Python练习之小爬虫--从requests到selenium
前言:
开始学习python快2个月了,前段时间突然很喜欢爬虫,研究了一段时间,有一些心得体会,也完成了我自己的需求,趁着还新鲜记录一下,做一个总结。也希望能帮到刚入坑的同学,尽早爬坑。
(一)工具
我用的是pycharm和anaconda,这里强烈推荐anaconda,如果用原版python,以后会发现有些库安装不了或者过程曲折,折腾一下午白瞎的痛苦不要问我是怎么知道的。。。
安装好后进入cmd,用pip安装两个库,requests库和bs4。
以上步骤弄好后进入正题
(二)静态网页数据采集
这里直接用一个经典的案例好了----豆瓣电影TOP250。
http://movie.douban.com/top250/
1、首先分析网页,看看网页的结构找到我们需要采集的元素。这里需要使用chrome浏览器或者chrome内核的浏览器F12功能,如图
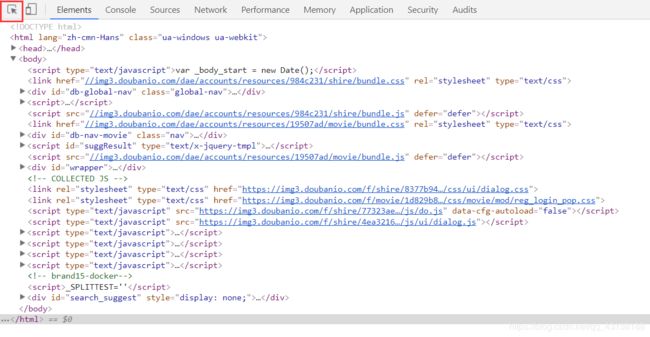
F12得到是当前页面的源码,我们需要的信息就在这里面,然后用红框标注的箭头在页面上我们需要采集的信息上点一下,就得到了该信息具体在源码的哪个位置了(或者在网页上点击右键,审查元素)。

这是点了肖申克救赎的结果,从图上就可以很清晰的看出来,每一部电影的所有信息都在一个Li标签里面,电影名字在一个span标签里,标签属性是title。由此就可以得出我们的爬虫逻辑是遍历所有的Li标签,取出需要的数据。
2、代码的实现
import requests
from bs4 import BeautifulSoup
URL = 'http://movie.douban.com/top250/'
def gethtml(url):
html = requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 \ '
'(KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}).content
这段就是用requests来请求豆瓣top250的网页,.content获得网页的源码。在使用requests的时候,一般都要加上headers参数,来伪装成一个浏览器访问,有的网站需要添加更多参数才行。
def parsehtml(html):
soup = BeautifulSoup(html,'html.parser')
lis = soup.find('ol',{'class': 'grid_view'}).find_all('li')
movie_name_list = []
for li in lis:
movie_name = li.find('div',{'class': 'hd'}).find('span',{'class': 'title'}).getText()
movie_name_list.append(movie_name)
next_page = soup.find('span',{'class': 'next'}).find('a')
if next_page:
return movie_name_list, URL + next_page['href']
return movie_name_list, None
这段定义了一个解析函数,用beautifulsoup定位到我们需要的元素并获取文本,返回两个值一个是电影名字列表,一个是下一页的网址
url = URL
with open('movies', 'w') as fp:
while url:
html = gethtml(url)
movies, url = parsehtml(html)
fp.write('{movies}\n'.format(movies='\n'.join(movies)))
这段就算是主函数了,用url接收返回的下一页的网址,while循环获得所有页的电影名字,然后写入文件。
拼接起来就是一段完整的代码,结果如图

至此,一个爬取静态网页的框架就有了,很简单,从零开始2到3天就能搞定其语法和代码实现。接下来就是花了我将近2个星期的采用ajax技术的网页爬取了。
(三)动态网页数据采集
这里的动态网页我是指用ajax技术异步加载的网页,对新人很不友好的一个坑。在读过n篇文章和m次测试后,我才意识到这种网页看着源代码里啥内容都有,但是你就是get不到。因为requests.get(url),面对ajax网页,get到的只是一个框架,内容是之后加载的,requests表示无能为力。还好这时候逆天神器selenium出现了。
selenium本是一个自动化测试的工具,现在却是爬虫的好朋友,因为它能模拟浏览器的行为。
1、准备工作
Selenium必须配合webdriver才能使用,各大浏览器都有自己的webdriver,我懒得装新浏览器,就用win10自带的Edge浏览器了。(好像有个无头浏览器也可以替代webdriver)
2、分析网页
我的目标网页是一个类似聊天室的课堂,有老师讲课,有学生发言,有老师回复。输入账户密码登陆后的源码是这样的
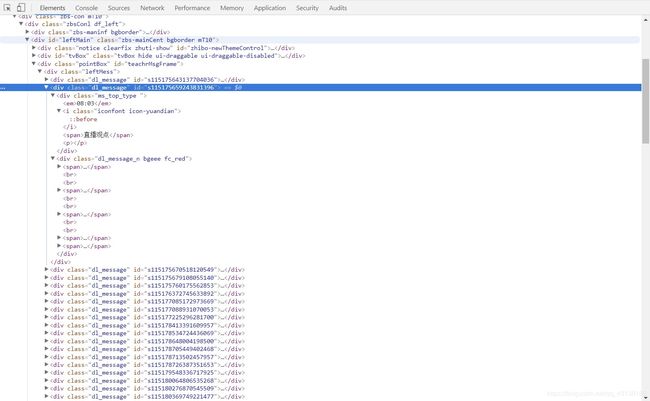
源码一目了然,所有信息都在div标签里,class属性为dl_message,每一个div标签里的子标签对应着相应的信息。
3、代码实现
from selenium import webdriver
import time
from docx import Document
import requests
from io import BytesIO
import os
from docx.shared import RGBColor
from selenium.common.exceptions import NoSuchElementException
from datetime import datetime
导入这一堆模块
#日期
y = input('date_of_year:')
m = input('date_of_month:').zfill(2)
d_start = input('start_of_day:')
d_end = input('end_of_day:')
我的目标是导出这个课堂的历史聊天记录,然后导出的记录存到docx文档中,并按照当天的日期保存。
#设置存储路径,按照时间保存
basepath = 'C:\\Users\\yy\\Desktop\\'
dir_name = '{name}'.format(name = (y+"."+m))
dir_path = os.path.join(basepath,dir_name)
os.mkdir(dir_path)
browser = webdriver.Edge()
browser.get('http://www.targetwebsite.com')
time.sleep(6)
这里利用os模块在桌面上新建一个文件夹,接着调用webdriver打开Edge浏览器,然后打开目标网站(对于需要登陆的网站,可以提前登陆一次,之后webdriver打开的时候是带着cookie的)。time模块的sleep方法就是让程序等待6秒,因为网页加载需要时间(这也是selinium爬虫的一个劣势,就是效率比较低)。
def weekday(date):
week = datetime.strptime(date,'%Y%m%d').weekday()
if week > 4:
return '-周末'
else:
return ''
这个方法是获得任意一天是周几。周一是0,周天是6。
def getpics(element):
try:
element.find_element_by_tag_name('img')
except NoSuchElementException:
pass
else:
msg_imgs = element.find_elements_by_tag_name('img')
for msg_img in msg_imgs:
msg_img_url = msg_img.get_attribute('src')
img = requests.get(msg_img_url).content
document_class.add_picture(BytesIO(img))
这个函数是用来获取课堂上的图片的。每个图片都在img标签里,关于selenium的定位语法我就不多说了,太多了。借助reques和IO模块,就可以将网上的图片直接存入docx文档。
def write_docx(content,color):
if color == 'red':
rgbcolor = RGBColor(255, 0, 0)
elif color == 'orange':
rgbcolor = RGBColor(255, 97, 3)
elif color == 'black':
rgbcolor = RGBColor(0, 0, 0)
para = document_class.add_paragraph()
run = para.add_run(content)
run.font.color.rgb = rgbcolor
这个函数是将文字写入docx的,接收2个参数,一个是内容,一个是颜色,最后三行是docx模块指定文字颜色的方法。
def getclass(element,color):
try:
element.find_element_by_class_name('dl_message_n bgeee fc_red').text
except NoSuchElementException:
pass
else:
msg_text = element.find_element_by_class_name('dl_message_n bgeee fc_red').text
write_docx(msg_text,color)
这个函数就是读取课堂文字的,并调用上一个函数将文字写入文档。
def getchat_teacher(element):
try:
element.find_element_by_class_name('dl_message_n bgeee fc_666').text
except NoSuchElementException:
pass
else:
msg_text_stu = element.find_element_by_class_name('dl_message_n bgeee fc_666').text
write_docx(msg_text_stu,'black')
try:
element.find_element_by_class_name('dl_ask_box fc_red').text
except NoSuchElementException:
pass
else:
msg_text_teacher = element.find_element_by_class_name('dl_ask_box fc_red').text
write_docx(msg_text_teacher,'red')
获取老师与学生的对话。学生黑字,老师红字。
def getchat_assis(element):
try:
element.find_element_by_class_name('dl_message_n bgeee fc_666').text
except NoSuchElementException:
pass
else:
msg_text_stu = element.find_element_by_class_name('dl_message_n bgeee fc_666').text
write_docx(msg_text_stu,'black')
try:
element.find_element_by_class_name('dl_ask_box fc_red').text
except NoSuchElementException:
pass
else:
msg_text_teacher = element.find_element_by_class_name('dl_ask_box fc_red').text
write_docx(msg_text_teacher,'orange')
获取老师助理的对话,学生黑字,助理橙色。
def getmore():
try:
browser.find_element_by_link_text('点击查看更多')
except NoSuchElementException:
pass
else:
if browser.find_element_by_link_text('点击查看更多').get_attribute('style') == 'display:none':
pass
else:
try:
browser.find_element_by_link_text('点击查看更多').click()
except NoSuchElementException:
pass
else:
time.sleep(0.5)
getmore()
这是一个很好玩的地方,这个网站不一次性显示全部内容(源代码也是),而是页面到头后需要手动点一下查看更多,点好几次之后才能全部显示,此时查看更多标签就消失了。
我的实现逻辑就是用try-except-else,配合一个骚气的小递归解决,当时写到这里脑子里一下子蹦出来的就是递归,就写递归了,实际while可以更简单直接的解决,就这样吧。。
def getchat(element):
chat = element.find_element_by_class_name('dr_text_n bgeee ').text
document_chat.add_paragraph(chat)
获取聊天记录。
以上函数都写好后,就是根据具体页面的逻辑写2个小爬虫了,一个爬取课堂记录,一个爬取聊天记录。
def class_docx():
try:
browser.find_elements_by_class_name("dl_message")
except NoSuchElementException:
pass
else:
msgs = browser.find_elements_by_class_name("dl_message")
for msg in msgs:
try:
msg.find_element_by_class_name("ms_top_type ")
except NoSuchElementException:
pass
else:
msg_time = msg.find_element_by_class_name("ms_top_type ").text
msg_type = msg.find_element_by_class_name("iconfont icon-yuandian").text
if '直播观点-老师助理' in (msg_time + msg_type):
document_class.add_paragraph(msg_time + msg_type)
getclass(msg,'orange')
getpics(msg)
elif '直播观点' in (msg_time + msg_type):
document_class.add_paragraph(msg_time + msg_type)
getclass(msg,'red')
getpics(msg)
elif '互动回复-老师助理' in (msg_time + msg_type):
document_class.add_paragraph(msg_time + msg_type)
getchat_assis(msg)
elif '互动回复' in (msg_time + msg_type):
document_class.add_paragraph(msg_time + msg_type)
getchat_teacher(msg)
elif '系统消息' in (msg_time + msg_type):
pass
else:
document_class.add_paragraph(msg_time + msg_type)
getclass(msg,'red')
getchat_teacher(msg)
getpics(msg)
获取课堂记录,并写入docx文档。
def chat_docx():
try:
browser.find_elements_by_class_name("dr_ms_n")
except NoSuchElementException:
pass
else:
msgs = browser.find_elements_by_class_name("dr_ms_n")
for msg in msgs:
msg_time = msg.find_element_by_class_name('dr_head').text
msg_type = msg.find_element_by_class_name('user_rel').text
document_chat.add_paragraph(msg_time + '' + msg_type)
getchat(msg)
获取聊天记录,并写入docx文档。
#main
for d in range(int(d_start),int(d_end)+1):
d = str(d).zfill(2)
date = y + m + d
js = " window.open('http://www.targetwebsite.com/history/')"
browser.execute_script(js)
time.sleep(6)
browser.switch_to.window(browser.window_handles[1])
print('----开始拷贝{date}的课程----'.format(date=date))
document_class = Document()
class_docx()
document_class.save('C:\\Users\\yy\\Desktop\\{dir_name}\\{name}-0.课堂记录.docx'.format(dir_name=dir_name,name=(y + '.'+ m + '.'+ d + weekday(date)).strip()))
print('----开始拷贝{date}的互动记录----'.format(date=date))
getmore()
time.sleep(2)
document_chat = Document()
chat_docx()
document_chat.save('C:\\Users\\yy\\Desktop\\{dir_name}\\{name}-1.互动记录.docx'.format(dir_name=dir_name, name=(y + '.' + m + '.' + d + weekday(date)).strip()))
print('----*successful finished*----')
browser.close()
browser.switch_to.window(browser.window_handles[0])
time.sleep(2)
这个就是执行的代码了,值得说道的就是5-8行,因为如果每爬完一天的内容就关闭浏览器然后重新打开浏览器太慢了,所以这里我打开的是一个新标签页,爬完就关闭该标签页然后打开一个新的。5-8行就是标签页的操作,注意如果没有第8行,新建了一个标签页后,操作句柄还是在第一个标签页上。
最终执行就是这样子的了

对于一个懒人来说,真的是很方便啊(手动要哭脸),爬虫要继续深入下去,还得研究js,scrapy,数据库等,不过我的爬虫之旅到此就先暂告一个段落,毕竟学python的目的是自动化交易、量化交易的。接下来就还有python面向对象和网络编程这两大块,之后就可以进入量化交易的篇章了。