打破常规,逆残差模块超强改进,新一代移动端模型MobileNeXt来了!精度速度双超MobileNetV2
原文链接:打破常规,逆残差模块超强改进,新一代移动端模型MobileNeXt来了!精度速度双超MobileNetV2

导语:该文是依图科技&新加坡国立大学颜水成大佬团队提出的一种对标MobileNetV2的网络架构MobileNeXt。它针对MobileNetV2的核心模块逆残差模块存在的问题进行了深度分析,提出了一种新颖的SandGlass模块,并用于组建了该文的MobileNeXt架构,SandGlass是一种通用的模块,它可以轻易的嵌入到现有网络架构中并提升模型性能。该文应该是近年来为数不多的优秀终端模型了,推荐指数五颗星。
paper: https://arxiv.org/abs/2007.02269
code: https://github.com/zhoudaquan/rethinking_bottleneck_design(未开源)
Abstract
截止目前,逆残差模块已成为手机端网络架构设计的主流架构。它通过引入两个主要的设计规则(1.逆残差学习;2.线性瓶颈层)对经典的残差瓶颈模块进行了改变。
该文作者对这种设计模式改变的必要性进行了重思考,发现:这种设计模块可能导致信息损失与梯度混淆。鉴于此,作者提出对该结构进行镜像并提出一种新颖的瓶颈模块,称之为SandGlass Block,它在更高维度进行恒等映射与空间变换,因此可以有效的缓解信息损失与梯度混淆。
作者通过实验证实:所提模块比已有的逆残差模块更有效。在ImageNet分类任务中,通过简单的模块替换(即采用SandGlass 替换MobileNetV2中的InvertedResidualBlock),即可取得了1.7%的性能提升,且不会导致额外的参数量与计算量提升;在VOC2007测试集上,可以按到目标检测指标的0.9%mAP的提升。
与此同时,作者将所提模块嵌入到NAS方法(DARTS)搜索空间中,可以取得了0.13%的性能提升且参数量降低25%。
Method
下图给出了目前CNN网络架构常用的两种主流模块与本文所提的模块:
- Bottleneck,见下图a,它包含两个1x1卷积(分别进行降维与升维)与一个3x3卷积(用于空间信息变换),它是一种heavy-weight模块;
- Inverted Residual Block,见下图b,它包含两个1x1卷积(分别进行升维与降维)与一个3x3深度卷积(用于空间信息变换),它是一种light-weight模块。
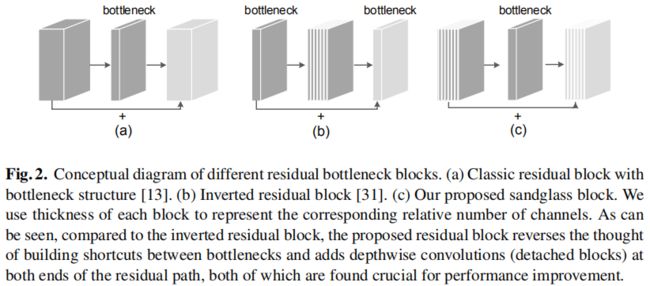
- SandGlass,见上图c,整体形势上它与Bottlneck比较类似,但它引入了深度卷积降低计算量,更多描述见下文。
SandGlass
已有研究表明:(1) 更宽的网络有利于缓解梯度混淆问题并有助于提升模型性能;(2)逆残差模块中的短连接可能会影响梯度回传。
考虑到上述逆残差模块的局限性,作者对其设计规则进行重思考并提出了SandGlass模块缓解上述问题。该模块的设计主要源自如下几点分析:
- 保持更多的信息从bottom传递给top层,进而有助于梯度回传;
- 深度卷积是一种轻量型单元,可以执行两次深度卷积以编码更多的空间信息。
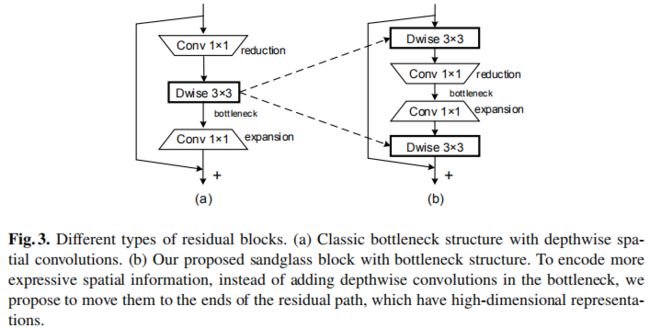
基于上述分析,作者从以下几个方面进行了模块的精心设计(最终设计的模块见上图)。
- Position of Expansion and Reduction. 在原始的逆残差模块中先进行升维再进行降维。基于前述分析,为确保高维度特征的短连接,作者对两个1x1卷积的顺序进行了调整。假设 F ∈ R D f × D f × M F \in R^{D_f \times D_f \times M} F∈RDf×Df×M表示输入张量, G ∈ R D f × D f × M G \in R^{D_f \times D_f \times M} G∈RDf×Df×M表示输出张量(注:此时尚未考虑深度卷积),那么该模块的可以写成如下形式,见上图b中的中间两个1x1卷积。
G = ϕ e ( ϕ r ( F ) ) + F G = \phi_e (\phi_r(F)) + F G=ϕe(ϕr(F))+F
- High-dimensional Shortcut. 作者并未在瓶颈层间构建短连接,而是在更高维特征之间构建短连接,见上图b。更宽的短连接有助于更多的信息从输入F传递给输出G,从而有更多的梯度回传。
- Learning expressive spatial features. 1x1卷积有助于编码通道间的信息,但难以获取空间信息,因此,在这里作者沿着逆残差模块的思路引入深度卷积编码空间信息。不同于逆残差模块在两个1x1卷积之间引入深度卷积,作者认为1x1卷积导致了减少的空域信息编码,因此将深度卷积置于两个1x1卷积之外,见上图b中的两个3x3深度卷积。该模块可以采用如下公式进行描述:
G ^ = ϕ 1 , p ϕ 1 , d ( F ) G = ϕ 1 , d ϕ 2 , p ( G ^ ) + F \hat{G} = \phi_{1,p}\phi_{1,d}(F) \\ G = \phi_{1,d} \phi_{2,p}(\hat{G}) + F G^=ϕ1,pϕ1,d(F)G=ϕ1,dϕ2,p(G^)+F
其中 ϕ i , p , ϕ i , d \phi_{i,p}, \phi_{i,d} ϕi,p,ϕi,d分别表示1x1卷积与深度卷积。从而确保了深度卷积在高维空间处理并得到更丰富的特征表达。
- Activation Layer. 已有研究表明:线性瓶颈层有助于避免特征出现零化现象,进而导致信息损失。基于此,作者在用于降维的1x1卷积后不添加激活函数。同时最后一个深度卷积后也不添加激活函数,激活函数今天加第一个深度卷积与最后一个1x1卷积之后。
- Block Structure. 基于上述考虑,我们得到了该文所设计的新颖的残差瓶颈模块,结构如下表与上图b所示。注:当输入与输出通道数不相同时不进行短连接操作。

MobileNeXt Architecture
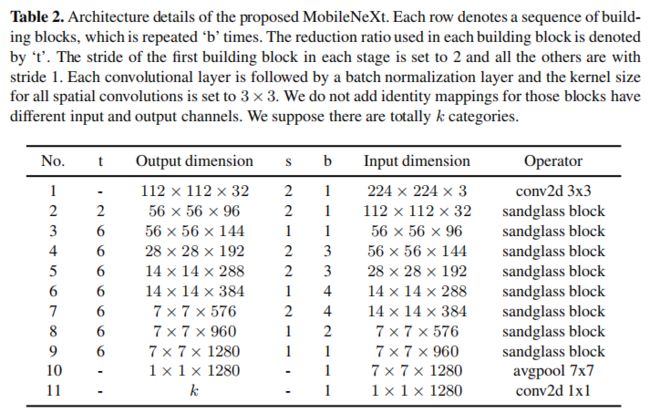
前面已经对该文所提到的SandGlass模块进行了详细介绍说明,那么接下来就是如何利用上述模块构建网路架构了。作者将上述模块构建的网络架构称之为MobileNeXt(是为了对标MobileNet吗?哈哈)。MobileNeXt的详细配置信息见下表。注:SandGlass中的扩展比例与MobileNetV2中的相同,均为6.
Identity tensor multiplier
已有研究表明:残差模块中的短连接有助于梯度跨层传播。但是,作者通过实验发现:没有必要保持全局恒等tensor与残差分支组合。为使得该网络更适合于手机端,作者引入了一个新的超参数:identity tensor multiplier,表示为 α ∈ [ 0 , 1 ] \alpha \in [0,1] α∈[0,1]。为简单起见,我们假设 ϕ \phi ϕ表示残差分支的变换函数,那么添加该超参数后的模块可以重写为:
G 1 : α M = ϕ ( F ) 1 : α M + F 1 : α M G α M : m = ϕ ( F ) α M : M G_{1:\alpha M} = \phi(F)_{1: \alpha M} + F_{1:\alpha M} \\ G_{\alpha M : m} = \phi(F)_{\alpha M : M} G1:αM=ϕ(F)1:αM+F1:αMGαM:m=ϕ(F)αM:M
这里引入的超参数 α \alpha α有两个作用:
- 通过降低该超参数,每个模块中的add数量可以进一步降低,因为add操作会占用不少耗时。用户可以选择更少的 α \alpha α以得到更好的推理速度且性能几乎无影响;
- 可以降低内存访问时间。影响模型推理的一个重要因素是:内存访问消耗(Memory acces cost, MAC)。降低该超参数有助于减少cache占用,进而加速推理。更多分析见实验部分。
Experiments
为说明所提方案的有效性,作者在ImageNet与VOC数据集上进行了实验分析。在模型训练过程中,优化器为SGD(momentum=0.9,weight_decay= 4 × 1 0 − 5 4\times 10^{-5} 4×10−5),初始学习率为0.05,cosine方式衰减,BatchSize=256,4个GPU。如无特殊说明,模型总计训练200epoch。
Comparsions with MobileNetV2
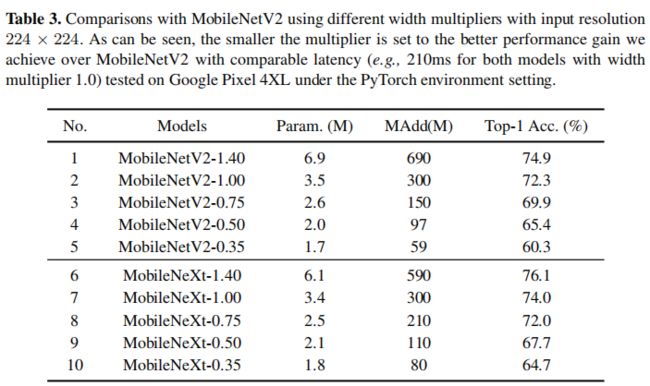
下表给出了所提方法与MobileNetV2在不同参数量下的性能对比。可以看到:(1) 所提方法在参数量和精度方面均优于MobileNetV2;(2) 模型越小,所提方法优势越明显。
下表给出了所提方法在添加后训练量化后的性能对比。可以看到:后训练量化对于MobileNet的精度影响非常大,而所提方法经量化后性能差异进一步拉大。产生这种现象的原因有两点:(1) 相比MobileNetV2,所提方法将短连接有瓶颈区域移到了高维区域,经由量化,跟过的信息得以保留;(2) 采用更多的深度卷积有助于保留更多的空域信息,而空域信息有助于分类性能提升。
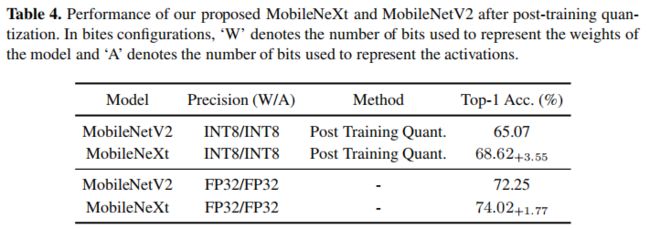
为更好的说明所提模块有效性,作者将MobileNetV2的卷积数提升到与SandGlass相同。实验结果见下表。尽管添加了额外的深度卷积有确实提升了模型性能,但仍比所提方法的性能低1%,而且MobileNetV2添加额外的深度卷积还导致了参数量与计算量的增加。

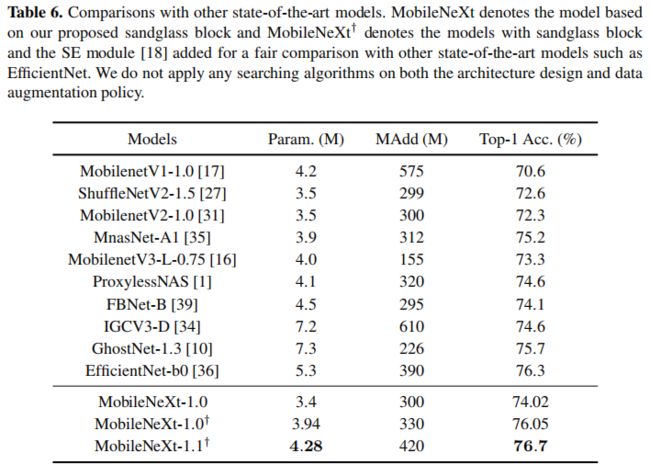
此外,作者还给出了所提方法与其他SOTA方法的性能对比,见下表。注:为更好的说明所提方法的优越性,作者还额外引入了SE模块。
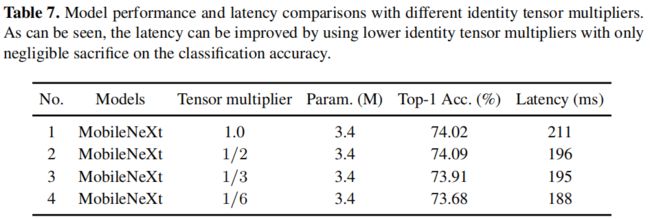
下表给出了超参数 α \alpha α不同配置时的模型性能对比,注:硬件平台为Google Pixel 4XL手机,Pytorch导出模型。可以看到随着该超分数的酱烧,推理速度有提升,且性能无显著下降。此外,作者还提到,在Pixel 4XL平台,TF-Lite推理框架下,MobileNeXt的推理速度为66ms,MobileNetV2的推理速度为68ms(可能这里的模型进行了量化,作者原文并未细说)。
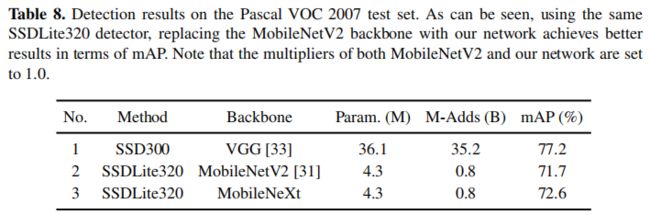
Object Detection
为探索所提方案的迁移性能,作者在目标检测任务上进行了更多的实验分析,结果见下表。相比MobileNetV2,所提方法作为Backbone时的性能可以提升0.09mAP。
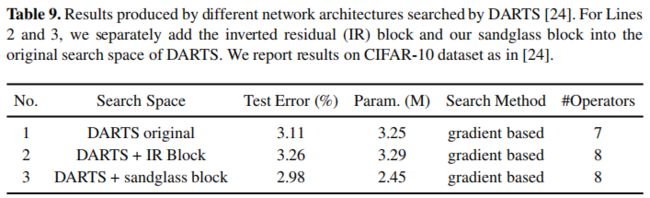
Combine with NAS
为更好说明所提方案的有效性,作者还将其与NAS相结合,将该模块为作为NAS网络的搜索空间。相关结果见下表。关于NAS所得网路架构建议查看原文的supp部分内容。
好了,全文核心内容到此结束。对此感兴趣的小伙伴建议去看原文,虽然这里已经将文章核心介绍清楚了,但实验部分的分析还是建议查看原文。
Conclusion
该文对逆残差模块中的设计规则与缺陷进行了深度分析,并基于分析结果提出一种新颖的称之为SandGlass的模块。它打破了传统残差模块的设计思想并着重说明了高维度特征进行短连接的重要。最后作者通过实验在分类、检测以及NAS方面论证了所提方案的有效性。
关注极市平台公众号(ID:extrememart),获取计算机视觉前沿资讯/技术干货/招聘面经等
