2019独角兽企业重金招聘Python工程师标准>>> 
随着互联网的不断发展,各种类型的应用层出不穷,所以导致在这个云计算的时代,对技术提出了更多的需求,主要体现在下面这四个方面:
低延迟的读写速度:应用快速地反应能极大地提升用户的满意度;
支撑海量的数据和流量:对于搜索这样大型应用而言,需要利用PB级别的数据和能应对百万级的流量;
大规模集群的管理:系统管理员希望分布式应用能更简单的部署和管理;
庞大运营成本的考量:IT经理们希望在硬件成本、软件成本和人力成本能够有大幅度地降低;
一、关系型数据库
关系型数据库,是指采用了关系模型来组织数据的数据库。关系模型是在1970年由IBM的研究员E.F.Codd博士首先提出的,在之后的几十年中,关系模型的概念得到了充分的发展并逐渐成为主流数据库结构的主流模型。
简单来说,关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
关系模型中常用的概念
- 关系:可以理解为一张二维表,每个关系都具有一个关系名,就是通常说的表名
- 元组:可以理解为二维表中的一行,在数据库中经常被称为记录
- 属性:可以理解为二维表中的一列,在数据库中经常被称为字段
- 域:属性的取值范围,也就是数据库中某一列的取值限制
- 关键字:一组可以唯一标识元组的属性,数据库中常称为主键,由一个或多个列组成
- 关系模式:指对关系的描述。其格式为:关系名(属性1,属性2, ... ... ,属性N),在数据库中成为表结构
关系型数据库的优点
- 容易理解:二维表结构是非常贴近逻辑世界的一个概念,关系模型相对网状、层次等其他模型来说更容易理解
- 使用方便:通用的SQL语言使得操作关系型数据库非常方便
- 易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率
- ACID,多表关联,复杂的数据分析类SQL查询。
- 事务处理—保持数据的一致性;
- 由于以标准化为前提,数据更新的开销很小(相同的字段基本上只有一处);
- 可以进行Join等复杂查询
虽然关系型数据库已经在业界的数据存储方面占据不可动摇的地位,但是由于其天生的几个限制,使其很难满足上面这几个需求
- 扩展困难:由于存在类似Join这样多表查询机制,使得数据库在扩展方面很艰难;
- 读写慢:这种情况主要发生在数据量达到一定规模时由于关系型数据库的系统逻辑非常复杂,使得其非常容易发生死锁等的并发问题,所以导致其读写速度下滑非常严重;
- 成本高:企业级数据库的License价格很惊人,并且随着系统的规模,而不断上升;
- 有限的支撑容量:现有关系型解决方案还无法支撑Google这样海量的数据存储;
关系型数据库瓶颈
高并发读写需求:网站的用户并发性非常高,往往达到每秒上万次读写请求,对于传统关系型数据库来说,硬盘I/O是一个很大的瓶颈(随机I/O);
海量数据的高效率读写:网站每天产生的数据量是巨大的,对于关系型数据库来说,在一张包含海量数据的表中查询,效率是非常低的;
高扩展性和可用性:在基于web的结构当中,数据库是最难进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,数据库却没有办法像web server和app server那样简单的通过添加更多的硬件和服务节点来扩展性能和负载能力。对于很多需要提供24小时不间断服务的网站来说,对数据库系统进行升级和扩展 是非常痛苦的事情,往往需要停机维护和数据迁移。
对网站来说,关系型数据库的很多特性不再需要了:
事务一致性:关系型数据库在对事物一致性的维护中有很大的开销,而现在很多web2.0系统对事物的读写一致性都不高
读写实时性:对关系数据库来说,插入一条数据之后立刻查询,是肯定可以读出这条数据的,但是对于很多web应用来说,并不要求这么高的实时性,比如发一条消息之后,过几秒乃至十几秒之后才看到这条动态是完全可以接受的
复杂SQL,特别是多表关联查询:任何大数据量的web系统,都非常忌讳多个大表的关联查询,以及复杂的数据分析类型的复杂SQL报表查询,特别是SNS类型的网站,从需求以及产品阶级角度,就避免了这种情况的产生。往往更多的只是单表的主键查询,以及单表的简单条件分页查询,SQL的功能极大的弱化了
SNS (Social Networking Services 社交网络服务)专指社交网络服务,包括了社交软件和社交网站。
CIO (Chief Information Officer 首席信息官)
在关系型数据库中,导致性能欠佳的最主要原因是多表的关联查询,以及复杂的数据分析类型的复杂SQL报表查询。为了保证数据库的ACID特性,我们 必须尽量按照其要求的范式进行设计,关系型数据库中的表都是存储一个格式化的数据结构。每个元组字段的组成都是一样,即使不是每个元组都需要所有的字段, 但数据库会为每个元组分配所有的字段,这样的结构可以便于表与表之间进行链接等操作,但从另一个角度来说它也是关系型数据库性能瓶颈的一个因素。
二、NoSQL
NoSQL一词首先是Carlo Strozzi在1998年提出来的,指的是他开发的一个没有SQL功能,轻量级的,开源的关系型数据库。这个定义跟我们现在对NoSQL的定义有很大的 区别,它确确实实字如其名,指的就是“没有SQL”的数据库。但是NoSQL的发展慢慢偏离了初衷,我们要的不是“no sql”,而是“no relational”,也就是我们现在常说的非关系型数据库了。
2009年初,Johan Oskarsson举办了一场关于开源分布式数据库的讨论,Eric Evans在这次讨论中再次提出了NoSQL一词,用于指代那些非关系型的,分布式的,且一般不保证遵循ACID原则的数据存储系统。Eric Evans使用NoSQL这个词,并不是因为字面上的“没有SQL”的意思,他只是觉得很多经典的关系型数据库名字都叫“**SQL”,所以为了表示跟这些关系型数据库在定位上的截然不同,就是用了“NoSQL“一词。
注:数据库事务必须具备ACID特性,ACID是Atomic原子性,Consistency一致性,Isolation隔离性,Durability持久性。
非关系型数据库提出另一种理念,例如,以键值对存储,且结构不固定,每一个元组可以有不一样的字段,每个元组可以根据需要增加一些自己的键值对,这 样就不会局限于固定的结构,可以减少一些时间和空间的开销。使用这种方式,用户可以根据需要去添加自己需要的字段,这样,为了获取用户的不同信息,不需要 像关系型数据库中,要对多表进行关联查询。仅需要根据id取出相应的value就可以完成查询。但非关系型数据库由于很少的约束,他也不能够提供像SQL 所提供的where这种对于字段属性值情况的查询。并且难以体现设计的完整性。他只适合存储一些较为简单的数据,对于需要进行较复杂查询的数据,SQL数 据库显的更为合适。
为何要使用NoSQL数据库
NoSQL具有灵活的数据模型,可以处理非结构化/半结构化的大数据
面对丰富多样的数据,构建的应用需要使用非常灵活的数据存储系统,能够轻松容纳新的数据类型,并且不会被第三方数据提供商内容结构的变化所累。NoSQL提供的数据模型则能很好地满足这种需求。通过这种灵活性存储数据而无需修改表或是创建更多的列。非常适合于创建原型或是快速应用,这种灵活性使得新特性的开发变得非常容易。
NoSQL很容易实现可伸缩性(向上扩展与水平扩展)
RDBMS是中心化的,向上扩展而非水平扩展的。这使得他们不适合于那些需要简单且动态可伸缩性的应用。NoSQL数据库从一开始就是分布式、水平扩展的,因此非常适合于互联网应用分布式的特性。
动态模式
关系型数据库需要在添加数据前先定义好模式。这对于敏捷开发模式来说是场灾难,因为每次完成新特性时,数据库的模式通常都需要改变。
自动分片
NoSQL数据库通常都支持自动分片,这意味着他们本质上就会自动在多台服务器上分发数据,应用甚至都不知道这些事情。数据与查询负载会自动在多台服务器上做到平衡,当某台服务器当机时,它能快速且透明地被替换掉。
复制
大多数NoSQL数据库也支持自动复制,这意味着你可以获得高可用性与灾备恢复功能。从开发者的角度来看,存储环境本质上是虚拟化的。
易扩展
NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。也无形之间,在架构的层面上带来了可扩展的能力。
大数据量,高性能
NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。一般MySQL使用Query Cache,每次表的更新Cache就失效,是一种大粒度的Cache,在针对web2.0的交互频繁的应用,Cache性能不高。而NoSQL的Cache是记录级的,是一种细粒度的Cache,所以NoSQL在这个层面上来说就要性能高很多了。
灵活的数据模型
NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦。这点在大数据量的web2.0时代尤其明显。
高可用
NoSQL在不太影响性能的情况,就可以方便的实现高可用的架构。比如Cassandra,HBase模型,通过复制模型也能实现高可用。
简单的扩展:典型例子是Cassandra,由于其架构是类似于经典的P2P,所以能通过轻松地添加新的节点来扩展这个集群;
快速的读写:主要例子有Redis,由于其逻辑简单,而且纯内存操作,使得其性能非常出色,单节点每秒可以处理超过10万次读写操作;
低廉的成本:这是大多数分布式数据库共有的特点,因为主要都是开源软件,没有昂贵的License成本;
但瑕不掩瑜,NoSQL数据库还存在着很多的不足,常见主要有下面这几个:
不提供对SQL的支持:如果不支持SQL这样的工业标准,将会对用户产生一定的学习和应用迁移成本;
支持的特性不够丰富:现有产品所提供的功能都比较有限,大多数NoSQL数据库都不支持事务,也不像MS SQL Server和Oracle那样能提供各种附加功能,比如BI和报表等;
现有产品的不够成熟:大多数产品都还处于初创期,和关系型数据库几十年的完善不可同日而语;
成熟度
RDBMS系统由来已久。NoSQL拥护者们会说RDBMS的高龄是其衰退的标志,不过对于大多数CIO来说,RDBMS的成熟让人放心。对于大多数情况来说,RDBMS系统是稳定且功能丰富的。相比较而言,大多数NoSQL数据库则还有很多特性有待实现。
支持
企业需要的是安心,如果关键系统出现了故障,他们可以获得即时的支持。所有RDBMS厂商都在不遗余力地提供良好的企业支持。与之相反,大多数NoSQL系统都是开源项目,虽然每种数据库都有那么几家公司提供支持,不过这些公司大多都是小的初创公司,没有全球支持资源,也没有Oracle、微软或是IBM那种令人放心的公信力。
分析与商业智能
NoSQL数据库在Web 2.0应用时代开始出现。因此,大多数特性都是面向这些应用的需要的。然而,应用中的数据对于业务来说是有价值的,这种价值远远超出了Web应用那种CRUD。企业数据库中的业务信息可以帮助改进效率并提升竞争力,商业智能对于大中型企业来说是个非常关键的IT问题。
管理
NoSQL的设计目标是提供零管理的解决方案,不过当今的现实却离这个目标还相去甚远。现在的NoSQL需要很多技巧才能用好,并且需要不少人力、物力来维护。
适合使用NoSQL场景
数据库表schema经常变化
比如在线商城,维护产品的属性经常要增加字段,这就意味着ORMapping层的代码和配置要改,如果该表的数据量过百万,新增字段会带来额外开销(重建索引等)。NoSQL应用在这种场景,可以极大提升DB的可伸缩性,开发人员可以将更多的精力放在业务层。
数据库表字段是复杂数据类型
对于复杂数据类型,比如SQL Sever提供了可扩展性的支持,像xml类型的字段。很多用过的同学应该知道,该字段不管是查询还是更改,效率非常一般。主要原因是是DB层对xml字段很难建高效索引,应用层又要做从字符流到dom的解析转换。NoSQL以json方式存储,提供了原生态的支持,在效率方便远远高于传统关系型数据库。
高并发数据库请求
此类应用常见于web2.0的网站,很多应用对于数据一致性要求很低,而关系型数据库的事务以及大表join反而成了”性能杀手”。在高并发情况下,sql与no-sql的性能对比由于环境和角度不同一直是存在争议的,并不是说在任何场景,no-sql总是会比sql快。有篇article和大家分享下,http://artur.ejsmont.org/blog/content/insert-performance-comparison-of-nosql-vs-sql-servers
海量数据的分布式存储
海量数据的存储如果选用大型商用数据,如Oracle,那么整个解决方案的成本是非常高的,要花很多钱在软硬件上。NoSQL分布式存储,可以部署在廉价的硬件上,是一个性价比非常高的解决方案。
非关系型数据库分类
由于非关系型数据库本身天然的多样性,以及出现的时间较短,因此,不想关系型数据库,有几种数据库能够一统江山,非关系型数据库非常多,并且大部分都是开源的。
这些数据库中,其实实现大部分都比较简单,除了一些共性外,很大一部分都是针对某些特定的应用需求出现的,因此,对于该类应用,具有极高的性能。依据结构化方法以及应用场合的不同,主要分为以下几类:

面向高性能并发读写的key-value数据库:
key-value数据库的主要特点即使具有极高的并发读写性能,Redis,Tokyo Cabinet,Flare就是这类的代表
面向海量数据访问的面向文档数据库:
这类数据库的特点是,可以在海量的数据中快速的查询数据,典型代表为MongoDB以及CouchDB
面向可扩展性的分布式数据库:
这类数据库想解决的问题就是传统数据库存在可扩展性上的缺陷,这类数据库可以适应数据量的增加以及数据结构的变化
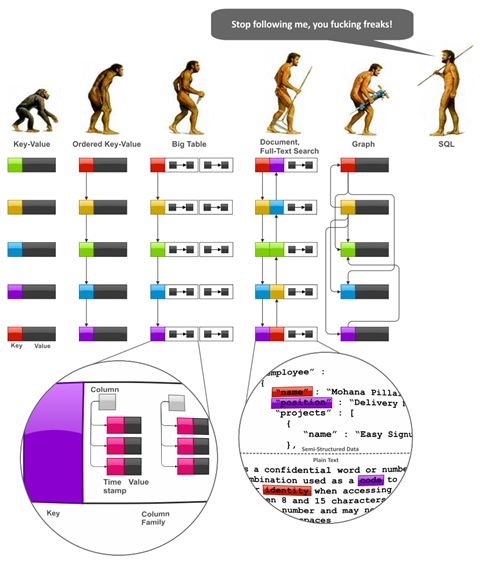
三、RDBMS VS NoSQL
关系型数据库的最大特点就是事务的一致性:传统的关系型数据库读写操作都是事务的,具有ACID的特点,这个特性使得关系型数据库可以用于几乎所有对一致性有要求的系统中,如典型的银行系统。
但是,在网页应用中,尤其是SNS应用中,一致性却不是显得那么重要,用户A看到的内容和用户B看到同一用户C内容更新不一致是可以容忍的,或者 说,两个人看到同一好友的数据更新的时间差那么几秒是可以容忍的,因此,关系型数据库的最大特点在这里已经无用武之地,起码不是那么重要了。
相反地,关系型数据库为了维护一致性所付出的巨大代价就是其读写性能比较差,而像微博、facebook这类SNS的应用,对并发读写能力要求极 高,关系型数据库已经无法应付(在读方面,传统上为了克服关系型数据库缺陷,提高性能,都是增加一级memcache来静态化网页,而在SNS中,变化太 快,memchache已经无能为力了),因此,必须用新的一种数据结构存储来代替关系数据库。
关系数据库的另一个特点就是其具有固定的表结构,因此,其扩展性极差,而在SNS中,系统的升级,功能的增加,往往意味着数据结构巨大变动,这一点关系型数据库也难以应付,需要新的结构化数据存储。
于是,非关系型数据库应运而生,由于不可能用一种数据结构化存储应付所有的新的需求,因此,非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合。
必须强调的是,数据的持久存储,尤其是海量数据的持久存储,还是需要一种关系数据库这员老将。
