(2)Hadoop笔记:hadoop-eclipse-plugin插件的安装和mapReduce小栗子
注:
1.eclipse所在环境为windows
2.hadoop版本2.8.3
3.hadoop-eclipse-plugin版本2.8.3
4.eclipse版本Luna Service Release 1 (4.4.1)
5.JDK 1.7
- 插件安装
hadoop-eclipse-plugin编译
因为我本地使用的JDK为1.7,而现在网上能找到的hadoop-eclipse-plugin-2.8.3都是基于JDK1.8编译的,所以都不能使用,因此需要下载hadoop-eclipse-plugin的源码然后在本地编译,过程中需要Hadoop-2.8.3的支持。当然如果你能找到符合自己环境的插件包,这步就可以跳过了。
Hadoop-2.8.3.tar.gz
hadoop2x-eclipse-plugin (github托管的源码)
apache-ant-1.9.11-bin.zip
下载完后解压apache-ant-1.9.11-bin.zip,并配置环境变量。
新建ANT_HOME=E:apache-ant-1.9.4
在PATH后面加;%ANT_HOME%\bin
测试下
ant -version![]()
解压Hadoop-2.8.3.tar.gz,hadoop2x-eclipse-plugin
编辑E:\hadoop2x-eclipse-plugin-master\src\contrib\eclipse-plugin\build.xml
添加下图红框中的部分,3项代表的意思应该都懂,就不多说了。
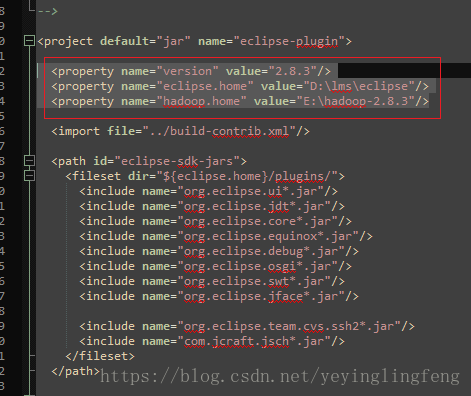
然后往下翻能发现有一堆这个东西,之后编译时大概会出错的地方。先打开放在这,不用修改。①

然后编辑E:\hadoop2x-eclipse-plugin-master\ivy\libraries.properties.xml
一般来讲只要修改下红框中的版本即可,然后这里有一大堆版本,而上面①图中那些都是在引用这里的版本。这里的版本又对应着Hadoop-2.8.3中的资源。在编译时可能会出现这里写的版本和Hadoop实际用的版本不一样导致找不到jar包的报错,这时就可以根据报错信息来修改下方的版本号,使得符合实际。基本都在${hadoop.home}/share/hadoop/common/lib文件夹中

进入hadoop2x-eclipse-plugin-master\src\contrib\eclipse-plugin目录,运行cmd命令行
ant jar编译完成,遇到错误就根据提示修改,最大可能遇到的就是我上面提到的问题,还有当编译时长时间卡在ivy-resolve-common: 处时,大概率已经编译失败。

编译完成后的文件在
hadoop2x-eclipse-plugin-master\build\contrib\eclipse-plugin文件夹中

将jar包放入eclipse/plugins文件夹中,重启eclipse
可以看到如下图标

添加
window->show view->other

配置连接,如下图所示,随便取个名字就行

然后如果连接成功的话就如下图所示,这里刚新搭建的Hadoop环境的话应该一开始就是空的,所以可能会抛空指针异常,没什么影响的,直接新建东西就行。


新建后需要刷新一下,同时可以访问http://xx.xx.xx.xx:50070/explorer.html#/网址查看是否真的新建了。

通过这个我们可以轻松快捷的将文件上传给Hadoop文件系统,方便本地调试。
window->preferences,选择Hadoop文件,这里主要目的是可以直接引用相关jar包

- 使用例子,单词计数
首先需要下载hadoop.dll,这个网上找找对应版本的吧,我用的是2.X的,放在C/windows/System32下。
File->New->other
next,填写名字,finish
新建4个文件

WordCountMapper.java
package com.hadoop.demo;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/*
* KEYIN:输入kv数据对中key的数据类型
* VALUEIN:输入kv数据对中value的数据类型
* KEYOUT:输出kv数据对中key的数据类型
* VALUEOUT:输出kv数据对中value的数据类型
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
/*
* map方法是提供给map task进程来调用的,map task进程是每读取一行文本来调用一次我们自定义的map方法
* map task在调用map方法时,传递的参数:
* 一行的起始偏移量LongWritable作为key
* 一行的文本内容Text作为value
*/
@Override
protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException {
//拿到一行文本内容,转换成String 类型
String line = value.toString();
//将这行文本切分成单词
String[] words=line.split(" ");
//输出<单词,1>
for(String word:words){
context.write(new Text(word), new IntWritable(1));
}
}
}
WordCountReducer.java
package com.hadoop.demo;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/*
* KEYIN:对应mapper阶段输出的key类型
* VALUEIN:对应mapper阶段输出的value类型
* KEYOUT:reduce处理完之后输出的结果kv对中key的类型
* VALUEOUT:reduce处理完之后输出的结果kv对中value的类型
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
/*
* reduce方法提供给reduce task进程来调用
*
* reduce task会将shuffle阶段分发过来的大量kv数据对进行聚合,聚合的机制是相同key的kv对聚合为一组
* 然后reduce task对每一组聚合kv调用一次我们自定义的reduce方法
* 比如:
* hello组会调用一次reduce方法进行处理,tom组也会调用一次reduce方法进行处理
* 调用时传递的参数:
* key:一组kv中的key
* values:一组kv中所有value的迭代器
*/ values,Context context) throws IOException, InterruptedException {
//定义一个计数器
int count = 0;
//通过value这个迭代器,遍历这一组kv中所有的value,进行累加
for(IntWritable value:values){
count+=value.get();
}
//输出这个单词的统计结果
context.write(key, new IntWritable(count));
}
}
WordCountJobSubmitter.java
package com.hadoop.demo;
import java.io.IOException;
import java.util.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountJobSubmitter {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job wordCountJob = Job.getInstance(conf);
//重要:指定本job所在的jar包
wordCountJob.setJarByClass(WordCountJobSubmitter.class);
//设置wordCountJob所用的mapper逻辑类为哪个类
wordCountJob.setMapperClass(WordCountMapper.class);
//设置wordCountJob所用的reducer逻辑类为哪个类
wordCountJob.setReducerClass(WordCountReducer.class);
//设置map阶段输出的kv数据类型
wordCountJob.setMapOutputKeyClass(Text.class);
wordCountJob.setMapOutputValueClass(IntWritable.class);
//设置最终输出的kv数据类型
wordCountJob.setOutputKeyClass(Text.class);
wordCountJob.setOutputValueClass(IntWritable.class);
Long fileName = (new Date()).getTime();
//设置要处理的文本数据所存放的路径
FileInputFormat.setInputPaths(wordCountJob, "hdfs://xx.xx.xx.xx:9002/test/1.data");
FileOutputFormat.setOutputPath(wordCountJob, new Path("hdfs://xx.xx.xx.xx:9002/test/"+fileName));
//提交job给hadoop集群
wordCountJob.waitForCompletion(true);
}
}
log4j.properties
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n然后准备下1.data的数据(就是个txt编辑后修改后缀为data的文件),将该文件通过DFS上传
hello tom
hello jim
how are you
i love you
i miss you
i love you
因为我这里放的路径是test下,实际使用时请在WordCountJobSubmitter .java中替换为自己的路径和文件名。
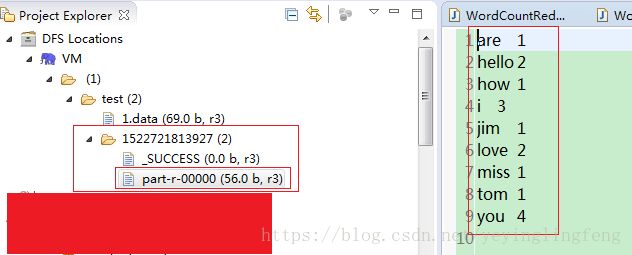
运行,选中WordCountJobSubmitter.java(有main函数的),右键run as ->run configurations。hdfs第一行为输入,第二行为输出
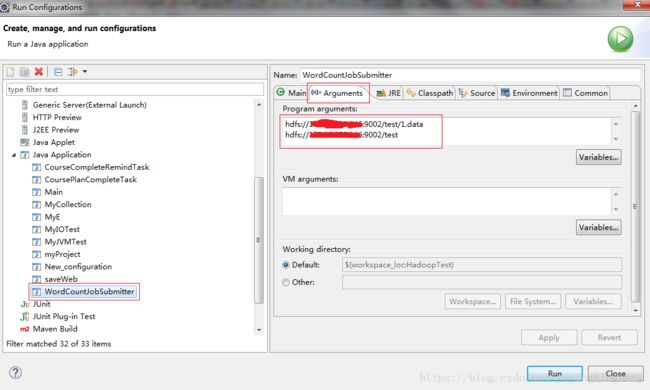
运行,可以看见生成了新的文件,点击查看,可以看到单词计数的结果了。
因为大部分都是根据记忆写的,所以过程中如果出现错误,望指正 _ (:з」∠*)_。