Unicode
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
起源
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),0 - 255被用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
如果要表示中文,显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
类似的,日文和韩文等其他语言也有这个问题。为了统一所有文字的编码,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode通常用两个字节表示一个字符,原有的英文编码从单字节变成双字节,只需要把高字节全部填为0就可以。
因为Python的诞生比Unicode标准发布的时间还要早,所以最早的Python只支持ASCII编码,普通的字符串'ABC'在Python内部都是ASCII编码的。
Unicode 是为了解决传统的字符编码方案的局限而产生的,例如ISO 8859所定义的字符虽然在不同的国家中广泛地使用,可是在不同国家间却经常出现不兼容的情况。很多传统的编码方式都有一个共同的问题,即容许电脑处理双语环境(通常使用拉丁字母以及其本地语言),但却无法同时支持多语言环境(指可同时处理多种语言混合的情况)。
Unicode 编码包含了不同写法的字,如“ɑ/a”、“户/户/戸”。然而在汉字方面引起了一字多形的认定争议。
在文字处理方面,统一码为每一个字符而非字形定义唯一的代码(即一个整数)。换句话说,统一码以一种抽象的方式(即数字)来处理字符,并将视觉上的演绎工作(例如字体大小、外观形状、字体形态、文体等)留给其他软件来处理,例如网页浏览器或是文字处理器。
几乎所有电脑系统都支持基本拉丁字母,并各自支持不同的其他编码方式。Unicode为了和它们相互兼容,其首256字符保留给ISO 8859-1所定义的字符,使既有的西欧语系文字的转换不需特别考量;并且把大量相同的字符重复编到不同的字符码中去,使得旧有纷杂的编码方式得以和Unicode编码间互相直接转换,而不会丢失任何信息。举例来说,全角格式区段包含了主要的拉丁字母的全角格式,在中文、日文、以及韩文字形当中,这些字符以全角的方式来呈现,而不以常见的半角形式显示,这对竖排文字和等宽排列文字有重要作用。
在表示一个Unicode的字符时,通常会用“U+”然后紧接着一组十六进制的数字来表示这一个字符。在基本多文种平面(英文为 Basic Multilingual Plane,简写 BMP。它又简称为“零号平面”, plane 0)里的所有字符,要用四位十六进制数(例如U+4AE0,共支持六万多个字符);在零号平面以外的字符则需要使用五位或六位十六进制数了。旧版的Unicode标准使用相近的标记方法,但却有些微的差异:在Unicode 3.0里使用“U-”然后紧接着八位数,而“U+”则必须随后紧接着四位数。 [1]
作用
能够使计算机实现跨语言、跨平台的文本转换及处理。
层次
Unicode 编码系统,可分为编码方式和实现方式两个层次。
方式
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。目前的Unicode字符分为17组编排,0x0000 至 0x10FFFF,每组称为平面(Plane),而每平面拥有65536个码位,共1114112个。然而目前只用了少数平面。UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。
通用字符集(Universal Character Set, UCS)是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集。UCS-2用两个字节编码,UCS-4用4个字节编码。
历史上存在两个独立的尝试创立单一字符集的组织,即国际标准化组织(ISO)和多语言软件制造商组成的统一码联盟。前者开发的 ISO/IEC 10646 项目,后者开发的统一码项目。因此最初制定了不同的标准。
1991年前后,两个项目的参与者都认识到,世界不需要两个不兼容的字符集。于是,它们开始合并双方的工作成果,并为创立一个单一编码表而协同工作。从Unicode 2.0开始,Unicode采用了与ISO 10646-1相同的字库和字码;ISO也承诺,ISO 10646将不会替超出U+10FFFF的UCS-4编码赋值,以使得两者保持一致。两个项目仍都存在,并独立地公布各自的标准。但统一码联盟和ISO/IEC JTC1/SC2都同意保持两者标准的码表兼容,并紧密地共同调整任何未来的扩展。在发布的时候,Unicode一般都会采用有关字码最常见的字型,但ISO 10646一般都尽可能采用Century字型。
UCS-4根据最高位为0的最高字节分成27=128个group。每个group再根据次高字节分为256个平面(plane)。每个平面根据第3个字节分为256行 (row),每行有256个码位(cell)。group 0的平面0被称作BMP(Basic Multilingual Plane)。如果UCS-4的前两个字节为全零,那么将UCS-4的BMP去掉前面的两个零字节就得到了UCS-2。每个平面有216=65536个码位。Unicode计划使用了17个平面,一共有17×65536=1114112个码位。在Unicode 5.0.0版本中,已定义的码位只有238605个,分布在平面0、平面1、平面2、平面14、平面15、平面16。其中平面15和平面16上只是定义了两个各占65534个码位的专用区(Private Use Area),分别是0xF0000-0xFFFFD和0x100000-0x10FFFD。所谓专用区,就是保留给大家放自定义字符的区域,可以简写为PUA。
平面0也有一个专用区:0xE000-0xF8FF,有6400个码位。平面0的0xD800-0xDFFF,共2048个码位,是一个被称作代理区(Surrogate)的特殊区域。代理区的目的用两个UTF-16字符表示BMP以外的字符。在介绍UTF-16编码时会介绍。
如前所述在Unicode 5.0.0版本中,238605-65534*2-6400-2048=99089。余下的99089个已定义码位分布在平面0、平面1、平面2和平面14上,它们对应着Unicode定义的99089个字符,其中包括71226个汉字。平面0、平面1、平面2和平面14上分别定义了52080、3419、43253和337个字符。平面2的43253个字符都是汉字。平面0上定义了27973个汉字。
在Unicode中:汉字“字”对应的数字是23383(十进制),十六进制表示为5B57。在Unicode中,我们有很多方式将数字23383表示成程序中的数据,包括:UTF-8、UTF-16、UTF-32。UTF是“Unicode Transformation Format”的缩写,可以翻译成Unicode字符集转换格式,即怎样将Unicode定义的数字转换成程序数据。
例如,“汉字”对应的数字是0x6c49和0x5b57,而编码的程序数据是:
| 1 2 3 |
|
这里用char、char16_t、char32_t分别表示无符号8位整数,无符号16位整数和无符号32位整数。UTF-8、UTF-16、UTF-32分别以char、char16_t、char32_t作为编码单位。(注: char16_t 和 char32_t 是 C++ 11 标准新增的关键字。如果你的编译器不支持 C++ 11 标准,请改用 unsigned short 和 unsigned long。)“汉字”的UTF-8编码需要6个字节。“汉字”的UTF-16编码需要两个char16_t,大小是4个字节。“汉字”的UTF-32编码需要两个char32_t,大小是8个字节。根据字节序的不同,UTF-16可以被实现为UTF-16LE或UTF-16BE,UTF-32可以被实现为UTF-32LE或UTF-32BE。下面介绍UTF-8、UTF-16、UTF-32、字节序和BOM。 [1]
UTF-8
UTF-8以字节为单位对Unicode进行编码。从Unicode到UTF-8的编码方式如下:
| Unicode编码(十六进制) |
UTF-8 字节流(二进制) |
| 000000-00007F |
0xxxxxxx |
| 000080-0007FF |
110xxxxx 10xxxxxx |
| 000800-00FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
| 010000-10FFFF | 11110xxx10xxxxxx10xxxxxx10xxxxxx |
UTF-8的特点是对不同范围的字符使用不同长度的编码。对于0x00-0x7F之间的字符,UTF-8编码与ASCII编码完全相同。UTF-8编码的最大长度是4个字节。从上表可以看出,4字节模板有21个x,即可以容纳21位二进制数字。Unicode的最大码位0x10FFFF也只有21位。
例1:“汉”字的Unicode编码是0x6C49。0x6C49在0x0800-0xFFFF之间,使用3字节模板:1110xxxx 10xxxxxx 10xxxxxx。将0x6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
例2:Unicode编码0x20C30在0x010000-0x10FFFF之间,使用4字节模板:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx。将0x20C30写成21位二进制数字(不足21位就在前面补0):0 0010 0000 1100 0011 0000,用这个比特流依次代替模板中的x,得到:11110000 10100000 10110000 10110000,即F0 A0 B0 B0。
UTF-16
UTF-16编码以16位无符号整数为单位。我们把Unicode
 unicode
unicode
编码记作U。编码规则如下:
如果U<0x10000,U的UTF-16编码就是U对应的16位无符号整数(为书写简便,下文将16位无符号整数记作WORD)。
如果U≥0x10000,我们先计算U'=U-0x10000,然后将U'写成二进制形式:yyyy yyyy yyxx xxxx xxxx,U的UTF-16编码(二进制)就是:110110yyyyyyyyyy 110111xxxxxxxxxx。
为什么U'可以被写成20个二进制位?Unicode的最大码位是0x10FFFF,减去0x10000后,U'的最大值是0xFFFFF,所以肯定可以用20个二进制位表示。例如:Unicode编码0x20C30,减去0x10000后,得到0x10C30,写成二进制是:0001 0000 1100 0011 0000。用前10位依次替代模板中的y,用后10位依次替代模板中的x,就得到:1101100001000011 1101110000110000,即0xD843 0xDC30。
按照上述规则,Unicode编码0x10000-0x10FFFF的UTF-16编码有两个WORD,第一个WORD的高6位是110110,第二个WORD的高6位是110111。可见,第一个WORD的取值范围(二进制)是11011000 00000000到11011011 11111111,即0xD800-0xDBFF。第二个WORD的取值范围(二进制)是11011100 00000000到11011111 11111111,即0xDC00-0xDFFF。
为了将一个WORD的UTF-16编码与两个WORD的UTF-16编码区分开来,Unicode编码的设计者将0xD800-0xDFFF保留下来,并称为代理区(Surrogate):
| D800-DB7F |
High Surrogates |
高位替代 |
| DB80-DBFF |
High Private Use Surrogates |
高位专用替代 |
| DC00-DFFF |
Low Surrogates |
低位替代 |
高位替代就是指这个范围的码位是两个WORD的UTF-16编码的第一个WORD。低位替代就是指这个范围的码位是两个WORD的UTF-16编码的第二个WORD。那么,高位专用替代是什么意思?我们来解答这个问题,顺便看看怎么由UTF-16编码推导Unicode编码。
如果一个字符的UTF-16编码的第一个WORD在0xDB80到0xDBFF之间,那么它的Unicode编码在什么范围内?我们知道第二个WORD的取值范围是0xDC00-0xDFFF,所以这个字符的UTF-16编码范围应该是0xDB80 0xDC00到0xDBFF 0xDFFF。我们将这个范围写成二进制:
1101101110000000 11011100 00000000 - 1101101111111111 1101111111111111
按照编码的相反步骤,取出高低WORD的后10位,并拼在一起,得到
1110 0000 0000 0000 0000 - 1111 1111 1111 1111 1111
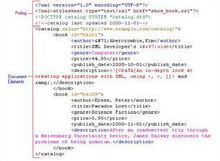 XML
XML
即0xe0000-0xfffff,按照编码的相反步骤再加上0x10000,得到0xf0000-0x10ffff。这就是UTF-16编码的第一个WORD在0xdb80到0xdbff之间的Unicode编码范围,即平面15和平面16。因为Unicode标准将平面15和平面16都作为专用区,所以0xDB80到0xDBFF之间的保留码位被称作高位专用替代 [1] 。
UTF-32
UTF-32编码以32位无符号整数为单位。Unicode的UTF-32编码就是其对应的32位无符号整数。
字节序
字节序有两种,分别是“大端”(Big Endian, BE)和“小端”(Little Endian, LE)。
根据字节序的不同,UTF-16可被实现为UTF-16LE或UTF-16BE,UTF-32可被实现为UTF-32LE或UTF-32BE。例如:
| Unicode编码 |
UTF-16LE |
UTF-16BE |
UTF32-LE |
UTF32-BE |
| 0x006C49 |
49 6C |
6C 49 |
49 6C 00 00 |
00 00 6C 49 |
| 0x020C30 |
43 D8 30 DC |
D8 43 DC 30 |
30 0C 02 00 |
00 02 0C 30 |
Unicode标准建议用BOM(Byte Order Mark)来区分字节序,即在传输字节流前,先传输被作为BOM的字符“零宽无中断空格”。这个字符的编码是FEFF,而反过来的FFFE(UTF-16)和FFFE0000(UTF-32)在Unicode中都是未定义的码位,不应该出现在实际传输中。
下表是各种UTF编码的BOM:
| UTF编码 |
Byte Order Mark (BOM) |
| UTF-8 without BOM | 无 |
| UTF-8 with BOM |
EF BB BF |
| UTF-16LE |
FF FE |
| UTF-16BE |
FE FF |
| UTF-32LE |
FF FE 00 00 |
| UTF-32BE |
00 00 FE FF |
分布
Unicode 到目前为止所定义的五个平面中,第0平面(BMP)最为重要,其编码分布如下:
注:中文范围 4E00-9FA5:CJK 统一表意符号 (CJK Unified Ideographs)
0000-007F:C0控制符及基本拉丁文 (C0 Control and Basic Latin)
0080-00FF:C1控制符及拉丁文补充-1 (C1 Control and Latin 1 Supplement)
0100-017F:拉丁文扩展-A (Latin Extended-A)
0180-024F:拉丁文扩展-B (Latin Extended-B)
0250-02AF:国际音标扩展 (IPA Extensions)
02B0-02FF:空白修饰字母 (Spacing Modifiers)
0300-036F:结合用读音符号 (Combining Diacritics Marks)
0370-03FF:希腊文及科普特文 (Greek and Coptic)
 Microsoft Word
Microsoft Word
0400-04FF:西里尔字母(Cyrillic)
0500-052F:西里尔字母补充 (Cyrillic Supplement)
0530-058F:亚美尼亚语 (Armenian)
0590-05FF:希伯来文 (Hebrew)
0600-06FF:阿拉伯文 (Arabic)
0700-074F:叙利亚文 (Syriac)
0750-077F:阿拉伯文补充 (Arabic Supplement)
0780-07BF:马尔代夫语 (Thaana)
07C0-07FF:西非书面语言 (N'Ko)
0800-085F:阿维斯塔语及巴列维语(Avestan and Pahlavi)
0860-087F:Mandaic
0880-08AF:撒马利亚语 (Samaritan)
0900-097F:天城文书 (Devanagari)
0980-09FF:孟加拉语 (Bengali)
0A00-0A7F:锡克教文 (Gurmukhi)
0A80-0AFF:古吉拉特文 (Gujarati)
0B00-0B7F:奥里亚文 (Oriya)
0B80-0BFF:泰米尔文 (Tamil)
0C00-0C7F:泰卢固文 (Telugu)
0C80-0CFF:卡纳达文 (Kannada)
0D00-0D7F:德拉维族语 (Malayalam)
0D80-0DFF:僧伽罗语 (Sinhala)
0E00-0E7F:泰文 (Thai)
0E80-0EFF:老挝文 (Lao)
0F00-0FFF:藏文 (Tibetan)
1000-109F:缅甸语 (Myanmar)
10A0-10FF:格鲁吉亚语(Georgian)
1100-11FF:朝鲜文 (Hangul Jamo)
1200-137F:埃塞俄比亚语 (Ethiopic)
1380-139F:埃塞俄比亚语补充 (Ethiopic Supplement)
13A0-13FF:切罗基语 (Cherokee)
1400-167F:统一加拿大土著语音节 (Unified Canadian Aboriginal Syllabics)
1680-169F:欧甘字母 (Ogham)
16A0-16FF:如尼文(Runic)
1700-171F:塔加拉语 (Tagalog)
1720-173F:Hanunóo
1740-175F:Buhid
1760-177F:塔格班瓦文(Tagbanwa)
1780-17FF:高棉语 (Khmer)
1800-18AF:蒙古文 (Mongolian)
18B0-18FF:Cham
1900-194F:Limbu
1950-197F:德宏泰语 (Tai Le)
1980-19DF:新傣仂语 (New Tai Lue)
19E0-19FF:高棉语记号 (Kmer Symbols)
1A00-1A1F:Buginese
1A20-1A5F:Batak
1A80-1AEF:Lanna
1B00-1B7F:巴厘语 (Balinese)
1B80-1BB0:巽他语 (Sundanese)
1BC0-1BFF:Pahawh Hmong
1C00-1C4F:雷布查语(Lepcha)
1C50-1C7F:桑塔利文(Ol Chiki)
1C80-1CDF:曼尼普尔语(Meithei/Manipuri)
1D00-1D7F:语音学扩展 (Phonetic Extensions)
1D80-1DBF:语音学扩展补充 (Phonetic Extensions Supplem
 unicode
unicode
ent)
1DC0-1DFF:结合用读音符号补充 (Combining Diacritics Marks Supplement)
1E00-1EFF:拉丁文扩充附加 (Latin Extended Additional)
1F00-1FFF:希腊语扩充 (Greek Extended)
2000-206F:常用标点(General Punctuation)
2070-209F:上标及下标 (Superscripts and Subscripts)
20A0-20CF:货币符号 (Currency Symbols)
20D0-20FF:组合用记号 (Combining Diacritics Marks for Symbols)
2100-214F:字母式符号 (Letterlike Symbols)
2150-218F:数字形式 (Number Form)
2190-21FF:箭头 (Arrows)
2200-22FF:数学运算符 (Mathematical Operator)
2300-23FF:杂项工业符号 (Miscellaneous Technical)
2400-243F:控制图片 (Control Pictures)
2440-245F:光学识别符 (Optical Character Recognition)
2460-24FF:封闭式字母数字 (Enclosed Alphanumerics)
2500-257F:制表符 (Box Drawing)
2580-259F:方块元素 (Block Element)
25A0-25FF:几何图形 (Geometric Shapes)
2600-26FF:杂项符号 (Miscellaneous Symbols)
2700-27BF:印刷符号 (Dingbats)
27C0-27EF:杂项数学符号-A (Miscellaneous Mathematical Symbols-A)
27F0-27FF:追加箭头-A (Supplemental Arrows-A)
2800-28FF:盲文点字模型 (Braille Patterns)
2900-297F:追加箭头-B (Supplemental Arrows-B)
2980-29FF:杂项数学符号-B (Miscellaneous Mathematical Symbols-B)
2A00-2AFF:追加数学运算符 (Supplemental Mathematical Operator)
2B00-2BFF:杂项符号和箭头 (Miscellaneous Symbols and Arrows)
2C00-2C5F:格拉哥里字母(Glagolitic)
2C60-2C7F:拉丁文扩展-C (Latin Extended-C)
2C80-2CFF:古埃及语 (Coptic)
2D00-2D2F:格鲁吉亚语补充 (Georgian Supplement)
2D30-2D7F:提非纳文 (Tifinagh)
2D80-2DDF:埃塞俄比亚语扩展 (Ethiopic Extended)
2E00-2E7F:追加标点 (Supplemental Punctuation)
2E80-2EFF:CJK 部首补充 (CJK Radicals Supplement)
2F00-2FDF:康熙字典部首 (Kangxi Radicals)
2FF0-2FFF:表意文字描述符 (Ideographic Description Characters)
3000-303F:CJK 符号和标点 (CJK Symbols and Punctuation)
3040-309F:日文平假名 (Hiragana)
30A0-30FF:日文片假名 (Katakana)
3100-312F:注音字母 (Bopomofo)
3130-318F:朝鲜文兼容字母 (Hangul Compatibility Jamo)
3190-319F:象形字注释标志 (Kanbun)
31A0-31BF:注音字母扩展 (Bopomofo Extended)
31C0-31EF:CJK 笔画 (CJK Strokes)
31F0-31FF:日文片假名语音扩展 (Katakana Phonetic Extensions)
3200-32FF:封闭式 CJK 文字和月份 (Enclosed CJK Letters and Months)
3300-33FF:CJK 兼容 (CJK Compatibility)
3400-4DBF:CJK 统一表意符号扩展 A (CJK Unified Ideographs Extension A)
4DC0-4DFF:易经六十四卦符号 (Yijing Hexagrams Symbols)
4E00-9FBF:CJK 统一表意符号 (CJK Unified Ideographs)
A000-A48F:彝文音节 (Yi Syllables)
A490-A4CF:彝文字根 (Yi Radicals)
A500-A61F:Vai
A660-A6FF:统一加拿大土著语音节补充 (Unified Canadian Aboriginal Syllabics Supplement)
A700-A71F:声调修饰字母 (Modifier Tone Letters)
A720-A7FF:拉丁文扩展-D (Latin Extended-D)
A800-A82F:Syloti Nagri
A840-A87F:八思巴字 (Phags-pa)
A880-A8DF:Saurashtra
A900-A97F:爪哇语 (Javanese)
A980-A9DF:Chakma
AA00-AA3F:Varang Kshiti
AA40-AA6F:Sorang Sompeng
AA80-AADF:Newari
AB00-AB5F:越南傣语 (Vi?t Thái)
AB80-ABA0:Kayah Li
AC00-D7AF:朝鲜文音节 (Hangul Syllables)
D800-DBFF:High-half zone of UTF-16
DC00-DFFF:Low-half zone of UTF-16
E000-F8FF:自行使用区域 (Private Use Zone)
F900-FAFF:CJK 兼容象形文字 (CJK Compatibility Ideographs)
FB00-FB4F:字母表达形式 (Alphabetic Presentation Form)
FB50-FDFF:阿拉伯表达形式A (Arabic Presentation Form-A)
FE00-FE0F:变量选择符 (Variation Selector)
FE10-FE1F:竖排形式 (Vertical Forms)
FE20-FE2F:组合用半符号 (Combining Half Marks)
FE30-FE4F:CJK 兼容形式 (CJK Compatibility Forms)
FE50-FE6F:小型变体形式 (Small Form Variants)
FE70-FEFF:阿拉伯表达形式B (Arabic Presentation Form-B)
FF00-FFEF:半型及全型形式 (Halfwidth and Fullwidth Form)
FFF0-FFFF:特殊 (Specials)
环境
在非 Unicode 环境下,由于不同国家和地区采用的字符集不一致,很可能出现无法正常显示所有字符的情况。微软公司使用了代码页(Codepage)转换表的技术来过渡性的部分解决这一问题,即通过指定的转换表将非 Unicode 的字符编码转换为同一字符对应的系统内部使用的 Unicode 编码。可以在“语言与区域设置”中选择一个代码页作为非 Unicode 编码所采用的默认编码方式,如936为简体中文GBK,950为繁体中文Big5(皆指PC上使用的)。在这种情况下,一些非英语的欧洲语言编写的软件和文档很可能出现乱码。而将代码页设置为相应语言中文处理又会出现问题,这一情况无法避免。从根本上说,完全采用统一编码才是解决之道,但是Windows操作系统由于历史遗留原因尚无法做到这一点。
代码页技术广泛为各种平台所采用。UTF-7 的代码页是65000,UTF-8 的代码页是65001。
字集
XML及其子集HTML采用UTF-8作为标准字集,理论上我们可以在各种支持XML标准的浏览器上显示任何地区文字的网页,只要电脑本身安装有合适的字体即可。可以利用&#nnn;的格式显示特定的字符。nnn代表该字符的十进制 Unicode 代码。如果采用十六进制代码,在编码之前加上x字符即可。但部分旧版本的浏览器可能无法识别十六进制代码。
然而部分由于Unicode 版本发展原因,很多浏览器只能显示UCS-2 完整字符集也即日常使用的Unicode 版本中的一个小子集。下表可以检验您的浏览器怎样显示各种各样的 Unicode 代码:
输入
综述
除了输入法外,操作系统会提供几种方法输入Unicode。像是Windows 2000之后的Windows系统就提供一个可点击的表。例如在Microsoft Word或者金山WPS之下,按下Alt键不放,输入 0 和某个字符的 Unicode 编码(十进制),再松开 Alt 键即可得到该字符,如Alt + 033865会得到Unicode字符“叶”(繁体)。另外按Alt + X 组合键,MS Word 也会将光标前面的字符同其十六进制的四位 Unicode 编码进行互相转换。
Unicode 编码表反弹
0000-0FFF 8000-8FFF 10000-10FFF 20000-20FFF 28000-28FFF
1000-1FFF 9000-9FFF 21000-21FFF 29000-29FFF
2000-2FFF A000-AFFF 22000-22FFF 2A000-2AFFF
3000-3FFF B000-BFFF 23000-23FFF
4000-4FFF C000-CFFF 1D000-1DFFF 24000-24FFF 2F000-2FFFF
5000-5FFF D000-DFFF 25000-25FFF
6000-6FFF E000-EFFF 26000-26FFF
7000-7FFF F000-FFFF 27000-27FFF E0000-E0FFF
Unicode 已经有6.2版本。世界上有一大批计算机、语言学等科学家专门研究Unicode,Unicode标准已经不单是一个编码标准,还是记录人类语言文字资料的一个巨大的数据库,同时从事人类文化遗产的发掘和保护工作。
对于中文而言,Unicode 16编码里面已经包含了GB18030里面的所有汉字(27484个字),Unicode标准准备把康熙字典的所有汉字放入到Unicode 32bit编码中。
简单地说,Unicode扩展自ASCII字元集。在严格的ASCII中,每个字元用7位元表示,或者电脑上普遍使用的每字元有8位元宽;而Unicode使用全16位元字元集。这使得Unicode能够表示世界上所有的书写语言中可能用於电脑通讯的字元、象形文字和其他符号。Unicode最初打算作为ASCII的补充,可能的话,最终将代替它。考虑到ASCII是电脑中最具支配地位的标准,所以这的确是一个很高的目标。
Unicode影响到了电脑工业的每个部分,但也许会对作业系统和程序设计语言的影响最大。从这方面来看,我们已经上路了。Windows NT从底层支持Unicode(不幸的是,Windows 98只是小部分支援Unicode)。先天即被ANSI束缚的C程序设计语言通过对宽字元集的支持来支持Unicode。
方法
中文输入法截至2009年3月,可以使用微软拼音2003或2007版本海峰五笔9.3版本,新注音输入法 和 VimIM 进行输入。
微软拼音 在输入法启动状态下,单击语言栏上的“功能菜单”按钮,指向“辅助输入法”即可发现“Unicode码输入方式”,利用它可以直接输入Unicode相应十六进制值的方式输入相应文字。例如中文“胥”输入“5066”,朝鲜语文字“셅”输入“c145”(不需要在前面加0x或x)。海峰五笔 此输入法已经直接支持透过五笔码输入方式输入Unicode内的任意中日韩汉字,但无法使用键入Unicode码的方式输入。例如汉字(Unicode部分)“㗎”为“keks”,CJK扩展B区的“㿱”为“iyho”和CJK扩展C区的“뇛”为“muih”。新注音输入法 在输入法启动状态时,打入键盘上的“多功能前导字符键”(及通用键盘上之“`”),第一次使用会弹出说明。输入Unicode字符“胥”则是在键盘上键入“`U5066”。而韩语中的“셅”,则输入“`UC145”。而要输入日语自制汉字“卡”,则是“`U5CE0”。VimIM 在 Vim 环境中,可以直接键入十进制或十六进制 Unicode 码。既不需要启动输入法,也不需要码表。
日文输入法使用Microsoft IME 2007,可以在IME PAD里找到UNICODE的点击表。点击字符即可输入。选择字体可以预览字符效果。
其他
除了输入法外,操作系统也会提供另外几种方法输入 Unicode。像是Windows 2000之后的 Windows 系统就提供一个可点击的字符映射表。又或者在Microsoft Word下,按下 Alt 键不放,输入 0 和某个字符的 Unicode 编码(十进制),再松开 Alt 键即可得到该字符,如Alt + 033865会得到 Unicode 字符叶。另外按Alt + X 组合键,MS Word 也会将光标前面的字符,同其十六进制的四位Unicode 编码进行互相转换。
新建文本也能输入、右键 [1]
使用
基本上,计算机只是处理数字。它们指定一个数字,来储存字母或其他字符。在创造Unicode之前,有数百种指定这些数字的编码系统。没有一个编码可以包含足够的字符:例如,单单欧洲共同体就需要好几种不同的编码来包括所有的语言。即使是单一种语言,例如英语,也没有哪一个编码可以适用于所有的字母,标点符号,和常用的技术符号。这些编码系统也会互相冲突。也就是说,两种编码可能使用相同的数字代表两个不同的字符,或使用不同的数字代表相同的字符。任何一台特定的计算机(特别是服务器)都需要支持许多不同的编码,但是,不论什么时候数据通过不同的编码或平台之间,那些数据总会有损坏的危险。
为什么使用Unicode其实原因很简单,因为Unicode比ANSI好用。 自从Windows2K开始,Win的系统内核开始完全支持并完全应用Unicode编写,所有ANSI字符在进入底层前,都会被相应的API转换成Unicode。所以,如果你一开始就使用Unicode,则可以减少转换的用时和RAM开销。 对于JAVA/.NET等这些“新”的语言来说,内置的字符串所使用的字符集已经完全是Unicode。最重要的是,世界上大多数程序用的字符集都是Unicode,因为Unicode有利于程序国际化和标准化。
简史
1990年开始研发,1994年正式公布。随着计算机工作能力的增强,Unicode也在面世以来的十多年里得到普及。
Unicode6.3版已发布(2013年11月)。在Unicode联盟网站上可以查看完整的6.3的核心规范。
Unicode定义了大到足以代表人类所有可读字符的字符集。
Java语言就用到了Unicode编码,从而实现了该语言的国际通用性。
Unicode截至目前为止,共发布了以下多个版本:
Unicode 1.0:1991年10月
Unicode 1.0.1:1992年6月
Unicode 1.1:1993年6月
Unicode 2.0:1997年7月
Unicode 2.1:1998年5月
Unicode 2.1.2:1998年5月
Unicode 3.0:1999年9月;涵盖了来自ISO 10646-1的十六比特通用字符集(UCS)基本多文种平面(Basic Multilingual Plane)
Unicode 3.1:2001年3月;新增从ISO 10646-2定义的辅助平面(Supplementary Planes)
Unicode 3.2:2002年3月
Unicode 4.0:2003年4月
Unicode 4.0.1:2004年3月
Unicode 4.1:2005年3月
Unicode 5.0:2006年7月
Unicode 5.1:2008年4月
Unicode 5.2:2009年10月
Unicode 6.0:2010年10月
Unicode 6.1:2012年1月31日
Unicode 6.2:2012年9月
Unicode 6.3:2013年11月19日
Unicode 7.0:2014年6月15日
Unicode 8.0:2015年6月17日
Unicode 9.0:2016年6月22日
Unicode 10.0:2017年6月18日
Unicode 11.0:2018年6月5日
编码表
| U+ | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
| 4e00 | 一 | 丁 | 丂 | 七 | 丄 | 丅 | 丆 | 万 | 丈 | 三 | 上 | 下 | 丌 | 不 | 与 | 丏 |
| 4e10 | 丐 | 丑 | 丒 | 专 | 且 | 丕 | 世 | 丗 | 丘 | 丙 | 业 | 丛 | 东 | 丝 | 丞 | 丢 |
| 4e20 | 丠 | 両 | 丢 | 丣 | 两 | 严 | 并 | 丧 | 丨 | 丩 | 个 | 丫 | 丬 | 中 | 丮 | 丯 |
| 4e30 | 丰 | 丱 | 串 | 丳 | 临 | 丵 | 丶 | 丷 | 丸 | 丹 | 为 | 主 | 丼 | 丽 | 举 | 丿 |
| 4e40 | 乀 | 乁 | 乂 | 乃 | 乄 | 久 | 乆 | 乇 | 么 | 义 | 乊 | 之 | 乌 | 乍 | 乎 | 乏 |
| 4e50 | 乐 | 乑 | 乒 | 乓 | 乔 | 乕 | 乖 | 乗 | 乘 | 乙 | 乚 | 乛 | 乜 | 九 | 乞 | 也 |
| 4e60 | 习 | 乡 | 乢 | 乣 | 乤 | 乥 | 书 | 乧 | 乨 | 乩 | 乪 | 乫 | 乬 | 乭 | 乮 | 乯 |
| 4e70 | 买 | 乱 | 乲 | 乳 | 乴 | 乵 | 乶 | 乷 | 乸 | 乹 | 乺 | 乻 | 乼 | 乽 | 乾 | 乿 |
| 4e80 | 亀 | 亁 | 乱 | 亃 | 亄 | 亅 | 了 | 亇 | 予 | 争 | 亊 | 事 | 二 | 亍 | 于 | 亏 |
| 4e90 | 亐 | 云 | 互 | 亓 | 五 | 井 | 亖 | 亗 | 亘 | 亘 | 亚 | 些 | 亜 | 亝 | 亚 | 亟 |
| 4ea0 | 亠 | 亡 | 亢 | 亣 | 交 | 亥 | 亦 | 产 | 亨 | 亩 | 亪 | 享 | 京 | 亭 | 亮 | 亯 |
| 4eb0 | 亰 | 亱 | 亲 | 亳 | 亴 | 亵 | 亶 | 亷 | 亸 | 亹 | 人 | 亻 | 亼 | 亽 | 亾 | 亿 |
| 4ec0 | 什 | 仁 | 仂 | 仃 | 仄 | 仅 | 仆 | 仇 | 仈 | 仉 | 今 | 介 | 仌 | 仍 | 从 | 仏 |
| 4ed0 | 仐 | 仑 | 仒 | 仓 | 仔 | 仕 | 他 | 仗 | 付 | 仙 | 仚 | 仛 | 仜 | 仝 | 仞 | 仟 |
| 4ee0 | 仠 | 仡 | 仢 | 代 | 令 | 以 | 仦 | 仧 | 仨 | 仩 | 仪 | 仫 | 们 | 仭 | 仮 | 仯 |
| 4ef0 | 仰 | 仱 | 仲 | 仳 | 仴 | 仵 | 件 | 价 | 仸 | 仹 | 仺 | 任 | 仼 | 份 | 仾 | 仿 |
| 4f00 | 伀 | 企 | 伂 | 伃 | 伄 | 伅 | 伆 | 伇 | 伈 | 伉 | 伊 | 伋 | 伌 | 伍 | 伎 | 伏 |
| 4f10 | 伐 | 休 | 伒 | 伓 | 伔 | 夫 | 伖 | 众 | 优 | 伙 | 会 | 伛 | 伜 | 伝 | 伞 | 伟 |
| 4f20 | 传 | 伡 | 伢 | 伣 | 伤 | 伥 | 伦 | 伧 | 伨 | 伩 | 伪 | 伫 | 伬 | 伭 | 伮 | 伯 |
| 4f30 | 估 | 伱 | 伲 | 伳 | 伴 | 伵 | 伶 | 伷 | 伸 | 伹 | 伺 | 伻 | 似 | 伽 | 伾 | 伿 |
| 4f40 | 佀 | 佁 | 佂 | 佃 | 佄 | 佅 | 但 | 伫 | 布 | 佉 | 佊 | 佋 | 佌 | 位 | 低 | 住 |
| 4f50 | 佐 | 佑 | 佒 | 体 | 占 | 何 | 佖 | 佗 | 佘 | 余 | 佚 | 佛 | 作 | 佝 | 佞 | 佟 |
| 4f60 | 你 | 佡 | 佢 | 佣 | 佤 | 佥 | 佦 | 佧 | 佨 | 佩 | 佪 | 佫 | 佬 | 佭 | 佮 | 佯 |
| 4f70 | 佰 | 佱 | 佲 | 佳 | 佴 | 并 | 佶 | 佷 | 佸 | 佹 | 佺 | 佻 | 佼 | 佽 | 佾 | 使 |
| 4f80 | 侀 | 侁 | 侂 | 侃 | 侄 | 侅 | 来 | 侇 | 侈 | 侉 | 侊 | 例 | 侌 | 侍 | 侎 | 侏 |
| 4f90 | 侐 | 侑 | 侒 | 侓 | 侔 | 侕 | 仑 | 侗 | 侘 | 侙 | 徇 | 供 | 侜 | 依 | 侞 | 侟 |
| 4fa0 | 侠 | 価 | 侢 | 侣 | 侤 | 侥 | 侦 | 侧 | 侨 | 侩 | 侪 | 侫 | 侬 | 侭 | 侮 | 侯 |
| 4fb0 | 侰 | 侱 | 侲 | 侳 | 侴 | 侵 | 侣 | 局 | 侸 | 侹 | 侺 | 侻 | 侼 | 侽 | 侾 | 便 |
| 4fc0 | 俀 | 俣 | 系 | 促 | 俄 | 俅 | 俆 | 俇 | 俈 | 俉 | 俊 | 俋 | 俌 | 俍 | 俎 | 俏 |
| 4fd0 | 俐 | 俑 | 俒 | 俓 | 俔 | 俕 | 俖 | 俗 | 俘 | 俙 | 俚 | 俛 | 俜 | 保 | 俞 | 俟 |
| 4fe0 | 侠 | 信 | 俢 | 俣 | 俤 | 俥 | 俦 | 俧 | 俨 | 俩 | 俪 | 俫 | 俬 | 俭 | 修 | 俯 |
| 4ff0 | 俰 | 俱 | 俲 | 俳 | 俴 | 表 | 俶 | 俷 | 俸 | 俹 | 俺 | 俻 | 俼 | 俽 | 俾 | 俿 |
| 5000 | 伥 | 倁 | 倂 | 倃 | 倄 | 倅 | 俩 | 倇 | 倈 | 仓 | 倊 | 个 | 倌 | 倍 | 倎 | 倏 |
| 5010 | 倐 | 们 | 倒 | 倓 | 倔 | 倕 | 幸 | 倗 | 倘 | 候 | 倚 | 倛 | 倜 | 倝 | 倞 | 借 |
| 5020 | 倠 | 倡 | 倢 | 仿 | 値 | 倥 | 倦 | 倧 | 倨 | 倩 | 倪 | 伦 | 倬 | 倭 | 倮 | 倯 |
| 5030 | 倰 | 倱 | 倲 | 倳 | 倴 | 倵 | 倶 | 倷 | 倸 | 倹 | 债 | 倻 | 值 | 倽 | 倾 | 倿 |
| 5040 | 偀 | 偁 | 偂 | 偃 | 偄 | 偅 | 偆 | 假 | 偈 | 伟 | 偊 | 偋 | 偌 | 偍 | 偎 | 偏 |
| 5050 | 偐 | 偑 | 偒 | 偓 | 偔 | 偕 | 偖 | 偗 | 偘 | 偙 | 做 | 偛 | 停 | 偝 | 偞 | 偟 |
| 5060 | 偠 | 偡 | 偢 | 偣 | 偤 | 健 | 偦 | 偧 | 偨 | 偩 | 逼 | 偫 | 偬 | 偭 | 偮 | 偯 |
| 5070 | 偰 | 偱 | 偲 | 偳 | 侧 | 侦 | 偶 | 偷 | 偸 | 偹 | 偺 | 偻 | 偼 | 伪 | 偾 | 偿 |
| 5080 | 傀 | 傁 | 傂 | 傃 | 傄 | 傅 | 傆 | 傇 | 僳 | 傉 | 傊 | 傋 | 傌 | 傍 | 傎 | 傏 |
| 5090 | 傐 | 杰 | 傒 | 傓 | 傔 | 傕 | 伧 | 傗 | 伞 | 备 | 效 | 傛 | 傜 | 傝 | 傞 | 傟 |
| 50a0 | 傠 | 傡 | 家 | 傣 | 傤 | 傥 | 傦 | 傧 | 储 | 傩 | 傪 | 傫 | 催 | 佣 | 傮 | 偬 |
| 50b0 | 傰 | 傱 | 傲 | 传 | 伛 | 债 | 傶 | 伤 | 傸 | 傹 | 傺 | 傻 | 傼 | 傽 | 倾 | 傿 |
| 50c0 | 僀 | 僁 | 偻 | 僃 | 僄 | 仅 | 僆 | 僇 | 僈 | 佥 | 仙 | 僋 | 僌 | 働 | 僎 | 像 |
| 50d0 | 僐 | 侨 | 僒 | 僓 | 僔 | 仆 | 僖 | 僗 | 僘 | 僙 | 僚 | 僛 | 僜 | 僝 | 伪 | 僟 |
| 50e0 | 僠 | 僡 | 僢 | 僣 | 僤 | 侥 | 僦 | 僧 | 偾 | 僩 | 僪 | 僫 | 僬 | 僭 | 僮 | 僯 |
| 50f0 | 僰 | 雇 | 僲 | 僳 | 僴 | 僵 | 僶 | 僷 | 僸 | 价 | 僺 | 僻 | 僼 | 僽 | 僾 | 僿 |
| 5100 | 仪 | 儁 | 侬 | 儃 | 亿 | 儅 | 儆 | 儇 | 侩 | 俭 | 儊 | 儋 | 儌 | 儍 | 儎 | 儏 |
| 5110 | 傧 | 儑 | 儒 | 儓 | 俦 | 侪 | 儖 | 儗 | 尽 | 儙 | 儚 | 儛 | 儜 | 儝 | 儞 | 偿 |
| 5120 | 儠 | 儡 | 儢 | 儣 | 儤 | 儥 | 儦 | 儧 | 儨 | 儩 | 优 | 儫 | 儬 | 儭 | 儮 | 儯 |
| 5130 | 儰 | 儱 | 储 | 儳 | 儴 | 儵 | 儶 | 俪 | 儸 | 儹 | 傩 | 傥 | 俨 | 儽 | 儾 | 儿 |
| 5140 | 兀 | 允 | 兂 | 元 | 兄 | 充 | 兆 | 凶 | 先 | 光 | 兊 | 克 | 兑 | 免 | 兎 | 兏 |
| 5150 | 児 | 兑 | 儿 | 兓 | 兔 | 兕 | 兖 | 兖 | 兘 | 兙 | 党 | 兛 | 兜 | 兝 | 兞 | 兟 |
| 5160 | 兠 | 兡 | 兢 | 兣 | 兤 | 入 | 兦 | 内 | 全 | 两 | 兪 | 八 | 公 | 六 | 兮 | 兯 |
| 5170 | 兰 | 共 | 兲 | 关 | 兴 | 兵 | 其 | 具 | 典 | 兹 | 兺 | 养 | 兼 | 兽 | 兾 | 兿 |
| 5180 | 冀 | 冁 | 冂 | 冃 | 冄 | 内 | 円 | 冇 | 冈 | 冉 | 册 | 冋 | 册 | 再 | 冎 | 冏 |
| 5190 | 冐 | 胄 | 冒 | 冓 | 冔 | 冕 | 冖 | 冗 | 冘 | 写 | 冚 | 军 | 农 | 冝 | 冞 | 冟 |
| 51a0 | 冠 | 冡 | 冢 | 冣 | 冤 | 冥 | 冦 | 冧 | 冨 | 冩 | 幂 | 冫 | 冬 | 冭 | 冮 | 冯 |
| 51b0 | 冰 | 冱 | 冲 | 决 | 冴 | 况 | 冶 | 冷 | 冸 | 冹 | 冺 | 冻 | 冼 | 冽 | 冾 | 冿 |
| 51c0 | 净 | 凁 | 凂 | 凃 | 凄 | 凅 | 准 | 凇 | 净 | 凉 | 凊 | 凋 | 凌 | 冻 | 凎 | 减 |
| 51D0 | 凐 | 凑 | 凒 | 凓 | 凔 | 凕 | 凖 | 凗 | 凘 | 凙 | 凚 | 凛 | 凛 | 凝 | 凞 | 凟 |
| 51E0 | 几 | 凡 | 凢 | 凣 | 凤 | 凥 | 処 | 凧 | 凨 | 凩 | 凪 | 凫 | 凬 | 凭 | 凮 | 凯 |
| 51F0 | 凰 | 凯 | 凲 | 凳 | 凴 | 凵 | 凶 | 凷 | 凸 | 凹 | 出 | 击 | 凼 | 函 | 凾 | 凿 |
| 5200 | 刀 | 刁 | 刂 | 刃 | 刄 | 刅 | 分 | 切 | 刈 | 刉 | 刊 | 刋 | 刌 | 刍 | 刎 | 刏 |
| 5210 | 刐 | 刑 | 划 | 刓 | 刔 | 刕 | 刖 | 列 | 刘 | 则 | 刚 | 创 | 刜 | 初 | 刞 | 刟 |
| 5220 | 删 | 刡 | 刢 | 刣 | 判 | 别 | 刦 | 刧 | 刨 | 利 | 删 | 别 | 刬 | 刭 | 刮 | 刯 |
| 5230 | 到 | 刱 | 刲 | 刳 | 刴 | 刵 | 制 | 刷 | 券 | 刹 | 刺 | 刻 | 刼 | 刽 | 刾 | 刿 |
| 5240 | 剀 | 剁 | 剂 | 剃 | 刭 | 剅 | 剆 | 则 | 剈 | 锉 | 削 | 克 | 剌 | 前 | 刹 | 剏 |
| 5250 | 剐 | 剑 | 剒 | 剓 | 剔 | 剕 | 剖 | 剗 | 剘 | 剙 | 剚 | 刚 | 剜 | 剥 | 剞 | 剟 |
| 5260 | 剠 | 剡 | 剢 | 剣 | 剤 | 剥 | 剦 | 剧 | 剨 | 剩 | 剪 | 剫 | 剬 | 剭 | 剐 | 副 |
| 5270 | 剰 | 剱 | 割 | 剳 | 剀 | 创 | 剶 | 铲 | 剸 | 剹 | 剺 | 剻 | 剼 | 剽 | 剾 | 剿 |
| 5280 | 劀 | 劁 | 劂 | 划 | 札 | 劅 | 劆 | 剧 | 劈 | 刘 | 刽 | 劋 | 刿 | 剑 | 劎 | 劏 |
| 5290 | 劐 | 剂 | 劒 | 劓 | 劔 | 劕 | 劖 | 劗 | 劘 | 劙 | 劚 | 力 | 劜 | 劝 | 办 | 功 |
| 52A0 | 加 | 务 | 劢 | 劣 | 劤 | 劥 | 劦 | 劧 | 动 | 助 | 努 | 劫 | 劬 | 劭 | 劮 | 劯 |
| 52B0 | 劰 | 励 | 劲 | 劳 | 労 | 劵 | 劶 | 劷 | 劸 | 効 | 劺 | 劻 | 劼 | 劽 | 劾 | 势 |
| 52C0 | 勀 | 劲 | 勂 | 勃 | 勄 | 勅 | 勆 | 勇 | 勈 | 勉 | 勊 | 勋 | 勌 | 勍 | 勎 | 勏 |
| 52D0 | 勐 | 勑 | 勒 | 勓 | 勔 | 动 | 勖 | 勗 | 勘 | 务 | 勚 | 勋 | 勜 | 胜 | 劳 | 募 |
| 52E0 | 勠 | 勡 | 势 | 勣 | 勤 | 勥 | 勦 | 勧 | 勨 | 勩 | 勪 | 勫 | 勬 | 勭 | 勮 | 勯 |
| 52F0 | 勰 | 劢 | 勲 | 勋 | 勴 | 励 | 勶 | 勷 | 劝 | 勹 | 勺 | 匀 | 勼 | 勽 | 勾 | 勿 |
| 5300 | 匀 | 匁 | 匂 | 匃 | 匄 | 包 | 匆 | 匇 | 匈 | 匉 | 匊 | 陶 | 匌 | 匍 | 匎 | 匏 |
| 5310 | 匐 | 匑 | 匒 | 匓 | 匔 | 匕 | 化 | 北 | 匘 | 匙 | 匚 | 匛 | 匜 | 匝 | 匞 | 匟 |
| 5320 | 匠 | 匡 | 匢 | 匣 | 匤 | 匥 | 匦 | 匧 | 匨 | 匩 | 匪 | 匫 | 匬 | 匦 | 匮 | 汇 |
| 5330 | 匰 | 匮 | 匲 | 匳 | 匴 | 匵 | 匶 | 匷 | 匸 | 匹 | 区 | 医 | 匼 | 匽 | 匾 | 匿 |
| 5340 | 区 | 十 | 卂 | 千 | 卄 | 卅 | 卆 | 升 | 午 | 卉 | 半 | 卋 | 卌 | 卍 | 华 | 协 |
| 5350 | 卐 | 卑 | 卒 | 卓 | 协 | 单 | 卖 | 南 | 単 | 卙 | 博 | 卛 | 卜 | 卝 | 卞 | 卟 |
| 5360 | 占 | 卡 | 卢 | 卣 | 卤 | 卥 | 卦 | 卧 | 卨 | 卩 | 卪 | 卫 | 卬 | 卭 | 卮 | 卯 |
| 5370 | 印 | 危 | 卲 | 即 | 却 | 卵 | 卶 | 卷 | 卸 | 恤 | 卺 | 却 | 卼 | 卽 | 卾 | 卿 |
| 5380 | 厀 | 厁 | 厂 | 厃 | 厄 | 厅 | 历 | 厇 | 厈 | 厉 | 厊 | 压 | 厌 | 厍 | 厎 | 厏 |
| 5390 | 厐 | 厑 | 厒 | 厓 | 厔 | 厕 | 厖 | 厗 | 厘 | 厍 | 厚 | 厛 | 厜 | 厝 | 厞 | 原 |
| 53a0 | 厕 | 厡 | 厢 | 厣 | 厤 | 厥 | 厦 | 厧 | 厨 | 厩 | 厪 | 厫 | 厬 | 厌 | 厮 | 厯 |
| 53b0 | 厰 | 厱 | 厉 | 厳 | 厣 | 厵 | 厶 | 厷 | 厸 | 厹 | 厺 | 去 | 厼 | 厽 | 厾 | 县 |
| 53c0 | 叀 | 叁 | 参 | 参 | 叄 | 叅 | 叆 | 叇 | 又 | 叉 | 及 | 友 | 双 | 反 | 収 | 叏 |
| 53d0 | 叐 | 发 | 叒 | 叓 | 叔 | 叕 | 取 | 受 | 变 | 叙 | 叚 | 叛 | 叜 | 叝 | 叞 | 叟 |
| 53e0 | 叠 | 叡 | 丛 | 口 | 古 | 句 | 另 | 叧 | 叨 | 叩 | 只 | 叫 | 召 | 叭 | 叮 | 可 |
| 53f0 | 台 | 叱 | 史 | 右 | 叴 | 叵 | 叶 | 号 | 司 | 叹 | 叺 | 叻 | 叼 | 叽 | 叾 | 叿 |
| 5400 | 吀 | 吁 | 吂 | 吃 | 各 | 吅 | 吆 | 吇 | 合 | 吉 | 吊 | 吋 | 同 | 名 | 后 | 吏 |
| 5410 | 吐 | 向 | 吒 | 吓 | 吔 | 吕 | 吖 | 吗 | 吘 | 吙 | 吚 | 君 | 吜 | 吝 | 吞 | 吟 |
| 5420 | 吠 | 吡 | 吢 | 吣 | 吤 | 吥 | 否 | 吧 | 吨 | 吩 | 吪 | 含 | 听 | 吭 | 吮 | 启 |
| 5430 | 吰 | 吱 | 吲 | 吴 | 吴 | 吵 | 呐 | 吷 | 吸 | 吹 | 吺 | 吻 | 吼 | 吽 | 吾 | 吿 |
| 5440 | 呀 | 呁 | 吕 | 呃 | 呄 | 呅 | 呆 | 呇 | 呈 | 呉 | 告 | 呋 | 呌 | 呍 | 呎 | 呏 |
| 5450 | 呐 | 呑 | 呒 | 呓 | 呔 | 呕 | 呖 | 呗 | 员 | 呙 | 呚 | 呛 | 呜 | 呝 | 呞 | 呟 |
| 5460 | 呠 | 呡 | 呢 | 呣 | 呤 | 呥 | 呦 | 呧 | 周 | 呩 | 呪 | 呫 | 呬 | 呭 | 呮 | 呯 |
| 5470 | 呰 | 呱 | 呲 | 味 | 呴 | 呵 | 呶 | 呷 | 呸 | 呹 | 呺 | 呻 | 呼 | 命 | 呾 | 呿 |
| 5480 | 咀 | 咁 | 咂 | 咃 | 咄 | 咅 | 咆 | 咇 | 咈 | 咉 | 咊 | 咋 | 和 | 咍 | 咎 | 咏 |
| 5490 | 咐 | 咑 | 咒 | 咓 | 咔 | 咕 | 咖 | 咗 | 咘 | 咙 | 咚 | 咛 | 咜 | 咝 | 咞 | 咟 |
| 54a0 | 咠 | 咡 | 咢 | 咣 | 咤 | 咥 | 咦 | 咧 | 咨 | 咩 | 咪 | 咫 | 咬 | 咭 | 咮 | 咯 |
| 54b0 | 咰 | 咱 | 咲 | 咳 | 咴 | 咵 | 咶 | 啕 | 咸 | 咹 | 咺 | 咻 | 呙 | 咽 | 咾 | 咿 |
| 54c0 | 哀 | 品 | 哂 | 哃 | 哄 | 哅 | 哆 | 哇 | 哈 | 哉 | 哊 | 哋 | 哌 | 响 | 哎 | 哏 |
| 54d0 | 哐 | 哑 | 哒 | 哓 | 哔 | 哕 | 哖 | 哗 | 哘 | 哙 | 哚 | 哛 | 哜 | 哝 | 哞 | 哟 |
| 54e0 | 哠 | 员 | 哢 | 哣 | 哤 | 哥 | 哦 | 哧 | 哨 | 哩 | 哪 | 哫 | 哬 | 哭 | 哮 | 哯 |
| 54f0 | 哰 | 哱 | 哲 | 哳 | 哴 | 哵 | 哶 | 哷 | 哸 | 哹 | 哺 | 哻 | 哼 | 哽 | 哾 | 哿 |
| 5500 | 唀 | 唁 | 唂 | 唃 | 呗 | 唅 | 唆 | 唇 | 唈 | 唉 | 唊 | 唋 | 唌 | 唍 | 唎 | 唏 |
| 5510 | 唐 | 唑 | 唒 | 唓 | 唔 | 唕 | 唖 | 唗 | 唘 | 唙 | 唚 | 唛 | 唜 | 唝 | 唞 | 唟 |
| 5520 | 唠 | 唡 | 唢 | 唣 | 唤 | 唥 | 唦 | 唧 | 唨 | 唩 | 唪 | 唫 | 唬 | 唭 | 售 | 唯 |
| 5530 | 唰 | 唱 | 唲 | 唳 | 唴 | 唵 | 唶 | 唷 | 念 | 唹 | 唺 | 唻 | 唼 | 唽 | 唾 | 唿 |
| 5540 | 啀 | 啁 | 啂 | 啃 | 啄 | 啅 | 商 | 啇 | 啈 | 啉 | 啊 | 啋 | 啌 | 啍 | 啎 | 问 |
| 5550 | 啐 | 啑 | 啒 | 启 | 啔 | 啕 | 啖 | 啗 | 啘 | 啙 | 啚 | 啛 | 啜 | 啝 | 哑 | 启 |
| 5560 | 啠 | 啡 | 啢 | 衔 | 啤 | 啥 | 啦 | 啧 | 啨 | 啩 | 啪 | 啫 | 啬 | 啭 | 啮 | 啯 |
| 5570 | 啰 | 啱 | 啲 | 啳 | 啴 | 啵 | 啶 | 啷 | 啸 | 啹 | 啺 | 啻 | 啼 | 啽 | 啾 | 啿 |
| 5580 | 喀 | 喁 | 喂 | 喃 | 善 | 喅 | 喆 | 喇 | 喈 | 喉 | 喊 | 喋 | 喌 | 喍 | 喎 | 喏 |
| 5590 | 喐 | 喑 | 喒 | 喓 | 喔 | 喕 | 喖 | 喗 | 喘 | 喙 | 唤 | 喛 | 喜 | 喝 | 喞 | 喟 |
| 55a0 | 喠 | 喡 | 喢 | 喣 | 喤 | 喥 | 喦 | 喧 | 喨 | 喩 | 丧 | 喫 | 乔 | 喭 | 单 | 喯 |
| 55b0 | 喰 | 喱 | 哟 | 喳 | 喴 | 喵 | 営 | 喷 | 喸 | 喹 | 喺 | 喻 | 喼 | 喽 | 喾 | 喿 |
| 55c0 | 嗀 | 嗁 | 嗂 | 嗃 | 嗄 | 嗅 | 呛 | 啬 | 嗈 | 嗉 | 嗊 | 嗋 | 嗌 | 嗍 | 吗 | 嗏 |
| 55d0 | 嗐 | 嗑 | 嗒 | 嗓 | 嗔 | 嗕 | 嗖 | 嗗 | 嗘 | 嗙 | 呜 | 嗛 | 嗜 | 嗝 | 嗞 | 嗟 |
| 55e0 | 嗠 | 嗡 | 嗢 | 嗣 | 嗤 | 嗥 | 嗦 | 嗧 | 嗨 | 唢 | 嗪 | 嗫 | 嗬 | 嗭 | 嗮 | 嗯 |
| 55f0 | 嗰 | 嗱 | 嗲 | 嗳 | 嗴 | 嗵 | 哔 | 嗷 | 嗸 | 嗹 | 嗺 | 嗻 | 嗼 | 嗽 | 嗾 | 嗿 |
| 5600 | 嘀 | 嘁 | 嘂 | 嘃 | 嘄 | 嘅 | 叹 | 嘇 | 嘈 | 嘉 | 嘊 | 嘋 | 嘌 | 喽 | 嘎 | 嘏 |
| 5610 | 嘐 | 嘑 | 嘒 | 嘓 | 呕 | 嘕 | 啧 | 尝 | 嘘 | 嘙 | 嘚 | 嘛 | 唛 | 嘝 | 嘞 | 嘟 |
| 5620 | 嘠 | 嘡 | 嘢 | 嘣 | 嘤 | 嘥 | 嘦 | 嘧 | 嘨 | 哗 | 嘪 | 嘫 | 嘬 | 嘭 | 唠 | 啸 |
| 5630 | 叽 | 嘱 | 嘲 | 嘳 | 嘴 | 哓 | 嘶 | 嘷 | 呒 | 嘹 | 嘺 | 嘻 | 嘼 | 嘽 | 嘾 | 嘿 |
| 5640 | 噀 | 恶 | 噂 | 噃 | 噄 | 噅 | 噆 | 噇 | 噈 | 噉 | 噊 | 噋 | 噌 | 噍 | 噎 | 噏 |
| 5650 | 噐 | 噑 | 噒 | 嘘 | 噔 | 噕 | 噖 | 噗 | 噘 | 噙 | 噚 | 噛 | 噜 | 噝 | 噞 | 噟 |
| 5660 | 哒 | 噡 | 噢 | 噣 | 噤 | 哝 | 哕 | 噧 | 器 | 噩 | 噪 | 噫 | 噬 | 噭 | 噮 | 嗳 |
| 5670 | 噰 | 噱 | 哙 | 噳 | 喷 | 噵 | 噶 | 噷 | 吨 | 当 | 噺 | 噻 | 噼 | 噽 | 噾 | 噿 |
| 5680 | 咛 | 嚁 | 嚂 | 嚃 | 嚄 | 嚅 | 嚆 | 吓 | 嚈 | 嚉 | 嚊 | 嚋 | 哜 | 嚍 | 嚎 | 嚏 |
| 5690 | 嚐 | 嚑 | 嚒 | 嚓 | 嚔 | 噜 | 嚖 | 嚗 | 嚘 | 啮 | 嚚 | 嚛 | 嚜 | 嚝 | 嚞 | 嚟 |
| 56a0 | 嚠 | 嚡 | 嚢 | 嚣 | 嚤 | 嚥 | 呖 | 嚧 | 咙 | 嚩 | 嚪 | 嚫 | 嚬 | 嚭 | 向 | 嚯 |
| 56b0 | 嚰 | 嚱 | 嚲 | 喾 | 严 | 嚵 | 嘤 | 嚷 | 嚸 | 嚹 | 嚺 | 嚻 | 嚼 | 嚽 | 嚾 | 嚿 |
| 56c0 | 啭 | 嗫 | 嚣 | 囃 | 囄 | 冁 | 囆 | 囇 | 呓 | 罗 | 囊 | 囋 | 囌 | 囍 | 囎 | 囏 |
| 56d0 | 囐 | 嘱 | 囒 | 囓 | 囔 | 囕 | 囖 | 囗 | 囘 | 囙 | 囚 | 四 | 囜 | 囝 | 回 | 囟 |
| 56e0 | 因 | 囡 | 团 | 団 | 囤 | 囥 | 囦 | 囧 | 囨 | 囩 | 囱 | 囫 | 囬 | 园 | 囮 | 囯 |
| 56f0 | 困 | 囱 | 囲 | 図 | 围 | 囵 | 囶 | 囷 | 囸 | 囹 | 固 | 囻 | 囼 | 国 | 图 | 囿 |
| 5700 | 圀 | 圁 | 圂 | 圃 | 圄 | 圅 | 圆 | 囵 | 圈 | 圉 | 圊 | 国 | 圌 | 围 | 圎 | 圏 |
| 5710 | 圐 | 圑 | 园 | 圆 | 圔 | 圕 | 图 | 圗 | 团 | 圙 | 圚 | 圛 | 圜 | 圝 | 圞 | 土 |
| 5720 | 圠 | 圡 | 圢 | 圣 | 圤 | 圥 | 圦 | 圧 | 在 | 圩 | 圪 | 圫 | 圬 | 圭 | 圮 | 圯 |
| 5730 | 地 | 圱 | 圲 | 圳 | 圴 | 圵 | 圶 | 圷 | 圸 | 圹 | 场 | 圻 | 圼 | 圽 | 圾 | 圿 |
| 5740 | 址 | 坁 | 坂 | 坃 | 坄 | 坅 | 坆 | 均 | 坈 | 坉 | 坊 | 坋 | 坌 | 坍 | 坎 | 坏 |
| 5750 | 坐 | 坑 | 坒 | 坓 | 坔 | 坕 | 坖 | 块 | 坘 | 坙 | 坚 | 坛 | 坜 | 坝 | 坞 | 坟 |
| 5760 | 坠 | 坡 | 坢 | 坣 | 坤 | 坥 | 坦 | 坧 | 坨 | 坩 | 坪 | 坫 | 坬 | 坭 | 坮 | 坯 |
| 5770 | 坰 | 坱 | 坲 | 坳 | 坴 | 丘 | 坶 | 坷 | 坸 | 坹 | 坺 | 坻 | 坼 | 坽 | 坾 | 坿 |
| 5780 | 垀 | 垁 | 垂 | 垃 | 垄 | 垅 | 垆 | 垇 | 垈 | 垉 | 垊 | 型 | 垌 | 垍 | 垎 | 垏 |
| 5790 | 垐 | 垑 | 垒 | 垓 | 垔 | 垕 | 垖 | 垗 | 垘 | 垙 | 垚 | 垛 | 垜 | 垝 | 垞 | 垟 |
| 57a0 | 垠 | 垡 | 垢 | 垣 | 垤 | 垥 | 垦 | 垧 | 垨 | 垩 | 垪 | 垫 | 垬 | 垭 | 垮 | 垯 |
| 57b0 | 垰 | 垱 | 垲 | 垳 | 垴 | 垵 | 垶 | 垷 | 垸 | 垹 | 垺 | 垻 | 垼 | 垽 | 垾 | 垿 |
| 57c0 | 埀 | 埁 | 埂 | 埃 | 埄 | 埅 | 埆 | 埇 | 埈 | 埉 | 埊 | 埋 | 埌 | 埍 | 城 | 埏 |
| 57d0 | 埐 | 埑 | 埒 | 埓 | 埔 | 埕 | 埖 | 埗 | 埘 | 埙 | 埚 | 埛 | 埜 | 埝 | 埞 | 域 |
| 57e0 | 埠 | 垭 | 埢 | 埣 | 埤 | 埥 | 埦 | 埧 | 埨 | 埩 | 埪 | 埫 | 埬 | 埭 | 埮 | 埯 |
| 57f0 | 埰 | 埱 | 埲 | 埳 | 埴 | 埵 | 埶 | 执 | 埸 | 培 | 基 | 埻 | 埼 | 埽 | 埾 | 埿 |
| 5800 | 堀 | 堁 | 堂 | 堃 | 堄 | 坚 | 堆 | 堇 | 堈 | 堉 | 垩 | 堋 | 堌 | 堍 | 堎 | 堏 |
| 5810 | 堐 | 堑 | 堒 | 堓 | 堔 | 堕 | 堖 | 堗 | 堘 | 堙 | 堚 | 堛 | 堜 | 埚 | 堞 | 堟 |
| 5820 | 堠 | 堡 | 堢 | 堣 | 堤 | 堥 | 堦 | 堧 | 堨 | 堩 | 堪 | 堫 | 堬 | 堭 | 堮 | 尧 |
| 5830 | 堰 | 报 | 堲 | 堳 | 场 | 堵 | 堶 | 堷 | 堸 | 堹 | 堺 | 堻 | 堼 | 堽 | 堾 | 堿 |
| 5840 | 塀 | 塁 | 塂 | 塃 | 塄 | 塅 | 塆 | 塇 | 塈 | 塉 | 块 | 茔 | 塌 | 塍 | 塎 | 垲 |
| 5850 | 塐 | 塑 | 埘 | 塓 | 塔 | 塕 | 塖 | 涂 | 塘 | 塙 | 冢 | 塛 | 塜 | 塝 | 塞 | 塟 |
| 5860 | 塠 | 塡 | 坞 | 塣 | 埙 | 塥 | 塦 | 塧 | 塨 | 塩 | 塪 | 填 | 塬 | 塭 | 塮 | 塯 |
| 5870 | 塰 | 塱 | 塲 | 塳 | 塴 | 尘 | 塶 | 塷 | 塸 | 堑 | 塺 | 塻 | 塼 | 塽 | 塾 | 塿 |
| 5880 | 墀 | 墁 | 墂 | 境 | 墄 | 墅 | 墆 | 墇 | 墈 | 墉 | 垫 | 墋 | 墌 | 墍 | 墎 | 墏 |
| 5890 | 墐 | 墑 | 墒 | 墓 | 墔 | 墕 | 墖 | 増 | 墘 | 墙 | 墚 | 墛 | 坠 | 墝 | 增 | 墟 |
| 58a0 | 墠 | 墡 | 墢 | 墣 | 墤 | 墥 | 墦 | 墧 | 墨 | 墩 | 墪 | 墫 | 墬 | 墭 | 堕 | 墯 |
| 58b0 | 墰 | 墱 | 墲 | 坟 | 墴 | 墵 | 墶 | 墷 | 墸 | 墹 | 墺 | 墻 | 墼 | 墽 | 垦 | 墿 |
| 58c0 | 壀 | 壁 | 壂 | 壃 | 壄 | 壅 | 壆 | 坛 | 壈 | 壉 | 壊 | 壋 | 壌 | 壍 | 壎 | 壏 |
| 58d0 | 壐 | 壑 | 壒 | 压 | 壔 | 壕 | 壖 | 壗 | 垒 | 圹 | 垆 | 壛 | 壜 | 壝 | 坏 | 垄 |
| 58e0 | 壠 | 壡 | 坜 | 壣 | 壤 | 壥 | 壦 | 壧 | 壨 | 坝 | 壪 | 士 | 壬 | 壭 | 壮 | 壮 |
| 58f0 | 声 | 壱 | 売 | 壳 | 壴 | 壵 | 壶 | 壷 | 壸 | 壹 | 壶 | 壻 | 壼 | 寿 | 壾 | 壿 |
| 5900 | 夀 | 夁 | 夂 | 夃 | 处 | 夅 | 夆 | 备 | 夈 | 変 | 夊 | 夋 | 夌 | 复 | 夎 | 夏 |
| 5910 | 夐 | 夑 | 夒 | 夓 | 夔 | 夕 | 外 | 夗 | 夘 | 夙 | 多 | 夛 | 夜 | 夝 | 夞 | 够 |
| 5920 | 够 | 夡 | 梦 | 夣 | 夤 | 夥 | 夦 | 大 | 夨 | 天 | 太 | 夫 | 夬 | 夭 | 央 | 夯 |
| 5930 | 夰 | 失 | 夲 | 夳 | 头 | 夵 | 夶 | 夷 | 夸 | 夹 | 夺 | 夻 | 夼 | 夽 | 夹 | 夿 |
| 5940 | 奀 | 奁 | 奂 | 奃 | 奄 | 奅 | 奆 | 奇 | 奈 | 奉 | 奊 | 奋 | 奌 | 奍 | 奎 | 奏 |
| 5950 | 奂 | 契 | 奒 | 奓 | 奔 | 奕 | 奖 | 套 | 奘 | 奙 | 奚 | 奛 | 奜 | 奝 | 奞 | 奟 |
| 5960 | 奠 | 奡 | 奢 | 奣 | 奤 | 奥 | 奦 | 奥 | 奨 | 奁 | 夺 | 奫 | 奖 | 奭 | 奋 | 奯 |
| 5970 | 奰 | 奱 | 奲 | 女 | 奴 | 奵 | 奶 | 奷 | 奸 | 她 | 奺 | 奻 | 奼 | 好 | 奾 | 奿 |
| 5980 | 妀 | 妁 | 如 | 妃 | 妄 | 妅 | 妆 | 妇 | 妈 | 妉 | 妊 | 妋 | 妌 | 妍 | 妎 | 妏 |
| 5990 | 妐 | 妑 | 妒 | 妓 | 妔 | 妕 | 妖 | 妗 | 妘 | 妙 | 妚 | 妛 | 妜 | 妆 | 妞 | 妟 |
| 59a0 | 妠 | 妡 | 妢 | 妣 | 妤 | 妥 | 妦 | 妧 | 妨 | 妩 | 妪 | 妫 | 妬 | 妭 | 妮 | 妯 |
| 59b0 | 妰 | 妱 | 妲 | 你 | 妴 | 妵 | 妶 | 妷 | 妸 | 妹 | 妺 | 妻 | 妼 | 妽 | 妾 | 妿 |
| 59c0 | 姀 | 姁 | 姂 | 姃 | 姄 | 姅 | 姆 | 姇 | 姈 | 姉 | 姊 | 始 | 姌 | 姗 | 姎 | 姏 |
| 59d0 | 姐 | 姑 | 姒 | 姓 | 委 | 姕 | 姖 | 姗 | 姘 | 姙 | 姚 | 姛 | 姜 | 姝 | 姞 | 姟 |
| 59e0 | 姠 | 姡 | 姢 | 姣 | 姤 | 姥 | 奸 | 姧 | 姨 | 姩 | 侄 | 姫 | 姬 | 姭 | 姮 | 姯 |
| 59f0 | 姰 | 姱 | 姲 | 姳 | 姴 | 姵 | 姶 | 姷 | 姸 | 姹 | 姺 | 姻 | 姼 | 姽 | 姾 | 姿 |
| 5a00 | 娀 | 威 | 娂 | 娃 | 娄 | 娅 | 娆 | 娇 | 娈 | 娉 | 娊 | 娋 | 娌 | 娍 | 娎 | 娏 |
| 5a10 | 娐 | 娑 | 娒 | 娓 | 娔 | 娕 | 娖 | 娗 | 娘 | 娙 | 娚 | 娱 | 娜 | 娝 | 娞 | 娟 |
| 5a20 | 娠 | 娡 | 娢 | 娣 | 娤 | 娥 | 娦 | 娧 | 娨 | 娩 | 娪 | 娫 | 娬 | 娭 | 娮 | 娯 |
| 5a30 | 娰 | 娱 | 娲 | 娳 | 娴 | 娵 | 娶 | 娷 | 娸 | 娹 | 娺 | 娻 | 娼 | 娽 | 娾 | 娿 |
| 5a40 | 婀 | 娄 | 婂 | 婃 | 婄 | 婅 | 婆 | 婇 | 婈 | 婉 | 婊 | 婋 | 婌 | 婍 | 婎 | 婏 |
| 5a50 | 婐 | 婑 | 婒 | 婓 | 婔 | 婕 | 婖 | 婗 | 婘 | 婙 | 婚 | 婛 | 婜 | 婝 | 婞 | 婟 |
| 5a60 | 婠 | 婡 | 婢 | 婣 | 婤 | 婥 | 妇 | 婧 | 婨 | 婩 | 婪 | 婫 | 婬 | 娅 | 婮 | 婯 |
| 5a70 | 婰 | 婱 | 婲 | 婳 | 婴 | 婵 | 婶 | 婷 | 婸 | 婹 | 婺 | 婻 | 婼 | 婽 | 婾 | 婿 |
| 5a80 | 媀 | 媁 | 媂 | 媃 | 媄 | 媅 | 媆 | 媇 | 媈 | 媉 | 媊 | 媋 | 媌 | 媍 | 媎 | 媏 |
| 5a90 | 媐 | 媑 | 媒 | 媓 | 媔 | 媕 | 媖 | 媗 | 媘 | 媙 | 媚 | 媛 | 媜 | 媝 | 媞 | 媟 |
| 5aa0 | 媠 | 媡 | 媢 | 媣 | 媤 | 媥 | 媦 | 娲 | 媨 | 媩 | 媪 | 媫 | 媬 | 媭 | 媮 | 妫 |
| 5ab0 | 媰 | 媱 | 媲 | 媳 | 媴 | 媵 | 媶 | 媷 | 媸 | 媹 | 媺 | 媻 | 媪 | 妈 | 媾 | 媿 |
| 5ac0 | 嫀 | 嫁 | 嫂 | 嫃 | 嫄 | 嫅 | 嫆 | 嫇 | 嫈 | 嫉 | 嫊 | 嫋 | 嫌 | 嫍 | 嫎 | 嫏 |
| 5ad0 | 嫐 | 嫑 | 嫒 | 嫓 | 嫔 | 嫕 | 嫖 | 妪 | 嫘 | 嫙 | 嫚 | 嫛 | 嫜 | 嫝 | 嫞 | 嫟 |
| 5ae0 | 嫠 | 嫡 | 嫢 | 嫣 | 嫤 | 嫥 | 嫦 | 嫧 | 嫨 | 嫩 | 嫪 | 嫫 | 嫬 | 嫭 | 嫮 | 嫯 |
| 5af0 | 嫰 | 嫱 | 嫲 | 嫳 | 嫴 | 妩 | 嫶 | 嫷 | 嫸 | 嫹 | 嫺 | 娴 | 嫼 | 嫽 | 嫾 | 嫿 |
| 5b00 | 妫 | 嬁 | 嬂 | 嬃 | 嬄 | 嬅 | 嬆 | 嬇 | 娆 | 嬉 | 嬊 | 婵 | 娇 | 嬍 | 嬎 | 嬏 |
| 5b10 | 嬐 | 嬑 | 嬒 | 嬓 | 嬔 | 嬕 | 嬖 | 嬗 | 嬘 | 嫱 | 嬚 | 嬛 | 嬜 | 嬝 | 嬞 | 嬟 |
| 5b20 | 嬠 | 嫒 | 嬢 | 嬣 | 嬷 | 嬥 | 嬦 | 嬧 | 嬨 | 嬩 | 嫔 | 嬫 | 嬬 | 嬭 | 嬮 | 嬯 |
| 5b30 | 婴 | 嬱 | 嬲 | 嬳 | 嬴 | 嬵 | 嬶 | 嬷 | 婶 | 嬹 | 嬺 | 嬻 | 嬼 | 嬽 | 嬾 | 嬿 |
| 5b40 | 孀 | 孁 | 孂 | 娘 | 孄 | 孅 | 孆 | 孇 | 孈 | 孉 | 孊 | 孋 | 娈 | 孍 | 孎 | 孏 |
| 5b50 | 子 | 孑 | 孒 | 孓 | 孔 | 孕 | 孖 | 字 | 存 | 孙 | 孚 | 孛 | 孜 | 孝 | 孞 | 孟 |
| 5b60 | 孠 | 孡 | 孢 | 季 | 孤 | 孥 | 学 | 孧 | 孨 | 孩 | 孪 | 孙 | 孬 | 孭 | 孮 | 孯 |
| 5b70 | 孰 | 孱 | 孲 | 孳 | 孴 | 孵 | 孶 | 孷 | 学 | 孹 | 孺 | 孻 | 孼 | 孽 | 孾 | 孪 |
| 5b80 | 宀 | 宁 | 宂 | 它 | 宄 | 宅 | 宆 | 宇 | 守 | 安 | 宊 | 宋 | 完 | 宍 | 宎 | 宏 |
| 5b90 | 宐 | 宑 | 宒 | 宓 | 宔 | 宕 | 宖 | 宗 | 官 | 宙 | 定 | 宛 | 宜 | 宝 | 实 | 実 |
| 5ba0 | 宠 | 审 | 客 | 宣 | 室 | 宥 | 宦 | 宧 | 宨 | 宩 | 宪 | 宫 | 宬 | 宭 | 宫 | 宯 |
| 5bb0 | 宰 | 宱 | 宲 | 害 | 宴 | 宵 | 家 | 宷 | 宸 | 容 | 宺 | 宻 | 宼 | 宽 | 宾 | 宿 |
| 5bc0 | 寀 | 寁 | 寂 | 寃 | 寄 | 寅 | 密 | 寇 | 寈 | 寉 | 寊 | 寋 | 富 | 寍 | 寎 | 寏 |
| 5bd0 | 寐 | 寑 | 寒 | 寓 | 寔 | 寕 | 寖 | 寗 | 寘 | 寙 | 寚 | 寛 | 寜 | 寝 | 寞 | 察 |
| 5be0 | 寠 | 寡 | 寝 | 寣 | 寤 | 寥 | 实 | 宁 | 寨 | 审 | 寪 | 写 | 宽 | 寭 | 寮 | 寯 |
| 5bf0 | 寰 | 寱 | 寲 | 寳 | 寴 | 宠 | 宝 | 寷 | 寸 | 对 | 寺 | 寻 | 导 | 寽 | 対 | 寿 |
| 5c00 | 尀 | 封 | 専 | 尃 | 射 | 尅 | 将 | 将 | 专 | 尉 | 尊 | 寻 | 尌 | 对 | 导 | 小 |
| 5c10 | 尐 | 少 | 尒 | 尓 | 尔 | 尕 | 尖 | 尗 | 尘 | 尙 | 尚 | 尛 | 尜 | 尝 | 尞 | 尟 |
| 5c20 | 尠 | 尡 | 尢 | 尣 | 尤 | 尥 | 尦 | 尧 | 尨 | 尩 | 尪 | 尫 | 尬 | 尭 | 尮 | 尯 |
| 5c30 | 尰 | 就 | 尲 | 尳 | 尴 | 尵 | 尶 | 尴 | 尸 | 尹 | 尺 | 尻 | 尼 | 尽 | 尾 | 尿 |
| 5c40 | 局 | 屁 | 层 | 屃 | 屄 | 居 | 届 | 屇 | 屈 | 屉 | 届 | 屋 | 屌 | 屍 | 屎 | 屏 |
| 5c50 | 屐 | 屑 | 屒 | 屓 | 屔 | 展 | 屖 | 屗 | 屘 | 屙 | 屚 | 屛 | 屉 | 屝 | 属 | 屟 |
| 5c60 | 屠 | 屡 | 屡 | 屣 | 层 | 履 | 屦 | 屧 | 屦 | 屩 | 屪 | 屫 | 属 | 屭 | 屮 | 屯 |
| 5c70 | 屰 | 山 | 屲 | 屳 | 屴 | 屵 | 屶 | 屷 | 屸 | 屹 | 屺 | 屻 | 屼 | 屽 | 屾 | 屿 |
| 5c80 | 岀 | 岁 | 岂 | 岃 | 岄 | 岅 | 岆 | 岇 | 岈 | 岉 | 岊 | 岋 | 岌 | 岍 | 岎 | 岏 |
| 5c90 | 岐 | 岑 | 岒 | 岓 | 岔 | 岕 | 岖 | 岗 | 岘 | 岙 | 岚 | 岛 | 岜 | 岝 | 岞 | 岟 |
| 5ca0 | 岠 | 冈 | 岢 | 岣 | 岤 | 岥 | 岦 | 岧 | 岨 | 岩 | 岪 | 岫 | 岬 | 岭 | 岮 | 岯 |
| 5cb0 | 岰 | 岱 | 岲 | 岳 | 岴 | 岵 | 岶 | 岷 | 岸 | 岹 | 岺 | 岻 | 岼 | 岽 | 岾 | 岿 |
| 5cc0 | 峀 | 峁 | 峂 | 峃 | 峄 | 峅 | 峆 | 峇 | 峈 | 峉 | 峊 | 峋 | 峌 | 峍 | 峎 | 峏 |
| 5cd0 | 峐 | 峑 | 峒 | 峓 | 峔 | 峕 | 峖 | 峗 | 峘 | 峙 | 峚 | 峛 | 峜 | 峝 | 峞 | 峟 |
| 5ce0 | 峠 | 峡 | 峢 | 峣 | 峤 | 峥 | 峦 | 峧 | 峨 | 峩 | 峪 | 峫 | 峬 | 峭 | 峮 | 峯 |
| 5cf0 | 峰 | 峱 | 峲 | 峳 | 岘 | 峵 | 岛 | 峷 | 峸 | 峹 | 峺 | 峻 | 峼 | 峡 | 峾 | 峿 |
| 5d00 | 崀 | 崁 | 崂 | 崃 | 崄 | 崅 | 崆 | 崇 | 崈 | 崉 | 崊 | 崋 | 崌 | 崃 | 崎 | 崏 |
| 5d10 | 崐 | 昆 | 崒 | 崓 | 崔 | 崕 | 崖 | 岗 | 崘 | 仑 | 崚 | 崛 | 崜 | 崝 | 崞 | 崟 |
| 5d20 | 崠 | 崡 | 峥 | 崣 | 崤 | 崥 | 崦 | 崧 | 崨 | 崩 | 崪 | 崫 | 崬 | 崭 | 崮 | 崯 |
| 5d30 | 崰 | 崱 | 崲 | 嵛 | 崴 | 崵 | 崶 | 崷 | 崸 | 崹 | 崺 | 崻 | 崼 | 崽 | 崾 | 崿 |
| 5d40 | 嵀 | 嵁 | 嵂 | 嵃 | 嵄 | 嵅 | 嵆 | 嵇 | 嵈 | 嵉 | 嵊 | 嵋 | 嵌 | 嵍 | 嵎 | 嵏 |
| 5d50 | 岚 | 嵑 | 嵒 | 嵓 | 嵔 | 嵕 | 嵖 | 嵗 | 嵘 | 嵙 | 嵚 | 嵛 | 嵜 | 嵝 | 嵞 | 嵟 |
| 5d60 | 嵠 | 嵡 | 嵢 | 嵣 | 嵤 | 嵥 | 嵦 | 嵧 | 嵨 | 嵩 | 嵪 | 嵫 | 嵬 | 嵭 | 嵮 | 嵯 |
| 5d70 | 嵰 | 嵱 | 嵲 | 嵳 | 嵴 | 嵵 | 嵶 | 嵷 | 嵸 | 嵹 | 嵺 | 嵻 | 嵼 | 嵽 | 嵾 | 嵿 |
| 5d80 | 嶀 | 嵝 | 嶂 | 嶃 | 崭 | 嶅 | 嶆 | 岖 | 嶈 | 嶉 | 嶊 | 嶋 | 嶌 | 嶍 | 嶎 | 嶏 |
| 5d90 | 嶐 | 嶑 | 嶒 | 嶓 | 嶔 | 嶕 | 嶖 | 崂 | 嶘 | 嶙 | 嶚 | 嶛 | 嶜 | 嶝 | 嶞 | 嶟 |
| 5da0 | 峤 | 嶡 | 嶢 | 嶣 | 嶤 | 嶥 | 嶦 | 峄 | 嶨 | 嶩 | 嶪 | 嶫 | 嶬 | 嶭 | 嶮 | 嶯 |
| 5db0 | 嶰 | 嶱 | 嶲 | 嶳 | 嶴 | 嶵 | 嶶 | 嶷 | 嵘 | 嶹 | 岭 | 嶻 | 屿 | 岳 | 嶾 | 嶿 |
| 5dc0 | 巀 | 巁 | 巂 | 巃 | 巄 | 巅 | 巆 | 巇 | 巈 | 巉 | 巊 | 岿 | 巌 | 巍 | 巎 | 巏 |
| 5dd0 | 巐 | 巑 | 峦 | 巓 | 巅 | 巕 | 巖 | 巗 | 巘 | 巙 | 巚 | 巛 | 巜 | 川 | 州 | 巟 |
| 5de0 | 巠 | 巡 | 巢 | 巣 | 巤 | 工 | 左 | 巧 | 巨 | 巩 | 巪 | 巫 | 巬 | 巭 | 差 | 巯 |
| 5df0 | 巯 | 己 | 已 | 巳 | 巴 | 巵 | 巶 | 巷 | 巸 | 卺 | 巺 | 巻 | 巼 | 巽 | 巾 | 巿 |
| 5e00 | 帀 | 币 | 市 | 布 | 帄 | 帅 | 帆 | 帇 | 师 | 帉 | 帊 | 帋 | 希 | 帍 | 帎 | 帏 |
| 5e10 | 帐 | 帑 | 帒 | 帓 | 帔 | 帕 | 帖 | 帗 | 帘 | 帙 | 帚 | 帛 | 帜 | 帝 | 帞 | 帟 |
| 5e20 | 帠 | 帡 | 帢 | 帣 | 帤 | 帅 | 带 | 帧 | 帨 | 帩 | 帪 | 师 | 帬 | 席 | 帮 | 帯 |
| 5e30 | 帰 | 帱 | 帲 | 帐 | 帴 | 帵 | 带 | 帷 | 常 | 帹 | 帺 | 帻 | 帼 | 帽 | 帾 | 帿 |
| 5e40 | 帧 | 幁 | 幂 | 帏 | 幄 | 幅 | 幆 | 幇 | 幈 | 幉 | 幊 | 幋 | 幌 | 幍 | 幎 | 幏 |
| 5e50 | 幐 | 幑 | 幒 | 幓 | 幔 | 幕 | 幖 | 帼 | 帻 | 幙 | 幚 | 幛 | 幜 | 幝 | 幞 | 帜 |
| 5e60 | 幠 | 幡 | 幢 | 币 | 幤 | 幥 | 幦 | 幧 | 幨 | 幩 | 幪 | 帮 | 帱 | 幭 | 幮 | 幯 |
| 5e70 | 幰 | 幱 | 干 | 平 | 年 | 开 | 并 | 幷 | 幸 | 干 | 幺 | 幻 | 幼 | 幽 | 几 | 广 |
| 5e80 | 庀 | 庁 | 庂 | 広 | 庄 | 庅 | 庆 | 庇 | 庈 | 庉 | 床 | 庋 | 庌 | 庍 | 庎 | 序 |
| 5e90 | 庐 | 庑 | 庒 | 库 | 应 | 底 | 庖 | 店 | 庘 | 庙 | 庚 | 庛 | 府 | 庝 | 庞 | 废 |
| 5ea0 | 庠 | 庡 | 庢 | 庣 | 庤 | 庥 | 度 | 座 | 庨 | 庩 | 庪 | 库 | 庬 | 庭 | 庮 | 庯 |
| 5eb0 | 庰 | 庱 | 庲 | 庳 | 庴 | 庵 | 庶 | 康 | 庸 | 庹 | 庺 | 庻 | 庼 | 庽 | 庾 | 庿 |
| 5ec0 | 廀 | 厕 | 厢 | 廃 | 厩 | 廅 | 廆 | 廇 | 厦 | 廉 | 廊 | 廋 | 廌 | 廍 | 廎 | 廏 |
| 5ed0 | 廐 | 廑 | 廒 | 廓 | 廔 | 廕 | 廖 | 廗 | 廘 | 廙 | 厨 | 廛 | 廜 | 廝 | 廞 | 庙 |
| 5ee0 | 厂 | 庑 | 废 | 广 | 廤 | 廥 | 廦 | 廧 | 廨 | 廪 | 廪 | 廫 | 庐 | 廭 | 廮 | 廯 |
| 5ef0 | 廰 | 廱 | 廲 | 厅 | 廴 | 廵 | 延 | 廷 | 廸 | 廹 | 建 | 廻 | 廼 | 廽 | 廾 | 廿 |
| 5f00 | 开 | 弁 | 异 | 弃 | 弄 | 弅 | 弆 | 弇 | 弈 | 弉 | 弊 | 弋 | 弌 | 弍 | 弎 | 式 |
| 5f10 | 弐 | 弑 | 弑 | 弓 | 吊 | 引 | 弖 | 弗 | 弘 | 弙 | 弚 | 弛 | 弜 | 弝 | 弞 | 弟 |
| 5f20 | 张 | 弡 | 弢 | 弣 | 弤 | 弥 | 弦 | 弧 | 弨 | 弩 | 弪 | 弫 | 弬 | 弭 | 弮 | 弯 |
| 5f30 | 弰 | 弱 | 弲 | 弪 | 弴 | 张 | 弶 | 强 | 弸 | 弹 | 强 | 弻 | 弼 | 弽 | 弾 | 弿 |
| 5f40 | 彀 | 彁 | 彂 | 彃 | 彄 | 彅 | 彆 | 彇 | 弹 | 彉 | 彊 | 彋 | 弥 | 彍 | 弯 | 彏 |
| 5f50 | 彐 | 彑 | 归 | 当 | 彔 | 录 | 彖 | 彗 | 彘 | 汇 | 彚 | 彛 | 彜 | 彝 | 彞 | 彟 |
| 5f60 | 彠 | 彡 | 形 | 彣 | 彤 | 彦 | 彦 | 彧 | 彨 | 彩 | 彪 | 雕 | 彬 | 彭 | 彮 | 彯 |
| 5f70 | 彰 | 影 | 彲 | 彳 | 彴 | 彵 | 彶 | 彷 | 彸 | 役 | 彺 | 彻 | 彼 | 彽 | 彾 | 佛 |
| 5f80 | 往 | 征 | 徂 | 徃 | 径 | 待 | 徆 | 徇 | 很 | 徉 | 徊 | 律 | 後 | 徍 | 徎 | 徏 |
| 5f90 | 徐 | 径 | 徒 | 従 | 徔 | 徕 | 徖 | 得 | 徘 | 徙 | 徚 | 徛 | 徜 | 徝 | 从 | 徟 |
| 5fa0 | 徕 | 御 | 徢 | 徣 | 徤 | 徥 | 徦 | 徧 | 徨 | 复 | 循 | 徫 | 徬 | 徭 | 微 | 徯 |
| 5fb0 | 徰 | 徱 | 徲 | 徳 | 徴 | 徵 | 徶 | 德 | 徸 | 彻 | 徺 | 徻 | 徼 | 徽 | 徾 | 徿 |
| 5fc0 | 忀 | 忁 | 忂 | 心 | 忄 | 必 | 忆 | 忇 | 忈 | 忉 | 忊 | 忋 | 忌 | 忍 | 忎 | 忏 |
| 5fd0 | 忐 | 忑 | 忒 | 忓 | 忔 | 忕 | 忖 | 志 | 忘 | 忙 | 忚 | 忛 | 応 | 忝 | 忞 | 忟 |
| 5fe0 | 忠 | 忡 | 忢 | 忣 | 忤 | 忥 | 忦 | 忧 | 忨 | 忩 | 忪 | 快 | 忬 | 忭 | 忮 | 忯 |
| 5ff0 | 忰 | 忱 | 忲 | 忳 | 忴 | 念 | 忶 | 汹 | 忸 | 忹 | 忺 | 忻 | 忼 | 忽 | 忾 | 忿 |
| 6000 | 怀 | 态 | 怂 | 怃 | 怄 | 怅 | 怆 | 怇 | 怈 | 怉 | 怊 | 怋 | 怌 | 怍 | 怎 | 怏 |
| 6010 | 怐 | 怑 | 怒 | 怓 | 怔 | 怕 | 怖 | 怗 | 怘 | 怙 | 怚 | 怛 | 怜 | 思 | 怞 | 怟 |
| 6020 | 怠 | 怡 | 怢 | 怣 | 怤 | 急 | 怦 | 性 | 怨 | 怩 | 怪 | 怫 | 怬 | 怭 | 怮 | 怯 |
| 6030 | 怰 | 怱 | 怲 | 怳 | 怴 | 怵 | 怶 | 怷 | 怸 | 怹 | 怺 | 总 | 怼 | 怽 | 怾 | 怿 |
| 6040 | 恀 | 恁 | 恂 | 恃 | 恄 | 恅 | 恒 | 恇 | 恈 | 恉 | 恊 | 恋 | 恌 | 恍 | 恎 | 恏 |
| 6050 | 恐 | 恑 | 恒 | 恓 | 恔 | 恕 | 恖 | 恗 | 恘 | 恙 | 恚 | 恛 | 恜 | 恝 | 恞 | 汹 |
| 6060 | 恠 | 恡 | 恢 | 恣 | 恤 | 耻 | 恦 | 恧 | 恨 | 恩 | 恪 | 恫 | 恬 | 恭 | 恮 | 息 |
| 6070 | 恰 | 恱 | 恲 | 恳 | 恴 | 恵 | 恶 | 恷 | 恸 | 恹 | 恺 | 恻 | 恼 | 恽 | 恾 | 恿 |
| 6080 | 悀 | 悁 | 悂 | 悃 | 悄 | 悦 | 悆 | 悇 | 悈 | 悉 | 悊 | 悋 | 悌 | 悍 | 悎 | 悏 |
| 6090 | 悐 | 悑 | 悒 | 悓 | 悔 | 悕 | 悖 | 悗 | 悘 | 悙 | 悚 | 悛 | 悜 | 悝 | 悞 | 悟 |
| 60a0 | 悠 | 悡 | 悢 | 患 | 悤 | 悥 | 悦 | 悧 | 您 | 悩 | 悪 | 悫 | 悬 | 悭 | 悮 | 悯 |
| 60b0 | 悰 | 悱 | 悲 | 悳 | 悴 | 怅 | 闷 | 悷 | 悸 | 悹 | 悺 | 悻 | 悼 | 凄 | 悾 | 悿 |
| 60c0 | 惀 | 惁 | 惂 | 惃 | 惄 | 情 | 惆 | 惇 | 惈 | 惉 | 惊 | 惋 | 惌 | 惍 | 惎 | 惏 |
| 60d0 | 惐 | 惑 | 惒 | 惓 | 惔 | 惕 | 惖 | 惗 | 惘 | 惙 | 惚 | 惛 | 惜 | 惝 | 惞 | 惟 |
| 60e0 | 惠 | 恶 | 惢 | 惣 | 惤 | 惥 | 惦 | 惧 | 惨 | 惩 | 惪 | 惫 | 惬 | 惭 | 惮 | 惯 |
| 60f0 | 惰 | 恼 | 恽 | 想 | 惴 | 惵 | 惶 | 惷 | 惸 | 惹 | 惺 | 恻 | 惼 | 惽 | 惾 | 惿 |
| 6100 | 愀 | 愁 | 愂 | 愃 | 愄 | 愅 | 愆 | 愇 | 愈 | 愉 | 愊 | 愋 | 愌 | 愍 | 愎 | 意 |
| 6110 | 愐 | 愑 | 愒 | 愓 | 愔 | 愕 | 愖 | 愗 | 愘 | 愙 | 愚 | 爱 | 惬 | 愝 | 愞 | 感 |
| 6120 | 愠 | 愡 | 愢 | 愣 | 愤 | 愥 | 愦 | 愧 | 悫 | 愩 | 愪 | 愫 | 愬 | 愭 | 愮 | 愯 |
| 6130 | 愰 | 愱 | 愲 | 愳 | 怆 | 愵 | 愶 | 恺 | 愸 | 愹 | 愺 | 愻 | 愼 | 愽 | 忾 | 愿 |
| 6140 | 慀 | 慁 | 慂 | 慃 | 栗 | 慅 | 慆 | 慇 | 慈 | 慉 | 慊 | 态 | 慌 | 愠 | 慎 | 慏 |
| 6150 | 慐 | 慑 | 慒 | 慓 | 慔 | 慕 | 慖 | 慗 | 惨 | 慙 | 惭 | 慛 | 慜 | 慝 | 慞 | 恸 |
| 6160 | 慠 | 慡 | 慢 | 惯 | 悫 | 慥 | 慦 | 慧 | 慨 | 慩 | 怄 | 怂 | 慬 | 慭 | 虑 | 慯 |
| 6170 | 慰 | 慱 | 慲 | 悭 | 慴 | 慵 | 庆 | 慷 | 慸 | 慹 | 慺 | 慻 | 戚 | 慽 | 欲 | 慿 |
| 6180 | 憀 | 憁 | 忧 | 憃 | 憄 | 憅 | 憆 | 憇 | 憈 | 憉 | 惫 | 憋 | 憌 | 憍 | 憎 | 憏 |
| 6190 | 怜 | 凭 | 愦 | 憓 | 憔 | 憕 | 憖 | 憗 | 憘 | 憙 | 惮 | 憛 | 憜 | 憝 | 憞 | 憟 |
| 61a0 | 憠 | 憡 | 憢 | 憣 | 愤 | 憥 | 憦 | 憧 | 憨 | 憩 | 憪 | 悯 | 憬 | 憭 | 怃 | 憯 |
| 61b0 | 憰 | 憱 | 宪 | 憳 | 憴 | 憵 | 忆 | 憷 | 憸 | 憹 | 憺 | 憻 | 憼 | 憽 | 憾 | 憿 |
| 61c0 | 懀 | 懁 | 懂 | 懃 | 懄 | 懅 | 懆 | 恳 | 懈 | 应 | 懊 | 懋 | 怿 | 懔 | 懎 | 懏 |
| 61d0 | 懐 | 懑 | 懒 | 懓 | 懔 | 懕 | 懖 | 懗 | 懘 | 懙 | 懚 | 懛 | 懜 | 懝 | 懞 | 怼 |
| 61e0 | 懠 | 懡 | 懢 | 懑 | 懤 | 懥 | 懦 | 懧 | 恹 | 懩 | 懪 | 懫 | 懬 | 懭 | 懮 | 懯 |
| 61f0 | 懰 | 懱 | 惩 | 懳 | 懴 | 懵 | 懒 | 怀 | 悬 | 懹 | 忏 | 懻 | 惧 | 懽 | 慑 | 懿 |
| 6200 | 恋 | 戁 | 戂 | 戃 | 戄 | 戅 | 戆 | 戇 | 戈 | 戉 | 戊 | 戋 | 戌 | 戍 | 戎 | 戏 |
| 6210 | 成 | 我 | 戒 | 戓 | 戋 | 戕 | 或 | 戗 | 战 | 戙 | 戚 | 戛 | 戜 | 戝 | 戞 | 戟 |
| 6220 | 戠 | 戡 | 戢 | 戣 | 戤 | 戥 | 戦 | 戗 | 戨 | 戬 | 截 | 戫 | 戬 | 戭 | 戮 | 戯 |
| 6230 | 战 | 戱 | 戏 | 戳 | 戴 | 戵 | 户 | 户 | 戸 | 戹 | 戺 | 戻 | 戼 | 戽 | 戾 | 房 |
| 6240 | 所 | 扁 | 扂 | 扃 | 扄 | 扅 | 扆 | 扇 | 扈 | 扉 | 扊 | 手 | 扌 | 才 | 扎 | 扏 |
| 6250 | 扐 | 扑 | 扒 | 打 | 扔 | 払 | 扖 | 扗 | 托 | 扙 | 扚 | 扛 | 扜 | 扝 | 扞 | 扟 |
| 6260 | 扠 | 扡 | 扢 | 扣 | 扤 | 扥 | 扦 | 执 | 扨 | 扩 | 扪 | 扫 | 扬 | 扭 | 扮 | 扯 |
| 6270 | 扰 | 扱 | 扲 | 扳 | 扴 | 扵 | 扶 | 扷 | 扸 | 批 | 扺 | 扻 | 扼 | 扽 | 找 | 承 |
| 6280 | 技 | 抁 | 抂 | 抃 | 抄 | 抅 | 抆 | 抇 | 抈 | 抉 | 把 | 抋 | 抌 | 抍 | 抎 | 抏 |
| 6290 | 抐 | 抑 | 抒 | 抓 | 抔 | 投 | 抖 | 抗 | 折 | 抙 | 抚 | 抛 | 抜 | 抝 | 択 | 抟 |
| 62a0 | 抠 | 抡 | 抢 | 抣 | 护 | 报 | 抦 | 抧 | 抨 | 抩 | 抪 | 披 | 抬 | 抭 | 抮 | 抯 |
| 62b0 | 抰 | 抱 | 抲 | 抳 | 抴 | 抵 | 抶 | 抷 | 抸 | 抹 | 抺 | 抻 | 押 | 抽 | 抾 | 抿 |
| 62c0 | 拀 | 拁 | 拂 | 拃 | 拄 | 担 | 拆 | 拇 | 拈 | 拉 | 拊 | 抛 | 拌 | 拍 | 拎 | 拏 |
| 62d0 | 拐 | 拑 | 拒 | 拓 | 拔 | 拕 | 拖 | 拗 | 拘 | 拙 | 拚 | 招 | 拜 | 拝 | 拞 | 拟 |
| 62e0 | 拠 | 拡 | 拢 | 拣 | 拤 | 拥 | 拦 | 拧 | 拨 | 择 | 拪 | 拫 | 括 | 拭 | 拮 | 拯 |
| 62f0 | 拰 | 拱 | 拲 | 拳 | 拴 | 拵 | 拶 | 拷 | 拸 | 拹 | 拺 | 拻 | 拼 | 拽 | 拾 | 拿 |
| 6300 | 挀 | 持 | 挂 | 挃 | 挄 | 挅 | 挆 | 指 | 挈 | 按 | 挊 | 挋 | 挌 | 挍 | 挎 | 挏 |
| 6310 | 挐 | 挑 | 挒 | 挓 | 挔 | 挕 | 挖 | 挗 | 挘 | 挙 | 挚 | 挛 | 挜 | 挝 | 挞 | 挟 |
| 6320 | 挠 | 挡 | 挢 | 挣 | 挤 | 挥 | 挦 | 挧 | 挨 | 挩 | 挪 | 挫 | 挬 | 挭 | 挮 | 振 |
| 6330 | 挰 | 挱 | 挲 | 挳 | 挴 | 挵 | 挶 | 挷 | 挸 | 挹 | 挺 | 挻 | 挼 | 挽 | 挟 | 挿 |
| 6340 | 捀 | 捁 | 捂 | 捃 | 捄 | 捅 | 捆 | 捇 | 捈 | 捉 | 捊 | 捋 | 捌 | 捍 | 捎 | 捏 |
| 6350 | 捐 | 捑 | 捒 | 捓 | 捔 | 捕 | 捖 | 捗 | 捘 | 捙 | 捚 | 捛 | 捜 | 捝 | 捞 | 损 |
| 6360 | 捠 | 捡 | 换 | 捣 | 捤 | 捥 | 捦 | 捧 | 舍 | 捩 | 捪 | 扪 | 捬 | 捭 | 据 | 捯 |
| 6370 | 捰 | 捱 | 卷 | 捳 | 捴 | 捵 | 捶 | 捷 | 捸 | 捹 | 捺 | 捻 | 捼 | 捽 | 捾 | 捿 |
| 6380 | 掀 | 掁 | 掂 | 扫 | 抡 | 掅 | 掆 | 掇 | 授 | 掉 | 掊 | 掋 | 掌 | 掍 | 掎 | 掏 |
| 6390 | 掐 | 掑 | 排 | 掓 | 掔 | 掕 | 掖 | 掗 | 掘 | 挣 | 掚 | 挂 | 掜 | 掝 | 掞 | 掟 |
| 63a0 | 掠 | 采 | 探 | 掣 | 掤 | 接 | 掦 | 控 | 推 | 掩 | 措 | 掫 | 掬 | 掭 | 掮 | 掯 |
| 63b0 | 掰 | 掱 | 掲 | 掳 | 掴 | 掵 | 掶 | 掷 | 掸 | 掹 | 掺 | 掻 | 掼 | 掽 | 掾 | 掿 |
| 63c0 | 拣 | 揁 | 揂 | 揃 | 揄 | 揅 | 揆 | 揇 | 揈 | 揉 | 揊 | 揋 | 揌 | 揍 | 揎 | 描 |
| 63d0 | 提 | 揑 | 插 | 揓 | 揔 | 揕 | 揖 | 揗 | 揘 | 揙 | 扬 | 换 | 揜 | 揝 | 揞 | 揟 |
| 63e0 | 揠 | 握 | 揢 | 揣 | 揤 | 揥 | 揦 | 揧 | 揨 | 揩 | 揪 | 揫 | 揬 | 揭 | 挥 | 揯 |
| 63f0 | 揰 | 揱 | 揲 | 揳 | 援 | 揵 | 揶 | 揷 | 揸 | 背 | 揺 | 揻 | 揼 | 揽 | 揾 | 揿 |
| 6400 | 搀 | 搁 | 搂 | 搃 | 搄 | 搅 | 搆 | 搇 | 搈 | 搉 | 搊 | 搋 | 搌 | 损 | 搎 | 搏 |
| 6410 | 搐 | 搑 | 搒 | 搓 | 搔 | 搕 | 摇 | 捣 | 搘 | 搙 | 搚 | 搛 | 搜 | 搝 | 搞 | 搟 |
| 6420 | 搠 | 搡 | 搢 | 搣 | 搤 | 搥 | 搦 | 搧 | 搨 | 搩 | 搪 | 搫 | 搬 | 搭 | 搮 | 掏 |
| 6430 | 搰 | 搱 | 搲 | 搳 | 搴 | 搵 | 抢 | 搷 | 搸 | 搹 | 携 | 搻 | 搼 | 搽 | 搾 | 搿 |
| 6440 | 捂 | 摁 | 摂 | 摃 | 摄 | 摅 | 摆 | 摇 | 摈 | 摉 | 摊 | 摋 | 摌 | 摍 | 摎 | 摏 |
| 6450 | 摐 | 掴 | 摒 | 摓 | 摔 | 摕 | 摖 | 摗 | 摘 | 摙 | 摚 | 摛 | 掼 | 摝 | 摞 | 搂 |
| 6460 | 摠 | 摡 | 摢 | 摣 | 摤 | 摥 | 摦 | 摧 | 摨 | 摩 | 摪 | 摫 | 摬 | 摭 | 摮 | 挚 |
| 6470 | 摰 | 摱 | 摲 | 抠 | 摴 | 摵 | 抟 | 摷 | 摸 | 摹 | 摺 | 掺 | 摼 | 摽 | 摾 | 摿 |
| 6480 | 撀 | 撁 | 撂 | 撃 | 撄 | 撅 | 撆 | 撇 | 捞 | 撉 | 撊 | 撋 | 撌 | 撍 | 撎 | 撏 |
| 6490 | 撑 | 撑 | 撒 | 挠 | 撔 | 撕 | 撖 | 撗 | 撘 | 撙 | 捻 | 撛 | 撜 | 撝 | 撞 | 挢 |
| 64a0 | 撠 | 撡 | 撢 | 掸 | 撤 | 拨 | 撦 | 撧 | 撨 | 撩 | 撪 | 抚 | 撬 | 播 | 撮 | 撯 |
| 64b0 | 撰 | 撱 | 扑 | 揿 | 撴 | 撵 | 撶 | 撷 | 撸 | 撹 | 撺 | 挞 | 撼 | 撽 | 挝 | 捡 |
| 64c0 | 擀 | 拥 | 擂 | 擃 | 掳 | 擅 | 擆 | 择 | 擈 | 擉 | 击 | 挡 | 擌 | 操 | 擎 | 擏 |
| 64d0 | 擐 | 擑 | 擒 | 擓 | 担 | 擕 | 擖 | 擗 | 擘 | 擙 | 据 | 擛 | 擜 | 擝 | 擞 | 擟 |
| 64e0 | 挤 | 擡 | 擢 | 擣 | 擤 | 擥 | 擦 | 擧 | 擨 | 擩 | 擪 | 擫 | 拟 | 擭 | 擮 | 摈 |
| 64f0 | 拧 | 搁 | 掷 | 擳 | 扩 | 擵 | 擶 | 撷 | 擸 | 擹 | 摆 | 擞 | 撸 | 擽 | 扰 | 擿 |