Python与机器学习实战——SVM(1)
SVM
感知器能将线性可分数据集准确分割开,但是从损失函数可以看出,只是分割开了,但是没有一个最优解,比如:
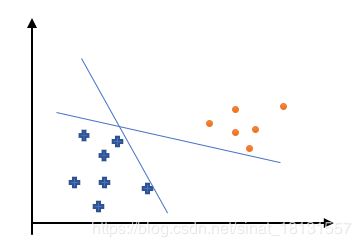
这样虽然两条直线都将数据集分开了,但是如果出现了一个新的数据点,很有可能这个数据点的分割结果是错误的。比如这样:
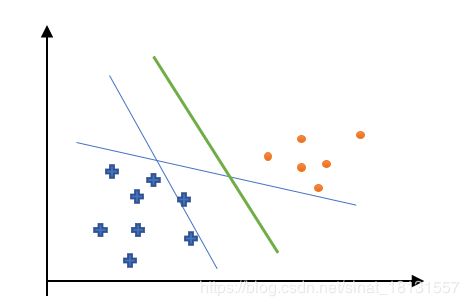
那么就需要绿色的这个“超平面”作为分类输出才行。这个最有“超平面”就是支持向量机SVM的分类思想。
线性SVM
在感知器中有描述到样本点 ( x i , y i ) (x_i,y_i) (xi,yi)到超平面 Π : w ⋅ x + b = 0 \Pi:w·x+b=0 Π:w⋅x+b=0的相对距离为:
d ∗ ( x i , Π ) = ∣ w ⋅ x i + b ∣ d^*(x_i,\Pi)=|w·x_i+b| d∗(xi,Π)=∣w⋅xi+b∣这个也被称为函数间隔(Functional Margin),当 w w w和 b b b等比例变大变小时候,超平面不会发生变化,但是 d ∗ d^* d∗却在变大变小,为了解决这个问题,引出了几何间隔(Geometric Margin):
d ( x i , Π ) = 1 ∣ ∣ w ∣ ∣ ∣ w ⋅ x i + b ∣ = 1 ∣ ∣ w ∣ ∣ d ∗ ( x i , Π ) d(x_i,\Pi)=\frac{1}{||w||}|w·x_i+b|=\frac{1}{||w||}d^*(x_i,\Pi) d(xi,Π)=∣∣w∣∣1∣w⋅xi+b∣=∣∣w∣∣1d∗(xi,Π)其中, ∣ ∣ w ∣ ∣ ||w|| ∣∣w∣∣是 w w w的欧式范数。SVM是让超平面到点集的距离最大化,也就是需要最大化几个间隔 d ( x i , Π ) d(x_i,\Pi) d(xi,Π),使得:
1 ∣ ∣ w ∣ ∣ ( w ⋅ x i + b ) y i ⩾ d ( i = 1 , . . , N ) \frac{1}{||w||}(w·x_i+b)y_i\geqslant d(i=1,..,N) ∣∣w∣∣1(w⋅xi+b)yi⩾d(i=1,..,N)这里,由于在超平面两边的样本点分别分别计算 w ⋅ x i + b w·x_i+b w⋅xi+b是有正有负的,而 y i ∈ { − 1 , + 1 } y_i\in\{-1,+1\} yi∈{−1,+1},所以能使得 ( w ⋅ x i + b ) y i (w·x_i+b)y_i (w⋅xi+b)yi都是正数。 y i y_i yi在这个表示的是符号。
由于 d ∗ = ∣ ∣ w ∣ ∣ d d^*=||w||d d∗=∣∣w∣∣d,所以上式两边同时乘以 ∣ ∣ w ∣ ∣ ||w|| ∣∣w∣∣,问题等价为最大化 d = d ∗ ∣ ∣ w ∣ ∣ d=\frac{d^*}{||w||} d=∣∣w∣∣d∗,并使得:
( w ⋅ x i + b ) y i ⩾ d ∗ ( i = 1 , . . , N ) (w·x_i+b)y_i\geqslant d^*(i=1,..,N) (w⋅xi+b)yi⩾d∗(i=1,..,N)可以发现 d ∗ d* d∗的取值对优化问题的解(超平面的位置)没有影响,比如,当 d ∗ d^* d∗变成了 λ d ∗ \lambda d^* λd∗,那么 w w w和 b b b也变成了 λ w \lambda w λw和 λ b \lambda b λb,但是超平面并没有变化。不妨假设 d ∗ = 1 d^*=1 d∗=1,问题转化为了最大化 1 ∣ ∣ w ∣ ∣ \frac{1}{||w||} ∣∣w∣∣1使得:
( w ⋅ x i + b ) y i ⩾ 1 ( i = 1 , . . , N ) (w·x_i+b)y_i\geqslant 1(i=1,..,N) (w⋅xi+b)yi⩾1(i=1,..,N)由于 1 ∣ ∣ w ∣ ∣ \frac{1}{||w||} ∣∣w∣∣1是非负的,最大化 1 ∣ ∣ w ∣ ∣ \frac{1}{||w||} ∣∣w∣∣1,就是要最小化 ∣ ∣ w ∣ ∣ ||w|| ∣∣w∣∣,为了方便数学表达和计算,将优化问题写成最小化 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}||w||^2 21∣∣w∣∣2使得:
( w ⋅ x i + b ) y i ⩾ 1 ( i = 1 , . . , N ) (w·x_i+b)y_i\geqslant 1(i=1,..,N) (w⋅xi+b)yi⩾1(i=1,..,N)这就是SVM最原始的形式,如果数据集D是线性可分的,那么SVM的解就存在且唯一。
假设最优化的解为 w ∗ w^* w∗和 b ∗ b^* b∗,那么称超平面:
Π ∗ : w ∗ ⋅ x + b ∗ = 0 \Pi^*:w^*·x+b^*=0 Π∗:w∗⋅x+b∗=0为最大硬间隔分离超平面。考虑到不等式的约束条件可以知道在两个平面:
Π 1 ∗ : w ∗ ⋅ x + b ∗ = − 1 Π 2 ∗ : w ∗ ⋅ x + b ∗ = + 1 \Pi^*_1:w^*·x+b^*=-1\\\Pi^*_2:w^*·x+b^*=+1 Π1∗:w∗⋅x+b∗=−1Π2∗:w∗⋅x+b∗=+1中间是没有点的,因为 ( w ⋅ x i + b ) y i < 1 (w·x_i+b)y_i<1 (w⋅xi+b)yi<1了,但是在 Π 1 ∗ \Pi^*_1 Π1∗和 Π 2 ∗ \Pi^*_2 Π2∗上是有样本点的,通常称 Π 1 ∗ \Pi^*_1 Π1∗和 Π 2 ∗ \Pi^*_2 Π2∗为间隔边界,而边界上的点就是支持向量。
那么对于线性不可分的数据集呢?无法找到超平面完全分割数据集,更不用说要间隔最大化。就需要做出一定妥协,将“硬”间隔转化为“软”间隔,就是将不等式的条件放宽。
( w ⋅ x i + b ) y i ⩾ 1 → ( w ⋅ x i + b ) y i ⩾ 1 − ξ i (w·x_i+b)y_i\geqslant 1\rightarrow (w·x_i+b)y_i\geqslant 1-\xi_i (w⋅xi+b)yi⩾1→(w⋅xi+b)yi⩾1−ξi其中, ξ i \xi_i ξi被称为松弛变量,不小于0。加入这个松弛变量后,损失函数需要加入一个惩罚项:
L ( w , b , x , y ) = 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 N ξ i \mathbf{L}(w,b,x,y)=\frac{1}{2}||w||^2+C\sum_{i=1}^N\xi_i L(w,b,x,y)=21∣∣w∣∣2+Ci=1∑NξiC被称为惩罚因子,C越大,最终SVM的模型越不能容忍误分类的点,反之越小。
到现在,SVM算法的最优化问题变为了最小化 L ( w , b , x , y ) \mathbf{L}(w,b,x,y) L(w,b,x,y),并使得:
( w ⋅ x i + b ) y i ⩾ 1 − ξ i ( i = 1 , . . , N ) (w·x_i+b)y_i\geqslant 1-\xi_i(i=1,..,N) (w⋅xi+b)yi⩾1−ξi(i=1,..,N)其中 ξ i ⩾ 0 \xi_i\geqslant0 ξi⩾0,所以可以定义:
ξ i = l ( w , b , x , y ) = max ( 0 , 1 − y ( w ⋅ x + b ) ) \xi_i=l(w,b,x,y)=\max(0,1-y(w·x+b)) ξi=l(w,b,x,y)=max(0,1−y(w⋅x+b))其中 y ∈ { − 1 , + 1 } y\in \{-1,+1\} y∈{−1,+1},所以当模型判断不正确时候,就会有惩罚,而判断正确了就没有惩罚了。损失函数可以写为:
L ( w , b , x , y ) = 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 N l ( w , b , x i , y i ) \mathbf{L}(w,b,x,y)=\frac{1}{2}||w||^2+C\sum_{i=1}^Nl(w,b,x_i,y_i) L(w,b,x,y)=21∣∣w∣∣2+Ci=1∑Nl(w,b,xi,yi)同样也是使用梯度下降法进行训练的,所以有偏导数:
∂ L ( w , b , x , y ) ∂ w = w + { 0 , y i ( w x i + b ) ⩾ 1 − C y i x i , y i ( w x i + b ) < 1 ∂ L ( w , b , x , y ) ∂ b = { 0 , y i ( w x i + b ) ⩾ 1 − C y i , y i ( w x i + b ) < 1 \begin{array}{c}\frac{\partial L(w,b,x,y)}{\partial w}=w+\left\{\begin{array}{l}0,y_i(wx_i+b)\geqslant1\\-Cy_ix_i,y_i(wx_i+b)<1\end{array}\right.\\\frac{\partial L(w,b,x,y)}{\partial b}=\left\{\begin{array}{l}0,y_i(wx_i+b)\geqslant1\\-Cy_i,y_i(wx_i+b)<1\end{array}\right.\end{array} ∂w∂L(w,b,x,y)=w+{0,yi(wxi+b)⩾1−Cyixi,yi(wxi+b)<1∂b∂L(w,b,x,y)={0,yi(wxi+b)⩾1−Cyi,yi(wxi+b)<1这样就可以写出线性SVM的算法实现过程:
输入:训练集 D = { ( x 1 , y 1 ) , . . . , ( x n , y n ) } D=\{(x_1,y_1),...,(x_n,y_n)\} D={(x1,y1),...,(xn,yn)},迭代次数M,学习率 α \alpha α,其中: x i ∈ X ⊆ R n , y i ∈ { − 1 , + 1 } x_i\in \bold{X}\subseteq\mathbb{R^n} ,y_i\in\{-1,+1\} xi∈X⊆Rn,yi∈{−1,+1}过程:
(1)初始化参数: w = ( 0 , . . . , 0 ) T ∈ R N , b = 0 w=(0,...,0)^T\in \mathbb{R^N},b=0 w=(0,...,0)T∈RN,b=0(2)对 j = 1 , . . . , M j=1,...,M j=1,...,M:
(a)算出误差向量 e = ( e 1 , . . . , e n ) T e=(e_1,...,e_n)^T e=(e1,...,en)T,其中:
e i = 1 − y i ( w ⋅ x i + b ) e_i=1-y_i(w·x_i+b) ei=1−yi(w⋅xi+b)(b)取出误差最大的一项:
i = arg max i e i i=\underset{i}{\argmax}e_i i=iargmaxei(c)若 e i ⩽ 0 e_i\leqslant 0 ei⩽0则退出循环。否则取对应样本来进行随机梯度下降:
w ← ( 1 − α ) w + α C y i x i b ← b + α C y i w\leftarrow (1-\alpha)w+\alpha Cy_ix_i\\b\leftarrow b+\alpha Cy_i w←(1−α)w+αCyixib←b+αCyi输出:线性SVM模型 g ( x ) = s i g n ( f ( x ) ) = s i g n ( w ⋅ x + b ) g(x)=sign(f(x))=sign(w·x+b) g(x)=sign(f(x))=sign(w⋅x+b)
SVM算法的对偶形式
SVM的问题为:
min w , b L ( w , b , x , y ) = 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 N ξ i \underset{w,b}{\min}L(w,b,x,y)=\frac{1}{2}||w||^2+C\sum_{i=1}^N\xi_i w,bminL(w,b,x,y)=21∣∣w∣∣2+Ci=1∑Nξi使得:
y i ( w ⋅ x i + b ) ⩾ 1 − ξ i y_i(w·x_i+b)\geqslant1-\xi_i yi(w⋅xi+b)⩾1−ξi其中: ξ i ⩾ 0 \xi_i\geqslant0 ξi⩾0。那么原始问题的拉格朗日函数可以表达为(这里的 α \alpha α不是学习率):
L ( w , b , ξ , α , β ) = 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 N ξ i − ∑ i = 1 N α i [ y i ( w ⋅ x i + b ) − 1 + ξ i ] − ∑ i = 1 N β i ξ i L(w,b,\xi,\alpha,\beta)=\frac{1}{2}||w||^2+C\sum_{i=1}^N\xi_i-\sum_{i=1}^N\alpha_i[y_i(w·x_i+b)-1+\xi_i]-\sum_{i=1}^N\beta_i\xi_i L(w,b,ξ,α,β)=21∣∣w∣∣2+Ci=1∑Nξi−i=1∑Nαi[yi(w⋅xi+b)−1+ξi]−i=1∑Nβiξi为求解L的极小值,需要对 α , β , ξ \alpha,\beta,\xi α,β,ξ求偏倒,并令为0。就有:
∇ w L = w − ∑ i = 1 N α i y i x i = 0 ∇ b L = − ∑ i = 1 N α i y i = 0 ∇ ξ i L = C − α i − β i \nabla_wL=w-\sum_{i=1}^N\alpha_iy_ix_i=0\\\nabla_bL=-\sum_{i=1}^N\alpha_iy_i=0\\\nabla_{\xi_i}L=C-\alpha_i-\beta_i ∇wL=w−i=1∑Nαiyixi=0∇bL=−i=1∑Nαiyi=0∇ξiL=C−αi−βi解得:
w = ∑ i = 1 N α i y i x i ∑ i = 1 N α i y i = 0 w=\sum_{i=1}^N\alpha_iy_ix_i\\\sum_{i=1}^N\alpha_iy_i=0 w=i=1∑Nαiyixii=1∑Nαiyi=0以及对 j = 1 , . . . , N j=1,...,N j=1,...,N都有:
α i + β i = C \alpha_i+\beta_i=C αi+βi=C带入计算可以得到拉格朗日函数为:
L ( w , b , ξ , α , β ) = − 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i ⋅ x j ) + ∑ i = 1 N α i L(w,b,\xi,\alpha,\beta)=-\frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_j(x_i·x_j)+\sum_{i=1}^N\alpha_i L(w,b,ξ,α,β)=−21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)+i=1∑Nαi所以原始函数的对偶问题就是求上式的最大值:
m a x α ( − 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i ⋅ x j ) + ∑ i = 1 N α i ) \underset{\alpha}{max}(-\frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_j(x_i·x_j)+\sum_{i=1}^N\alpha_i) αmax(−21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)+i=1∑Nαi)约束条件为
∑ i = 1 N α i y i = 0 \sum_{i=1}^N\alpha_iy_i=0 i=1∑Nαiyi=0以及对 j = 1 , . . . , N j=1,...,N j=1,...,N都有:
α i ⩾ 0 β i ⩾ 0 α i + β i = C \alpha_i\geqslant0\\\beta_i\geqslant0\\\alpha_i+\beta_i=C αi⩾0βi⩾0αi+βi=C由于和是常数,所以上述约束条件可以简化为:
0 ⩽ α i ⩽ C 0\leqslant\alpha_i\leqslant C 0⩽αi⩽C假设对偶形式的解为: α ∗ = ( α 1 , . . . , α N ) T \alpha^*=(\alpha_1,...,\alpha_N)^T α∗=(α1,...,αN)T,那么:
w ∗ = ∑ i = 1 N α i ∗ y i x i b ∗ = y j − ∑ i = 1 N α i ∗ y i ( x i ⋅ x j ) w^*=\sum_{i=1}^N\alpha^*_iy_ix_i\\b^*=y_j-\sum_{i=1}^N\alpha^*_iy_i(x_i·x_j) w∗=i=1∑Nαi∗yixib∗=yj−i=1∑Nαi∗yi(xi⋅xj)其中 b ∗ b^* b∗中出现的 j j j是满足 0 ⩽ α i ⩽ C 0\leqslant\alpha_i\leqslant C 0⩽αi⩽C的下标。