python爬虫系列(3):使用Selenium和BeautifulSoup获取12306一个月内所有车次车票情况
首先针对标题说明一下,本次的获取数据是指定出发地和目的地之间的车次,不是整个网站所有车次。
在此操作之前,请确保自己的相关的库都已经安装完全,这里可没有教安装库的方法哦~~~~好的,往下走,这次的目标网页是 https://kyfw.12306.cn/otn/leftTicket/init,查询12306余票情况,老套路打开浏览器的开发者模式。因为这次使用的是Selenium控制浏览器模拟人为点击的方式操作,所以在这之前我们需要自己使用浏览器点击操作一番,看看怎么使用这个网页:

经过一番点击测试,发现出发地和目的地都必须要选择,出发日也是必选项。但是发现,这些输入框都不是我们自己输入内容,只能是先点击这个框框后(如下图),在下面会出现出发地选项框,在这些选项框中选择一个出发地,这样才被网站识别为有效输入,后面的出发日期也是同样的道理。等这些必要的信息都已经输入完毕后点击右边那橘黄色的“查询”按钮,这是指定日期的所有车次信息全部都显示出来。

现在我们学会了怎么查询车班次,这时我们来整理思路,怎么抓取30天所有的车班次呢?小脑袋瓜稍微的转一下就能想到,只要输入完出发地和目的地后,再输入正确的日期,点击查询后这一天的信息就出来了,然后再重新输入下一天的日期,再点击查询,这样反复30次,ok,30天的数据就摆在我们眼前了。
第一步:定位出发地输入框,在输入框右击,可以看到检查(审查元素),这时候就会自动跳到开发者模式的elements中的相应的位置,然后右击copy selector,待会儿在代码中会用到。右边的目的输入框同样的方法实现。
def input_FromTo(self):
fromStation = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#fromStationText"))) #刚刚copy的内容在这里使用
fromStation.click() #点击输入框选中
fromStation.clear() #删除其中默认的文字
fromStation.send_keys('北京') #输入出发地
fStation = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#citem_0 > span:nth-child(1)"))) #等待下拉选项框中指定的元素出来
fStation.click() #等指定的元素出来之后,模拟点击选择
toStation = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#toStationText")))
toStation.click()
toStation.clear()
toStation.send_keys('上海')
tStation = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#citem_0 > span:nth-child(1)")))
tStation.click()第二步:搞定时间,在时间上我们可以读取本地的时间,知道今天的时间,然后在出现的日历框中输入指定的月和日,定位可以看出CSS选择器的规律,只要在child后给出相应的月和日的数值就能点击输入对应的时间。到此可以写一个设置时间的方法,方法带有一个入参,入参为从今天的日期起算,往后推算第n天,入参便是这个n:
css_month = 'body > div.cal-wrap > div:nth-child(1) > div.cal-top > div.month > ul > li:nth-child(%d)' % month
css_day = 'body > div.cal-wrap > div:nth-child(1) > div.cal-cm > div:nth-child(%d) > div' % day
def set_date(self, n):
needDate = datetime.datetime.now() + datetime.timedelta(days = n) #获取今天的时间往后偏移n天
css_month = 'body > div.cal-wrap > div:nth-child(1) > div.cal-top > div.month > ul > li:nth-child(%d)' % needDate.month
css_day = 'body > div.cal-wrap > div:nth-child(1) > div.cal-cm > div:nth-child(%d) > div' % needDate.day
#点击选择出发时间输入框
train_date = self.wait.until(EC.presence_of_element_located((By.ID, "train_date")))
train_date.click()
#点击左边选择月份表
month_list = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'body > div.cal-wrap > div:nth-child(1) > div.cal-top > div.month > input[type="text"]')))
month_list.click()
month = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, css_month)))
month.click()
get_date_list = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, css_day)))
get_date_list.click()
self.click_query()
return needDate第三步:点击查询按钮等待数据的呈现:
#点击查询按钮
def click_query(self):
self.query_ticket = self.wait.until(EC.presence_of_element_located((By.ID, "query_ticket")))
self.query_ticket.click()第四步:分析数据获取数据,可以看到,tobody节点中的tr标签都是展开都是我们需要的单次列车信息,需要将这里面的数据解析出来报文,打印,或者做其他的数据分析处理。这里就可以使用BeautifulSoup解析库处理,首先可以根据关键字tobody中的id属性立刻定位到列表信息的位置所在,然后将tobody中的每一个车次行信息提取出来,送到单独处理行信息的方法中。在该方法中就可以将我们期望需要的信息提取出来。
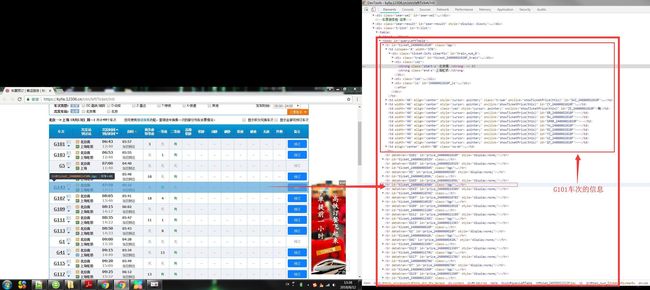
#对每一列车次的信息进行解析
def get_detail_info(self, node):
autoShift = {}
data = []
nodes = node.contents
queryLeftTable = nodes[0].div.div.div.a.string #车班次,为key
autoShift[queryLeftTable] = list()
strong = nodes[0].select('strong')
for i in range(0,4):
data.append(strong[i].string)
for i in range(1,len(nodes)):
#在node.contents时,列表中有很多空格,会导致异常发生,在之前将数据清洗这里就可以不用异常判断,这里大家可以自己试试
try:
if nodes[i].string != '--':
key = nodes[i].attrs['id'].split('_')[0]
str = self.ztype[nodes[i].attrs['id'].split('_')[0]] + ":" + nodes[i].string
data.append(str)
except:
pass
autoShift[queryLeftTable] = data
print(autoShift)
#在网页中找到一页班次信息,然后遍历这些班次信息
def get_list(self, date):
print('\n', date, ':')
info = list()
soup = BeautifulSoup(self.browser.page_source, 'lxml')
soup = soup.select('#queryLeftTable') #在整个网页中找到该id
queryLeftTable = soup[0].select('tr[id^="ticket_"]') #返回列表,列表每个内容为一个节点tag
for tr in queryLeftTable:
self.get_detail_info(tr) #传入每一列车次的信息在这里我们没有将数据保存下来,只是将其打印出来看我们确实将这些数据得到了,本章做个保留,等到后面我们将数据进行可是化的时候,再回头对这些数据做一些简单的处理,并将数据以图表的形式呈现出来,现将所有的代码和运行结果贴出来,写的并不是完美的,大家可以将这些代码复制下来进行改动,达到完美:
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from bs4 import BeautifulSoup
import io,sys, time, datetime, re
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
class Info12306(object):
def __init__(self):
#座位种类
self.ztype = {"SWZ" : "商务特等座",
"ZY" : "一等座",
"ZE" : "二等座",
"GR" : "高级软卧",
"RW" : "软卧",
"SRRB" : "动卧",
"YW" : "硬卧",
"RZ" : "软座",
"YZ" : "硬座",
"WZ" : "无座",
"QT" : "其他"}
self.url = "https://kyfw.12306.cn/otn/leftTicket/init"
self.info = {}
self.browser = webdriver.Chrome() #初始化浏览器
self.wait = WebDriverWait(self.browser, 5)
def open_html(self):
self.browser.get(self.url)
def close_html(self):
self.browser.close()
#点击查询按钮
def click_query(self):
self.query_ticket = self.wait.until(EC.presence_of_element_located((By.ID, "query_ticket")))
self.query_ticket.click()
#点击离今天往后第n天的结果
def set_date(self, n):
needDate = datetime.datetime.now() + datetime.timedelta(days = n) #获取今天的时间往后偏移n天
css_month = 'body > div.cal-wrap > div:nth-child(1) > div.cal-top > div.month > ul > li:nth-child(%d)' % needDate.month
css_day = 'body > div.cal-wrap > div:nth-child(1) > div.cal-cm > div:nth-child(%d) > div' % needDate.day
#点击选择出发时间输入框
train_date = self.wait.until(EC.presence_of_element_located((By.ID, "train_date")))
train_date.click()
#点击左边选择月份表
month_list = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'body > div.cal-wrap > div:nth-child(1) > div.cal-top > div.month > input[type="text"]')))
month_list.click()
month = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, css_month)))
month.click()
get_date_list = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, css_day)))
get_date_list.click()
self.click_query()
return needDate
#选择面板上的日期
def select_date(self):
action = ActionChains(self.browser) #使用浏览器动作模拟库
move_to_date = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#date_range > ul > li:nth-child(3)")))
action.move_to_element(move_to_date).perform()
action.click(move_to_date).perform()
#输入出发地和目的地,可以手动添加地址
def input_FromTo(self):
fromStation = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#fromStationText")))
fromStation.click()
fromStation.clear()
fromStation.send_keys('北京')
fStation = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#citem_0 > span:nth-child(1)")))
fStation.click()
toStation = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#toStationText")))
toStation.click()
toStation.clear()
toStation.send_keys('上海')
tStation = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#citem_0 > span:nth-child(1)")))
tStation.click()
def get_detail_info(self, node):
autoShift = {}
data = []
nodes = node.contents
queryLeftTable = nodes[0].div.div.div.a.string #车班次,为key
autoShift[queryLeftTable] = list()
strong = nodes[0].select('strong')
for i in range(0,4):
data.append(strong[i].string)
for i in range(1,len(nodes)):
try:
if nodes[i].string != '--':
key = nodes[i].attrs['id'].split('_')[0]
str = self.ztype[nodes[i].attrs['id'].split('_')[0]] + ":" + nodes[i].string
data.append(str)
except:
pass
autoShift[queryLeftTable] = data
print(autoShift)
def get_list(self, date):
print('\n', date, ':')
info = list()
soup = BeautifulSoup(self.browser.page_source, 'lxml')
soup = soup.select('#queryLeftTable')
queryLeftTable = soup[0].select('tr[id^="ticket_"]') #返回列表,列表每个内容为一个节点tag
for tr in queryLeftTable:
self.get_detail_info(tr)
def run(self):
self.open_html()
self.input_FromTo()
for seq in range(0,1):
date = self.set_date(seq)
time.sleep(1)
self.get_list(date)
#self.close_html()
Get12306 = Info12306()
Get12306.run()
运行结果
小结:使用selenium的好处就是不需要分析后台传送的数据,因为后台传输的数据有可能是加密,这样的数据抓取了也是没有用的,对于selenium来说这些都是不存的,在页面可见即可抓,管你加密不加密,这就是selenium,当然这里的解析库也可以只用其他的,根据不同的场景选择不同的解析库有助于提高抓取效率。