深度强化学习+启发人类的决策智能,专访一家有愿景的中国企业「启元世界」 ...
雷锋网 AI 科技评论按:上次我们报道了来自中国的决策智能企业「启元世界」,他们凭借自己的核心技术深度强化学习和决策智能平台,在 NeurIPS 2018 多智能体竞赛「炸弹人团队赛」中获得了 Learning 组冠军。
启元世界对于深度强化学习技术路线的选择,不禁让人想起了同样深耕强化学习、以围棋 AI AlphaGo 闻名世界的人工智能企业 DeepMind。同时,启元世界也和年轻人生活中不可或缺的元素 —— 游戏 —— 有着千丝万缕的联系。
但另一方面,强化学习作为一个快速发展的新兴技术领域,本身尚有许多挑战,如可复现性、可复用性和鲁棒性方面的问题可能也会限制它的实际应用。启元世界把深度强化学习用于决策智能的信心和热忱来自哪里?他们如何看待强化学习的种种挑战?他们又有哪些技术成果支撑自己的远大想法呢?抱着这些好奇,我们采访了启元世界的创始人 & CEO 袁泉。

袁泉,启元世界创始人 & CEO:曾担任阿里认知计算实验室负责人、资深总监,手机淘宝天猫推荐算法团队缔造者,打造了有好货、猜你喜欢等电商知名个性化产品,率团队荣获 2015 年双 11 CEO 特别贡献奖。加入阿里前,袁泉曾是 IBM 中国研究院的研究员,从事推荐等智能决策算法的研究,是 IBM 2011 年全球银行业 FOAK 创新项目发起人。在工业界大规模应用实践的同时,总结并发表了十余篇论文在国际顶级会议 ACM RecSys、KDD、SDM 等。袁泉拥有多项中美技术专利,长期担任 ACM RecSys、IEEE Transaction on Games 审稿人。
启元世界是一家 2017 年成立的以认知决策智能技术为核心的公司,由前阿里、Netflix、IBM 的科学家和高管发起,多位名牌大学的博士和硕士加入,并拥有伯克利、CMU 等知名机构的特聘顾问。启元世界的愿景是「打造决策智能、构建平行世界、激发人类潜能」,团队核心能力以深度学习、强化学习、超大规模并行计算为基础,拥有互联网、游戏等众多领域的成功经验,受到国内外一流投资人的青睐。

10个训练后的智能Reaper在环境中与玩家控制的10个Reaper对抗,表现出智能进退、追逐、分组合围、利用地形腾挪跳跃的能力
雷锋网 AI 科技评论:启元世界的核心关注点是认知决策智能技术。我们有所耳闻的决策智能应用场景包括金融风控、医疗辅助诊断等等。启元世界目前对哪些行业场景的关注比较多?成果如何?未来还计划覆盖哪些行业场景?
袁泉:我们关注的主要是游戏、网络智能和仿真相关的行业。我们的深度强化学习等技术,其实最早也是从游戏中训练而来的,而后基于启元决策智能平台做进一步的拓展和应用。所以我们比较自然的先发掘游戏行业的应用,比如为游戏公司提供 AI 引擎和服务。我们的 AI 智能体不仅可以在游戏中替代传统的 NPC,甚至可以陪人玩得很有乐趣(AI 和人类一起玩星际争霸的视频参见 这里),所以电子竞技行业是我们关注的比较多的。网络智能和仿真也是深度强化学习有优势的领域。
我们公司创办一年多,主要精力投入到核心技术和产品的研发,尤其是启元决策智能平台。启元决策智能平台经过了若干轮的迭代,内部版本号已经到了 -v0.8。目前启元的决策智能平台已经具备如下竞争优势:
第一,持续学习的能力。持续学习的能力是智能体训练中关键的一环。在训练阶段,智能体需要在学习新技能的过程中保留过去学会的技能,才能达到很高的水平。启元决策智能平台通过智能体群体匹配竞技的方式实现「自然选择」,从而达到持续学习的效果。在竞技过程中,强者留存,弱者被淘汰。在弱者被淘汰之后,空出来的位置被强者的克隆体代替,而强者的克隆体则根据新的超参设定持续进化。在固定计算资源预算的情况下,启元决策智能平台通过这套机制在探索新强者(exploration)和深挖旧强者(exploitation)之间平衡对计算资源的使用情况。
第二,支持复杂场景的多智能体联合训练。在多智能体博弈问题中,不同智能体之间的相互克制较为常见,其收敛可能性极为复杂。以炸弹人竞赛举例,在竞赛中,不同队伍的智能体风格迥异,有的善攻,有的善守。基于「鲶鱼效应」的思想(指透过引入强者,激发弱者变强的效应),启元决策智能平台在训练初期引入基于规则的高阶对手,激发初期较弱的智能体在与强者的对决中学会各种基本技能,迅速提升变强;随着训练阶段的深入,启元决策智能平台同时训练多个智能体,使其在激烈的相互对抗中完善自我。
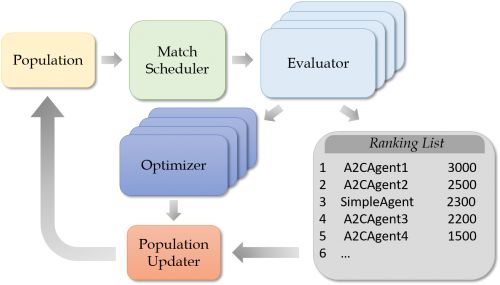
第三,支持基于私有云集群的大规模、高并发的模拟和大规模训练。启元决策智能平台将多个模块进行组件化,并封装到了容器中(如图)。通过云端自动化的方式管理数百 CPU 以及 GPU 资源并实现容器编排,降低了调度数十个炸弹人训练任务的成本。大规模、高并发的模拟计算以及大规模的训练同时在私有云集群中进行。另外,启元决策智能平台提供分布式存储方案,并配置成共享模型池,为炸弹人智能体模型群体的持久化和共享提供支持。
2018 年我们已经尝试把一些技术商业化,目前也取得了不错的营收。2019年,启元世界计划发布第一版启元决策智能平台型产品,为更多行业客户、终端用户带去高体验的服务。
说回决策智能,它是个比较通用的技术,这种辅助决策的能力可以泛化到很多行业,甚至包括网络智能 —— 其实网络中的每一个节点也都是一个可决策的智能体,决策智能有很大的发挥空间。未来可能对于电信电力、网络智能相关的行业我们也会关注。
雷锋网 AI 科技评论:决策智能在现实应用中需要考虑决策的可解释性、决策的公平性、给人类提供辩解的机会等等问题。你们对这些问题是否有所准备?
袁泉:可解释性、公平性这些都很重要。这里面不仅要给人类提供辩解的机会,也需要让 AI 解释自己的决策过程,向人展示可信任的、具备可解释性的决策,以及辅助决策的结果。比如其中一种方式是,可以把决策结果以很好的可视化呈现出来,我们过去在电商中做过的推荐系统,在生成推荐结果的时候可以同时给出几条可解释性的推荐理由。目前我们也从技术上,包括深度学习可解释性相关的技术上做更多的技术积累。
雷锋网 AI 科技评论:对于人工智能决策,有一个常被谈起的设想问题是,假如一辆高速行驶的自动驾驶汽车面前突然冲出一个行人,减速避让可能会伤害到车内的人,而不减速避让则会伤害到这个行人。决策智能能否完美地解决类似这样的问题呢?
袁泉:自动驾驶这个场景我们看的并不是很多,只能简单谈谈我对这个问题的理解。
首先,如果这是一个有智能的汽车,已经出现了这种情况,也就是说已经到了不得不做这种决策的时刻了,这就其实是一个很晚的决策时机了。其实理想的情况就是要避免这类两难决策的发生。当我们学开车的时候,最重要的一个原则就是 defensive driving,防御性驾驶。所以如果是一个真正智能的决策系统,它应该会预估到前方可能出现的意外,比如冲出来的行人或者小狗,对突发情况有一定的准备,尽量避免这样决策时机很晚的状况。决策的 timing 很重要,不应该错过最佳的决策时机。
其次,如果行进过程中确实有这种情况发生的时候,这个最大的原则肯定是保护人:保护人的生命,我觉得这应该是第一原则。这让我想到阿西莫夫的机器人三原则,其实自动驾驶汽车就是一个机器人,它在任何时候都要以不得伤害人的生命为第一原则。如果是要在行人的生命和乘客的一些小的损伤、安全性上面做一些取舍,我相信可能也应该遵从这种原则。

NeurIPS 炸弹人竞赛中,炸弹人学会准确的炸箱子,并且通过最短路径寻路吃增强药
雷锋网 AI 科技评论:在 NeurIPS 炸弹人竞赛中使用的决策智能来自启元决策智能平台上运行的强化学习算法。对于游戏竞赛来说用强化学习的学习范式是很自然的选择,那么其它领域的决策智能也是用强化学习的吗?(相比于更为直接的监督学习)
袁泉:我们团队在过去十多年中做过互联网推荐广告、图像、以及云,有很多标注数据,这种时候就用监督学习来学习大数据。但是标注数据的成本非常高,所以我们强调说,其实强化学习是更接近于人类、尤其是接近于小孩的自然学习过程。强化学习现在不仅可以适用在游戏里面,也可以用在自动驾驶。比如在真实世界中学习,哪怕积累了几百万公里的数据,你可能都很难获得有信息量的负样本(交通事故场景)。但是你在虚拟环境中,用强化学习去学习,是很容易获得这种负样本的。
所以强化学习这种范式,是可以走到游戏之外的很多别的行业的,在自动驾驶、AlphaGo 之后,还可以用来做推荐,谷歌已经用它做数据中心的节能,还包括我刚才提到的网络智能,都可以用强化学习的方式去学。
雷锋网 AI 科技评论:那么强化学习有机会全面替代监督学习吗?
袁泉:目前还不可以。监督学习的核心是它的正负反馈,样本的正负 label 其实是非常清楚和明确的一个信号,这个信号会指导机器学习系统的学习过程。但是强化学习中的「label」,也就是 reward,其实是个弱信号,它要么是由环境给定的,要么是 AI 开发人员指定的。也可以认为它其实是对监督学习强信号的一种逼近。
在一些情况下,比如说我们已经有了监督学习的大数据,而且这种任务又很关键、容错率低,那么借助监督学习的正负信号,它可以学得更明确,学的更有指向性。强化学习相对监督学习,毕竟是一个新兴的领域。监督学习通过过去几十年的发展,从理论到工业界应用成熟度是比较高的。

2017 年 5 月,乌镇,柯洁在三番棋中输给 AlphaGo Master
雷锋网 AI 科技评论:强化学习是近年来的人工智能研究热点,但是学习过程本身就有诸多困难,正如你们在介绍中说道「可复现性、可复用性和鲁棒性方面依然存在挑战」。那么你们选择强化学习作为自己的核心技术研发方向,可以谈谈有信心的理由吗?目前有哪些原创的技术成果吗?
袁泉:我们创始团队过去做了十多年的大数据、监督学习之后,看到这个新兴的技术领域就觉得很有兴趣,整个创始团队都对这个领域非常有 passion,不管是对技术本身,还是对玩游戏这件事。我们多位创始团队的成员其实都很喜欢玩游戏,尤其是一些比较有深度、有创造性的游戏。我和联合创始人海涛,十多年前就对星际争霸非常喜欢。
觉得有信心的理由的话,就是归根结底还是来自于团队和对强化学习的信仰。就像 AlphaGo 论文的一作以及主程序员、DeepMind 的科学家 David Silver 十多年前专门从英国跑到冰天雪地跟开辟了这整个领域的 Richard Sutton 学习强化学习。在这之前 David Silver 和 DeepMind 的另外一个创始人 Demis Hassabis 已经创办了一家电子游戏公司,十多年前就在探索《黑与白》这类基于 AI 的游戏。这都是他们对强化学习有信仰的证明。
目前通过这两年我们技术的积累,已经产生了不少原创性的技术成果,尤其是和游戏这种博弈场景结合起来。近几年热门的三款游戏都是这样的博弈类的游戏(MOBA)。我们目前已经有十余个专利、软件著作权作为我们这方面技术成果的体现,以及基础的技术平台 —— 启元决策智能平台。
其实当很多人还在谈论强化学习劝退文、谈到强化学习的训练不稳定的时候,我们已经在这个平台上不断打磨,让智能体能够稳定的学习和训练起来。包括这次炸弹人竞赛,我们每个阶段的训练过程是没有人类编写的先验规则参与的,都是智能体自己学出来的,学习曲线也非常漂亮,而且是两个智能体在稳定地往上提升效果。
我们这一次得了竞赛冠军之后,就已经把竞赛的成果写了一篇论文(arxiv.org/abs/1812.07297),我们近期还有一篇论文在提交,是关于如何把强化学习和演化博弈论结合起来。未来我们也会更系统地整理其中的创新点、补充更多的实验结果后,跟学界和产业界分享。
雷锋网(公众号:雷锋网) AI 科技评论:现阶段你们都面对(还面对)哪些技术挑战?总体解决思路如何?
袁泉:技术挑战肯定还是存在的,深度强化学习也是个新兴的方向,刚刚火起来。
深度强化学习这个方向,我们从自己业务场景和体会来看,一个很大的门槛是大规模复杂场景的智能体的训练。这也是我们启元决策智能平台尽力在解决的目标。就在 NIPS 2018 上面,加拿大很权威的教授、图灵奖得主 Judea Pearl 还在讲强化学习的这种可复现性问题。目前我们在平台上已经积累了许多技术,一定程度上解决了这些问题,但是随着比如智能体规模变大,比如上千个智能体,甚至在更复杂、更开放的环境中去训练,如何能够稳定收敛也是我们在探索的方向。
另一个问题是,在非完全信息环境下如何博弈。 AlphaGo 下围棋,是一个完全信息博弈(双方都能看到棋盘上的所有棋子的位置),但是基本上所有的游戏场景,以及现实的决策场景,都是不完全信息的。其实任何一个人做决策可能都是在不完全信息下做决策。我们提交的一些论文就是尝试把强化学习和博弈论结合起来,一起去研究,这个也是新的方向。
从决策的角度讲,决策智能目前也还是一个世界级的难题,决策过程也是人脑中最复杂的一种功能。从我们十余年前在 IBM 研究院对 Watson 的理解、在阿里电商平台的实践,以及在认知计算实验室所研读的 AI 数十年发展史来看,主要有以下几方面:一、决策过程是主观与客观、理智与情感相融合的过程,目前计算机擅于处理的是理性可计算部分,因此需要更好的建模和逼近路径; 二、影响决策的因素非常多,人是在多源信息密布的环境中进行决策,需要有效甄别和提取有效信息,同时对未知信息进行推理和假设。 三、各个行业运用决策智能的场景往往是要求实时决策,甚至是高并发决策,如互联网中通常需要在毫秒级返回给用户的推荐结果,因此对系统架构上挑战也很大。
我们优势是基于创始人、创始团队过去十余年在国际一流的研究机构、互联网企业的经验,对世界范围内整个领域有深入的洞见和实践经验,清楚技术的边界和发展路径,与伯克利、CMU、纽约大学的许多知名专家学者都建立了深入的合作机制,能比较好的将决策智能的技术研发与前沿科研统一起来,兼顾商业化的落地场景。

雷锋网 AI 科技评论:最后一个问题,您曾经在阿里工作了较长时间,那么您离开阿里创业的动力和愿景是什么?
袁泉:我从 2006 年开始做个性化推荐,最早在 IBM 的五六年主要是以研究和发表论文为主。然后 2012 年加入阿里,到 2017 年离开,非常感谢阿里这个平台,让我把过去研究算法、推荐系统的经验,能够完全应用在平台上。产品从手机淘宝、到天猫,再到双 11 项目,都成功地应用起来了。从我个人来说,非常感谢阿里这个平台,自己实现了阶段性的目标和使命。
决定离开,因为自己觉得在一个方向上做了超过十年之后,可以暂时告一段落。而且又看到以 AlphaGo 为代表的新技术,以及背后像 DeepMind 这样的有梦想的公司。所以我觉得我们这个团队也可以尝试新技术和远大的事情。我们公司的名字就叫启元世界,英文叫 Inspir.AI ,希望可以用 AI 启发更多的人。比如在游戏这样的虚拟化的场景中,可以更好地帮助人做辅助决策,以及给人提供创造性、有价值的,甚至启发人的事情。
出于这样的初心,我们希望 Build Intelligence ,打造决策智能; Incubate Worlds,构建平行世界,比如各种虚拟的游戏、虚拟的场景,甚至和 VR 结合起来的平行世界;Inspire People,通过决策智能帮助人、激发人的创造力。
上个月强化学习之父 Richard Sutton 为我们公司题词「To inspir.ai, Let us all be inspired ! 」是对我们最好的鼓励!