深入理解C语言
大型源代码里面经常出现一些晦涩的C语言及其规则。
本贴着重记录这些代码以及支撑代码运行的C语言神奇用法。
搞懂这些C语言面试就是无敌开挂模式了
牛人讲解的C语言为啥难。
语言的歧义
C语言的谜题
谁说C语言很简单?
C 语言中的指针和内存泄漏
C 语言中的指针和内存泄漏
这篇文章简单讲解了关于动态内存的东西,这些东西一般在大型程序里面都是必须十分注意的问题。
选择整数数据类型大小
C99仅仅规定了,char至少1字节,int和short int至少2字节long int至少4字节。一些系统上面通常允许字节数超过上面规定的最小字节数。如果因为某种原因需要声明一个精确大小变量并且具有可移植性,应该使用typedef定义类型,系统变了,字节数变了,仅仅只需要修改typedef类型定义即可方便。
typedef和#define
typedef位数据类型创建别名,而不是创建新的数据类型,这是宣称这个名字是指定的类型的同义词。
typedef是一种彻底的封装类型,宏定义仅仅是文本替换
///////////////////////////////////////////////////////////
typedef char* String_t;
#define String_d char *
String_t s1 , s2;
String_d s3 , s4;
//s1 s2 s3是指针,s4是char类型。
typedef struct{
char *item;
NODEPTR next;
}*NODEPTR;
//上述这种定义报错,因为声明next在typedef之前处理了。应该修改成下面这种。
typedef strcut node{
char *item;
struct node *next;
}*NODEPTR;//修改1
strcut node{
char *item;
struct node *next;
}
typedef struct node *NODEPTR;//修改2
///////////////////////////////////////////////////////////
typedef void (*func)(int);
void (*signal(int sig , void (*func)(int) ))(int);
func signal(int sig , func f);//通过tpyedef简化signal函数
#define peach int
#define int_ptr int *
typedef int banana;
typedef char * char_ptr;
unsigned peach i ;//正确
unsigned banana i ;//错误,typedef是整体类型了
int_ptr a , b;//声明a指针和b int类型
char_ptr a , b;//声明a指针和b 指针,因为typedef是类型别名,已经是类型了。
/*
不要为了方便在结构使用typedef,这样仅仅帮助你省略了关键字而已,而没有提示功能了,在大量代码中,应该使用关键字给别人以提示功能。
typedef应该使用在:
1、数组,结构,指针以及函数的组合类型。
2、为了可移植的数据类型。方便将代码移植到不同平台,仅仅修改typedef定义即可。
3、为强制类型转换提供简单的名字。
4、结构中尽量使用结构标签,让代码更加清晰。
*/
//////////////////////////////////////////////////////////
//定义两个相互引用结构
struct a;//空声明告诉编译器下面有定义
struct b;//空声明告诉编译下面有定义
typedef struct a *APTR;
typedef struct b *BPTR;
struct a{
int afiled;
BPTR bpointer;
}
struct b{
int bfiled;
BPTR apointer;
}
//////////////////////////////////////////////////////////
//////////////////////////////////////////////////////////
tpyedef int (*funcptr)();//定义一个新的类型,可以声明函数指针。表示指向返回值是int类型,没有参数的函数。
funcptr fp1 , fp2;//两个函数指针
//等效于
int (*fp1)() , (*fp2)();//这是晦涩写法
//////////////////////////////////////////////////////////
const
const修饰的变量是不可以改变的,所以定义该变量时候初始化是使该变量具有值的唯一机会。
使用const几点作用:
- 向阅读代码的人传递有用的信息,告诉用户这个参数应用目的,不必担心指针指向的内容被此函数修改
- 合理使用const可以使编译器很自然地区保护那些不希望被改变的参数,防止被意外更改,减少bug出现。假如程序很大,万行代码,那么这种有用的声明就起到了作用。正确使用const关键字是一个良好的编程习惯,对于调试可以节省大量时间和精力。
const char *p;
char const *p;
char *const p;
//上面三个区别一些复杂声明
超级复杂的声明在实际应用中需求很少,这里暂时先放着,以后实际工作中遇到了,需要理解,那么就再记录.通过typedef可以解决晦涩难懂类型。
//定义一个返回函数指针的函数指针。
typedef int (*funcptr)();//定义函数指针类型
typedef funcptr (*ptrfuncptr)();//定义一个返回值是函数指针的函数指针新类型。
//等效与
int (*(*ptrfuncptr)()) ();变量初始化问题
静态变量和全局变量未初始化,编译器自动初始化为0.非静态的局部变量则里面存储垃圾数据。malloc和remalloc分配的里面也是垃圾数据,对于垃圾数据不能做任何假设。callock自动初始化为0.
char a[] = "myname";//数组
char *b = "myname";//const 指针,不能修改指向的内容,不能用于strcopy结构、联合、枚举
结构
struct name{
int namelen;//存储名字长度
char namestr[1];//存储名字字符串,可使长度和名字处于同一内存块
};
struct name *makename(char *name)
{
//这种做法可以是的名字和字符串长度存储在一块连续的存储区,但是并不是C语言标准
struct name *ret = (struct name *)malloc(sizeof(struct name)-1 + strlen(name) +1);
if(ret != NULL){
ret->namelen = strlen(name);
strcpy(ret->namestr , name);
}
return ret;
}
int main(void)
{
struct name *myname;
myname = makename("wangjun");
printf("name is %s , len is %d\n" , myname->namestr , myname->namelen);
exit(0);
}这种技术十分普遍,将长度和字符串保存在同一块内存中。实际上这里是将数组当作了指针来使用。但是不可靠,可靠的是使用字符指针。
#include 用字符串指针,这是一种更加通用的方法,但是这里在堆中动态分配了两块内存。释放的时候,需要利用两次free。为了保持内存的连续性,也可以仅仅分配一块,如下面部分。
#include 这种做法,使得一次malloc调用将两个区域拼接在一起,但是这里只有当第二个区域是char型的时候才可以移植。对于任何大一些的类型,对齐问题变得十分重要。这些“亲密”结构都必须十分小心的使用。因为只有程序员知道它们的大小,而编译器一无所知。
- 函数传入和传出大结构可能会代价很大(通常就是将整个结构都推进栈,需要多少空间,就占用多少空间),因此当不需要进行值传递的时候,我们必须考虑通过传递指针代替,减少访问的开销。
- 因为涉及内存对齐的问题,所以并不能用==或者!=比较结构类型。填充空洞不一样,不能进行比较。
- 向接收结构的参数传入常量值,建立无名结构数值
plotpoint( (struct point){.x = 1 , .y = 2} );//这种方式省略了初始化一个临时变量
void plot(struct point x)
{
printf("%d , %d\n" , x.x , x.y);
}
int main(void)
{
struct name *myname;
myname = makename("wangjun");
printf("name is %s , len is %d\n" , myname->namep , myname->namelen);
plot( (struct point){.x =2 , .y = 3} );
exit(0);
}结构体对齐的问题(C primer Plus)
确定结构体域中字节偏移量以及通过名字访问结构体中的域(设计内存对齐)
联合和枚举
联合本质上是一个一个成员相互重叠的结构,某一时刻只能使用一个成员。也可以从一个成员写入,然后从另外一个成员读出。联合大小是最大成员的大小。
枚举的存在完成是为了代码可读性。变量自动赋值,服从数据块作用域,使用之后代码可读性增强。
位域
数字表示该域中用位计量的准确大小。
单独操作变量中的位,例如设备寄存器不同位对应者不同的功能,文件相关的操作系统信息一般通过特定的位表明特定的选项。
- 掩码
#define MASK = (0x01>> 2)
//通过掩码打开某些位,关闭某些位
flags &= (~MASK);//清除第2位
flags |= (MASK);//设置第2位
//通过掩码切换某些位
flag ^= MASK;//将第二位翻转,为1的将翻转
//检查位的值
if( (flag & MASK) == MASK)//证明功能已经被设置
{
}
//移位,产生一个新的位值,但是不改变运算对象。- 位字段
表达式
对于复杂表达式中各个子表达式的求值顺序,编译器有相对自由选择的权利,这和操作符的优先级和结合性没有关系。如果某个变量同时受到多个副作用的影响,这种情况下的行为是未定义的。
a[i] = i++;//副作用,修改i的数值。导致a[i]引用不知道引用i++还是i。这种行为未定义。
printf("%d\n" , i++ * i++);//同样未定义,编译器并不知道选择旧值还是选择新值,出现多个副作用。
/*
括号作用:仅仅告诉哪个操作数和哪个操作数结合,并没有要求编译器先对括号内的表达式求值。
*/
f() + (g()*h());//这里并不能确定哪个优先调用,编译器会随机选择调用顺序。
(i++)*(i++);//这里结果同样是未定义的。
/*
逗号表达式,&&和||可以确保左边的表达式决定了最终结果,那么右边的子表达式不会计算,因此从左边都右边的计算可以保证。
*/
if(d != 0 && n/d > 0)
{
;//可以确保n/d是有定义,否则跳过,放置系统崩溃。
}
if(p == NULL || *p == '\0')
{
;//可以确保p是有定义指针,否则跳过,防止系统崩溃。
}
//i++和++i的唯一区别在于它们向包含它们的表达式传出的值不同,一个传原来副本,一个传最新的值。c++优先使用++i因为更加符合人们思想。
if(a//a
if(a < b && b < c);
double degc , degf;
degc = 5/9*(degf - 32);//必定等于0,因为5/9=0,修改
degc = 5.0/9*(degf - 32);//degc = (double)5/9*(degf - 32);才正确 指针
指针是C语言最强大和最流行的功能之一。但是指向不应该指的位置,后患无穷。那么问题来了,指针到底有什么好处呢?
- 实现动态分配数组,利用malloc分配空间,通过指针访问,这条使用过。
- 对多个相似变量的一般性访问。
- (模拟)按照引用传递函数参数(后续继续理解,这里不明白)
- 各种动态分配的数据结构,尤其是树和链表
- 遍历数组,利用许多处理字符串的库函数,strcpy ,memset等,都是通过指针。
- 高效复制数组和结构,作为函数参数,传入指针,然后直接访问内存,避免了数据结构在堆中完全拷贝。
*p++ = 22;//这种语句使用巨多,将当前位置赋值,并指向下一个位置。
int array[5] , i , *p;
p = array;
printf("%d" , *(p + 3*sizeof(int)) );
//这里指针必定溢出,因为指针加数字相当于加上数字乘以指针所指类型大小
//上述可能是array[6]或者array[12].这是老生常谈的问题,很简单
char *p;
p = p + sizeof(int);//跳过一个int类型
p = (char *)( (int *)p + 1 );//将p升级为int,然后加1跳过一个int,然后转换回来。这种做法可行,但是非常丑陋,并不提倡。
////////////////////////////////////////////////////////
//模拟引用传递参数
void f(int *ip)
{
static int d = 5;
ip = &d;
}
int *p;
f(p);
//这里发现拍并没有变化,因为参数都是值传递副本进去,
//要想改变一个东西,必须传递它的指针进去,然后通过指针修改指向的内容而已,或者通过参数返回。
//我们一般需要修改传入的多个形参里面的内容,一般是传递其对应的指针进去,然后通过指针直接访问内存,修改传入参数里面的内容。或者返回,但是返回仅仅只能返回一个数值。
//这里如果要修改传入的指针,那么必须传入指针的指针或者返回,如下:
void f(int **ip)
{
static int d = 5;
*ip = &d;
}
int *p;
f(&p);//这样就可以正确了
int *f(void)
{
static int d = 5;
return (&d);
}
int *ip = f();//这里返回也是正确的
////////////////////////////////////////////////////////////////
int r , (*fp)() , func();
fp = func;
r = fp();
r = (*fp)();//上面两种指针函数调用完全等效。空指针
C语言定义空指针,可以确保这个指针不会指向任何一个对象或函数。空指针不同于未初始化的指针。空指针可以确保不指向任何对象或函数,而未初始化的指针则可以指向任何地方。
在C语言中空指针NULL和空指针常量0一样的效果。
//编译器会进行如下修复,
if(expr) 等效于 if( (expr) != 0 )
if(!p)等效于if(p == 0)或者if( (expr)?0:1 )
//尽量少些缩写的方法,为了让别人看清楚,尽量将条件写清楚。;数组和指针
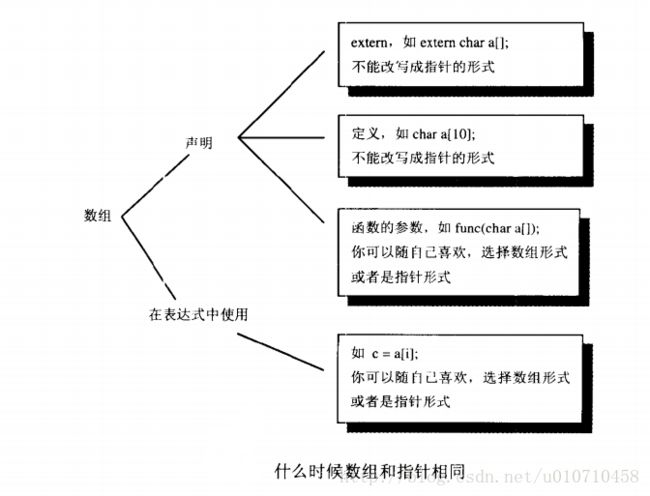
- 数组和指针的统一性是C语言长处之一,用指针可以很方便地访问数组和模拟动态分配的数组。只能说数组名和指针等价,可以通过指针访问数组里面的元素而已。可不能说它们一样。数组是一个由同一类型的连续元素组成的预先分配的内存块。指针是一个变量可以对任何位置数据元素进行引用而已。数组下标访问是属于指针定义的。
/*
数组并非指针,数组定义绝对不是指针的外部声明。定义只可以出现一次用于确定对象的类型并分配内存,用于创建新的对象;声明可以出现多次,用于描述对象类型,指示对象在其他地方创建的。
exten声明告诉编译器对象的类型和名字,对象的内存分配则在别处进行。由于并
未在声明中为数组分配内存,所以并不需要提供关于数组长度的信息。对于多维数组,需要提供除最左边一维之外其他维的长度-这就给编译器足够的信息产生相应的代码。
*/
char a[6];
extern char *a;//这种声明上面的a不正确,因为a是数组6个区域,而这个声明是字符指针,效果不一样。修改为 extern char a[];
编译器看到a[3]的时候直接访问数据,它生成的代码从a位置开始跳过3个,然后取出指向的字符。而对于p[3]的时候间接访问数据,先找到p的位置取出其中指针值,然后在指针后面加3,取出其中的字符。数组和指针一旦在表达式中出现就会按照不同的方法计算,但是二者可以达到一样的效果。二者实现效果相同,但是实现的方式非常不一样。
//数组名不能赋值。
extern char *getpass();
char str[10];
str = getpass();//数组是二等公民,不能向他赋值。当需要从一个数组向另一个数组复制所有内容的时候。对于char型数组,strcpy , 如果不想复制数组且希望传递,那么直接指针搞起。
/*
字符串常量放在只读数据段,将其地址返回给p。
p不可以修改文本,只读而已。
定义指针,编译器并不为指针所指向的对象分配空间,
仅仅给指针本身分配空间而已,除非定义指针的同时通过字符串常量进行初始化。
*/
char *p = "abdcfdfd";//"abdcfdfd"一般放在只读数据段,不可通过p修改。
char a[] = "abdcfdfd";//"abdcfdfd"初始化被分配内存,可通过a修改。
int a[10];
/*
a的引用类型是“int型的指针”。&a是“10个int的数组的指针”
*/
int b[2][5];
/*
b的引用类型是“5个int型数组的指针”。&b是“2个5个int的数组的数组的指针”。
*/
/*
区别指向数组的指针和指向数组某个元素的指针。通常并不需要声明数组的指针。
真正的数组指针,在使用下标或增量操作符的时候,会跳过整个数组,通常在操作数组的数组有用(二维数组)。
*/二维数组的一些理解:
二维数组也叫做数组的数组,相当于一维数组里面的元素是一个数组。这样就很好理解了。例如int a[2][3],那么a[0]和a[1]就相当于对应的数组名。而a就是指向数组的指针,也就是指针的指针。再数值上a[0]和a相等,但是他们类型不一样,a[0]是指向int的指针而a是指向3维数组的指针。所以要引用a的时候,必须声明类型相匹配的指针变量。下面展示了一些用法。
#include 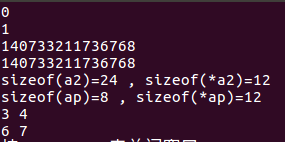
输出结果和上面描述一致。
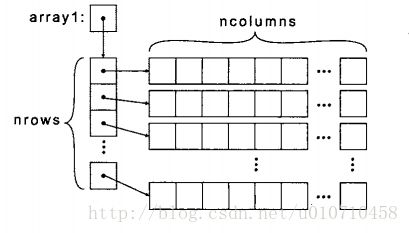
动态分配多维数组
二维数组动态分配两步走:先分配空间存储指针数组,然后把每个指针初始化为动态分配的行。
//int **array1 和int (*array1)[ncolumns]类似
#include int *)malloc(ncolumns * sizeof(int));//分配ncolumns个连续存储int数据的空间,并返回首地址,指针。
}//这样就动态分配了二维数组,可以用过array1[i][j]进行访问了。
array1[0][0] = 1;
array1[0][1] = 2;
array1[0][2] = 3;
array1[1][0] = 4;
array1[1][1] = 5;
array1[1][2] = 6;
/*
可以通过二维数组一样索引存储区域.
这是由编译器决定的,编译之后全部替换成指针引用区域
*/
for(i = 0 ; ifree(array1[i]);//释放指针
}
free(array1);//释放指针的指针
printf("%d\n" , array1[1][2]);
//释放之后,对应区域还是可以访问,数据可能并没有清空,释放仅仅标记这个区域块可以重新被分配给其他对象。这就是虚拟内存达到的效果。
//内存释放,表示这部分区域可以重新分配给其他对象,
//但是不代表将以前的数据清0(具体实现依靠操作系统),所以这里还可以继续访问到这个区域的数据
//因此,使用动态分配最好清0,不然数据是多少不确定,使用malloc,然后memset。
return 0;
} 

这里的访问数据,可能是6可能是其他,由具体的操作系统决定,释放后内存数据是否清空。
一些关键性得例子
一维数组和指针:
int main(void)
{
//注意p+1相当于指向下一个同类型,地址为p + sizeof(type)*1;
int a[] = {0 ,1 , 2 , 3 , 4};
int i , *p;
for(i = 0 ; i < 5 ; i++){
printf("%d " , a[i]);//a[i]访问 0 1 2 3 4
}
printf("\n");
for(p = &a[0] ; p <= &a[4] ; p++){
printf("%d " , *p);//访问地址 0 1 2 3 4
}
printf("\n");
for(p = &a[0] , i = 1 ; i <= 5 ; i++){
printf("%d " , p[i]);//注意p[5]是未定义的数据,因为越界访问数组了 1 2 3 4 ?(随机)
}
printf("\n");
for(p = a , i = 0 ; p+i <= a + 4 ; p++ , i++){
printf("%d " , p[i]);//p[i] = *(p+i)这是编译器做的事情 0 2 4
}
printf("\n");
for(p = a + 4 ; p >= a ; p--){
printf("%d " , *p);//p[i] = *(p+i)这是编译器做的事情 4 3 2 1 0
}
printf("\n");
for(p = a + 4 , i = 0 ; i <= 4 ; i++){
printf("%d " , p[-i]);//p[-i] = *(p-i)这是编译器做的事情 4 3 2 1 0
}
printf("\n");
for(p = a + 4 ; p >= a ; p--){
printf("%d " , a[p-a]);//p-a的数值等于((long)p-(long)a)/sizeof(int) = 跨越个数,
//这也是编译器做的,因为p指向int类型,所以都是以sizeof(int)为单位 4 3 2 1 0
}
printf("\n");
exit(0);
}
sizeof问题
sizeof在编译器期间起到作用。
int a[2][2];
int *b;
//sizeof(a) = 2 * 2 * 4 =16 数组所占用字节数
//sizeof(b) = 4 指针变量所占用字节数指针数组和指针:
int main(void)
{
int a[] = {0 ,1 , 2 , 3 , 4};//这种定义形式,让编译器决定数组维度,经常使用。
int *p[] = {a , a+1 , a+2 , a+3 , a+4};
/*根据优先级及结合性可以这样理解,
int * (p[]),首先p是数组,数组里面元素是int *类型。所以是指针数组。
*/
int **pp = p;//通过2级指针,引用一个地方
/*根据优先级及结合性可以这样理解,
int * (*pp),首先pp是指针,指针里面元素是int *类型。所以是pp是指针的指针,
刚刚p也是数组名,也是指针,数组里面元素也是指针,所以p也是指针的指针,刚刚和pp类型一样
可以相互赋值。
*/
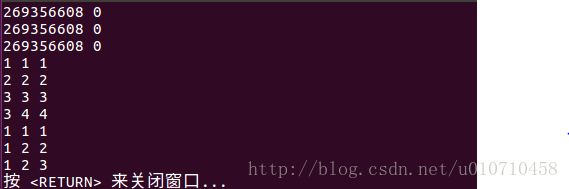
//内存分布如示意图1:
printf("%d %d\n" , a , *a); //&a[0] , 0
printf("%d %d\n" , *p , **p); //&a[0] , 0
printf("%d %d\n" , *pp , **pp);//&a[0] , 0
//内存分布如示意图2:
pp++;//指向下一个int *
printf("%d %d %d\n" ,pp-p , *pp - a , **pp);//1 1 1
*pp++;//再指向下一个int *
printf("%d %d %d\n" ,pp-p , *pp - a , **pp);//2 2 2
*++pp;//继续指向下一个int *
printf("%d %d %d\n" ,pp-p , *pp - a , **pp);//3 3 3
++*pp;//还是指向第三个int *
printf("%d %d %d\n" ,pp-p , *pp - a , **pp);//3 4 4
//内存分布如示意图3:
pp= p;
**pp++;//
printf("%d %d %d\n" ,pp-p , *pp - a , **pp);//1 1 1
*++*pp;//
printf("%d %d %d\n" ,pp-p , *pp - a , **pp);//1 2 2
++**pp;//
printf("%d %d %d\n" ,pp-p , *pp - a , **pp);//1 2 3
}
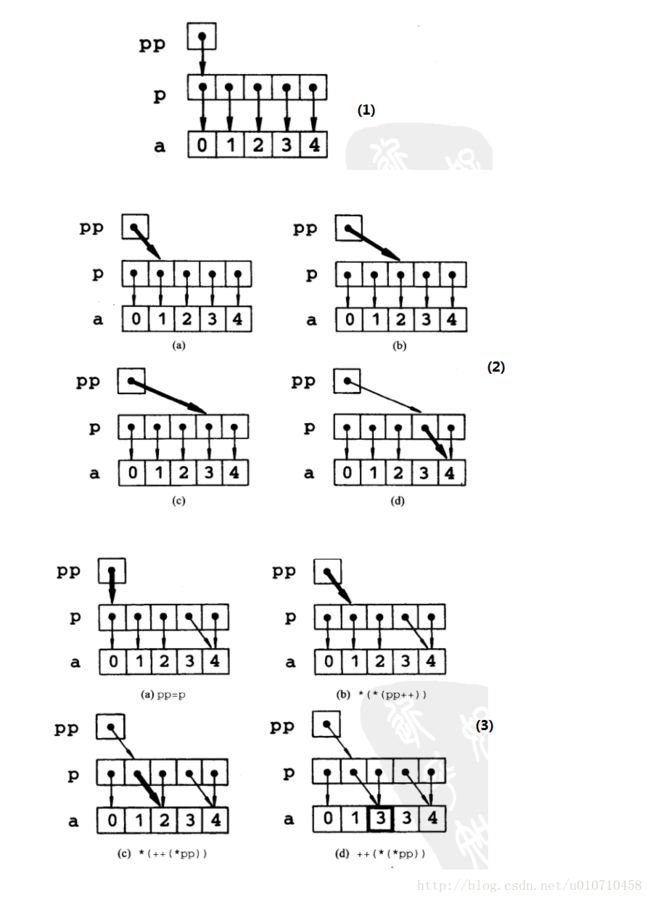
有了这个图片,那么一切都很清晰明了。
多维数组和指针:
内存分配
指针通过比较难学习,但是更加难的在于管理指针指向的内存块。很容易造成内层泄漏的问题。这种BUG最难找出问题。
char *i;
gets(i);
printf("%s" , i);
//代码希望gets的东西,存储在i执行的区域,因为i未初始化,所以这是一个错误使用。必须初始化i指针。相当于int i没有初始化一样。先要指向一片区域,然后通过gets填写指向的区域。如果不初始化指针,那么它不知道把东西搬到哪个内存区域。就算没有malloc也必须确保要使用的内存正确分配。
//上述可以修改成数组,让编译器操心内存分配
char i[100];
gets(i);
printf("%s" , i);
//strcat
char *s1 = "wang";
char *s2 = "jun";
char *s3 = strcat(s1,s2);//肯定不能得到正确的结果。
/*
字符拼接,s1中必须有足够的存储空间,容纳s1和s2指向的字符。程序员必须分配足够的空间,可以通过声明数组或者malloc完成。字符串字面量是不可以修改的。可以通过修改s1为数组
char s1[20] = "wang,";
char *s2 = "jun";
strcat(s1,s2);//这种方法就可以搞定了
*/
char *p;
strcpy(p , "abc");//这种必定错误使用,p没有初始化,那么abc将放到哪里?
char *p;
//这中声明仅仅分配了容纳存储指针本身的内存,也就是sizeof(char *)个字节内存。单没有分配指针指向任何内存(指针没有初始化)。全部可以统一到内存块上面想象。都是放在内存块上面的,指针也放在内存块,只是系统规定这个存放指针的内存块当作地址来解析处理。
//函数返回指针,必须确保指向的内存已经正确分配。
//指针必须静态分配或者调用者传入缓冲区,或者malloc分配。
char *itoa(int n)
{
char retbuf[20];
sprintf(retbuf , "%d" , n);
return retbuf;
}//这个函数绝对错误,因为retbuf是局部变量,函数调用内存分配在栈,函数退出自动释放,所以返回的指针是无效的,因为指向一个已经不存在的数组了。
char *itoa(int n)
{
static char retbuf[20];
sprintf(retbuf , "%d" , n);
return retbuf;
}//修改版本1,通过静态未初始化,存储在BSS段,程序结束之前retbuf一直存在,但是一直指向同一个区域,所以调用者不能多次调用这个函数并同时保存所有返回值。
char *itoa(int n , char *retbuf)
{
sprintf(retbuf , "%d" , n);
return retbuf;
}//修改版本2,可以同时保存所有值,因为传入了保存的空间
char str[20];
itoa(124 , str);
char *itoa(int n)
{
char *retbuf = (char *)malloc(20);
sprintf(retbuf , "%d" , n);
return retbuf;
}//通过malloc从堆(就是虚拟内存上面的一块区域而已,没啥特别之处)分配空间,并返回,但是在不使用的时候,记得释放,否则内存泄漏成为可能。
//malloc分配返回值强制转换类型的问题:标准C不建议转换,但是C++必须进行显示转换,为了C/C++兼容,所以最后转换。
//malloc十分脆弱,因为它们直接在它们返回的内存旁边存储至关重要的内部信息片段,这些信息很容易被指针破坏。(分配大小为0对象,写入比所分配还多的数据,malloc(strlen(s))而不是malloc(strlen(s) + 1 等等)
//free如何知道要释放的大小?
//通常在malloc之后,大小会记录在内存块旁边,这就是为什么越界访问会导致内存泄漏的问题,所以对超出分配内存块边界的内存哪怕是轻微的改写,也会导致严重的后果。字符和字符串
C语言没有内建的字符串类型,都是以’0’结尾的字符数组表示字符串。这一点是字符串操作最重要的一点。
char *mystrcat(char *s1 , const char *s2)
{
char *s;//暂存进行拷贝作用
for(s = s1;*s != '\0';++s)
;//s指向s1的结尾
for( ; (*s = *s2) != '\0' ; ++s , ++s2)
;//将s2拷贝到s1末尾,直到遇到s2的结束符
return(s1);//可以不测试返回值
}
strcat(string , '!');//错误,因为后面不是字符串常量,没有结束符号,拼接会出问题的,错误内存访问很可能发生。
char a[] = "wangjun";
char *p = "wangnjun";//二者区别巨大,前一个字符数组,后声明一个字符指针,指向一个字符串常量。并且p指向的内容不能更改,想当与const char *p;C预处理器
预处理器是在正式解析和编译之前的工作,最开始进行预处理操作。
这里对宏定义解析比较清晰
/*书写多语句宏的最好方法,这样对于if里面使用宏定义,可以加分号也可以不加分号。
如果要使用宏定义来定义多条语句时,采用do { … } while (0) 的形式是一种较好的方法。空的宏定义避免warning;存在一个独立的block中,可以用来进行变量定义作用域是块,因此可以实现比较复杂的功能;如果出现在判断语句过后的宏,这样可以保证作为一个整体来是实现。
对于宏定义后面加分号和不加分号,都可以正常运行。
*/
#define MACRO(arg1 , arg2) do{ \
stmt1; \
stmt2; \
//.... \
}while(0)
#define FUNC(argc1 , argc2) (expr1 , expr2 , expr3)
//expr*多条语句执行,并且返回expr3的数值给外部赋值语句。
/*放入h里面的东西
宏定义;
结构、联合和枚举声明;
typedef声明;
外部函数声明;
全局变量声明;
*/
/*
当前目录:Unix下,为包含#include指令文件所在的目录。
标准位置:编译之前人为添加的目录,编译器下可以使用环境变量或者命令行参数的方法向标准位置的搜索列表增加其他目录。如Kile/CCS里面配置增加目录方法。
< >首先在一个或多个标准位置搜索,通常保留给系统定义的头文件。
" "首先当前目录搜索,然后在标准位置搜索。
*/
//可变参数宏以及调用辅助宏定义 后面使用了之后,再次发觉效果作用。ANSI C标准
const int n = 5;
int a[5];//数组维度,case行标必须用真正常量,可以使用#define,而n也是变量,只是限制为只读而已。
const char *p;
char const *p;
char * const p;
//前面两个等效,都是指向字符常量的指针,也就是p值可以更改,但是p所指对象不可更改。
//后一个是指向可变字符的指针常量。也就是p值不可更改,但是p所指对象可以更改。
typedef char *charp;
const charp p;
//p被声明为const。因为typedef不完全基于文本替换。
//这里类似与const int i将i声明为const原因一样。
//因为charp已经是一个类型的别名了,这点和define差别很大。
#define Str(x) #x
char *name = Str(plus);//name = "plus"将参数扩展然后字符串化操作。##进行连接两个宏值,具体可以参见宏定义声明。
//为什么不能对void *指针进行算术运算?
//因为编译器不知道所指对象大小,不能清晰的进行汇编步骤处理。标准输入输出库
printf格式输出对应类型


printf(“%*d” , width , x);//实现可变域宽度的printf。
未完待续,以后继续查看。
库函数
操作符优先级及求值顺序差别
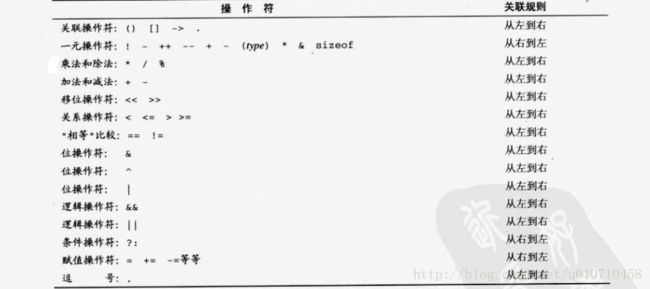
优先级决定操作符和操作数绑定顺序。操作符按照优先级从高到低的顺序与操作符进行绑定。先在表达式里面找出操作符,优先级高的先绑定,加入操作符优先级相同,就按照关联规则处理。如果关联规则从左向右,那么表达式更接近左边的操作符将有着更高的优先级,否则相反。
重要的几点:
0、一元操作符优先级仅仅低于前述运算符,具有很高的优先级。
1、6个关系运算符优先级高于逻辑运算符。if(a >b && c >d)这种表达合理。
2、6个关系运算符里面==和!=低于其他关系运算符号,if(a < b == c < d)比较a与b的相对大小顺序是否和c与d相对大小顺序一样,这种写法合理。b = a>10 && c<5 ? 1:2;这种写法同样合理。
3、*p++,优先级相同,编译器解释成*(p++)取出p所指对象然后p自增。
4、赋值运算符优先级较低,注意这种写法if( (c = func()) != 12);求值顺序代表对操作数进行求值的顺序,和优先级是完全不一样的规则。
优先级将 a+b*c解释成a + (b * c),当并没有保证a 和 b*c的求值顺序。一般来说编译器随机决定求值顺序。
1、C语言中只有四个运算符(&&、||、?:、,)。存在规定的求值顺序。&&和||先进行左侧求值,需要时候进行右侧。a?b:c中,操作数a先求值,根据a在求b或者c。逗号运算符,首先左侧操作数求值,然后丢弃该值,再对右侧操作数求值,其他求值顺序未定义。
x = 5;
z = x / ++x;//先求x,z = 5/6 = 0;先求x++,z = 6/6 = 1。
/*z结果未定义,编译器将表达式解释成 z = ( x / (++x) ),但是x或者++x求值顺序不确定,假如++x先求值(因为是++x所以求值返回结果是6)然后取出x,那么x=6。那就是z = 1。假如x先求值,那么x=5,然后++x = 6,那就是z = 0;
*/
z = x / x++;//先求x,z = 5/5 = 1;先求x++,z = 6/5 = 1。
y[i++] = x[i];//综上所述,结果同意未定义,出现很大的错误。
y[i++] = x[i];//综上所述,结果同意未定义,出现很大的错误。
x++;//规定x++返回值是x原来值,然后x+1。
++x;//规定++x返回值是x+1后的值,然后x+1。
x = 2;
y = x + x++ +2;//这种结果未定义,因为求值顺序不确定
//先求x,y = 2 + 2 + 2 = 6;先求x++,y = 3 + 2 + 2 = 7; 综上所述,清楚了解操作符优先级及求值顺序的规则非常重要。
链接
to be continue
运行时的数据结构
搞懂C函数过程调用很重要
内存分配和段定义很重要
再论数组和指针
1、数组和指针相等情况:
2、作为函数参数的数组名等同于指针,仅仅将数组地址复制给子函数(在子函数里面表现为指针),然后子函数通过指针引用实参。数组参数的地址和数组参数的第一个元素的地址不一样,并且sizeof形参和sizeof实参也不一样。
#include 
addr of global array = 0x601034
sizeof(ga) = 9
addr (ga[0]) = 0x601034
addr (ga[1]) = 0x601035
addr of array param = 0xb695afc8
sizeof(ca) = 8
addr (ca[0]) = 0x601034
addr (ca[1]) = 0x601035
++ca = 0x601035
addr of ptr param = 0xb695afc8
sizeof(pa) = 8
addr (pa[0]) = 0x601034
addr (pa[1]) = 0x601035
++pa = 0x601035
3、分解多维数组
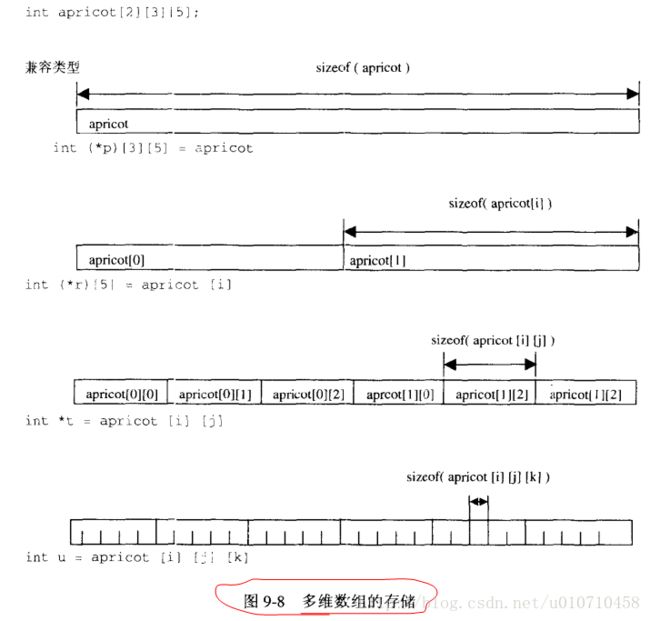
r++,t++将会各自指向它们下一个元素,增加的步长不一样。之所以有这么多类型,就是为了指导编译器在编译器期间,如何在内存上面取值。不同类型,取值增加的步长不一样。这就是所谓的规则,理解这些规则之后,分析代码,写代码就更加沉着稳定安心。因为理解了编译器的工作行为。
4、数组的数组和指针数组的寻址:理解这个过程有点作用。

5、数组形参被编译器如何修改

注意数组指针是行指针,也就是二维数组名是行指针类型,和指针的指针不一样。
OOP
类
面向对象的关键就是把一些数据和对这些数据进行操作的代码组合在一起,并用某种时髦手法将它们做成一个单元。许多编程语言把这种类型的单元称为 ”class (类)“。类是一种用户定义类型,就好像是int这样的内置类型一样。内置类型己经有了一套完善的外对它的操作(如算术运算等) ,类机制也必须允许程序员规定他所定义的类能够进行的操作。类里面的任何东西被称为类的成员。
类经常被实现的形式是:一个包含多个数据的结构,加上对这些数据进行操作的函数的指针。编译器施行强类型一一确保这些函数只会被该类的对象调用,而且该类的对象无法调用除它们之外的其他函数。上面是一种定义,而这是定义对应的实现形式,和C语言里面函数指针类似。
/*
类定义类似结构体。
1、访问控制:
public:类外部可见,可以被按需设置调用操纵。数据应该私 有,这才符合OOP,函数应该是公用的,使得外部可用。
protected:只能由类本身函数以及派生类函数使用。
private:只能被类成员使用,对于外部可见(名字已知),但是却不能访问。
friend:每次只能声明一个变量。后面不要冒号。函数不属于类的成员函数,但可以像成员函数一样访问类的protected和private成员。friend可以是函数也可以是类。
virtual:每次只能声明一个变量。后面不要冒号。
2、声明:就是正常的C语言声明。类中的每个函数声明都需要对应一个实现,实现可以在类里面,也可以在类外面(通常)。
3、this指针,每一个成员函数都被隐式给该函数一个this指针参数指向改对象,允许对象成员函数引用对象本身。
4、构造函数:对象创建隐式被调用,负责对象初始化。很重要,因为外部函数都不能访问private成员,所以很有必要一个特权函数对其初始化。这是一个飞跃,比C语言多了一些优点。构造函数可以多个,通过参数区分。
析构函数:对象被销毁隐式调用,每构造常用,一般用于处理特殊终止要求以及垃圾回收机制。这两个函数机制违反了C语言的哲学-一切工作自己负责的原则。
*/
class 类名{
访问控制:声明
访问控制:声明
};对象
某个类的一个特定变量,就像j可能是int类型的一个变量一样。对象也可以被称作类的实例 (instance)。
封装
把类型、数据和函数组合在一起,组成一个类。在 C 语言中,头文件就是一个作常脆弱的封装实例。它之所以是一个微不足道的封装例子,是因为它的组合形式是纯词法意义上的,编译器并不知道头文件是一个语义单位。
继承
这是一个很大的概念一一允许类从一个更简单的基类中接收数据结构和函数。派生类获得基类的数据和操作,并可以根据需要对它们进行改写,也可以在派生类中增加新的数据和函数成员。在C语言里不存在继承的概念,没有任何东西可以模拟这个特性。
class Fruit
{
public:
peel();
slice();
juice();
privite:
int weight , calories_per_oz;
}
class Apple : public Fruit //从公共Fruit中派生
{
public:
void make_candy_apple(float weight);
}
//区别于嵌套类,狗里面不肯能嵌套哺乳动物,应该是狗继承了哺乳动物的特征。思考自己所面对的情形,选择合适用法。多重继承:用的灰常少,没有哪个例子证明需要用到多重继承。
重载:运行时通过参数类型确定调用哪个函数,作用于不同类型的同一操作具有相同的名字。C语言中浮点数加法,整形加法,这都是+重载例子。C++允许创建新类型,并且赋予+不同的含义。
class Fruit
{
public:
peel();
slice();
juice();
int opetator+(Fruit &f);//提示重载+
privite:
int weight , calories_per_oz;
}
int Fruit::opetator+(Fruit &f)
{
printf("calling ");
return (weight + f.weight);
}
Apple apple;
Fruit orange;
int o = apple + orange;//apple通过this访问,orange通过引用访问。多态:支持相关的对象具有不同的成员函数(但原型相同) ,并允许对象与适当的成员函数进行运行时绑定。C++通过覆盖(override)支持这种机制一一所有的多态成员函数具有相同的名字,由运行时系统判断哪一个最为合适。当使用继承时就要用到这种机制:有时你无法在编译时分辨所拥有的对象到底是基类对象还是派生类对象。这个判断并调用正确的函数的过程被称为”后期绑定(late binding) “。在成员函数前面加上virtual关键字告诉编译器该成员函数是多态的(也就是虚拟函数)。
多态非常有用,因为它意味着可以给类似的东西取相同的名字,运行时系统在几个名字相同的函数中选择了正确的一个进行调用,这就是多态。
class Fruit
{
public:
void peel()//水果类有去皮
{
printf("peeling ");
}
void slice();
void juice();
privite:
int weight , calories_per_oz;
}
class Apple : public Fruit //从公共Fruit中派生苹果类,也有去皮操作,但是可能和水果类去皮方式不同,这就需要多态了,那么可以同名,C++使用覆盖的方法进行处理。这种抽象真是的太牛逼了,将事物高度抽象。
{
public:
void peel()
{
printf("apple peel");
}
void make_candy_apple(float weight);
}
Fruit banana;
banana.peel();//输出peeling,一切正常。
Fruit *p;
p = new Apple;
p->peel();
//输出peeling,为苹果量身定做的peel没有被调用。
/*
为什么会出现上述问题?
当想用派生类的成员函数取代基类的同名函数时,C++要求你必须预先通知编译器;通知的方法就是在可能会被取代的基类成员函数前面加上virtual关键字,需要许多背景知识才能理解这样问题。这才是讲解知识点嘛,外国人写书就是这么牛逼。。。娓娓道来,让人一听就明白,一听就懂。virtual含义:它的意思是不让用户看到事实上存在的东西(基类的成员函数)。换用一个更有意义的关键字(虽然长得不切实际)。在上面Apple peel前面加上virtual就可以正确输出了。
多态如何表现出来?
C++内部实现是通过函数指针向量表和一个指向这个向量的vtbl指针来实现的。
在C++里面为了满足多态、重载等等功能,C++编译器需要进行很多处理,为了在内存上面取指令的形式和这种操作对应起来,需要花费大量的精力考虑算法如何设计才可以满足多态,重载等等取得的功能。所以C++编译器必定比C编译器大的多多的。
*/模版:完全为了对应泛型编程设计,让算法适用于不同的类型。
内联函数:C++里面也有,在调用的地方展开函数,省略了过程调用开销,函数里面内容应该相对较小才可以进行内联处理。
new和delete操作符:new可以自动sizeof对象分配需要多少,malloc不可能必须手动,为什么会出现这种功能,都是编译器设计方便了我们的操作。
传引用:C语言中只有传值调用,C++引入传引用,可以把对象引用作为参数传递。
参考书籍:
《C专家编程》极度推荐,讲解了许多C语言里面的实现细节。
《C陷阱与缺陷》
《C语言解惑》
《你必须知道的495个C语言问题》