论文笔记:Multi-Label Zero-Shot Learning with Structured Knowledge Graphs
来源:CVPR-2018,台湾国立&CMU,paper
概述
- 问题描述:针对每一个输入预测多个见过的和没见过的标签
- motivation:人类利用兴趣物体之间的语义信息的方式。提出了一个结合知识图谱的框架来描述多标签之间的关系。
- 模型中学习了一种在语义标签空间的信息传播方式,以此来建模见过的和没见过的label之间的相互依赖。
Introduction
- 自然图片的标注工作要求神经网络应该具有多标签的识别能力,这不仅需要将image与多标签关联起来,同时也需要发掘标签之间的关系,因为兴趣标签(labels of interest)是经常共同出现的。
- 目前对于多标签标注的工作:
- 二元相关性的分类建模:缺乏建模label共同出现的能力
- 通过假设标签先验来衡量label之间的关联的方法
- 基于label-embedding将images和labels映射到潜在的空间中去发现label之间的关联
- BPPMLL首次提出使用loss函数建模label之间的依赖关系
- 多标签与zero-shot(ML-ZSL)
- 关键点在于预测出训练过程中并未定义的标签
- 二元相关性或者增加先验的方法是不适用的,因为他们无法产生出新的模型;但label-embedding的方法是可以使用的,只需要给出没见过的label的representation
- 目前提出的方法中很少关注到结构化知识和推理带来的优势
- 人类识别物体并不只是通过他们的外形,还会使用他们通过经验学到的关于世界的知识。基于这样的思考,使用知识图谱建模共同出现的和未共同出现的概念,可将利用外部的结构化的知识图谱,并且将知识扩展到没见过的类别。
- 目前工作没有将结构化的知识推理应用到ML-ZSL领域
- 本文方法:
- 通过语义向量表示label
- 通过在label空间中观察label之间的关系学习一种传播机制,来修改初始化后的不同class label之间关系的表达
- 通过传播机制完成推理过程
- 使用了来自WordNet的结构化知识图谱
Related Work
文章首先分析了多标签的分类任务,同Introduction。然后介绍了建模label之间相互依赖关系的方法——通过利用label之间语义关系。
- Hierarchy and Exclusion(HEX) graph:考虑了label语义中的相互排斥、交叉和包含的关系。之后模型被拓展到加入soft或者不确定的关系。
- Structured Inference Neural Network(SINN):收到RNN的启发,正向关系和负向关系通过在概念层的双向信息传播得到。
- Graph Gated Neural Networks (GGNN):使用周期门控单元Gated Recurrent Units(GRU) 完成图上的信息传播,直到Graph Search Neural Network (GSNN) 才完成了多标签分类任务中以结构化知识的形式对语义关系的发掘*(注意这里没有适应zero-shot场景)*
以上方法都没有对zero-shot场景的应用,接下来作者描述了zero-shot中对于多标签分类的一些方法: - COSTA:假设了共同出现的统计结果,同时通过对见过的class的结果的加权组合来评价针对见过的标签的分类器效果。
- 将所有可能的标签列出然后转化为一份zero-shot分类问题。
- 考虑embedding的方法得到label对应的图像语义信息,针对subregions和它对应的标签形成一个空间映射。
- 考虑使用图模型,针对同时出现和不同时出现的matrix进行建模分析
Approach
使用 D = { ( x i , y i ) } i = 1 N \mathcal{D}=\{(\mathbf{x}^i,\mathbf{y}^i)\}_{i=1}^{N} D={(xi,yi)}i=1N 表示训练的实例集合, x i ∈ R d f e a t \mathbf{x}^i\in\mathbb{R}^{d_feat} xi∈Rdfeat 是 d f e a t d_{feat} dfeat 维的特征向量, y i ∈ { 0 , 1 } ∣ S ∣ \mathbf{y}^i\in\{0,1\}^{|S|} yi∈{0,1}∣S∣ 是相应的标签集合 S S S 中的标签。 N N N 是训练实例的个数, ∣ S ∣ |S| ∣S∣ 是见过的标签的数量。给定 D D D 和 S S S,多标签的分类任务可以定义为:学习一个模型,能够准确预测测试实例 x ^ i ∈ R d f e a t \hat{\mathbf{x}}^i\in\mathbb{R}^{d_feat} x^i∈Rdfeat 的标签 y ^ i ∈ { 0 , 1 } ∣ S ∣ \hat{\mathbf{y}}^i\in\{0,1\}^{|S|} y^i∈{0,1}∣S∣。
对于ML-ZSL问题,有没见过的标签集合 U \mathcal{U} U ,目标就是对于 S \mathcal{S} S 和 U \mathcal{U} U 中的所有测试实例 x ^ \hat{\mathbf{x}} x^ 能够准确地预测其标签。这样的标签集合是 y ~ i ∈ { 0 , 1 } ∣ S ∣ + ∣ U ∣ \tilde{\mathbf{y}}^i\in\{0,1\}^{|\mathcal{S}|+|\mathcal{U}|} y~i∈{0,1}∣S∣+∣U∣。因为训练时图片中并不包含 U \mathcal{U} U 集合中的标签,因此ML-ZSL需要从观测到的标签空间中提取信息,论文中使用了分布式的词嵌入来用一个语义向量来表示一个类别标签,即 W = { w v } v = 1 ∣ S ∣ + ∣ U ∣ \mathbf{W}=\{\mathbf{w}_v\}_{v=1}^{|\mathcal{S}|+|\mathcal{U}|} W={wv}v=1∣S∣+∣U∣ 。本文中使用了 GloVe(?) 的方法建立词嵌入空间, w v ∈ R d e m b , d e m b = 300 \mathbf{w}_v\in\mathbb{R}^{d_{emb}}, d_{emb}=300 wv∈Rdemb,demb=300。

在构建的结构化知识图谱中,将所有 label 作为节点,初始的节点表示通过 F I \mathbf{F}_{I} FI 输入,通过图传播 T T T 步最终达到稳定,得到输出 F O \mathbf{F}_{O} FO 。其中,图中所有节点之间的链接权重通过关联函数 F R k \mathbf{F}_{R}^{k} FRk 得到,这个函数接收相邻标签的嵌入向量 w u \mathbf{w}_{u} wu 和 w v \mathbf{w}_{v} wv 作为输入,给出链接权重 a v u a_{vu} avu。
结构化知识图谱在神经网络中的传播
仿照递归神经网络中的递归门控更新机制(GSNN),设置每一个时间步 t 都有一个 belief state 向量 h v ( t ) ∈ R d h i d h_{v}^{(t)}\in\mathbb{R}^{d_{hid}} hv(t)∈Rdhid ,根据之前的实验设置,这里 d h i d = 5 d_{hid}=5 dhid=5。通过一个神经网络建模得到初始的创建输入 h v ( 0 ) = F I ( x , w v ) \mathbf{h}_{v}^{(0)}=\mathbf{F}_{I}(\mathbf{x},\mathbf{w}_{v}) hv(0)=FI(x,wv)。之后通过图的邻接矩阵就能结合考虑每一个节点的相邻节点信息,从而更新 通过 Gated Recurrent Unit(GRU) 机制更新belief state。
(1) h v ( 0 ) = F I ( x , w v ) \mathbf{h}_{v}^{(0)}=\mathbf{F}_{I}\left(\mathbf{x},\mathbf{w}_{v}\right)\tag{1} hv(0)=FI(x,wv)(1)
(2) u v ( t ) = t a n h ( A v T [ h 1 ( t − 1 ) T ... h ∣ S ∣ ( t − 1 ) T ] T ) \mathbf{u}_{v}^{(t)}=tanh(\mathbf{A}_{v}^{T}[\mathbf{h}_{1}^{(t-1)T}\text{ ... }\mathbf{h}_{|\mathcal{S}|}^{(t-1)T}]^{T})\tag{2} uv(t)=tanh(AvT[h1(t−1)T ... h∣S∣(t−1)T]T)(2)
(3) h v ( t ) = G R U C e l l ( u v ( t ) , h v ( t − 1 ) ) \mathbf{h}_{v}^{(t)}=GRUCell(\mathbf{u}_{v}^{(t)},\mathbf{h}_{v}^{(t-1)})\tag{3} hv(t)=GRUCell(uv(t),hv(t−1))(3)
这里使用的 A v ∈ R ∣ S ∣ d h i d × d h i d \mathbf{A}_{v}\in\mathbb{R}^{|\mathcal{S}|d_{hid}\times{d_{hid}}} Av∈R∣S∣dhid×dhid 是邻接矩阵 A \mathbf{A} A 的一个子矩阵,用来表示针对于节点 v v v 的传播权重度量。
GRUCell 指GRU更新机制,表示为:

理解:通过图上的传播(加权平均)加激活得到 h \mathbf{h} h 向量的综合表现结果 u \mathbf{u} u ,这个结果用来指示更新的方向,可以看到在更新过程中是不考虑相邻节点之间的关系的。更新过程中,通过上一时间步当前节点的表现 h v ( t − 1 ) \mathbf{h}_{v}^{(t-1)} hv(t−1) 和当前时间步相邻节点的综合结果 u v ( t ) \mathbf{u}_{v}^{(t)} uv(t) 得到估计两组参数: z \mathbf{z} z 是用来最当前时间步结果和上一时间步结果做滑动平均的(为了防止每个时间步变化过大?); r \mathbf{r} r 是用来为 t + 1 t+1 t+1 时间步提供参考的,相当于每次更新保留的结果为 r v \mathbf{r}_{v} rv 和 h v \mathbf{h}_{v} hv (为了建立更长期的关联?)
更新完毕之后,通过全连接层得到最终的置信度
p v ( t ) = F O ( h v ( t ) ) p_{v}^{(t)}=\mathbf{F}_{O}(\mathbf{h}_{v}^{(t)}) pv(t)=FO(hv(t))
传播度量的学习( A v \mathbf{A}_{v} Av)
首先,在 A v \mathbf{A}_{v} Av 中,相邻节点之间的权重是非零的,不相邻节点之间的权重为0,这样保证一个节点只考虑和它相邻的节点之间的关系。
在GSNN中,结构化的知识图谱被定义了大约30种关系类型, A \mathbf{A} A 中的元素被学习到之后,相同关系类型的边在GSNN中就是固定的。文章中说这会限制实际中的应用因为只有很少的关系类型被预先定义了,因此在ML-ZSL中希望能够更好地定义label之间的关系,使得传播机制能够更有效地获取信息。
基于这样的想法,作者改变了原来的基于边的类型定义权重取值的方式,而是针对边的类型,对相同类型边使用相同的关系函数 F R k \mathbf{F}_{R}^{k} FRk 来产生传播中的权重,其中 k k k 就表示边的类型,即:
(9) a v u = F R k ( w v , w u ) \mathbf{a}_{vu}=\mathbf{F}_{R}^{k}(\mathbf{w}_{v},\mathbf{w}_{u})\tag{9} avu=FRk(wv,wu)(9)

作者说这样的建模方式(针对生成函数进行建模)是有利于泛化到没见过的类别标签的。
理解:首先,按照作者的描述GSNN中的建模方式可以认为把 F R k \mathbf{F}_{R}^{k} FRk 当作一个恒等函数处理,而现在一个很显然的好处就是赋予了type -> weight这个映射更多的可能性。其次,通过学习这样一个函数,在应对没见过的类别的时候处理方式可以很灵活,即通过函数映射从嵌入向量直接获取权重,而不是依靠人类去定义。
从ML到ML-ZSL
训练过程中使用针对每个节点标签的BCE作为loss函数
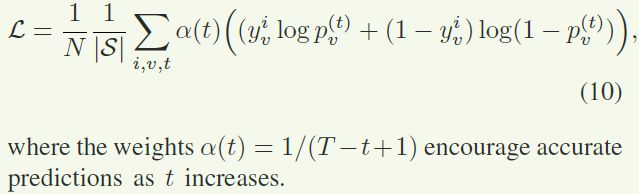
对于ML-ZSL的预测阶段,作者扩展了邻接矩阵 A \mathbf{A} A 到 A ~ ∈ R ( ∣ S ∣ + ∣ U ∣ ) d h i d × ( ∣ S ∣ + ∣ U ∣ ) d h i d \mathbf{\tilde{A}}\in\mathbb{R}^{(|\mathcal{S}|+|\mathcal{U}|)d_{hid}\times{(|\mathcal{S}|+|\mathcal{U}|)d_{hid}}} A~∈R(∣S∣+∣U∣)dhid×(∣S∣+∣U∣)dhid,这样就能在没见过的标签中也建立知识图谱上的联系。同时,作者限制 A ~ \mathbf{\tilde{A}} A~中 S \mathcal{S} S 和 U \mathcal{U} U 之间的边上只允许从见过的节点向没有见过的节点传播 ,同时,公式 ( 2 ) (2) (2)修改为:
(2) u v ( t ) = t a n h ( A ~ v T [ h 1 ( t − 1 ) T ... h ∣ S ∣ + ∣ U ∣ ( t − 1 ) T ] T ) , ∀ v ∈ S ∪ U \mathbf{u}_{v}^{(t)}=tanh(\mathbf{\tilde{A}}_{v}^{T}[\mathbf{h}_{1}^{(t-1)T}\text{ ... }\mathbf{h}_{|\mathcal{S}|+|\mathcal{U}|}^{(t-1)T}]^{T}),\forall{v}\in\mathcal{S}\cup\mathcal{U}\tag{2} uv(t)=tanh(A~vT[h1(t−1)T ... h∣S∣+∣U∣(t−1)T]T),∀v∈S∪U(2)
这样,模型就既能够计算没见过的类的初始向量也能够完成从见过的类向没见过的类(以及没见过的类之间的)图传播过程。于是就能够得到没见过的类的置信度。

实验
建立知识图谱
-
使用 WordNet 作为构建知识图谱的来源,里面包含在不同概念之间大量的语义关系。
-
在知识图谱中定义三种类型的链接:
- super-suberdinate,超级下属 (hyponymy, hypernomy,上位词下位词,ISA relation):在 WordNet 中被定义并能够很好地从 WordNet 中被提取。
- positive correlation,正相关关系:通过计算label的 WUP similarity 进行阈值限制完成,下同
- negative correlation,负相关关系
如果一对label被考虑为超级下属关系,那不并不去计算他们之间的正负相似性
-
实验中设置结构化知识图谱上的传播 steps 为5 ( T = 5 T=5 T=5)
数据集和设置
- 数据集:NUS-WIDE,Microsoft COCO
- 通过ResNet-152提取图像的2048维特征作为图片特征
多标签分类
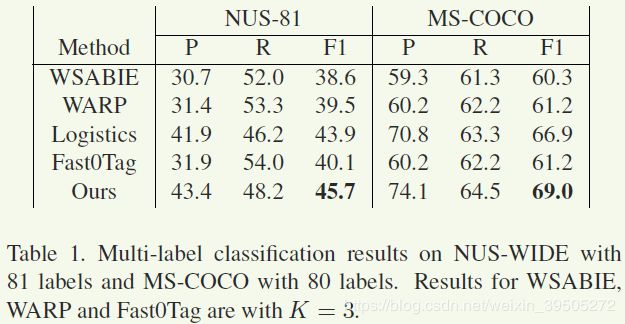
- precision和recall无法同时达到最好:作者认为可能的解释是一张图片包含的tag数量在数据集中该变化很大,所以简单的选取top K对于整个数据集而言是不合适的。但logistics回归和本文的方法给出了更有弹性的预测,相比较而言在recall和precision之间能够更好地平衡。
ML-ZSL和通用ML-ZSL

通用ML-ZSL设置:在训练完成之后在同时包含seen和unseen的label数据集测试
传播机制分析

这张图展示了针对不同的传播轮次的判断结果,可以看到
- 随着传播轮次的上升,预测结果是居于稳定而且向着真值上升的。
- 前几个传播轮次针对结果的影响程度最大,之后的轮次更像 fine-tuned 效果
作者同时展示了针对评价指标 F1 也有类似上图的稳定收敛效果。
总的来看,作者的主要贡献点在于
- 在多标签的识别领域引入的推导机制,即并不单单依靠像素之间的关系,而是将这样的特征向量上升到语义空间然后在语义空间机型推导。这样的推导是直观的,得益于知识图谱本身所提供的语义关系链接
- 针对知识图谱上的推导也进行了改进,针对不同的链接种类采用更为灵活的函数映射表示可能对相邻节点产生的影响权重,减少人为设定带来的主观性,这应该是好的出发点
反过来思考,作者这样做是不是认为这 词嵌入空间 和 像素特征空间 存在着某种一致性,即前者相关联的节点通常在后者也相互关联。因为只有这个假设成立,才能保证在使用词嵌入向量进行推理unseen label时,使用seen的像素特征能得到正确的初始词嵌入向量。