【比赛实战篇】天池-新冠疫情相似句对判定大赛top6方案及源码

转载: AILIGHT
Hi,大家好!这里是AILIGHT!AI light the world!这次给大家带来的是天池-新冠疫情相似句对判定大赛top6(并列)的代码开源。
比赛传送门:https://tianchi.aliyun.com/competition/entrance/231776/introduction
这次是常规的NLP赛题-语义相似度匹配。在之前的也有很多同类型的比赛,大家有兴趣的都可以了解了解。链接:https://ai.ppdai.com/mirror/goToMirrorDetail?mirrorId=1 https://tianchi.aliyun.com/competition/entrance/231661/introduction
Part 1 任务描述
比赛主打疫情相关的呼吸领域的真实数据积累,数据粒度更加细化,判定难度相比多科室文本相似度匹配更高,同时问答数据也更具时效性。本着宁缺毋滥的原则,问题的场地限制在20字以内,形成相对规范的句对。要求选手通过自然语义算法和医学知识识别相似问答和无关的问题。
 评估指标:准确率
评估指标:准确率
Part 2 语义匹配算法简要介绍
文本匹配是自然语言处理中一个重要的基础问题,自然语言处理中的许多任务都可以转为文本匹配任务。如网页搜索可抽象为网页同用户搜索 Query 的一个相关性匹配问题,自动问答可抽象为候选答案与问题的满足度匹配问题,文本去重可以抽象为文本与文本的相似度匹配问题。
这次的比赛是一个语义相似度计算的任务,不能只停留在字面匹配层面,更需要语义层面的匹配,不仅是相似度匹配,还包括更广泛意义上的匹配。
随着深度学习技术的逐渐兴起,基于神经网络训练出的 Word Embedding 来进行文本相似度计算的实践越来越多。Word Embedding 的训练方式更加简洁,而且所得的词语向量表示的语义可计算性进一步加强。
从最开始的DSSM, Match-LSRM, MatchSRNN到后面的ESIM,BIMPM,DIIN再到现在的bert。由于bert的显卡要求相对高一些,所以我们先简单介绍一下简单的语义匹配算法,例如上面提到的很多基于Siamese 网络的经典算法ESIM以及后续ESIM的变体,提取文本整体语义再进行匹配。如下就是ESIM(https://arxiv.org/pdf/1609.06038.pdf)的网络结构。
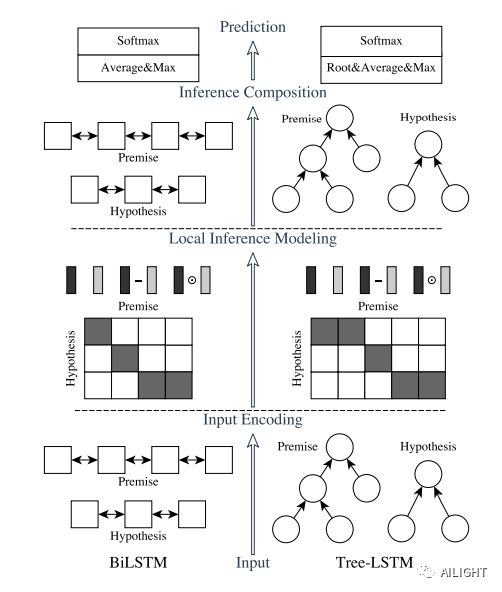
Input Encoding
输入两句话分别接 embeding 加一个双向LSTM
Local Inference Modeling
这里的目的是把第一层拿到的特征做差异性计算和信息交互。作者采用了soft_align_attention机制,进行交互。
Inference Composition
在这一层中,再通过BILSTM捕获局部推理信息特征及其上下文信息特征,下面是分别最大池化与平均池化,然后concat输入MLP,得到最终结果。
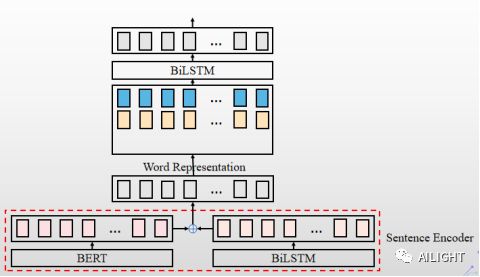
当然我们也可以在网络输入层通过tfidf加权词向量,加权逻辑如下图所示:
 n*d 的 embedding 矩阵 通过长度为 n 的 tfidf 向量来修正,修正后的 embedding 矩阵获取了全局的信息,让网络更加注重关键的单词,有助于对文本相似度的识别。即:sentence1 = [w11,w12,...,w1n] sentence1_new=[w11×tfidf11,w12×tfidf12,..]
n*d 的 embedding 矩阵 通过长度为 n 的 tfidf 向量来修正,修正后的 embedding 矩阵获取了全局的信息,让网络更加注重关键的单词,有助于对文本相似度的识别。即:sentence1 = [w11,w12,...,w1n] sentence1_new=[w11×tfidf11,w12×tfidf12,..]
这个加权词向量根据我们实验的结果在拍拍贷的语义相似度的比赛和2018CIKM的跨语言文本语义相似度比赛中都是有非常明显的提升。对于机器有限的同学可以在此类任务中尝试这些方法。
Part 3 数据处理&模型尝试
目前由于bert的强大超乎我们的想象,所以这次比赛中我们也没有过多的思考,直接bert一把梭,基本没有什么数据分析。只是根据赛题给的原始数据进行了简单的数据构造和各种开源的预训练模型的对比。
数据增强 根据数据传递性数据增强
原始数据:句子A和句子B相似, 句子A和句子C相似, 句子A和句子D不相似
增强后数据:句子A和句子B相似, 句子A和句子C相似, 句子B和句子C相似, 句子A和句子D不相似,句子B和句子D不相似,句子C和句子D不相似
具体模型结果如图:
预训练模型尝试&各个模型的线上分数
roberta-wwm-large~95.4
https://github.com/ymcui/Chinese-BERT-wwm
roberta-wwm-large+fgm(5 ensemble) ~95.6
roberta_large_clue/roberta_large_pair+ fgm ~95.8
https://github.com/CLUEbenchmark/CLUECorpus2020
NEZHA/NEZHA-wwm(5 ensemble) + fgm ~95.9
https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/NEZHA
UER-py+ fgm ~96.00
https://github.com/dbiir/UER-py
融合(UER-py + NEZHA)(10 model) 96.26
模型优化
特征融合(预训练模型 + 腾讯词向量 + fasttext词向量)
腾讯词向量(https://ai.tencent.com/ailab/nlp/embedding.html)
fasttext词向量(https://fasttext.cc/)
对抗学习/FGM
https://kexue.fm/archives/7234
Part 4 final模型
最终本次比赛采用UER-py + NEZHA各5折共10个模型进行模型融合
线上成绩:准确率 96.26
总结:这次的开源基本只是一个base方案,还有很多细致的可以优化的东西,大家可以把这次比赛的代码在后续的语义相似度计算的比赛中当作是baseline,在这个的基础上进行优化。
https://god.yanxishe.com/53这是最近一个新的文本语义相似度计算的比赛。大家可以去试试这个base方案,希望可以取得好的成绩。
关注并回复“AILIGHT新冠疫情相似句对判定 ”获取源码地址链接,还没有关注AILIGHT的朋友,扫描下方二维码识别关注吧。有什么建议也可以后台留言哦!
个人微信:加时请注明 (昵称+公司/学校+方向)

也欢迎小伙伴加入NLP交流群,刚刚创的,想和大家讨论NLP(若二维码过期可加作者微信)!

