HashMap实现了一个Hash表为主的数据结构,他将数据根据key的哈希值,存储于一个数组中,通过合理的碰撞,将相同hash值的数据通过链式结构存储。
很显然,这种hash结构存储的数据是无序的,JDK通过继承HashMap实现了集中有序的HashMap数据结构,如链表式的LinkHashMap
首先看,LinkHashMap是继承与HashMap的:
public class LinkedHashMap extends HashMap implements Map
那么这个Link是怎么实现顺序存储的呢?
他通过构造出另一个数据结构Doubly Linked List存储数据顺序,注意,这里他即实现了HashMap原有的数据结构进行数据存储,再实现了另一个Doubly Linked List去存储数据的顺序,这两个数据结构是相互独立,同时存在的。
private transient Entry header;
这里的header就是该link的头元素,其中Entry在这里重新进行了定义:
private static class Entry extends HashMap.Entry {
Entry before, after;
Entry(int hash, K key, V value, HashMap.Entry next) {
super(hash, key, value, next);
}
}
他既继承了原有的Entry结构,同时,加入了before, after的双向指针。
那么看一下,header在LinkHashMap初始化时:
void init() {
header = new Entry<>(-1, null, null, null);
header.before = header.after = header;
}
header定义了一个空的entry,同时这个entry的hash值为-1(也就是这个entry不会存入HashMap中的hash table中)。同时将entry的双向指针都指向自己。
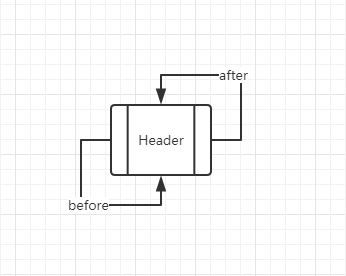
那么,现在看一下,怎么向这个header链表新增一个元素。LinkHashMap继承了put方法,同时重写了createEntry方法:
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry old = table[bucketIndex];
Entry e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
e.addBefore(header);
size++;
}
其中,加入了e.addBefore(header),这里的addBefore放在在Entry中定义为:
private void addBefore(Entry existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
举例,在header中加入第一个entryA时:

那么EntryA加在了Header之前,那么插入第二个元素EntryB时:

那么这里就是在entryA和header之间加入一个元素。
上面介绍了如何将一个entry加入到header中,使用的是put方法,同时linkHashMap还提供了在get的方法中修改header顺序的方法,这里就不讲述了。
总结:
==LinkHashMap实际是在HashMap的基础上再实现了一个链表的结构进行存储数据顺序的。==