本专题的内容结构:
第一部分主要是:面向对象基础
第二部分主要是:面向对象进阶
第一部分的结构:
unit1:面向对象编程模式:
(1),面向对象编程思想
(2),面向对象的三个特征
(3),Python面向对象术语
unit2:Python类的构建:
(1),类的基本构建
(2),类的属性和方法
(3),类的构造函数和析构函数
unit3:实例1:银行ATM等待时间分析
(1),对象的设计和构建
(2),生活现象的程序分析
unit4:Python类的封装
(1),私有属性和公开属性
(2),私有方法和公开方法
(3),保留属性和保留方法
unit5:Python类的继承:
(1),子类,父类与超类
(2),类的方法重载和属性重载
(3),类的多继承
第二部分的结构:
unit1:Python类的运算:
(1),运算符的理解
(2),各类运算符的重载
unit2:Python类的多态:
(1),多态的理解
(2),参数类型的多态
(3),参数形式的多态
unit3:实例2:图像的四则运算
(1),PIL库和Numpy 库实践
(2),图像的加减乘除操作
unit4:Python对象的引用
(1),引用的理解
(2),浅拷贝和深拷贝
unit5:Python类的高级话题:
(1),类的特殊装饰器
(2),命名空间的理解
(3),类的名称修饰
第一部分的内容:
unit1:面向对象编程模式:
(1),万物皆对象:
自然意义上的对象:独立的存在 或 作为目标的事物
>独立性:对象都存在清晰的边界,重点在于划分边界
>功能性:对象都能表现出一些功能,操作或行为
>交互性:对象之间存在交互,如:运算和继承
Python语言的“万物皆对象”:
>Python语言中所有数据类型都是对象,函数是对象,模块是对象
>Python所有类都是继承于最基础类object
>Python语言中数据类型的操作功能都是类方法的体现
(2),面向对象编程思想:
OOP :Object-Oriented Programming
>OOP :面向对象编程,一种编程思想,重点在于高抽象的 复用代码
>OOP 把对象当做程序的基本单元,对象包含数据和操作数据的函数
>OOP 本质是把问题解决抽象为以对象为中心的计算机程序
注:
>OOP在较大规模或复杂项目中十分有用,OOP可以提高协作产量
>OOP最主要的价值在于代码复用
>OOP只是一种编程方式,并非解决问题的高级方法
面向过程 vs 面向对象
>面向过程:以解决问题的过程步骤为核心编写程序的方式
>面向对象:以问题对象构建和应用为核心编写程序的方式
>所有OOP能解决的问题,面向过程都能解决
小例子:



(3),面向对象的三个特征:
OOP的三个特征:
>封装:属性和方法的抽象,用数据和操作数据的方法来形成对象逻辑
>继承:代码复用的高级抽象,用对象之间的继承关系来形成代码复用
>多态:方法灵活性的抽象,让对象的操作更加灵活,更多复用代码
它能让更少的对象名称来支持更多的对象操作
它们都是表达了代码抽象和代码复用,
封装的理解:
封装Encapsulation:属性和方法的抽象
>属性的抽象:对类的属性(变量)进行定义,隔离及保护
>方法的抽象:对类的方法(函数)进行定义,隔离及保护
>目标是形成一个类/对象 对外可操作属性和方法的接口
继承的理解:
继承 Inheritance:代码复用的高级抽象
>继承是面向对象程序设计精髓之一
>实现了以类为单位的高抽象级别代码复用
>继承是新定义的类 能够几乎完全使用原有类属性和方法的过程
多态的理解:
多态 Polymorphism :仅针对方法,方法灵活性的抽象
>参数类型的多态:一个方法能够处理多个类型的能力
>参数形式的多态:一个方法能够接受多个参数的能力
>多态是 OOP的一个传统概念,Python天然支持多态,不需要特殊语法
其他语言中要用特定的语法用多态,但是Python中设计的弱类型天然支持多态
对多态的理解重点是概念和思路上的理解,更能理解Python对类的方法灵活性的抽象是如何表达的,
(4),Python面向对象术语:
先简要过一遍,后会介绍:
类 Class 和 对象 Object :
>类:逻辑抽象和产生对象的模板,一组变量和函数的特定编排
>对象:具体表达数据及操作的实体,相当于程序中的"变量"
>实例化:从类到对象的过程,所有"对象"都源于某个"类"
对象: 对象具体分为: 类对象和实例对象
类对象 vs 实例对象 :
>类对象:Class Object,当一个类建立之后,系统会维护个Python类基本信息的数据结构
>实例对象:Instance Object,Python类实例后产生的对象,简称:对象
>这是一组概念,类对象全局只有一个(保存类的基本信息),实例对象可以生成多个
属性: 存储数据的“变量”,分为 :类属性 和实例属性
方法: 操作数据的"函数",
包括:类方法,实例方法,自由方法,静态方法,保留方法
三个特性:封装继承多态
继承:基类,派生类,子类,父类,超类,重载
命名空间:程序元素作用域的表达
构造和析构:生成对象和删除对象的过程

(5),Python面向对象实例入门:
是上面的那个例子,计算价格的和,
出现新的保留字class
它可以定义抽象的Product 类,


1 class Product(): 2 def __init__(self,name): 3 self.name = name 4 self.label_price = 0 5 self.real_price = 0 6 7 c = Product("电脑") 8 d = Product("打印机") 9 e = Product("投影仪") 10 c.label_price,c.real_price = 10000,8000 11 d.label_price,d.real_price = 2000,1000 12 e.label_price,e.real_price = 1500,900 13 s1 ,s2 = 0,0 14 for i in [c,d,e]: 15 s1+= i.label_price 16 s2+= i.real_price 17 print(s1,s2)
unit2:Python类的构建:
python类的构建需要关注的地方:
就是上面的那个图:它包含了构建一个类所要关注的方方面面:
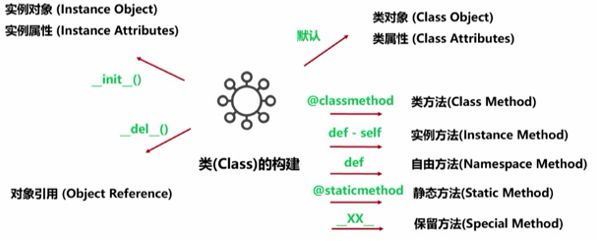
(1),类的基本构建:
使用class保留字定义类:
class <类名>:
[可以写个类描述字符串 "documentation string"]
<语句块>
注:类定义不限位置,可以包含在分支或其他从属语句块中,执行时存在即可
可以放在全局部分,也可以放在分支,函数,等从属语句块中,由于Python 语言是脚本语言,
所以在某个对象引用之前,只要是类被定义就可以。
类构造之类的名字:可以是任意有效标识符,建议采用大写单词的组合
如:ClassName ,BasicAuto ,BasicCreature
类构造之类描述:在类的定义后首行,以独立字符串形式定义
定义可以通过 <类名>.__doc__ 属性来访问
注:像这种前后都有两个下划线的属性是Python给类保留的属性,
class DemoClass:
"This is a demo for Python class"
pass
print(DemoClass.__doc__)
>>>This is a demo for Python class
介绍一个概念:类对象
大家不要把类和对象拆开,类对象是一个名词,(Class Object)
>类定义完成后,默认生成一个类对象
与其他语言不同,python的类只要定义完就会生成一个对象,但这个对象呢?只是与这个类唯一对应的,
每一个类只唯一对应一个类对象,这个类对象是存储这个类的基本信息的
>每个类唯一对应一个类对象,用于存储这个类的基本信息
>类对象是type类的实例,表达为type类型
什么是type类型呢?
它是编译器提供了一种类型,
class DemoClass:
"This is a demo for Python class"
print("hello DemoClass")
print(type(DemoClass))
输出:
hello DemoClass
我们发现,我们只是定义了这个类,但是它也执行 print("hello DemoClass)
这时因为在python中只要这个类被定义了, 就会生成一个表达它信息的 类对象
这个类对象是内置包含在类的定义中的,
那么这个类对象的生成使得类定义中的一些语句被执行,
因此,我们一般不在类的定义中直接包含语句,而是通过属性和方法来增加操作功能
类对象并不是使用类的常用方式,
使用类的方式最常用的是:通过创建实例对象来使用类的功能
<对象名> = <类名>([<参数>])
进一步采用 <对象名>.<属性名> 和 <对象名>.<方法名>() 体现类的功能
实例对象的类型:
它所生成时的那个类的类型
class DemoClass:
"This is a demo for Python class"
pass
print(type(DemoClass))
cn = DemoClass()
print(type(cn))
输出:
所以,实例对象和类对象是不一样的 ,
实例对象是最常用的方式,
了解Python 类的构造函数
>类的构造函数用于从类创建实例对象的过程
>类的构造函数为实例对象创建提供了参数输入方式
>类的构造函数为实例属性的定义和赋值提供了支持
了解Python类的属性和方法:
>类的属性:类中定义的变量,采用描述类的一些特性参数
>类的方法:类中定义且与类相关的函数,用来给出类的操作功能
>属性和方法是类对外交互所提供的两种接口方式
(2),类的构造函数:
类的构造函数是从类生成实例对象所使用的函数,
Python中使用预定义的__init__() 作为构造函数,
clsaa <类名>:
def __init__(self,<参数列表>)
<语句块>
类实例化时所使用的函数,可以接收参数并完成初始化操作
class DemoClass:
def __init__(self,name):
print(name)
dc1 = DemoClass("老王")
dc2 = DemoClass("老李")
输出:
老王
老李
注:通过构造函数__init__() 可以为Python对象提供参数
还有,构造函数默认有个参数self ,它内部使用的,默认保留的,
__init__() 的使用说明:
>参数:第一个参数约定是self,表示类实例自身,其他参数都是实例参数
>函数名:Python解释器内部定义的,由双下划线开始和结束
>返回值:构造函数没有返回值,或返回None ,否则产生TypeError 异常
self 在类定义内部代表类的实例
>self 是Python面向对象中约定的一个类参数
>self代表类的实例,在类内部,self用于组合访问实例相关的属性和方法
>相比较而言,类名代表类对象本身
(3),类的属性:
属性是类内部定义的变量
>类属性:类对象的属性,由所有实例对象共享
>实例属性:实例对象的属性,由各实例所独享
类的属性和实例属性是如何定义的?
我们知道属性是变量,类中有两个地方可以放变量,
第一个是在class 的全局命名空间:
<类属性名> =<类属性初值>
第二个是在函数/方法中定义的它就是实例属性:
class <类名>:
<类属性名>=<类属性初值>
def __init__(self,<参数列表>):
self.<实例属性名 > = <实例属性初值>
...
class DemoClass:
count = 0 #直接在类中定义或赋值 无论在类内类外,访问类属性都要用<类名>.<属性名>来访问
def __init__(self,name,age):
self.name = name
self.age = age
DemoClass.count +=1
dc1 = DemoClass("老王",45)
dc2 = DemoClass("老李",51)
print("总数:",DemoClass.count)
print(dc1.name,dc2.name)
我们已经知道,类属性在类内,类外都是<类名>.<类属性>
而对于实例属性:
在类内部,用self.<属性名>访问
在类外部,用<对象名>.<属性名> 访问
注:在类外,类属性也是可以用<对象名>.<属性名>来访问的
class DemoClass:
def __init__(self,name):
self.name = name
#注:构造函数没有返回值
def luckey(self):
s = 0
for c in self.name:
s+=ord(c)%100
return s
dc1 = DemoClass("Wang")
dc2 = DemoClass("Li")
print(DemoClass.__dict__) # 类对象的属性字典
print(dc1.__dict__) # 实例对象的属性字典
print(dc2.__dict__) # 实例对象的属性字典
print(DemoClass.__dir__(DemoClass)) #类对象的属性列表
print(dc1.__dir__()) #实例对象的属性列表
(4),类的方法:
方法是类内部定义的函数:
>实例方法:实例对象的方法,由各实例对象独享,最常用的形式
>类方法:类对象的方法,由所有实例对象共享
>自由方法:类中的一个普通函数,由类所在命名空间管理,类对象独享
>静态方法:类中的一个普通函数,由类对象和实例对象共享
>保留方法:由双下划线开始和结束的方法,保留使用,如__len__()
方法1:实例方法:
实例方法是类内部定义的函数,与实例对象相关
class <类名>:
def <方法名>(self,<参数列表>):
...
实例方法采用 <对象名>.<方法名>(<参数列表>) 方式使用
class DemoClass:
def __init__(self,name):
self.name = name
#注:构造函数没有返回值
def luckey(self):
s = 0
for c in self.name:
s+=ord(c)%100
return s
dc1 = DemoClass("Wang")
dc2 = DemoClass("Li")
print(dc1.name,"'s lucky number is :",dc1.luckey())
print(dc2.name,"'s lucky number is :",dc2.luckey())
输出:
Wang 's lucky number is : 197
Li 's lucky number is : 81
方法2:类方法:
类方法是与类对象相关的函数,由所有实例对象共享
class <类名>:
@classmethod 装饰器
def <方法名>(cls,<参数列表>):
...
类方法采用 <类名>.<方法名>(<参数列表>) 或 <对象名>.<方法名>(<参数列表>) 方式使用
>类方法至少包含一个参数,表示类对象,建议使用cls
>@classmethod是装饰器,类方法定义必须要有
>类方法只能操作类属性和其他类方法,不能操作实例属性和实例方法
class DemoClass:
count =0
def __init__(self,name):
self.name = name
DemoClass.count +=1
#注:构造函数没有返回值
@classmethod
def getChrCount(cls):
s = "0123456789"
return s[DemoClass.count]
dc1 = DemoClass("Wang")
dc2 = DemoClass("Li")
print(DemoClass.getChrCount())
print(dc1.getChrCount()) # 类方法是可以被实例对象调用的,因为它归类对象和实例对象共同所有
输出:
2
2
方法3,自由方法:
是定义在类命名空间中的普通函数
class <类名>:
def <方法名>(<参数列表>):
...
# 注:这里既没有self,也没有cls
自由方法采用 <类名>.<方法名>(<参数列表>)方式使用,这时的<类名>代表的是命名空间
换句话说,自有方法是什么,它是在<类名>这个命名空间中定义的一个函数,访问它只能用
<函数名>.方法名 来访问,
注:类对象自己独有
>自由方法不需要self,cls这类参数,可以没有参数
>自由方法只能操作类属性和类方法,不能操作实例属性和实例方法
>自由方法的使用只能用<类名>
严格来说,自由方法就不应该算是方法,它就是个函数,只不过是定义在类的命名空间中
为了统一说法,所以我们叫它自由方法,
class DemoClass:
count =0
def __init__(self,name):
self.name = name
DemoClass.count +=1
#注:构造函数没有返回值
def func():
DemoClass.count *=100
return DemoClass.count
dc1 = DemoClass("Wang")
print(DemoClass.func())
输出: 100
方法4:静态方法:
我们知道,自由方法只能由类对象来使用,有没有办法让实例对象使用普通的函数(没有self,cls)呢?
可以,就是在自由方法的基础上加上一个装饰器@classmethod就可以了,
它是定义在类中的普通函数,能够被所有实例对象共享
class <类名>:
@staticmethod
def <方法名>(<参数列表>):
...
静态方法采用 <类名>.<方法名>(<参数列表>) 或 <对象名>.<方法名>(<参数列表>) 方式使用
>静态方法可以没有参数,可以理解为定义在类中的普通函数
>@staticmethod是装饰器,静态方法必须用它
>静态方法只能操作 类属性和其他类 方法,不能操作实例属性和实例方法
>相比于自由方法,静态方法能够使用<类名>和<对象名>两种方式调用
class DemoClass:
count =0
def __init__(self,name):
self.name = name
DemoClass.count +=1
#注:构造函数没有返回值
@staticmethod
def func():
DemoClass.count *=100
return DemoClass.count
dc1 = DemoClass("Wang")
print(dc1.func())
print(DemoClass.func())
记时,方法3和方法4一起记
方法5:保留方法:
保留方法由双下划线开始和结束的方法,保留使用
class <类名>:
def <保留方法名>(self,<参数列表>):
...
保留方法一般都对应类的某种操作,使用操作符调用它
其实构造函数本身也是保留方法,
class DemoClass:
count =0
def __init__(self,name):
self.name = name
DemoClass.count +=1
#注:构造函数没有返回值
def __len__(self):
return len(self.name)
dc1 = DemoClass("Wang")
print(len(dc1))
输出:4
__len__ () 方法对应内置函数len() 函数操作
理解:
这时Python 解释器保留方法,已经对应,只需要编写代码即可
重写保留方法:
class DemoClass:
count =0
def __init__(self,name):
self.name = name
DemoClass.count +=1
#注:构造函数没有返回值
def __len__(self):
return 5
dc1 = DemoClass("Wang")
print(len(dc1))
输出: 5
终结总结:
我们可以理解为len() 只能计算基本数据类型的长度,对于类的长度它不能计算
我们就让他去调用类的保留方法__len__()
len(dc1) 其实它还是调用的是dc1.__len__() 方法
然后:这个保留方法内部计算了一个基础类型的长度 len(name)
(5),类的析构函数:
当一个对象不用的时候,我们要对它释放空间,
Python使用预定义的__del__() 作为析构函数
class <类名>:
def __del__(self):
<语句块>
...
析构函数在“真实” 删除实例对象时被调用
“真实”后面会介绍
例子:
class DemoClass:
def __init__(self,name):
self.name = name
def __del__(self):
print("再见",self.name)
dc1 = DemoClass("Wang")
del dc1
输出:
再见 Wang
删除对象就是使用保留字del
使用del 删除对象且对象被真实删除 时调用析构函数__del__()
>函数名和参数:Python解释器内部约定,保留方法
>调用条件:当实例对象被“真实删除”时,才调用该函数语句
>“真实删除”:当前对象的引用数为0 或当前程序退出(垃圾回收)
例子:
import time
class DemoClass:
def __init__(self,name):
self.name = name
def __del__(self):
print("再见",self.name)
dc1 = DemoClass("Wang")
dc2 = dc1 #引用
del dc1
print(dc2.name)
while(True):
time.sleep(1) # 使程序不退出
输出:
Wang
这就是只有当真实删除时才会调用析构函数
当然,一般构建对象的时候,我们不用写析构函数,python的垃圾回收机制已经很灵活了。
Python类的内存管理:
>在删除对象前,Python解释器会检查引用次数
>检查删除之后是否引用次数为0,不为0则仅删除当前引用;为0,则删除对象
>如果程序退出,则由垃圾回收机制删除对象
那么如何对一个对象的引用数量进行获取呢?
python 提供了一个sys.getrefcount(<对象名>)获得对象的引用次数
>返回对象引用次数的方法,辅助删除对象时的分析
>sys.getrefcount() 函数返回值为 被 引用值 +1
>非特定目的,不建议自己写析构函数,利用Python垃圾回收机制就行
import sys
class DemoClass:
def __init__(self,name):
self.name = name
def __del__(self):
print("再见",self.name)
dc1 = DemoClass("Wang")
dc2 = dc1 #引用
print(sys.getrefcount(dc1))
输出: 3 (比真实多1)
unit3:实例1:银行ATM等待时间分析:
需求分析:

可扩展为泊松分布:

1 import random as rd 2 ''' 3 整体思路: 4 1,需要一个全局时间 5 2,以ATM每次处理结束的时间为时间驱动事件 6 3,需要一个等待队列,维护客户到达时间 7 4,时间变化时,驱动等待队列变化 8 ''' 9 class ATM(): 10 def __init__(self,maxtime = 5): 11 self.t_max = maxtime 12 def getServCompleteTime(self,start= 0):#完成一次业务的时间 start 可赋值给真实的时间, 13 # 这样就是绝对的时间了 14 return start + rd.randint(1,self.t_max) 15 16 class Customers(): 17 def __init__(self,n): 18 self.count = n 19 self.left = n 20 def getNextArrvTime(self,start = 0,arrvtime = 10): #下一个人到达的时间 21 if self.left !=0: 22 self.left -=1 23 return start +rd.randint(1,arrvtime) 24 else: 25 return 0 26 def isOver(self): #判断n 个客户是否都到达了 27 return True if self.left == 0 else False 28 29 c = Customers(100) #100个客户 30 a = ATM() 31 wait_list =[] #存放用户到达时间 32 wait_time =0 #总共等待时间 33 cur_time= 0 #当前时间 34 cur_time +=c.getNextArrvTime() 35 wait_list.append(cur_time) 36 while len(wait_list) !=0 or not c.isOver(): 37 if wait_list[0] <= cur_time: # 用户提前到了 38 next_time = a.getServCompleteTime(cur_time) #下次时间 39 del wait_list[0] 40 else: 41 next_time = cur_time +1 42 43 if not c.isOver() and len(wait_list) ==0: 44 next_arrv = c.getNextArrvTime(cur_time) 45 wait_list.append(next_arrv) 46 47 if not c.isOver() and wait_list[-1] <next_time: 48 next_arrv = c.getNextArrvTime(wait_list[-1]) 49 wait_list.append(next_arrv) 50 while not c.isOver() and next_arrv <next_time: 51 next_arrv = c.getNextArrvTime(wait_list[-1]) 52 wait_list.append(next_arrv) 53 for i in wait_list: 54 if i<= cur_time: 55 wait_time += next_time -cur_time 56 elif cur_time next_time: 57 wait_time += next_time -i 58 else: 59 pass 60 cur_time = next_time 61 print(wait_time/c.count)

unit4:Python类的封装
(1),封装的理解:
封装Encapsulation :属性和方法的抽象
> 属性的抽象:对类的属性(变量)进行定义,隔离及保护
> 方法的抽象:对类的方法(函数)进行定义,隔离及保护
>目的是形成一个类对外可操作属性和方法的接口
类中有属性和方法:
而属性和方法又封装了一些:
属性:
>分为私有属性:只能在类内部访问
>公开属性:可以通过类/对象名访问
方法:
>私有方法:只能在类内部使用
>公开方法:可以通过类/对象名访问
>属性的抽象:可以选择公开或隐藏属性,隐藏属性的内在机理
>方法的抽象:可以选择公开或隐藏方法,隐藏方法的内部逻辑
>封装:让数据和代码成为类的过程,表达为: 类-属性-方法
(2),私有属性和公开属性:
对于类来说,有类对象和实例对象
所以,属性共有四类:
>公开类属性
>私有类属性
>公开实例属性
>私有实例属性
1,公开类属性:即类属性
class <类名>:
<类属性名> =<类属性初值>
def __init__(self,<参数列表>):
...
2,私有类属性:
仅供当前类访问的类属性,子类也不可访问
class <类名>:
<私有类属性名> =<类属性初值>
def __init__(self,<参数列表>):
...
区别:私有类属性名开始需要有两个下划线,如__count
>只能在类的内部被方法所访问
>不能通过<类名>.<属性名>或<对象名>.<属性名>方式访问
>有效保证了属性维护的可控性
class DemoClass:
__count = 0
def __init__(self,name):
self.name = name
DemoClass.__count += 1
@classmethod
def getCount(cls):
return DemoClass.__count
dc1 = DemoClass("Wang")
dc2 = DemoClass("Li")
print(DemoClass.getCount())
输出:2
3,公开实例属性:即实例属性
class <类名>:
<类属性名> =<类属性初值>
def __init__(self,<参数列表>)
self.<实例属性名> = <实例属性初值>
...
4,私有实例属性:仅供当前类内部访问的实例属性,子类也不能访问
class <类名>:
<类属性名> =<类属性初值>
def __init__(self,<参数列表>)
self.<私有实例属性名> = <实例属性初值>
注:方法一样,加上双下划线
>只能在类的内部被方法所访问
>不能通过<类名>.<属性名>或<对象名>.<属性名>方式访问
>有效保证了属性维护的可控性
例子:
class DemoClass:
def __init__(self,name):
self.__name = name
def getName(self):
return self.__name
dc1 = DemoClass("Wang")
dc2 = DemoClass("Li")
print(dc1.getName(),dc2.getName())
多看一眼:私有属性
双下划綫方法只是一种转换约定,转换后,类内原有名字发生了变化
这是一种形式上的私有!
它并不是真正的安全
class DemoClass:
def __init__(self,name):
self.__name = name
def getName(self):
return self.__name
dc1 = DemoClass("Wang")
dc2 = DemoClass("Li")
print(dc1._DemoClass__name)
输出: wang
这说明所谓的私有属性并不是真正的私有,只不过要换个名字才能访问它,这里的名字是
_DemoClass__name 。
这是形式上私有
别的语言(c++),是真正的私有
(3),私有方法和公开方法:
我们知道类有五种方法:
>实例方法
>类方法
>自由方法
>静态方法
>保留方法
私有方法是类内部定义并使用的函数:
class <类名>:
def <方法名>(self,<参数列表>):
...
私有方法名开始需要有两个下划线,如 :__getCount()
class DemoClass:
def __init__(self,name):
self.__name = name
def __getName(self):
if self.__name != "":
return self.__name
else:
return "Zcb"
def printName(self):
return "{}同志".format(self.__getName())
dc1 = DemoClass("Wang")
dc2 = DemoClass("")
print(dc1.printName(),dc2.printName())
输出:Wang同志 Zcb同志
>各类方法都可以通过增加双下划线变为私有方法
>私有方法从形式上保护了Python类内部使用的函数逻辑
>私有与公开是程序员逻辑,不是安全逻辑,重视约定
class DemoClass:
def __init__(self,name):
self.__name = name
def __getName(self):
if self.__name != "":
return self.__name
else:
return "Zcb"
def printName(self):
return "{}同志".format(self.__getName())
dc1 = DemoClass("Wang")
dc2 = DemoClass("")
print(dc1._DemoClass__getName())
输出: Wang
私有方法是一种形式上的私有,
(4),类的保留属性:
Python 解释器预留了一些类的属性,以双下划线开头和结尾来表示
>也叫:特殊属性,Special Attributes
>特点:双下划线开头和结尾
>作用:为理解Python类提供了同一的属性接口
>属性值:具有特定含义,类定义后直接使用
1,仅用 <类名> 访问的保留属性:
>__name__ : 类的名称
>__qualname__ : 以.分隔从模块全局命名空间开始的类名称
>__bases__ :类所继承的基类名称
例子:
class DemoClass:
"A Demo Class"
def __init__(self,name):
self.__name = name
def getName(self):
return self.name
dc1 = DemoClass("Wang")
print(DemoClass.__qualname__,DemoClass.__name__,DemoClass.__bases__)
输出:
DemoClass DemoClass (
由于当前类是定义在类的全局命名空间中,所以第二个就只是DemoClass
如下:将一个类定义在函数中:
def func():
class DemoClass:
"A Demo Class"
def __init__(self,name):
self.__name = name
def getName(self):
return self.name
return DemoClass
DemoClass =func()
dc1 = DemoClass("Wang")
print(DemoClass.__qualname__,DemoClass.__name__,DemoClass.__bases__)
输出:
func.
2,其他的保留属性:
<类>.__dict__ 包含类 成员(属性和方法) 信息的字典,key 是属性和方法名称,value是地址
<对象>.__dict__ 包含对象属性信息的字典,key是属性名称,value 是值
__class__ :对象所对应的类信息,即type信息
__doc__ : 类描述,写在类定义下的首行字符串,不能继承
__module__ :类所在模块的名称
class DemoClass:
"A Demo Class"
def __init__(self,name):
self.__name = name
def getName(self):
return self.name
dc1 = DemoClass("Wang")
print(DemoClass.__doc__,DemoClass.__module__,DemoClass.__class__)
print(dc1.__doc__,dc1.__module__,dc1.__class__)
输出:
A Demo Class __main__
A Demo Class __main__
注: 类对象的类是type
实例对象的类时__main__.DemoClass
class DemoClass:
"A Demo Class"
def __init__(self,name):
self.__name = name
def getName(self):
return self.name
dc1 = DemoClass("Wang")
print(DemoClass.__dict__)
print(dc1.__dict__)
输出:
{'__dict__':
{'_DemoClass__name': 'Wang'}
(5),类的保留方法:
与保留属性类似,python解释器预留 类的保留方法 ,
它们以双下划线开头和结尾
>也叫:特殊方法,Special Methods
>特点:双下划线开头和结尾
>作用:为操作Python类提供了统一的方法接口
>方法逻辑:具有特定含义,一般与操作符关联,类定义需要重载
Python解释器只是预留了这些名字,但是并没有预留逻辑,预留逻辑需要我们自己写,
常用保留方法:基础类别
保留方法 对应操作 描述
obj.__init__() obj = ClassName() 初始化实例对象的函数逻辑
obj.__del__() del obj 删除实例对象的函数逻辑
obj.__repr__() repr(obj) 定义对象可打印字符串的函数逻辑
obj.__str__() str(obj) 定义对象字符串转换操作的函数逻辑
obj.__del__() del obj 删除实例对象的函数逻辑
如何理解:str(obj) obj 是个对象,
那么它的str是什么呢?这就可以在其内部的__str__()中来定义函数逻辑了
其他依次类推
obj.__bytes__() bytes(obj) 定义对象字节串转换操作的函数逻辑
obj.__format__() format(obj) 定义对象格式化输出的的函数逻辑
obj.__hash__() hash(obj) 定义对象哈希操作的函数逻辑
obj.__bool__() bool(obj) 定义对象布尔运算的函数逻辑
obj.__len__() len(obj) 定义对象长度操作的函数逻辑
obj.__reversed__() obj.reversed() 定义对象逆序的函数逻辑
obj.__abs__() abs(obj) 定义对象绝对值操作的函数逻辑
obj.__int__() int(obj) 定义对象整数转换的函数逻辑
常用保留方法:比较操作
保留方法 对应操作 描述
obj.__lt__() obj1
obj.__le__() obj1<=obj2 对象间比较操作的保留方法
obj.__eq__() obj1==obj2 对象间比较操作的保留方法
obj.__ne__() obj1!=obj2 对象间比较操作的保留方法
obj.__gt__() obj1>obj2 对象间比较操作的保留方法
obj.__ge__() obj1>=obj2 对象间比较操作的保留方法
小于: little 大于是:great 等于:equal
同样的是,关于两个对象如何去比较,这是需要我们自己在其中补充代码
Python 类保留方法使用说明:
>Python保留了超过100个各种保留方法
>保留方法对应对象,对象间,对象方法的各种操作
>有哪些保留方法? 请参考各种数据类型的使用
总结: python 并不支持天然的私有封装,所谓的私有只是一种形式上的私有
unit5:Python类的继承:
(1),继承的理解:
继承 Inheritance :它是代码复用的高级抽象
>继承是面向对象的设计精髓之一
>实现了以类为单位的高抽象级别代码复用
>继承是新定义的类能够几乎完全使用原有类属性与方法的过程
之所以,使用面向对象是因为它比函数能提供更高级别的代码复用能力,
 (基类和派生类只是两种说法,它们都是Python类)
(基类和派生类只是两种说法,它们都是Python类)
除了基类和派生类,还有子类,父类,超类

最后生成的那个派生类是子类,子类直接继承的是父类,间接继承的是超类,
这些只是一些定义,
在讲派生时,我们一般用基类和派生类 或 父类和子类, 都可以的,
同时,派生类也可以继承多个基类,这就是多继承问题,
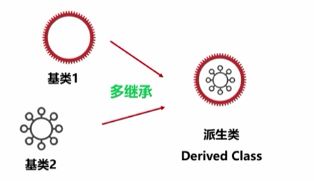
(2),类继承的构建:
在定义类时声明继承关系
calss <类名> (<基类名>):
def __init__(self,<参数列表>):
<语句块>
...
基类名也可以带有路径: MoudleName.BaseClassName
注:一定要记住,类名后的括号不是参数列表而是继承
派生类(子类) 可以直接使用基类(父类)的属性和方法:
>父类的属性 基本等同于 定义在子类中
>子类可以直接使用父类的类属性,实例属性
>子类可以直接使用父类的各种方法
>使用父类的类方法和类属性时,要用父类的类名调用
例子:
class DemoClass:
count = 0
def __init__(self,name):
self.name = name
DemoClass.count += 1
def getName(self):
return self.name
class HumanNameClass(DemoClass):
def printName(self):
return str(DemoClass.count)+self.name +"同志"
dc1= HumanNameClass("Wang")
print(dc1.getName())
print(dc1.printName())
输出:
Wang
1Wang同志
注意:父类的属性和方法相当于定义在子类中
2个与继承关系判断有关的Python内置函数:
isinstance(obj,cls) 判断对象obj 是否是类cls 的实例或子类实例,返回True/False
issubclass(cls1,cls2)判断类cls1 是否是类cls2 的子类,返回True/False
例子:
class DemoClass:
count = 0
def __init__(self,name):
self.name = name
DemoClass.count += 1
def getName(self):
return self.name
class HumanNameClass(DemoClass):
def printName(self):
return str(DemoClass.count)+self.name +"同志"
dc1= HumanNameClass("Wang")
print(isinstance(dc1,DemoClass))
print((isinstance(dc1,HumanNameClass)))
print(issubclass(HumanNameClass,DemoClass))
输出:
True
True
True
子类的约束:
>子类只能继承基类的公开属性和方法
>子类不能继承父类的私有属性和私有方法
(3),Python最基础类:
object类时Python所有类的基类
>object是Python最基础类的名字,不建议翻译理解,类的名字就是object (o是小写)
>所有类定义时默认继承object类
>保留属性和保留方法本质上是object类的属性和方法,因为我们定义的任何类都继承object,
所以object里的保留属性和方法就成了任何类中可用的属性和方法了
我们通过object的保留属性和保留方法来了解object
print(object.__name__)
print(object.__doc__)
print(object.__bases__)
print(object.__class__)
print(object.__module__)
print(object.__dict__)
输出:
object
The most base type
() #它本身就是基类
builtins
{'__ne__':
还有要知道
Python里的对象都有三个要素:标识,类型,和值
>标识identity :对象一旦构建不会改变,用id() 获得,一般是内存地址
>类型type : 对象的类型,用type()获得
>值 value :分为可变mutable 和不可变 immutable 两种
2个与基础类有关的Python内置功能:
函数/保留字 描述
id(x) 返回x 的标识,Cpython用内存地址标识
x is y 判断x 和y 的标识是否相等,返回 True/False,不判断值
例子:
class DemoClass:
count = 0
def __init__(self,name):
self.name = name
DemoClass.count += 1
def getName(self):
return self.name
class HumanNameClass(DemoClass):
def printName(self):
return str(DemoClass.count)+self.name +"同志"
dc1= HumanNameClass("Wang")
print(id(dc1),type(dc1))
print(id(DemoClass),type(DemoClass))
print(dc1 is DemoClass)
print(type(object),type(type))
输出:
2625484754056
2625483867848
False
总结:

(4),类的属性重载:
重载是指子类对父类属性或方法的再定义
>属性重载:子类定义并使用了与父类相同名称的属性
>方法重载:子类定义并使用了与父类相同名称的方法
最近覆盖原则:
重载无序特殊标记
>步骤1:优先使用子类重定义的属性和方法
>步骤2:然后寻找父类的属性和方法
>步骤3:再寻找超类的属性和方法
例子:
class DemoClass:
count = 0
def __init__(self,name):
self.name = name
DemoClass.count += 1
def getName(self):
return self.name
class HumanNameClass(DemoClass):
count = 99
def __init__(self,name):
self.name = name
HumanNameClass.count -=1
def printCount(self):
return str(HumanNameClass.count)+self.name
dc1= HumanNameClass("Wang")
print(dc1.printCount())
输出:
98Wang
(5),类的方法重载:
方法重载: 子类定义并使用了与父类相同名称的方法
>完全重载:子类完全重定义与父类相同名称的方法
直接在类中定义同名方法即可
>增量重载:子类扩展定义与父类相同名称的方法
我们这里主要说增量重载:(因为完全重载太简单了)
增量重载:使用super() 方法
class <子类名> (<父类名>):
def <方法名>(self,<参数列表>):
super().<父类方法名>(<参数列表>)
...
就是super() 函数实际上返回的是子类对应的父类
例子:
class DemoClass:
count = 0
def __init__(self,name):
self.name = name
DemoClass.count += 1
def printCount(self):
return str(HumanNameClass.count)+self.name
class HumanNameClass(DemoClass):
def __init__(self,name):
self.name = name
def printCount(self):
return super().printCount()+"同志"
dc1= HumanNameClass("Wang")
print(dc1.printCount())
输出:
0Wang同志 #这就给后面加上了同志二字
(6),类的多继承:
多继承是指在定义类时,继承多个父类
class <类名>(<父类名1>,<父类名2>,):
def __init__(self,<参数列表>):
<语句块>
...
注: 基类名也可以带有路径:MoudleName.BaseClassName
Python3 采用深度优先,从左至右 的方法实施多继承
例子:
class DemoClass:
def __init__(self,name):
self.name = name
def printName(self):
return self.name
class NameClass:
def __init__(self,title):
self.nick = title
def printName(self):
return self.nick + "同志"
class HumanNameClass(DemoClass,NameClass):
pass
dc1= HumanNameClass("Wang")
print(dc1.printName())
print(HumanNameClass.__mro__) #解析顺序MRO 是个元组
输出:
Wang
(
注: MRO:Method Resolution Order,即方法解析顺序,是python中用于处理二义性问题的算法
可通过<类名>.__mro__ 查看
类多继承的使用说明:
>所有属性和方法的使用按照 "深度优先,从左到右"的方式选取
>构造函数也参数上述原则,super() 也参照上述原则
>多个基类的顺序是关键
例子:
class DemoClass:
def __init__(self,name):
self.name = name
def printName(self):
return self.name
class NameClass:
def __init__(self,title):
self.nick = title
def printName(self):
return self.nick + "同志"
class HumanNameClass(DemoClass,NameClass):
def printName(self):
return super().printName() +"你好"
dc1= HumanNameClass("Wang")
print(dc1.printName())
输出:
Wang你好
第二部分的内容:
unit1:Python类的运算:
(1),运算符的理解:
运算Operation :操作逻辑的抽象
>运算体现一种操作逻辑,广义角度,任何程序都被认为是运算
>Python解释器通过保留方法预留了一批运算的接口,需要重载
>保留方法一般对应运算符,Python中运算体现为运算符的重载
类有 算术运算
比较运算
成员运算
其他运算
运算本质上体现了 交换关系
体现了 包含关系
体现了 常规关系
运算重载的限制:
>不能重载Python语言内置类型的运算符 ,比如改变字典类型的加法运算,这是不行的
>不能新建运算符,只能通过重载完成
>is and not or 不能被重载
=====各类运算符的重载
(2),算术运算的重载:
>一元算术运算符:+ - ~
>二元算术运算符:+,-,*,/,//,%,divmmod(),pow(),**,<<,>>,&,^,|
先看一元算术运算符的重载:
保留方法 对应操作 描述
.__neg__(self) -obj 定义对象取负的运算逻辑
.__pos__(self) +obj 定义对象取正的运算逻辑
.__abs__(self) abs(obj) 定义对象取绝对值的运算逻辑
.__invert__(self) ~obj 定义对象取反的运算逻辑
二元算术运算符的重载:
保留方法 对应操作 描述
.__add__(self,other) obj +other 定义两个对象加法的运算逻辑
.__sub__(self,other) obj -other 定义两个对象减法的运算逻辑
.__mul__(self,other) obj *other 定义两个对象乘法的运算逻辑
.__truediv__(self,other) obj /other 定义两个对象除法的运算逻辑
.__floordiv__(self,other) obj //other 定义两个对象整除的运算逻辑
.__mod__(self,other) obj %other 定义两个对象模的运算逻辑
.__divmod__(self,other) divmod(obj,other)定义两个对象除模的运算逻辑
.__pow__(self,other) obj **other 定义两个对象幂的运算逻辑
.__lshift__(self,other) obj < .__rshift__(self,other) obj >>other 定义两个对象右移的运算逻辑 .__and__(self,other) obj &other 定义两个对象位与的运算逻辑 .__xor__(self,other) obj ^other 定义两个对象位异或的运算逻辑 .__or__(self,other) obj |other 定义两个对象位或的运算逻辑 例子: class myList(list): # 继承list 类 def __add__(self, other): #重载加法运算 result =[] for i in range(len(self)): try: result.append(self[i]+other[i]) except: result.append(self[i]) return result ls1 = myList([1,2,3,4,5,6]) ls2 = myList([1,5,6,8]) print(ls1+ls2) 输出: [2, 7, 9, 12, 5, 6] 注: ls3=[1,5,66] ls4=[1,2] print(ls3+ls4) 输出:[1, 5, 66, 1, 2] (3),比较运算的重载: >比较运算:<,<=,==,!=,>,>= 六种比较运算 保留方法 对应操作 描述 obj.__lt__() obj1 obj.__le__() obj1<=obj2 对象间比较操作的保留方法 obj.__eq__() obj1==obj2 对象间比较操作的保留方法 obj.__ne__() obj1!=obj2 对象间比较操作的保留方法 obj.__gt__() obj1>obj2 对象间比较操作的保留方法 obj.__ge__() obj1>=obj2 对象间比较操作的保留方法 小于: little 大于是:great 等于:equal 例子: class myList(list): # 继承list 类 def __lt__(self, other): "以各元素的算术和为比较依据" s,t = 0,0 for c in self: s +=c for c in other: t +=c return True if s ls1 = myList([1,2,3,4,5,6]) ls2 = myList([1,5,6,8]) print(ls1 输出: False 注: ls3 = [1,2,3,4,5,6] ls4 = [1,5,6,8] print(ls3 输出: True (4),成员运算的重载: 成员运算的种类: >成员获取:[],del ,.reversed() >成员判断: in, not in 先看成员获取: 保留方法 对应操作 描述 .__getitem__(self,key) obj[k] 定义获取对象中序号k元素的运算逻辑,k为整数 .__setitem__(self,key,v) obj[k] =v 定义赋值对象中序号k元素的运算逻辑,k为整数 .__delitem__(self,key) del obj[k] 定义删除对象中序号k元素的运算逻辑,k为整数 .__reversed__(self) obj[k] 定义对象逆序的运算逻辑 成员判断: 保留方法 对应操作 描述 .__contains__(self,item) item in obj 定义in 操作符对应的运算逻辑 #not in不能重载 ,因为not 不能被重载 例子: class myList(list): # 继承list 类 def __contains__(self, item): "各元素的算术和也作为成员" s =0 for c in self: s +=c if super().__contains__(item) or item ==s: return True else: return False ls = myList([6,1,2,3]) print(6 in ls ,12 in ls) 输出: True True (5),其他运算的重载: 其他运算: >Python内置函数:repr(),str(),len(),int(),float(), complex(),round(),bytes(),bool(),format() >类的常用方法:.format() 保留方法 对应操作 描述 .__repr__() repr(obj) 定义对象可打印字符串的运算逻辑 .__str__() str(obj) 定义对象字符串转换操作的运算逻辑 .__len__() len(obj) 定义对象长度操作的运算逻辑 .__int__(self) int(obj) 定义对象整数转换的运算逻辑 .__float__(self) float(obj) 定义对象浮点数转换的运算逻辑 .__complex__(self) complex(obj) 定义对象复数转换的运算逻辑 .__round__(self) round(obj) 定义对象四舍五入的运算逻辑 .__bytes__(self) bytes(obj) 定义对象字节串转换操作的运算逻辑 .__bool__(self) bool(obj) 定义对象布尔运算的运算逻辑 .__format__(self) obj.format()/format(obj) 定义对象格式化输出的运算逻辑 例子: class myList(list): # 继承list 类 def __format__(self, format_spec): "格式化输出,以逗号分隔" t=[] for c in self: if type(c) == type("字符串"): t.append(c) else : t.append(str(c)) return ", ".join(t) ls = myList([6,1,2,3]) print(format(ls)) 输出: 6, 1, 2, 3 注: format([1,2,3,4]) 输出: [1, 2, 3, 4] unit2:Python类的多态: Python语言天生支持多态,这里没有特殊的语法需要我们记住, (1),多态的理解: 多态 Polymorphism: 仅针对方法,方法灵活性的抽象 >参数类型的多态: 一个方法能够处理多个类型的能力 >参数形式的多态: 一个方法能够处理多个参数的能力 >多态是OOP传统的一个概念,Python天然支持多态,不需要特殊的语法 参数类型多态是指:方法不改变的情况下,可以支持多种参数类型 参数形式多态是指:一个方法名字不改变的情况下,可以支持多个不同参数的输入 目的还是为了提高代码复用的抽象级别。 (2),参数类型的多态: 由于python的函数没有参数类型声明的限制,所以python天然支持参数类型的多态性, 天然支持:Python方法的参数无类型声明的限制 >Python的函数/方法的参数没有类型声明的限制,天然支持参数类型的多态性 >Python编程的理念在于:文档约束,而非语法约束 >对不同的参数类型的区分及功能,需要由程序员完成 例子: class DemoClass: def __init__(self,name): self.name = name def __id__(self): #处理多态时,尤其是需要处理所有数据类型的时候,建议重载 #一个Python内部的函数,这个内部函数要能跟所有类型打交道 #举个例子id () 函数,任何一个类型都可以通过它获得内部id #我们可以重载它,使得返回一个我们需要的结果 return len(self.name) #重载id ,使其返回用户的名字 def lucky(self,arg): s =0 for c in self.name: s += (ord(c)+id(arg)) %100 return s dc1 = DemoClass("Wang") dc2 = DemoClass("Li") print(dc1.lucky(10)) print(dc1.lucky("10")) print(dc1.lucky(dc2)) 输出: 317 189 221 (3),参数形式的多态: 由于python的方法本身就是个函数,python的函数又支持可变参数,所以参数形式的多态也是 天然的支持, >Python的函数/方法可以支持可变参数,支持参数形式的多态性 >Python的类方法也是函数,函数的各种定义方式均有效 >对不同参数个数及默认值的确定,需要由程序员完成 例子: class DemoClass: def __init__(self,name): self.name = name def __id__(self): return len(self.name) def lucky(self,arg=0,more = 0): #需要方法能够处理可变参数 s =0 for c in self.name: s += (ord(c)+id(arg)+more) %100 return s dc1 = DemoClass("Wang") print(dc1.lucky()) print(dc1.lucky(10)) print(dc1.lucky(10,100)) 输出: 237 317 317 unit3:实例2:图像的四则运算 需求分析: >加减法:两个图形相加减 >乘除法:一个图像与一个数字之间的乘除法 所要用到的两个库 具体代码: import numpy as np from PIL import Image class ImageObject: def __init__(self,path =""): self.path = path try: self.data = np.array(Image.open(path)) except: self.data = None def __add__(self, other): image = ImageObject() try : image.data = np.mod(self.data+other.data,255) except: image.data = self.data return image def __sub__(self, other): image = ImageObject() try : imgae.data = np.mod(self.data - other.data,255) except: image.data = self.data return image def __mul__(self, factor): image = ImageObject() try : image.data = np.mod(self.data*factor,255) except: image.data = self.data return image def __truediv__(self, factor): image = ImageObject() try : image.data = np.mod(self.data/factor,255) except: image.data = self.data return image def saveImage(self,path): try : im = Image.fromarray(self.data) im.save(path) return True except: return False a = ImageObject("d:/earth.jpg") b = ImageObject("d:/gray.jpg") (a+b).saveImage("d:/result_add.png") (a-b).saveImage("d:/result_sub.png") (a*2).saveImage("d:/result_mul.png") (a/2).saveImage("d:/result_div.png") 注: a = 15 print(a.__truediv__(2)) print(a.__floordiv__(2)) 输出: 7.5 7 unit4:Python对象的引用 通过引用,将更加理解对象和类的概念 (1),引用的理解: 引用 Reference :对象的指针 >引用是内存中真实对象的指针,表示为变量名或内存地址 >每个对象至少存在一个引用(否则将会被垃圾回收机制回收) ,id() 函数用于获得引用 >在传递参数和赋值时,Python传递对象的引用,而不是复制对象 例子: ls = [1,2,3,4,5] lt = ls print(id(ls)) print(id(lt)) 输出: 2472917877896 2472917877896 这说明赋值的时候并没有真正的开辟内存,只是引用复制了一份 Python内部对引用处理的机制: >对于不可变对象:immutable ,解释器会为相同值维护尽量少的内存区域 >对于可变对象: mutable ,解释器为每个对象维护不同的内存区域 例子: a =10 b = a #引用 c = 10 print(id(a)) print(id(b)) print(id(c)) 输出: 1489175280 1489175280 1489175280 整数是不可变类型,10 都是在同一个内存 再看个例子: a = "Python计算生态" b = a #引用 c = "Python" d = "计算生态" e = c+d f = "Python计算生态" print(id(a)) print(id(b)) print(id(c)) print(id(d)) print(id(e)) #对运算后的不会优化,会开辟新的内存 print(id(f)) 输出: 2288379740048 2288379740048 2288377961192 2288379805520 2288379969680 2288379740048 可变类型的引用: la = [] lb = la #引用 lc =[] print(id(la)) print(id(lb)) print(id(lc)) 输出: 1672822211656 1672822211656 1672824183816 再看: la = [] lb = la lb.append(1) print(la,id(la)) print(lb,id(lb)) #这是因为lb 是引用,它和la 指向同一块内存 输出 : [1] 1305658803272 [1] 1305658803272 导致引用 +1 的情况: >对像被创建:d = DemoClass() >对象被引用:a = d >对象被作为函数或方法的参数: sys.getrefcount(d) #这也是为何,使用sys.getrefcount()的时候,引用次数会加1 的原因了(因为对象做参数传递了) >对象被作为一个容器中的元素:ls =[d] 导致引用 -1 的情况: >对像被删除:del d >对象的名字被赋予新的对象:d = 123 >对象离开作用域:func() 函数的局部变量count >对象所在容器被删除:del ls 注:如果一个对象的引用为0,那么它就会被垃圾回收机制清理掉,内存就会被释放 引用的理解: >引用是内存中真实对象的指针,表示为变量名或内存地址 >在传递参数和赋值时,Python传递对象的引用,而不是复制对象 >不可变对象和可变对象的内存管理略有不同 对于可变对象,每次都会真实的创建对象, 对不可变对象,它会尽可能的复用不可变对象的内存空间 (2),浅拷贝和深拷贝: >拷贝:赋值一个对象为新的对象,内存空间有"变化" >浅拷贝: 仅复制最顶层对象的拷贝方式 ,默认拷贝方式 >深拷贝: 迭代复制所有对象的拷贝方式 1,浅拷贝: 例子: ls = ["Python",[1,2,3]] la = ls.copy() #引用 lb = ls[:]#引用 lc = list(ls)#引用 print("ls:",id(ls),ls) print("la:",id(la),la) print("lb:",id(lb),lb) print("lc:",id(lc),lc) 输出: ls: 1317721824264 ['Python', [1, 2, 3]] la: 1317721824008 ['Python', [1, 2, 3]] lb: 1317721824072 ['Python', [1, 2, 3]] lc: 1317721844040 ['Python', [1, 2, 3]] 这时候其实只是列表被拷贝了,但元素没有被拷贝, 看如下: ls = ["Python",[1,2,3]] la = ls.copy() #引用 lb = ls[:]#引用 lc = list(ls)#引用 for i in [ls,la,lb,lc]: for c in i: print(c,id(c)," ",end =" ") print(" ",i,id(i)) 输出: Python 2547295034088 [1, 2, 3] 2547295011976 ['Python', [1, 2, 3]] 2547301178376 Python 2547295034088 [1, 2, 3] 2547295011976 ['Python', [1, 2, 3]] 2547301178120 Python 2547295034088 [1, 2, 3] 2547295011976 ['Python', [1, 2, 3]] 2547301178184 Python 2547295034088 [1, 2, 3] 2547295011976 ['Python', [1, 2, 3]] 2547301198152 注:实际上复制的是列表中的指针。 这带来的问题: ls = ["Python",[1,2,3]] la = ls.copy() #引用 lb = ls[:]#引用 lc = list(ls)#引用 lc[-1].append(4) print(lc,la) print(ls,lb) 输出: ['Python', [1, 2, 3, 4]] ['Python', [1, 2, 3, 4]] ['Python', [1, 2, 3, 4]] ['Python', [1, 2, 3, 4]] 我们发现只要修改一个,其他都发生变化了, 2,深拷贝: 完全拷贝对象的内容 >这个要采用copy标准库的deepcopy() 方法 >迭代拷贝对象内各层次对象,完全新开辟内存建立对象 >深拷贝仅针对可变类型,不可变类型无需创建新对象 import copy ls = ["python",[1,2,3]] lt = copy.deepcopy(ls) for i in [ls,lt]: for c in i : print(c,id(c)," ",end = " ") print(" ",i,id(i)) 输出: python 2149527044816 [1, 2, 3] 2149529151752 ['python', [1, 2, 3]] 2149529115400 python 2149527044816 [1, 2, 3] 2149529151688 ['python', [1, 2, 3]] 2149529115464 注:不可变类型Python 是没有新创建的, 可变类型[1,2,3] 深拷贝是要新创建的 小结:对象的拷贝: 浅拷贝和深拷贝: >浅拷贝:仅复制最顶层对象的拷贝方式,默认拷贝方式 >深拷贝:迭代复制所有对象的拷贝方式,采用copy库的deepcopy() >一般深拷贝都与可变类型关联 (3),类的方法应用: 再看类的实例方法: >定义方式:def <实例方法名>(self,<参数列表>) >实例方法名(函数名)也是一种引用,即对方法本身的引用 >当方法被引用时,方法(函数)将产生一个对象:方法对象 class DemoClass: def __init__(self,name): self.name = name def lucky(self,arg= 0): s = 0 for c in self.name: s += (ord(c)+id(arg))%100 return s dc1 = DemoClass("Li") lucky = dc1.lucky print(DemoClass.lucky(dc1,10)) print(dc1.lucky(10)) print(lucky(10)) <对象名>.<方法>(方法参数) 等价于 <类名>.<方法名>(<对象名>,方法参数) 输出: 141 141 141 unit5:Python类的高级话题: (1),命名空间的理解: 命名空间 Namespace :从名字到对象的一种映射 >作用域:全局变量名在模块命名空间,局部变量在函数命名空间 >属性和方法在类命名空间,名字全称: <命名空间>.<变量/函数名> >命名空间底层由一个dict 实现,变量名是键,变量引用的对象是值 例子: >复数 z ,z.real 和 z.imag 是对象z命名空间的两个属性 >对象d,d.name 和d.printName() 是对象d命名空间的属性和方法 >global 和 nonlocal 是两个声明命名空间的保留字 例子: count = 0 #模块的命名空间 def getCounting(a): count = 0 #第一层函数的命名空间 if a != "": def doCounting(): nonlocal count #第二层函数的命名空间 count += 1 doCounting() return count print(getCounting("1"),count) print(getCounting("2"),count) print(getCounting("3"),count) 输出: 1 0 1 0 1 0 注:nonlocal的作用,是不在当前,向上逐层去找(到全局为止,不找全局) 例子: count = 0 #模块的命名空间 def getCounting(a): #count = 0 #第一层函数的命名空间 if a != "": def doCounting(): nonlocal count #第二层函数的命名空间 count += 1 doCounting() return count print(getCounting("1"),count) print(getCounting("2"),count) print(getCounting("3"),count) 输出: File "C:/Users/Administrator/Desktop/test/test.py", line 7 nonlocal count #第二层函数的命名空间 SyntaxError: no binding for nonlocal 'count' found 如果想用全局中的就要用global来声明了: 例子: count = 0 #模块的命名空间 def getCounting(a): #count = 0 #第一层函数的命名空间 if a != "": def doCounting(): global count #第二层函数的命名空间 count += 1 doCounting() return count print(getCounting("1"),count) print(getCounting("2"),count) print(getCounting("3"),count) 输出: 1 1 2 2 3 3 (2),类的特殊装饰器: 我们先看一个问题: d = DemoClass("LI") d.age = -99 >d.age如果作为年龄,其值有误,但属性不能检测异常值 >如何为属性增加异常检测呢? 这就要用Python的特性装饰器了, @property :类的特性装饰器 >使用@property 把类中的方法变成对外可见的“属性”,不是真正的属性,还是方法 >类内部:表现为方法 >类外部:表现为属性 例子: class DemoClass: def __init__(self,name): self.name = name @property #@property 用于转换方法为属性 def age(self): return self._age @age.setter # @<方法名>.setter 用于设定属性的赋值操作 def age(self,value): if value < 0 or value>100: value =30 self._age = value #将value 给self._age dc1 = DemoClass("Li") dc1.age = -100 print(dc1.age) #dc1.age其实调的是dc1.age() 输出:30 dc1.age 是被特性装饰器装饰过的, 总结,要想检测一个属性,可以@property 给它装饰,并用@<方法名>.setter 获取外部的值 (3),自定义的异常类型: 异常Exception 也是一种Python类: >try -except 捕捉自定义的异常 >继承Exception类,可以给出自定义的异常类 >自定义异常类时类继承的是Exception,那么,它就可以被try -except 捕获 例子: class DemoException(Exception): pass try: raise DemoException() #使用raise 抛出自定义的异常 except: print("捕获DemoException异常") 输出: 捕获DemoException异常 另一例子: class DemoException(Exception): def __init__(self,name,msg = "自定义异常"): self.name = name self.msg = msg try: raise DemoException("脚本错误") except DemoException as e: # 捕捉这个异常及异常对象 print("{} 异常的报警是 {}".format(e.name,e.msg)) 输出: 脚本错误 异常的报警是 自定义异常 (4),类的名称修饰: 名称修饰 Name Mangling :类中名称的变化约定 >Python通过名称修饰完成一些重要功能 >采用下划线进行名称修饰,分5中情况 >_X ,X_ ,__X ,__X__ ,_ 先看: _X >单下划线开头属性或方法为类内部使用 (PEP8 规定) >只是约定,仍然可以通过<对象名>.<属性名> 方式访问 >功能:from XX import * 时不会导入单下下划线开头的属性或方法 例子: class DemoClass(Exception): def __init__(self,name): self.name = name self._nick =name +"同志" #约定_nick 只在内部使用 def getNick(self): return self._nick dc1 = DemoClass("LI") print(dc1.getNick()) print(dc1._nick) # 仍然可以外部调用 输出: LI同志 LI同志 第二: X_ 单下划线接我的名称修饰 >单下划线结尾属性或方法为避免与保留字或已有命名冲突 (PEP 8) >只是约定,无任何功能性对应 例子: class DemoClass(Exception): def __init__(self,name): self.name = name self.class_ =name +"同志" def getNick(self): return self.class_ # 仅是为了避免重名 dc1 = DemoClass("LI") print(dc1.getNick()) print(dc1.class_) 第三:__X 双下划线开头的名称修饰 >双下划线开头属性或方法将被解释器修改名称,避免命名冲突 >不是约定,而是功能性,python 解释器会修改它,实现私有属性,私有方法 >__X 会被修改为 : _<类名>__X 例子: class DemoClass(Exception): def __init__(self,name): self.name = name self.__nick =name +"同志" def getNick(self): return self.__nick dc1 = DemoClass("LI") print(dc1.getNick()) print(dc1._DemoClass__nick) print(dc1.__nick) # 将报错 第四: __X__ 双下划綫开头和结尾的名称修饰 >双下划线开头和结尾的属性或方法无任何特殊功能,名字不被修改 >部分名称是保留属性/保留方法 例子: class DemoClass(Exception): def __init__(self,name): self.name = name self.__nick__ =name +"同志" def getNick(self): return self.__nick__ dc1 = DemoClass("LI") print(dc1.getNick()) print(dc1.__nick__) #不报错 第五: _ >单下划线是一个无关紧要的名字,无特殊功能 for _ in range(10): print("hello world") 小结:类的名称修饰: >_X :约定内部使用,仅在import *时不被引用 >X_ :避免与保留字冲突,无特殊功能 >__X :不被子类继承,可用于设定私有,改变为:_<类名>__X >__X__ :无特殊功能,部分用于保留属性和保留方法 >_ : 无特殊功能,不重要的命名 (5),Python最小空类: class <类名>(): pass >类是一个命名空间,最小空类可以当做命名空间来使用 >最小空类可辅助数据存储和使用 动态增加属性是Python类的一个特点 例子: class EmptyClass: pass a = EmptyClass() a.name = "Li" a.age = 50 a.family = {"son":"xiao Li"} print(a.family) print(a.__dict__) 输出: {'son': 'xiao Li'} {'name': 'Li', 'family': {'son': 'xiao Li'}, 'age': 50} 作用:用最小空类来组织数据 


