趣头条百PB规模 Hadoop实践(HDFS篇)
HDFS实践
- 文章背景
- NameNode负载和扩展性问题
- 拆RPC端口以及拆NameSpace组成Federation
- Balancer负载转移和搬迁优化
- 拆分日志相关的NameSpace降低负载
- NameNode用户的拥塞控制
- 异步化各种操作提高NameNode的吞吐量
- 块汇报的优化
- NameNode锁时间追踪
- Decommission的改进
- Qos保障,业务控制,限流以及作业追踪
- 软限制和作业追踪
- 硬限制:NameNode源码改动
- 用户体验和运维便利性
- 自研 HDFS Proxy
- HDFS Router 改进和二次开发
- Router审计日志的完善和作业追踪
- Router Trash重构和RPC优化
- Router 支持全局Quota管控
- Router rename across Federation
- HDFS目录实时解析
- 服务的稳定性和性能
- DataNode DU导致IO重和重启Uncached问题
- 存储从DU改为内存计算
- 解决重启Uncached问题
- 慢节点和读写长尾优化
- DataNode锁优化之旅
- Synchronized非公平锁改为ReentrantLock公平锁
- ReentrantLock公平锁拆成公平的读写锁
- 拆分成以BlockPool为单位的细粒度读写锁
- 最终目标,最小单位的锁
- DataNode 接受指令异步化
- DataNode IO和锁分离
- 进行中的和未来规划
文章背景
趣头条数据量达到了百PB级别,本文分享一下趣头条的HDFS相关实践。
NameNode负载和扩展性问题
拆RPC端口以及拆NameSpace组成Federation
针对NameNode单点瓶颈,在把NameNode拆分成Client RPC端口和Service RPC端口后,推进了HDFS Federation的架构,原因是NameNode单点存在元数据量激增的问题,也存在NameNode RPC负载激增的问题。
针对Federation之间的数据迁移引入FastCopy:
如下图所示:
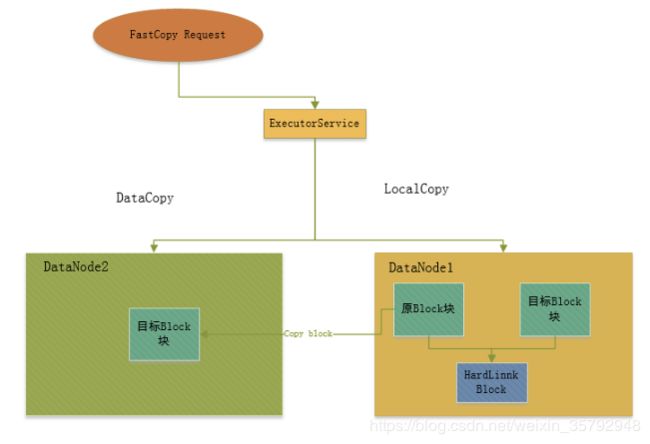
针对大数据量的Federation各个NameSpace之间的拷贝,比Distcp提升3倍左右的效率。
Balancer负载转移和搬迁优化
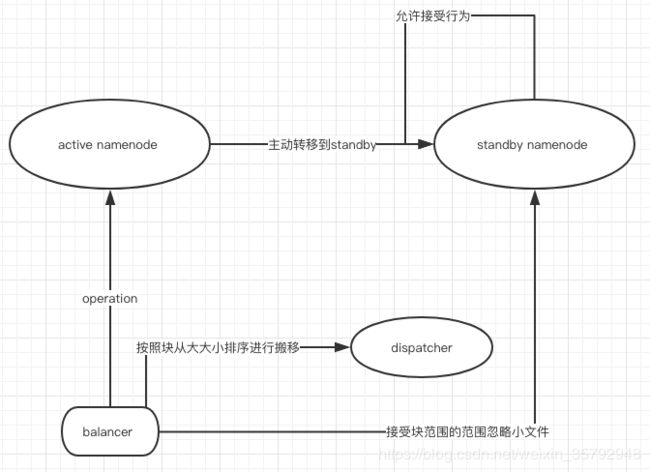
拆分成Federation架构之后,HDFS Balancer 操作对Active NameNode造成了很大对负载,为此我们把Balancer操作的负载转移到了standby上面,从而降低了Active NameNode的RPC负载。
具体把Balancer负载转移到Standby NameNode思想和社区最新的HDFS读写分离思想是一致的,读写分离HDFS社区具体的Issue为:HDFS-12943 ,而对应的Balancer转移到了ObserverNode的patch为: HDFS-14162。而我们的版本还不支持读写分离的功能,为了快速降低负载,我们把Balancer对Active NameNode的RPC主动抛异常到了Standby NameNode,并且让Standby NameNode对Balancer放行。
搬迁的时候忽略小的块,按照从大到小到顺序降序,增加搬迁的速度。
具体如下图:
拆分日志相关的NameSpace降低负载
有了HDFS Federation架构以后,日志还是会和业务的NameSpace互相产生影响,为此我们把defaultFs修改成系统单独的NameSpace。我们也向Hadoop YARN社区贡献了针对提交目录,日志聚合目录可以负载均衡到各个NameSpace的设想,具体Issue见:YARN-9634。
NameNode用户的拥塞控制

社区提出了FairCallQueue ,如上图所示,原有的FIFO的RPC结构,改成了Fair的结构,来对高频率的单账户进行缓解和限制,详细issue见:HADOOP-10282。应用以后,有效的隔离了Presto等即使查询用户并发量聚集时候,对HDFS其他线上业务的影响。
目前我们使用了FairCallQueue + RPC Backoff, 能满足我们拥塞控制的需求。有效限制了异常高负载的用户对整体RPC可用性的影响。
针对用户较多的NameSpace我们正准备进行用户优先级分更多层级,进行多层的Qos保障。
异步化各种操作提高NameNode的吞吐量
editlog和auditlog的异步化
原先版本的NameNode的editlog的行为和auditlog的行为都是同步阻塞的,这对NameNode的吞吐量影响很大,为此我们把这editlog和auditlog两个行为改成了异步化。
块汇报的优化
数据量越来越大以后,对NameNode的堆栈信息统计后发现,块汇报的压力对用户的影响较大,为此我们考虑对块汇报进行了优化。首先全量块汇报的时候加盐,分散整体汇报对NameNode的压力。然后增量汇报的时候进行如下优化:
首先把NameNode端的块汇报异步进行聚合,有效的缓解了RPC的压力,对应的Issue为:HDFS-9198。
然后相应的DataNode端的块汇报也进行了批量聚合,对应Issue为:HDFS-9710。
NameNode锁时间追踪
HDFS-10872 添加了NameNode锁住时间对应的Metrics。NameNode的锁队列长度堆积过高的时候,我们增加了全局锁对应的锁住时间,对某些锁占用时间过长的情况,进行分析,对很多锁优化对细节很有帮助。
Decommission的改进
大集群的Decommission操作非常常见,如机器迁移下线,机器故障需要下线等。而旧的Decommssion代码存在如下的问题:
- 遍历每个节点,对每个disk进行遍历,负载集中,没有分布到各个节点和各个磁盘,会导致命中的那个磁盘非常热。
- 通过上述NameNode的锁时间追踪发现,加入一个DataNode进行下线,会占用较长时间的写锁。
- replica队列堆积的问题。
- 等待复制队列多次判断是否replica,会重复占用写锁的时间。
社区最近也有了更完善的实现:HDFS-14854。
Qos保障,业务控制,限流以及作业追踪
软限制和作业追踪
针对访问过高的用户,进行审计增强,目前的审计日志无法获取用户的作业信息。某些异常作业对某些治理不够完善的大表的疯狂访问等等行为,会对集群造成很大的稳定性和性能影响。为此我们引入了审计增强。
这一块需要改的比较多包括计算引擎,以及YARN,HDFS都需要改一些依赖的Patch,主要有:
HDFS相关:HDFS-9184。
YARN相关:YARN-4349。
HIVE相关:HIVE-12254。
SPARK相关:SPARK-15857。
Flink 还没有CallerContext内置,我们提了个Issue,待完善:FLINK-16809。
Flink入库对HDFS的压力还是非常大的,加上业务滥用,有很严重的小文件问题见FLINK-11937。
这样审计日志中就有了关键的作业信息,然后通过打到Kafka,Flink做实时分析,就能很容易的定位到HDFS高负载的作业。
硬限制:NameNode源码改动
另外一种硬的方式,不做事后分析,做事前强限制:
上述提到过拥塞控制是用户对应的拥塞控制,这里对目录进行硬限制,因为除了不合理的用户的高频访问,还存在大表或者治理非常不完善的目录或者库表,可以做QPS限制,可以针对如create,delete等操作,在NameNode代码里对相关的目录对应的RPC做窗口的统计,如果QPS大于阈值则对客户端返回一个重试信息,进行限流。
用户体验和运维便利性
自研 HDFS Proxy
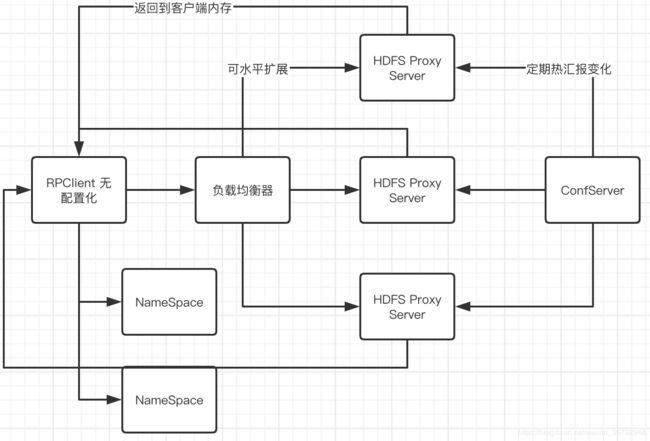
由于历史原因导致,很多算法等业务需要独立的客户端进行管理,而业务的激增导致了客户端配置的频繁更新造成了很大的人力运维成本。且客户端的种类过于繁多,例如调度客户机,容器化的调度客户机,普通gateway等等。为了实现配置转移到了服务端进行控制,我们开发了HDFS Proxy,客户端无需配置,Hdfs Client 将请求转发到对应的HDFS Proxy Server。Proxy 可以横向扩展,上面挂了一层负载均衡器。非常轻量级,已经使用了将近半年,由于viewFs客户端维护方式很不利于运维管理,且我们当前版本比较老,且Router不够成熟,主要用于和Router进行过渡。
具体结构如下图所示:
HDFS Router 改进和二次开发
随着Router的成熟,和我们对Router进行了一些定制化的改进,我们慢慢从我们轻量级的HDFS Proxy切换到Router,毕竟开源的力量是伟大的,我们也要站在巨人的肩膀上。
Router审计日志的完善和作业追踪
Router本身对AuditLog支持对不好,为此我们增加了定制对AuitLog,并且准备继续在Router这一层对任务进行追踪。在Router层实现软限制和作业追踪。
Router Trash重构和RPC优化
针对数据成本优化,我们做了Hive生命周期的项目,每天都有大量的Trash操作。
Router对Trash的支持很不好,社区有类似客户端的修改方案,但是很不友好,为此我们对Trash操作进行了重构,增加的新的RPC调用。
重构后不仅解决了Router中对应多个NameSpace的删除操作。还把之前的Trash对NameNode的RPC负载降低了50%,客户端从(mkdir rename) -> trash。
这一块也贡献给了社区,待完善:HDFS-15083。
Router 支持全局Quota管控
如果单个目录挂载了多个NameSpace,Router目前也支持了全局的Quota管控,但还有部分细节需要完善。
Router rename across Federation
针对Federation的各个NameSpace之间的FastCopy上述有做了介绍,Router有个功能可以实现类似FastMove的功能,针对跨NameSpace的已挂载的目录,可以进行rename到其他NameSpace。
HDFS目录实时解析
HDFS的目录信息解析,需要从FSImage进行解析,集群大了以后,我们FSImage达到几十上百G,解析过程相当缓慢,只能以 T+1的方式进行解析。
为此,我们开发了准实时的解析项目,来应对,例如:短时间内存储增量巨大的目录,小文件数量剧增的目录。
聚合策略:利用EditLog的操作码,通过实时流,利用Tidb或者Durid等进行准实时聚合。
操作数种类比较多,主要追踪的操作有:OP_DELETE, OP_MKDIR, OP_ADD, OP_UPDATE_BLOCKS, OP_CLOSE, OP_RENAME_OLD。
服务的稳定性和性能
由于Federation架构8组业务的NameSpace共享同一个DataNode底层服务,加上本身我们的机型磁盘块很多,且业务的复杂性多样性对DataNode的访问,NameNode的压力转移到了DataNode上面。
DataNode DU导致IO重和重启Uncached问题
存储从DU改为内存计算
DataNode默认使用DU对存储总量进行汇总给 NameNode,DU操作对DataNode的IO压力比较大,且DataNode的IO没有和全局锁进行分离,IO也会占用锁的时间。DU对IO压力大的解决方案有多种,分散DU的时间加个随机数然后分布到各个节点,减缓整体的IO,但是无法避免还是需要DU操作。
针对磁盘的DU,我们把存储总量的计算放到了内存里,因为内存里本身有磁盘块的信息,通过内存数据结果进行定期计算。具体最新的Issue:HDFS-9710。
解决重启Uncached问题
DataNode滚动的时候,经常会有ungraceful shutdown的情况,会导致存储量的缓存没有缓存到本地,那么启动的时候就会重复去计算,针对DU的场景会导致重启时间变得很长,为此我们加了定时线程对缓存进行更新,重启的时候就不用去重新计算存储总量了。具体Issue见:HDFS-15171。
慢节点和读写长尾优化
当集群节点日益增长当时候,很容易产生DataNode节点老化导致磁盘或者网络IO慢等其他问题,这就会造成用户的读写长尾等问题。
DataNode端的metrics收集: HDFS-10917慢节点监控,然后心跳汇报给NameNode:HDFS-11194。
除了DataNode的慢节点监控,以及NameNode汇总慢节点信息,也能从客户端去监控读写速度以及读写长尾的DataNode节点,这一块社区也有对应的实现,有待完善:HDFS-12861。
开启客户端并发读:
针对慢读取另起一个线程并发读,线程池的大小
dfs.client.hedged.read.threadpool.size
慢读取的阈值
dfs.client.hedged.read.threshold.millis (默认是500)
写慢节点:
写慢节点的时候,配合慢节点的情况,做快速的PipeLine Recovery。
DataNode锁优化之旅
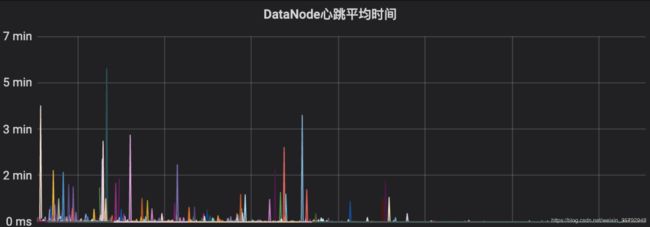
业务量激增导致8组NameNode的负载都打到了DataNode,突然出现DataNode心跳时间陡增到数分钟,导致心跳没有即时收到,DataNode经常在高峰期批量Dead,对业务造成了很严重的影响。
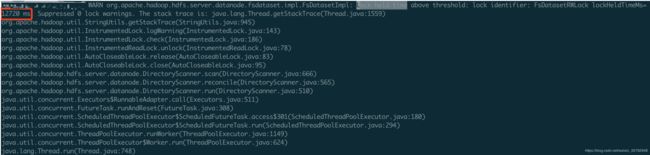
为此我们分析的DataNode的堆栈情况,发现是由于DataNode心跳的全局锁被其他并发过高的读写等操作占用,导致关键心跳线程被Blocked住。
Synchronized非公平锁改为ReentrantLock公平锁
首先,我们把DataNode的Synchronized非公平锁改成了,ReentrantLock默认为公平锁。
ReentrantLock公平锁拆成公平的读写锁
针对全局的可重入ReentrantLock,拆成了读写锁,效果很好,堵住几千个线程缓解了很多。

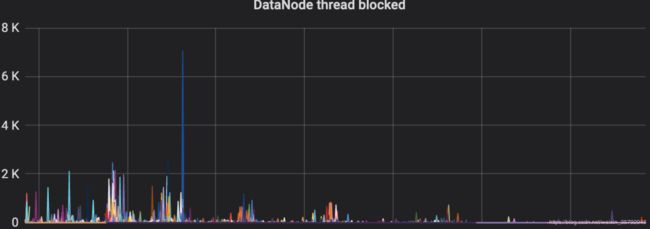
拆分成以BlockPool为单位的细粒度读写锁
继续拆锁,拆分成以BlockPool为单位的读写锁,意味着,如果你有8组NameSpace的话,一个DataNode全局锁,可以拆分成8把锁。
我在社区提了个Issue:HDFS-15180。
从灰度的节点看,锁的进一步拆分,带来了预期的效果,没有拆分之前,Directory Scan扫描操作会占用较长的锁时间,经常长达10几秒,甚至几十秒:
滚动以后,因为每个BlockPool单独扫描,锁住时间降低到2s, 1s,甚至更小。

HDFS的存储量计算,从DU改为内存计算以后,内存中的deepcopy部分本身会占用较长的锁时间超过 300ms,拆分为BlockPool锁以后,没有超过300ms的情况出现。
拆分前有超过300ms的情况较多:

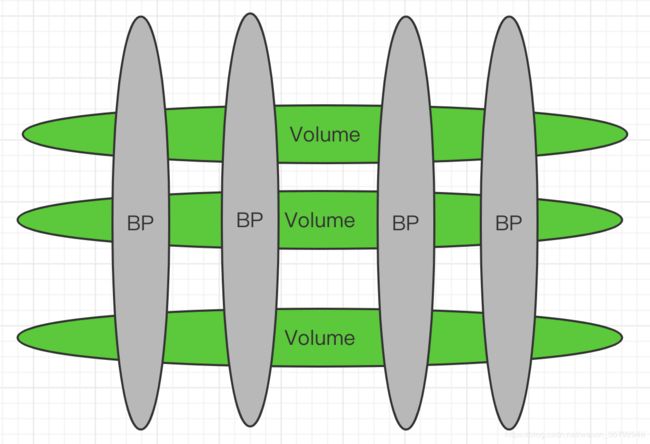
最终目标,最小单位的锁
最终目标,一个Volume中对应的BlockPool单位拆成一把锁。如下图所示,如果HDFS Federation有4组NameSpace,每个DataNode有3个磁盘块。那么就对应了4个BlockPool(BP),和3个Volume,原生的DataNode全局锁是一把锁,理想的情况下,在这个例子情况下是可以拆分成为4*3 = 12 把读写锁,对应锁住的范围就是两个椭圆的交接重合部分。
目前我们已经拆成了BlockPool为单位,对应到这个例子就是4把读写锁,对性能的提升效果不错。
DataNode 接受指令异步化
我们查看日志的时候发现,DataNode接受指令的时候,会把心跳线程给阻塞住,为此把阻塞的线程改成异步的线程池去处理这个指令操作,这样不会把心跳线程给堵住。
如下图所示,修改之前,心跳阻塞时间可以达到几十秒。
![]()
DataNode IO和锁分离
DataNode的IO操作,有时候会占用很长的锁时间,为此我们正准备把IO和锁进行分离。
进行中的和未来规划
- 我们在测试环境已经测试了Hadoop3的新功能,准备在新集群迁移的时候使用,完成Hadoop2到Hadoop3的升级 。
- Router还有很多功能正在不断完善。
- 为了解决NameNode读占比大的问题,我们准备对Hadoop3尝试读写分离功能,把读转移到Standby NameNode。
- 持续跟进新功能:
1. NameNode分段锁:HDFS-14703 , 解决NameNode锁吞吐量的问题。
2. Ozone,解决小文件,和NameNode扩展性的问题,数据存储底层也是用的DataNode。看了部分Ozone在开发中的代码,有个存储原地改变的功能还在开发中,DataNode的数据直接从HDFS转成Ozone,很不错的功能,可能还有其他惊喜。
3. EC的冷存储和公有云OSS的冷存储,成本和性能进行对比。
4. HDFS操作全面异步化: HDFS-9924。
5. NameNode启动时间优化。
欢迎业内交流:
微信: zhu821684824
Apache Jira: https://issues.apache.org/jira/secure/ViewProfile.jspa?name=zhuqi
邮箱:
[email protected]
[email protected]