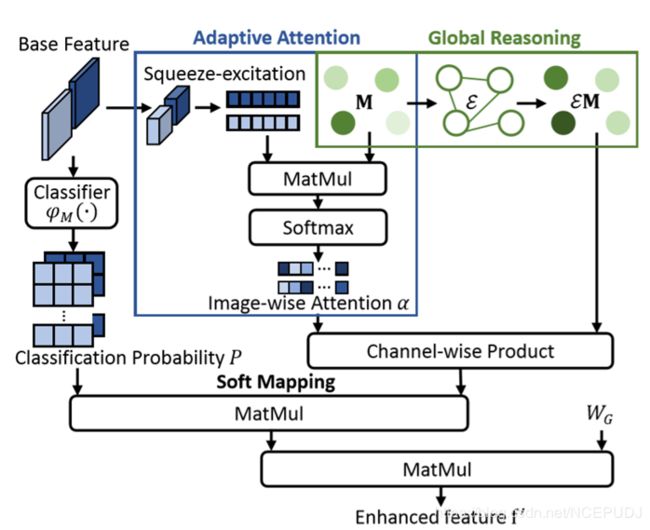
这一部分是为了提取有用的信息,并将无用信息压制
f ′ = P ( α ⊗ ε M ) W G f^{\prime}=P(\alpha \otimes \varepsilon M) W_{G} f′=P(α⊗εM)WG
最终对得到的结果,将增强的特征 f ’ 和 f 连接在一起。[ f ; f ’ ] 作为新的特征去送往网络产生新的结果。
应用介绍
这篇文章介绍了在 文本的语义识别 和 目标检测部分 应该如何结合知识图谱提高输出结果的准确度,并对神经网络进行解释。

原理说明



目标检测

图7:视觉实体对的编码器。我们扩展了Lu等人提出的union-box编码器。(2016)并将实体的特征(它是什么)及其位置(它在哪里)添加到嵌入向量中。
为了有效地将实体对的特征编码成分布式表示F(s,o),我们提取了主体、对象及其交互环境的特征。我们将特征表示为整个输入图像的提取特征。这些特征是用预先在MS-COCO上训练的VGG-16网络提取的(Xu等人,2017)。由边界框指定的给定区域的特征表示为feat[box]。这些特征是通过Girshick(2015)引入的兴趣区域(ROI)池操作获得的。feat[box{s,o}]然后表示单个实体(主题或对象)的特征,通过ROI池操作从给定边界框位置的图像特征feat中提取。
- Xu, D., Zhu, Y., Choy, C. B., and Fei-Fei, L. (2017). “Scene graph generation by iterative message passing,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Honolulu, HI), 5410–5419.
- Girshick, R. (2015). “Fast R-CNN,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV 2015) (Santiago), 1440–1448.
我们通过实体对的边界框boxs,boxo的并集框来模拟实体对的交互环境。交互环境的特性被表示为feat boxu]。与文本关系抽取中的标记嵌入相似,通过在ROI池后的特征中添加一个遮罩来指定交互环境中的主客体位置。在合并框的ROI池之后,掩模是与特征形状相同的二进制矩阵。ROI池后的每个特征元素对应于原始图像中的网格区域。然后,掩码的每个非零元素对应于实体边界框和bin边界框的并集(lou)上的交集。形式上,非零元素Ind 0]的指数由下式给出:
Ind i , j { s , o } = IoU ( Region ( b o x u ) i , j , b o x { s , o } ) \operatorname{Ind}_{i, j}^{\{s, o\}}=\operatorname{IoU}\left(\operatorname{Region}\left(b o x_{u}\right)_{i, j}, b o x_{\{s, o\}}\right) Indi,j{s,o}=IoU(Region(boxu)i,j,box{s,o})
其中Region(boxu)i,j 是位于ROI池窗口第i行和第j列的网格图像上的相应区域,形式上,给定主题特征 feat[boxs]、对象特征 featlboxol 和联合特征 feat[boxu], 然后按如下方式计算实体对的特征 F(S,0)
F ( s , o ) = feat [ b o x s ] \mathcal{F}(s, o)=\text { feat }\left[b o x_{s}\right] F(s,o)= feat [boxs]

其中 ⊗ \otimes ⊗ 连接操作,O 是元素乘法。