Oracle11g安装教程
官方下地址:
http://www.oracle.com/technetwork/database/enterprise-edition/downloads/index.html以下两网址来源此官方下载页网。
win 32位操作系统 下载地址:
http://download.oracle.com/otn/nt/oracle11g/112010/win32_11gR2_database_1of2.zip
http://download.oracle.com/otn/nt/oracle11g/112010/win32_11gR2_database_2of2.zip
win 64位操作系统 下载地址:
http://download.oracle.com/otn/nt/oracle11g/112010/win64_11gR2_database_1of2.zip
http://download.oracle.com/otn/nt/oracle11g/112010/win64_11gR2_database_2of2.zip
二、Oracle安装
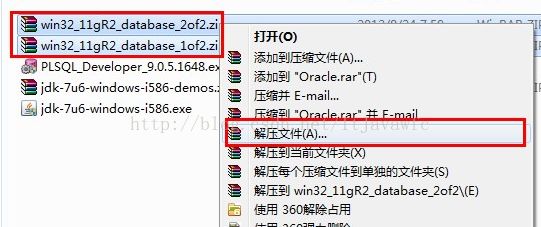
1. 解压缩文件,将两个压缩包一起选择, 鼠标右击 -> 解压文件 如图
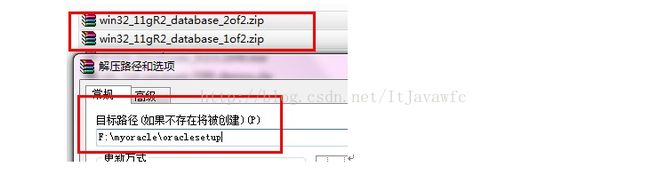
2.两者解压到相同的路径中,如图:
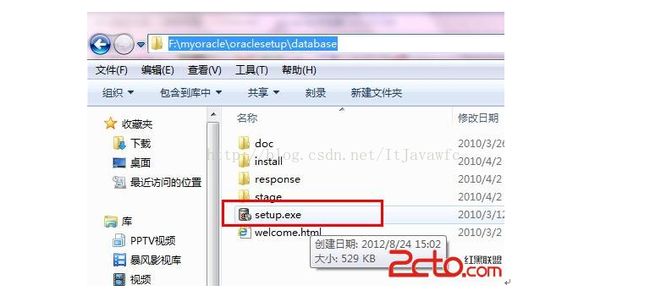
3. 到相应的解压路径上面,找到可执行安装文件【 setup.exe 】双击安装。如图:
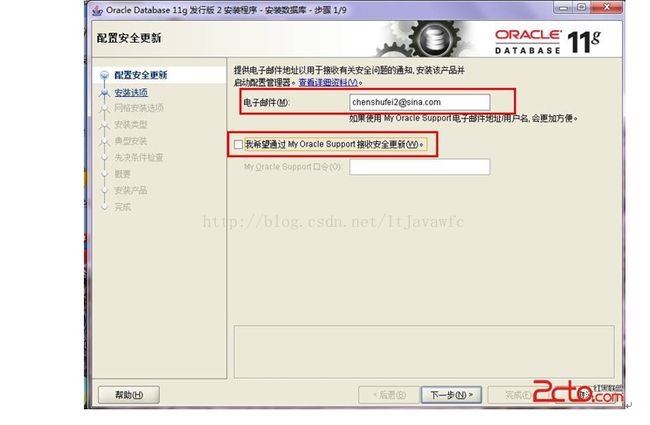
4. 安装第一步:配置安全更新,这步可将自己的电子邮件地址填写进去(也可以不填写,只是收到一些没什么用的邮件而已)。取消下面的“我希望通过My Oracle Support接受安全更新(W)”。 如图:
5. 安全选项,直接选择默认创建和配置一个数据库(安装完数据库管理软件后,系统会自动创建一个数据库实例)。 如图:
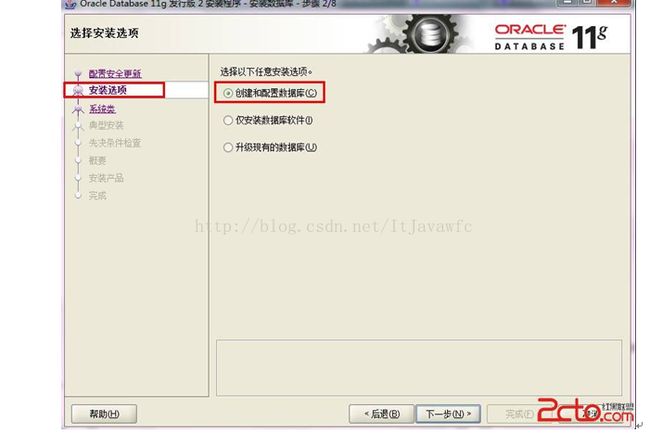
6. 系统类,直接选择默认的桌面类就可以了。(若安装到的电脑是,个人笔记本或个人使用的电脑使用此选项) 如图:
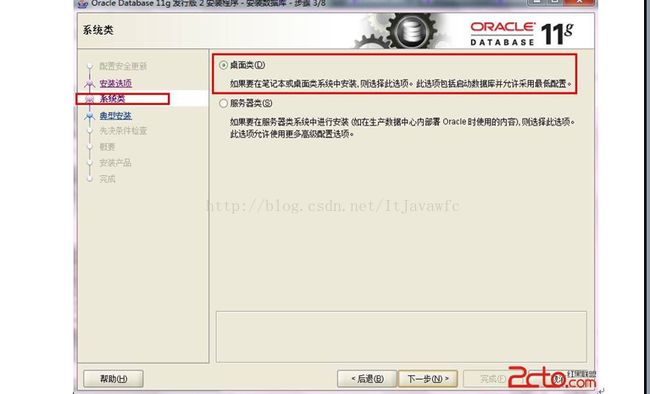
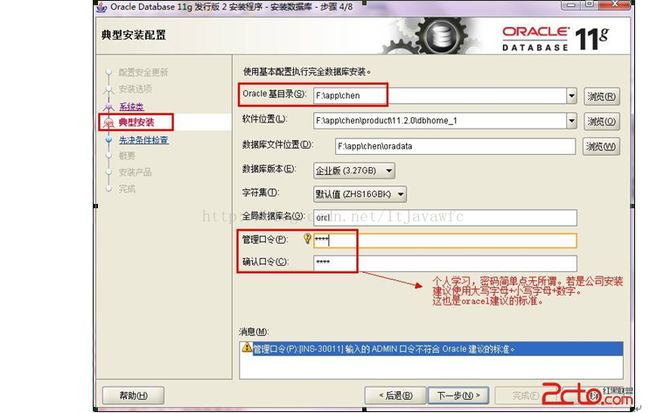
7. 典型安装。重要步骤。建议只需要将Oracle基目录更新下,目录路径不要含有中文或其它的特殊字符。全局数据库名可以默认,且口令密码,必须要牢记。密码输入时,有提示警告,不符合Oracel建议时不用管。 (因Oracel建议的密码规则比较麻烦, 必须是大写字母加小写字母加数字,而且必须是8位以上。麻烦,可以输入平常自己习惯的短小密码即可) 如图:
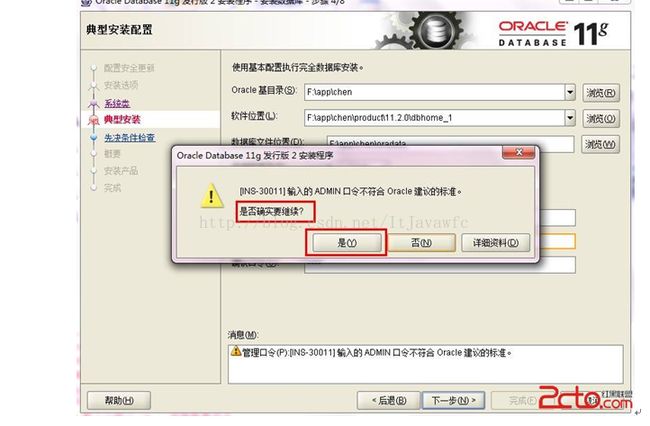
8. 若输入的口令短小简单,安装时会提示如下。直接确认Y继续安装就是了。如图:
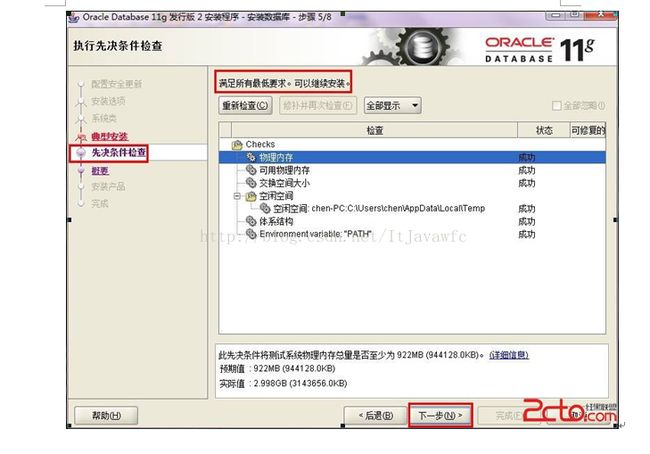
9. 先决条件检查。 安装程序会检查软硬件系统是否满足,安装此Oracle版本的最低要求。 直接下一步就OK 了。如图:
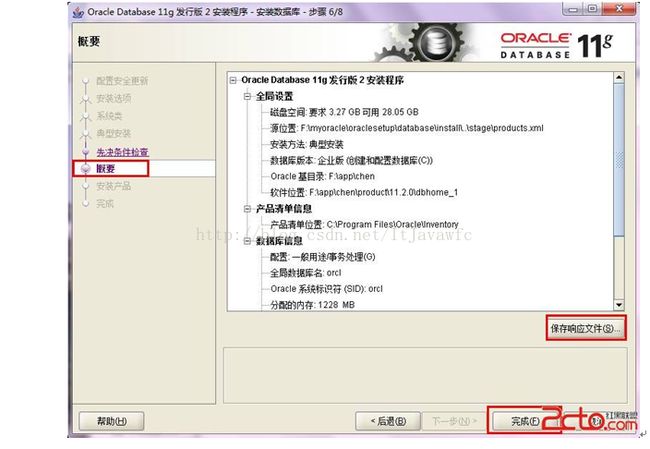
10. 概要 安装前的一些相关选择配置信息。可以保存成文件 或 不保存文件直接点完成即可。如图:
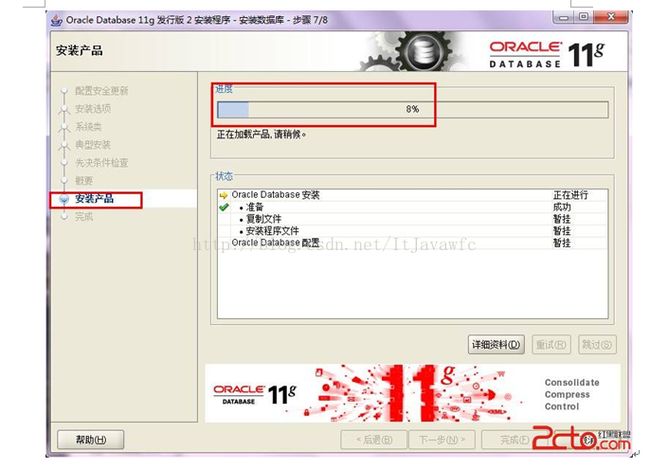
11. 安装产品自动进行,不用管。如图:
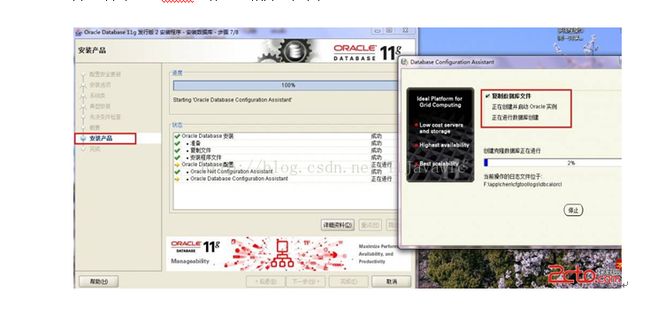
12. 数据库管理软件文件及dbms文件安装完后,会自动创建安装一个实例数据库默认前面的orcl名称的数据库。如图:
13. 实例数据库创建完成了,系统默认是把所有账户都锁定不可用了(除sys和system账户可用外),建议点右边的口令管理,将常用的scott账户解锁并输入密码。 如图:
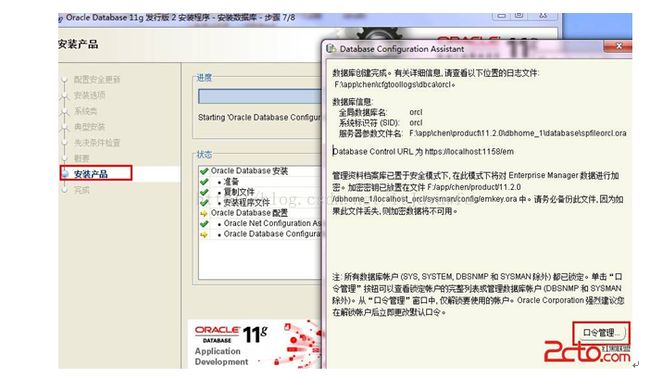
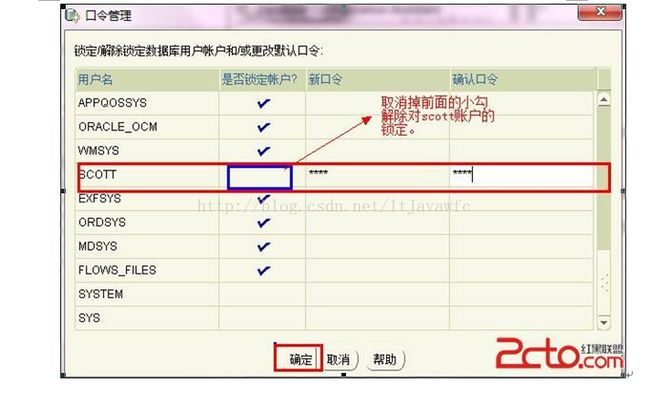
14. 解锁scott账户, 去掉前面的绿色小勾,输入密码。同样可以输入平常用的短小的密码,不必非得按oracle建议的8位以上大小写加数字,麻烦。呵呵。如图:
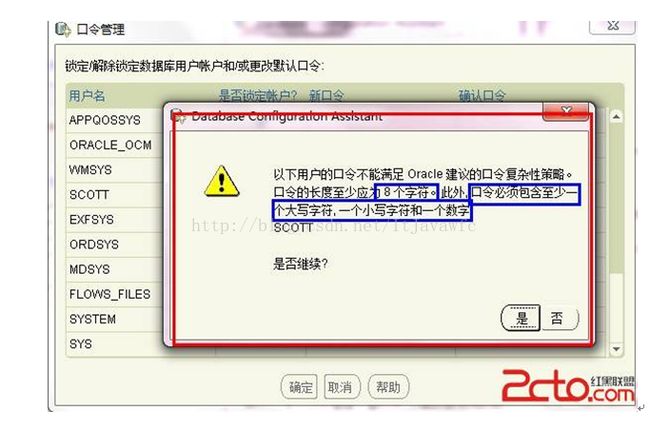
15. 同样,密码不符合规则会提示。不用管它,继续Y即可。如图:
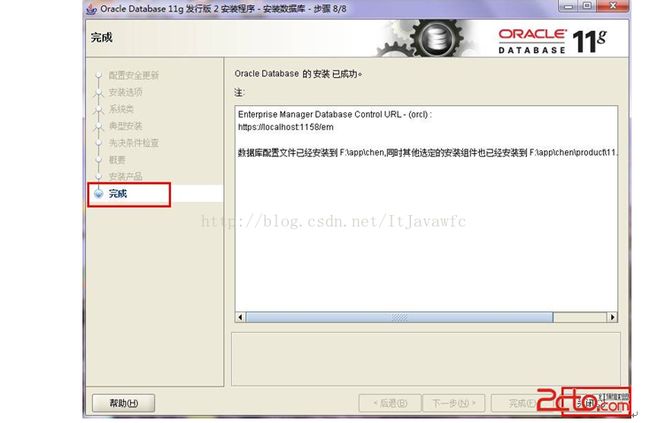
16. 安装成功,完成即可。 简单吧,呵呵。如图:
三、安装后,进入小测试下
可以通过开始,应用程序中的 "Oracle 11g" -> "应用程序开发" -> "Sql Developer 或SqlPlus" 连接。
注意第一次,使用SQL Developer时,会提示指定 java.exe的路径,这里千万别指定自己的java_home了(我就是开始不知道,指定一个JDK6,结束说不兼容。)可以使用Oracel安装路径下面的jdk路径 具体是:如图:。
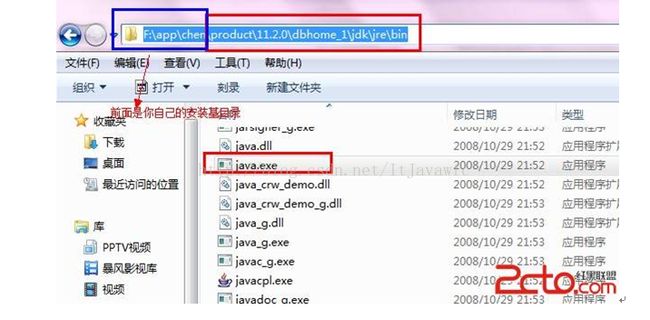
当然若不小心,选择错了。选择了java_home中的高级版本,打开SQL Developer报错后不兼容,也有办法解决。可以在
【F:\app\chen\product\11.2.0\dbhome_1\sqldeveloper\sqldeveloper\bin】路径下找到【sqldeveloper.conf】文件后打开
找到SetJavaHome 所匹配的值,删除后面的配置内容。保证时会提示,只读文件不可覆盖保存。此时可以另存为到桌面上,然后再回到bin目录中删除掉此文件,再把桌面上的文件复制过去,再打开时,重新选择java.exe。此时选择对就好了。
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
数据库学习笔记
一、 Oracle的安装(windowXP、win7、Linux)和卸载
1.1 Oracle的安装
1.1.1 在WindowsXP、Win7下安装
第一:解压win32_11gR2_database_1of2、
win32_11gR2_database_2of2,生成detabase目录
第二:安装oracle
A、点击setup图标即可,注意:安装目录不要含有中
文
B、在弹出的第一个界面中取消更新选择项,点击下
一步
C、在弹出的警告框中选择是
D、选择创建和配置数据库选项,下一步
E、选择桌面类安装,点击下一步
F、弹出的窗口中输入全局数据库名:orcl
输入管理口令:bluedot
默认的管理员是:sys和system
G、点完成,开始安装数据库,出现进度条
H、口令管理
I、设置口令
J、完成安装
1.2 Oracle的卸载:
1、 开始->设置->控制面板->管理工具->服务 停止
所有Oracle服务。
2、 开始->程序->Oracle - OraHome81->Oracle
Installation Products-> Universal Installer,单击“卸载
产品”-“全部展开”,选中除“OraDb11g_home1”外的全部目录
,删除。
3、 运行regedit,选择HKEY_LOCAL_MACHINE\SOFTWARE
\ORACLE,按del键删除这个入口。
4、 运行regedit,选择HKEY_LOCAL_MACHINE\SYSTEM
\CurrentControlSet\Services,滚动这个列表,删除所有Oracle
入口(以oracle或OraWeb开头的键)。
5、 运行refedit,HKEY_LOCAL_MACHINE\SYSTEM
\CurrentControlSet\Services\Eventlog\Application,删除所
有Oracle入口。e
6、 删除HKEY_CLASSES_ROOT目录下所有以Ora、Oracle、
Orcl或EnumOra为前缀的键。
7、 删除HKEY_CURRENT_USER\Software\Microsoft\Windows
\CurrentVersion\Explorer\MenuOrder\Start Menu\Programs中
所有以oracle开头的键。
8、删除HKEY_LOCAL_MACHINE\SOFTWARE\ODBC\ODBCINST.INI
中除MicrosoftODBC for Oracle注册表键以外的所有含有Oracle
的键。
9、我的电脑-->属性-->高级-->环境变量,删除环境变量
CLASSPATH和PATH中有关Oracle的设定。
10、从桌面上、STARTUP(启动)组、程序菜单中,删除所有
有关Oracle的组和图标。
11、删除所有与Oracle相关的目录(如果删不掉,重启计算机
后再删就可以了)包括:
1.C:\Program file\Oracle目录。
2.ORACLE_BASE目录(oracle的安装目录)。
3.C:\WINDOWS\system32\config\systemprofile
\Oracle目录。
4.C:\Users\Administrator\Oracle或C:\Documents
and Settings\Administrator\Oracle目录。
5.C:\WINDOWS下删除以下文件ORACLE.INI、
oradim73.INI、oradim80.INI、oraodbc.ini等等。
6.C:\WINDOWS下的WIN.INI文件中若有[ORACLE]的标记
段,删除该段。
12、如有必要,删除所有Oracle相关的ODBC的DSN
13、到事件查看器中,删除Oracle相关的日志 说明:如果
有个别DLL文件无法删除的情况,则不用理会,重新启动,开始新
的安装,安装时,选择一个新的目录,则,安装完毕并重新启动
后,老的目录及文件就可以删除掉了。
二、 用户管理
2.1 创建用户
注:创建用户只能在管理员下完成
CREATE USER 用户名 IDENTIFIED BY 密码。
|-CREATE USER demo IDENTIFIED BY 123456;
2.2 用户分类
|-管理员和普通用户
|-管理员
|-超级管理员:sys/bluedot
|-管理员:system/bluedot
|-普通用户:scott/tiger
hr/hr
|--常见角色:sysdba、sysoper
2.3 用户登录
2.3.1 在命令行窗口登录[c/s]
步骤:
运行 sqlplus /nolog
conn demo/123456
2.3.2 另外的一种登录方式【B/S】
输入网址----https://localhost:1158/em
输入用户名密码进入主界面
2.4 修改用户密码
注:修改密码必须要在级别高的用户下进行修改
ALTER USER 用户名 IDENTIFIED BY 密码;
conn sys/bluedot as sysdba
ALTER USER demo IDENTIFIED BY 654321;
2.5 查询用户
2.5.1查看用户信息
1、SELECT * FROM DBA_USERS;--------查看所有用户
的详细信息
2、SELECT * FROM ALL_USERS;-------查看所有用户简
要信息
3、SELECT * FROMUSER_USERS;------------查看当前
用户的所用信息
2.5.2 查看用户或角色系统权限(直接赋值给用户或角色
的系统权限)
SELECT * FROMDBA_SYS_PRIVS;----------全部
SELECT * FROM USER_SYS_PRIVS;---------当前用户
2.5.3 查看角色(登录用户拥有的角色)所包含的的权限
SELECT * FROM ROLE_SYS_PRIVS;
2.5.4 查看用户对象权限
SELECT * FROM DBA_TAB_PRIVS;
SELECT * FROM ALL_TAB_PRIVS;
SELECT * FROM USER_TAB_PRIVS;
2.5.5 查看所有角色
SELECT * FROM DBA_ROLES;
SELECT * FROM DBA_ROLE_PRIVS;
SELECT * FROM USER_ROLE_PRIVS;
2.5.6 查看哪些用户有sysdba或sysoper系统权限(查询时
需要相应权限)
SELECT * FROM V$PWFILE_USERS;
2.5.7 查看Oracle提供的系统权限
SELECT name FROMSYS.SYSTEM_PRIVSILEGE_MAP;
2.6 密码失效
提示用户第一次连接的时候需要修改密码,让用户的密码
到期
|- ALTER USER 用户名 PASSWORD expire ;
2.7 授权
GRANT 权限/角色 TO 用户
给 demo 用户以创建 session 的权限:GRANT create
session TO demo;
角色:-------------角色就是一堆权限的集合
Create role myrole;
Grant create table to myrole;
Drop role myrole; 删除角色
1.CONNECT, RESOURCE, DBA
这些预定义角色主要是为了向后兼容。其主要是用于数据
库管理。oracle建议用户自己设计数据库管理和安全的权限规划
,而不要简单的使用这些预定角色。将来的版本中这些角色可能
不会作为预定义角色。
2.DELETE_CATALOG_ROLE, EXECUTE_CATALOG_ROLE,
SELECT_CATALOG_ROLE 这些角色主要用于访问数据字典视图和包
。
3.EXP_FULL_DATABASE, IMP_FULL_DATABASE 这两个角
色用于数据导入导出工具的使用。
GRANT 权限(select、update、insert、delete) ON
schema.table TO 用户
|- GRANT select ONscott.emp TO test ;
|- Grant all onscott.emp to test; --将表相关的
所有权限付给 test
|- Grant update(ename)on emp to test; 可以控制
到列(还有 insert)
2.8 收权
REVOKE 权限/角色 ONschema.table FROM 用户
|- REVOKE select ON scott.emp FROM test ;
2.9 锁住一个用户
ALTER USER 用户名 ACCOUNT LOCK|UNLOCK
|- ALTER USER test ACCOUNTLOCK ;
|- ALTER USER test ACCOUNTUNLOCK ;
2.10 删除用户
|-DROP USER 用户名;
|-Drop user demo;
如果该用户下面已经存在表等一些数据库对象。则必
须用级联删除
|-DROP USER 用户名 CASCADE;
|-Drop user demo cascade;
备注:帮助
help index
help conn --------显示具体的
eidt---------------进入编辑文档
三、 Oracle的体系结构
3.1 Oracle数据库的整体架构 (DBA)
┌───────────────────
───────────┐
┌────┐ │ Instance │
│ User │ │ ┌────────────────────
──────┐ │
│ process│ │ │ ┌────────┐ SGA │ │
└────┘ │ │ │ Shared Pool │ │ │
↓ │ │ │ ┌─────┐ │ ┌────┐ ┌────
┐ │ │
↓ │ │ │ │Library │ │ │Database│ │ Redo │
│ │
┌────┐ │ │ │ │ Cache │ │ │Buffer │ │ Log
│ │ │
│ Server │ │ │ │ └─────┘ │ │Cache │ │
Buffer │ │ │
│process │ │ │ │ ┌─────┐ │ │ │ │ │ │ │
└────┘ │ │ │ │Data Dict │ │ └────┘ └─
───┘ │ │
↓ │ │ │ │ Cache │ │ │ │
→→→→→→│ │ │ └─────┘ │ │ │
│ │ └────────┘ │ │
│ └─────────────────
─────────┘ │
│ ┌──┐ ┌──┐ ┌──┐ ┌──┐
┌──┐ ┌───┐│
│ │PMON│ │SNON│ │DBWR│ │LGWR│ │CHPT│
│OTHERS││
│ └──┘ └──┘ └──┘ └──┘
└──┘ └───┘│
└───────────────────
───────────┘
↑ ↓
┌─────┐ ┌────────────
───────┐
│Parameter │ │┌───┐ ┌────┐
┌────┐│
│ file │ ││Data │ │control │ │Redo
Log││ ┌─────┐
└─────┘ ││files │ │ files │ │
files ││ │Archived │
┌─────┐ │└───┘ └────┘
└────┘│ │Log files │
│ Password │ │ Database │ └─────
┘
│ file │ │ │
└─────┘ └────────────
───────┘
由上图可知,Oracle数据库由实例和数据库组成。
3.2 数据库存储结构
3.2.1 数据库存储结构
Oracle数据库有物理结构和逻辑结构。数据库的物理结构
是数据库中的操作系统文件的集合。数据库的物理结构由数据文
件、控制文件和重做日志文件组成。
1、数据文件:数据文件是数据的存储仓库。
2、重做日志文件:重做日志文件包含对数据库所做的更改
记录,在发生故障时能够恢复数据。重做日志按时间顺序存储应
用于数据库的一连串的变更向量。其中仅包含重建(重做)所有
已完成工作的最少限度信息。如果数据文件受损,则可以将这些
变更向量应用于数据文件备份来重做工作,将它恢复到发生故障
的那一刻前的状态。重做日志文件包含联机重做日志文件(对于
连续的数据库操作时必须的)和归档日志文件(对于数据库操作
是可选的,但对于时间点恢复是必须的)。
3、控制文件:控制文件包含维护和验证数据库完整性的必
要的信息。控制文件虽小,但作用非常大。它包含指向数据库其
余部分的指针:联机重做日志文件和数据文件的位置,以及更新
的归档日志文件的位置。它还存储着维护数据库完整性所需的信
息。控制文件不过数MB,却起着至关重要的作用。
除了三个必须的文件外数据库还能有其它非必须的文件如
:参数文件、口令文件及归档日志文件。
1、实例参数文件:当启动oracle实例时,SGA结构会
根据此参数文件的设置内置到内存,后台进程会据此启动。
2、口令文件:用户通过提交用户名和口令来建立会话
。Oracle根据存储在数据字典的用户定义对用户名和口令进行验
证。
3、归档重做日志文件:当重做日志文件满时将重做日
志文件进行归档以便还原数据文件备份。
3.2.2 Oracle数据库结构的16个要点(表空间-->段-->
区-->块)
1、一个数据文件只能归到某一个表空间上,每个表空间可
以含一个或多个数据文件。包括系统数据和用户数据。
2、表空间是包括一个或多个数据文件的逻辑结构。用于存
放数据库表、索引、回滚段等对象的磁盘逻辑空间
3、数据库文件是存放实际数据的物理文件。包括实例和数
据库。
4、数据文件可以在创建表空间时创建,也可以以增加的方
式创建。
5、数据文件的大小一般与操作系统限制有关。
6、控制文件是Oracle的重要文件,主要存放数据文件、日
志文件和数据库的基本信息,一般在数据打开时访问。
7、日志文件在数据库活动时使用。
8、临时表空间是用于存放排序段的磁间;临时表空间由一
个或多个临时文件组成。
9、归档日志文件由归档进程将联机日志文件读出并写到一
个路径上的文件。
10、Oracle实例由一组后台进程和内存结构组成。
11、Oracle实例的内存结构常叫系统全局区,简称SGA。
12、DBA_开头的数据字典存放的字符信息都是大写,而V$_
开头的视图存放的都是小写。
13、后台进程是一组完成不同功能的程序,主要包括DBWR、
LGMR、CKPT等。
14、数据字典是Oracle的重要部分,也就是用于系统内部的
一组表。
15、数据字典分为动态和静态两部分,静态主要是DBA_开头
的数据字典,而动态则是以V$_开头的视图。
16、SGA分为数据缓冲区、共享池和日志缓冲区。
3.2.3 Oracle逻辑结构及表空间
1.ORACLE逻辑结构
ORACLE将数据逻辑地存放在表空间,物理地存放在
数据文件中。
一个表空间任何一个时刻只能属于一个数据库。
数据库——表空间——段——区——ORACLE块
每个数据库由一个或多个表空间组成,至少一个。
每个表空间基于一个或多个操作系统的数据文件,
至少一个,一个操作系统的数据文件只能属于一个表空间。一个
表空间可以存放一个或多个段segment。
每个段由一个或多个区段extent组成。
每个区段由一个或多个连续的ORACLE数据库块组成
。
每个ORACLE数据块由一个或多个连续的操作系统数
据块组成。
每个操作系统数据文件由一个或多个区段组成,由
一个或多个操作系统数据块组成。
⑴、表空间(tablespace)
表空间是数据库中最大的逻辑单位,每一个表空间
由一个或多个数据文件组成,一个数据文件只能与一个表空间相
联系。每一个数据库都有一个SYSTEM表空间,该表空间是在数据
库创建或数据库安装时自动创建的,用于存储系统的数据字典表
,程序系统单元,过程函数,包和触发器等,也可用于存储用户
数据表,索引对象。表空间具有在线(online)和离线(offline
)属性,可以将除SYSTME以外的其他任何表空间置为离线。
⑵、段(segment)
数据库的段可以分为四类:数据段、索引段、回退
段和临时段。
⑶、区
区是磁盘空间分配的最小单位。磁盘按区划分,每
次至少分配一个区。区存储与段中,它由连续的数据块组成。
⑷、数据块
数据块是数据库中最小的数据组织单位与管理单位
,是数据文件磁盘存储空间单位,也是数据库I/O的最小单位,数
据块大小由DB_BLOCK_SIZE参数决定,不同的Oracle版本
DB_BLOCK_SIZE的默认值是不同的。
⑸、模式对象
模式对象是一种应用,包括:表、聚簇、视图、索
引序列生成器、同义词、哈希、程序单元、数据库链等。
最后,在来说一下Oracle的用户、表空间和数据文
件的关系:
一个用户可以使用一个或多个表空间,一个表空间
也可以供多个用户使用。用户和表空间没有隶属关系,表空间是
一个用来管理数据存储的逻辑概念,表空间只是和数据文件发生
关系,数据文件是物理的,一个表空间可以包含多个数据文件,
而一个数据文件只能隶属一个表空间。
总结:解释数据库、表空间、数据文件、表、数据
的最好办法就是想象一个装满东西的柜子。数据库其实就是柜子
,柜中的抽屉是表空间,抽屉中的文件夹是数据文件,文件夹中
的纸是表,写在纸上的信息就是数据。
2.两类表空间:
系统SYSTEM表空间 非系统表空间 NON-SYSTEM表空间
系统SYSTEM表空间与数据库一起建立,在系统表空间
中有数据字典,系统还原段。可以存放用户数据但是不建议。
非系统表空间NON-SYSTEM表空间 由管理员创建。可
以方便管理。
3.3 实例的整体架构
实例整体架构图:
┌───────────────────
───────────┐
│ Instance │
│ ┌─────────────────
─────────┐ │
│ │ ┌────────┐ SGA │ │
│ │ │ Shared Pool │ │ │
│ │ │ ┌─────┐ │ ┌────┐
┌────┐ │ │
│ │ │ │Library │ │ │Database│ │
Redo │ │ │
│ │ │ │ Cache │ │ │Buffer │ │
Log │ │ │
│ │ │ └─────┘ │ │Cache │ │
Buffer │ │ │
│ │ │ ┌─────┐ │ │ │ │ │
│ │
│ │ │ │Data Dict │ │ └────┘
└────┘ │ │
│ │ │ │ Cache │ │ │ │
│ │ │ └─────┘ │ │ │
│ │ └────────┘ │ │
│ └─────────────────
─────────┘ │
│ ┌──┐ ┌──┐ ┌──┐ ┌──┐
┌──┐ ┌───┐│
│ │PMON│ │SNON│ │DBWR│ │LGWR│ │CHPT│
│OTHERS││
│ └──┘ └──┘ └──┘ └──┘
└──┘ └───┘│
└───────────────────
───────────┘
实例由内存和后台进程组成,它暂时存在于RAM和CPU中。
当关闭运行的实例时,实例将随即消失。数据库由磁盘上的物理
文件组成,不管在运行状态还是停止状态,这些文件就一直存在
。因此,实例的生命周期就是其在内存中存在的时间,可以启动
和停止。一旦创建数据库,数据库将永久存在。通俗的讲数据库
就相当于平时安装某个程序所生成的安装目录,而实例就是运行
某个程序时所需要的进程及消耗的内存。
Oracle的内存架构包含两部分系统全局区(SGA)和程序
全局区(PGA)。
3.3.1 程序全局区
3.3.2 系统全局区
在操作系统提供的共享内存段实现的内存结构称为系
统全局区(SGA)。SGA在实例启动时分配,在关闭时释放。在一
定范围内,可以在实例运行时通过自动方式或响应DBA的指令,重
新调整11g实例中的SGA及其中的组件的大小。
由上图可知SGA至少包含三种数据结构:数据库缓冲
区缓存、日志缓冲区及共享池。还可能包括:大池、JAVA池。可
以使用show sga,查看sga的状态。
1、共享池
a.库缓存是内存区域,按其已分析的格式存储
最近执行的代码。分析就是将编程人员编写的代码转换为可执行
的代码,这是oracle根据需要执行的一个过程。通过将代码缓存
在共享池,可以在不重新分析的情况下重用,极大地提高性能。
b.数据字典缓存有时称为“行缓存”,它存储
最近使用的对象定义:表、索引、用户和其他元数据定义的描述
。
c.PL/SQL区:存储的PL/SQL对象是过程、函数
、打包的过程、打包的函数、对象类型定义和触发器。
2、数据库缓冲区
数据库缓冲区是oracle用来执行SQL的工作区域
。
3、日志缓冲区
日志缓冲区是小型的、用于短期存储将写入到
磁盘上的重做日志的变更向量的临时区域。日志缓冲区在启动实
例时分配,如果不重新启动实例,就不能在随后调整其大小。
后台进程有:
1、PMON-----程序监控器
2、SMON-----系统监控区
3、DBWR-----数据写进程
4、LGWR-----日志写进程
5、CKPT-----检查点进程
6、Others---归档进程
四、SQL语法基础(DDL、DCL、TCL、DML)
SQL 全名是结构化查询语言(StructuredQuery Language),
是用于数据库中的标准数据查询语言,IBM 公司最早使用在其开
发的数据库系统中。1986 年 10 月,美国 ANSI 对 SQL 进行规
范后,以此作为关系式数据库管理系统的标准语言 (ANSI X3.
135-1986),1987 年得到国际标准组织的支持下成为国际标准。
不过各种通行的数据库系统在其实践过程中都对 SQL 规范作了某
些编改和扩充。所以,实际上不同数据库系统之间的 SQL 语言不
能完全相互通用
DML 语句(数据操作语言)Insert、Update、 Delete、
Select
DDL 语句(数据定义语言)Create、Alter、 Drop
DCL 语句(数据控制语言)Grant、Revoke
TCL 事务控制语句 Commit 、Rollback、Savepoint
4.1 入门语句
普通用户连接: Conn scott/tiger
超级管理员连接: Conn “sys/bluesot as sysdba”
Disconnect; 断开连接-------------disc
Save c:\1.txt 把 SQL 存到文件
Ed c:\1.txt 编辑 SQL 语句
@ c:\1.txt 运行 SQL 语句
Desc emp; 描述 Emp 结构
Select * from tab; 查看该用户下的所有对象
Show user; 显示当前用户
如果在 sys 用户下: 查询 Select * from emp; 会报错
,原因:emp 是属于 scott,所以此时必须使用:select * from
scott.emp; / 运行上一条语句
4.2 DDL(数据定义语言)----改变表结构
4.2.1 创建表
CREATE TABLE name (
tid VARCHAR2(5),
tname VARCHAR2(20),
tdate DATE,
as VARCHAR(7,2)
);
4.2.2 添加一列
ALTER TABLE 表名 ADD 列名 属性;
ALTER TABLE student ADD agenumber(5);
4.2.4 删除一列
ALTER TABLE table_name DROPCOLUMN column_name;
ALTER TABLE student DROPCOLUMN age;
4.2.5 修改一列的属性
ALTER TABLE table_name MODIFYcolumn_name type;
修改列名
ALTER TABLE table_name RENAMECOLUMN columnname
TO newname;
修改表名
ALTER TABLE table_name RENAMETO newname;
4.2.6 查看表中数据
DESC table_name;
4.2.7 删除表
DROP TABLE table_name;
4.3 DCL(数据控制语言)
4.3.1 授权
GRANT 权限/角色 TO 用户
给 demo 用户以创建 session 的权限:GRANT create
session TO demo;
角色:-------------角色就是一堆权限的集合Create
role myrole;
Grant create table to myrole;
Drop role myrole; 删除角色
1.CONNECT, RESOURCE, DBA
这些预定义角色主要是为了向后兼容。其主要是用于数
据库管理。oracle建议用户自己设计数据库管理和安全的权限规
划,而不要简单的使用这些预定角色。将来的版本中这些角色可
能不会作为预定义角色。
2.DELETE_CATALOG_ROLE, EXECUTE_CATALOG_ROLE,
SELECT_CATALOG_ROLE 这些角色主要用于访问数据字典视图和包
。
3.EXP_FULL_DATABASE, IMP_FULL_DATABASE 这两个
角色用于数据导入导出工具的使用。
GRANT 权限(select、update、insert、delete) ON
schema.table TO 用户
|- GRANT select ONscott.emp TO test ;
|- Grant all onscott.emp to test; --将表相关
的所有权限付给 test
|- Grantupdate(ename) on emp to test; 可以控
制到列(还有 insert)
4.3.2 收权
REVOKE 权限/角色 ON schema.table FROM 用户
|- REVOKEselect ON scott.emp FROM test ;
4.4 TCL(事务控制语言)
事务的概念:事务是一系列对数据库操作命令的集合,它
有边界(commit---commit)
事务的特征:A ------原子性-----不可分割性-------要
么执行要么不执行
C------一致性-----rollback
I-------隔离性-----锁的机制来保证的,
锁有粒度【表、行】---------只读、修改锁
上锁---SELECT *FROM DEMO1
FOR UPDATE;
释放------commit、rollback
D -----持久性-------commit
系统时间-----sysdate
to_date
(‘2013/11/09’,‘yyyy/mm/dd’)--------修改日期格式
转换函数
1、To_char
select to_char(sysdate,'yyyy') from
dual;
select to_char(sysdate,'fmyyyy-mm-
dd') from dual;
select to_char(sal,'L999,999,999')
from emp;
select to_char(sysdate,’D’) from
dual;//返回星期
2、To_number
select to_number('13')+to_number
('14') from dual;
3、To_date
Select to_date
(‘20090210’,‘yyyyMMdd’) from dual;
4.4.1 ROLLBACK
回滚------回滚到它上面的离它最近的commit
4.4.2 COMMIT
提交-----------将数据缓冲区的数据提交到文件中去
4.4.3 SAVEPOINT------保存点
回滚点例子:
INSERT INTO DEMO1(TID,TNAME) VALUES(11,'AS');
SAVEPOINT P1;
INSERT INTO DEMO1(TID,TNAME) VALUES(22,'AS');
INSERT INTO DEMO1(TID,TNAME) VALUES(33,'AS');
SAVEPOINT P2;
INSERT INTO DEMO1(TID,TNAME) VALUES(44,'AS');
ROLLBACK TO P2;
COMMIT;
INSERT INTO DEMO1(TID,TNAME) VALUES(55,'AS');
ROLLBACK TO P1;----------无法回滚
------------查询结果:11,22,33 由于55没有提交所以没有
写入文件
4.5 DML(数据操作语言)---------改变数据结构
4.5.1 insert 语句
INSERT INTO table_name() VALUES();
INSERT INTO table_name VALUES();
插入空值时,用三种格式
1、INSERT INTOdemo VALUES('');
2、INSERT INTOdemo VALUES(' ');
3、INSERT INTOdemo VALUES(NULL);
INSERT INTO demo(tid,tname,tdate) VALUES
(1,null,sysdate);
INSERT INTO demo(tid,tname,tdate) VALUES(1,'',to_date
(sysdate,'yyyy-mm-dd'));
INSERT INTO demo VALUES(1,'',to_date
('2013/11/11','yyyy/mm/dd'));
注意:
1、字符串类型的字段值必须用单引号括起来,如:‘rain’;
2、如果字段值里包含单引号需要进行字符串转换,把它替换成
两个单引号‘’,如:‘''c''' 数据库中将插入‘c’;
3、字符串类型的字段值超过定义长度会报错,最好在插入前进
行长度校验;
4、日期字段的字段值可以使用当前数据库的系统时间sysdate
,精确到秒;
5、INSERT时如果要用到从1开始自动增长的序列号,应该先建
立一个序列号。
4.5.2 update 语句
UPDATE table_name SET column_name=值 WHERE 查询条件
UPDATE demo SET tname='张三' WHERE tid=1;
COMMIT;------是更新生效
4.5.3 delete 语句-----不能回退
DELETE TABLE table_name;--------------只能删除数据,不
能释放空间
TRUNCATE TABLE table_name;---------------删除数据并释
放空间
DELETE TABLE demo;
TRUNCATE TABLE demo;
4.5.4 select 语句
A 、简单的 Select 语句
SELECT * FROM table_name;
SELECT * FROM demo;
B、空值 is null
SELECT * FROM demo where tname is null;
第五章 Select查询
结构: 执行顺序
SELECT * 5
FROM table_name 1
WHERE -----分组前的条件 2
GROUP BY 3
HAVING -----分组后的条件 4
ORDER BY column_name ASC/DESC;
6
-----------------------------
子句、聚合函数、友好列 列名 AS 别名
-----------------------------
5.1 简单查询
5.1.1 查看表结构
DESC table_name;
DESC emp;
5.1.2查看所有的列
SELECT * FROM table_name;
SELECT * FROM emp;
5.1.3 查看指定列
SELECT 列名 FROMtable_name;
SELECT empno FROM emp;
5.1.4 查看指定行
SELECT * FROM table_name WHERE column_name=值;
SELECT * FROM emp WHERE empno=7369;
5.1.5 使用算术表达式 + 、- 、/ 、*
SELECT ename,sal+1 FROM EMP;
ENAME SAL+1
---------- ----------
SMITH 801
ALLEN 1601
WARD 1251
SELECT ename,sal-2 FROM EMP;
ENAME SAL-1
---------- ----------
SMITH 799
ALLEN 1599
WARD 1249
SELECT ename,sal*2 FROM EMP;
ENAME SAL*2
---------- ----------
SMITH 1600
ALLEN 3200
WARD 2500
SELECT ename,sal/2 FROM EMP;
ENAME SAL/2
---------- ----------
SMITH 400
ALLEN 800
WARD 625
nvl(comm,0)的意思是,如果comm中有值,则nvl(comm,0)=comm;
comm中无值,则nvl(comm,0)=0
5.1.3 连接运算符 ||
SELECT 'how'||'do' ||sno;
5.1.4 使用字段别名 AS
SELECT * FROM DEMO1 "Asd";-------带引号可以保证输入的结果
有大小写
SELECT * FROM DEMO1 asd;
5.1.5 空值 IS NULL、 IS NOT NULL
SQL>SELECT * FROM EMP WHERE COMM IS NOT NULL AND SAL IN
(SELECT ENAME,sal FROM emp WHERE ENAME LIKE '_O%') ;
5.1.6 去除重复行 DISTINCT
SQL>SELECT DISTINCT DEPTNO FROM EMP ORDER BY DEPTNO
SQL>SELECT DEPTNO FROM EMP GROUP BY DEPTNO ORDER BY
DEPTNO
5.1.7 查询结果排序 ORDERBY ASC/DESC
逆序:
SQL> SELECT * FROM emp WHERE job='CLERK' OR
ename='MILLER' ORDER BY SAL DESC;
顺序:
SQL> SELECT * FROM emp WHERE job='CLERK' OR
ename='MILLER' ORDER BY SAL ASC;
SQL> SELECT * FROM emp WHERE job='CLERK' OR
ename='MILLER' ORDER BY SAL ;
5.1.8 关系运算符 >、 < 、=、(!= or <>) MOD(模,类似于%)、
BETWEEN AND、 NOT BETWEENAND
SQL> SELECT DISTINCT MGR FROM emp WHERE MGR<>7788;
SQL>SELECT DISTINCT MGR FROM emp WHERE MGR BETWEEN 7788
AND 7902;
SQL>SELECT * FROM emp WHERE MOD(DEPTNO,100)=2;
SQL>SELECT * FROM EMP1 WHERE EMPNO NOT BETWEEN 7369 AND
7521;
SQL>SELECT * FROM EMP1 WHERE EMPNO>=7369 AND EMPNO<=7521;
5.1.9 操作 IN、NOT IN
SQL> SELECT ENAME,SAL FROM EMP WHERE SAL IN(SELECT MAX
(SAL) FROM EMP1 GROUP BY DEPTNO);
5.1.10 模糊查询 LIKE、NOT LIKE----只针对字符型
% 表示零或多个字符
_ 表示一个字符
对于特殊符号可使用ESCAPE标识符来查找
select * from emp where ename like '%*_%' escape '*'
上面的escape表示*后面的那个符号不当成特殊字符处理,就是查
找普通的_符号
5.1.11 逻辑运算符 AND、OR、NOT
SQL> select * from emp where job='CLERK' OR
ename='MILLER';
SQL> select * from emp where job='CLERK' AND
ename='MILLER';
5.1.12 ANY、ALL
SQL>SELECT * FROM EMP WHERE EMPNO IN(7369,7521,7782);
SQL>SELECT * FROM EMP WHERE EMPNO>ANY(7369,7521,7782);--
大于min
SQL>SELECT * FROM EMP WHERE EMPNO>ALL(7369,7521,7782);--
大于max
SQL>SELECT * FROM EMP WHERE EMPNO
小于max
SQL>SELECT * FROM EMP WHERE EMPNO
小于min
5.1.13 练习
1、选择在部门30中员工的所有信息
Select * from emp where deptno=30;
2、列出职位为(MANAGER)的员工的编号,姓名
Select empno,ename from emp where job ="Manager";
3、找出奖金高于工资的员工
Select * from emp where comm>sal;
4、找出每个员工奖金和工资的总和
Select sal+comm,ename from emp;
5、找出部门10中的经理(MANAGER)和部门20中的普通员工(CLERK)
Select * from emp where (deptno=10 and job=?MANAGER?) or
(deptno=20 and job=?CLERK?);
6、找出部门10中既不是经理也不是普通员工,而且工资大于等于
2000的员工
Select * from emp where deptno=10 and job not in
('MANAGER') and sal>=2000;
7、找出有奖金的员工的不同工作
Select distinct job from emp where comm is not null and
comm>0;
8、找出没有奖金或者奖金低于500的员工
Select * from emp where comm<500 or comm is null;
9、显示雇员姓名,根据其服务年限,将最老的雇员排在最前面
select ename from emp order by hiredate ;
10、SQL>SELECTDEPTNO,MAX(SAL) AS tot,
MIN(COMM) AS MCOMM,
SUM(COMM) SUMC,
TRUNC(AVG(SAL+NVL(COMM,0)))TAVG,
ROUND(AVG(SAL+NVL(COMM,0)),2)RAVG,
COUNT(*)
FROM EMP
HAVINGCOUNT(*)>3
GROUP BY DEPTNO
ORDER BY DEPTNO
11、SQL>SELECT ENAME,SAL
FROM EMP
WHERE SAL IN(SELECT MAX(SAL)
FROM EMP1
GROUP BY
DEPTNO);
5.2 多表查询
INNER JOIN:内连接
JOIN: 如果表中有至少一个匹配,则返回行
LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行
RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行
FULL JOIN: 只要其中一个表中存在匹配,就返回行
5.2.1、笛卡尔集(CrossJoin)------------列相加,行相乘
Select * from emp,dept;
5.2.2、等值连接(Equijoin)(Naturaljoin..on)---------隐式
内联
select empno, ename, sal, emp.deptno, dname from emp,
dept where emp.deptno = dept.deptno;
5.2.3、非等值连接(Non-Equijoin)
select ename,empno,grade from emp,salgrade where sal
between losal and hisal;
5.2.4、自联接(Selfjoin)
select column_name from table_name1,table_name2 where 条
件;
select e.empno,e.ename,m.empno,m.ename from emp e,emp m
where m.mgr = e.empno;
5.2.5、内联接(InnerJoin)----------显式外联
SELECT column_name(s)
FROM table_name1
INNER JOIN table_name2
ON table_name1.column_name=table_name2.column_name
5.2.6、 左外联接(Left Outer Join )
左外连接:在内联接的基础上,增加左表中没有匹配的行,也就
是说,左表中的记录总会出现在最终结果集中
SELECT column_name(s)
FROM table_name1
LEFT JOIN table_name2
ON table_name1.column_name=table_name2.column_name
select s.sid,s.sname,s1.sid,s1.sname from student
s,student1 s1 where s.sid=s1.sid(+);
1、先通过from自句判断左表和右表;
2、接着看加号作用在那个表别名上;
3、如果作用在右表上,则为左外连接,否则为右外连接
select empno,ename,dname from emp left outer join dept on
emp.deptno = dept.deptno;
5.2.7、右外联接(RightOuter Join)
右外连接:在内联接的基础上,增加右表中没有匹配的行,也就
是说,右表中的记录总会出现在最终结果集中
SELECT column_name(s)
FROM table_name1
RIGHT JOIN table_name2
ON table_name1.column_name=table_name2.column_name
右外联接转换为内联接
SELECT column_name(s)
FROM table_name1
RIGHT JOIN table_name2
ON table_name1.column_name=table_name2.column_name WHERE
table_name1.column_name is not null;
select s.sid,s.sname,s1.sid,s1.sname from student
s,student1 s1 where s.sid(+)=s1.sid;
select empno,ename,dname from emp right outer join dept
on emp.deptno= dept.deptno;
select * from emp1 e right join dept d on
e.deptno=d.deptno where e.deptno is not null;
5.2.8、全外联接(FullOuter Join)
SELECT column_name(s)
FROM table_name1
FULL JOIN table_name2
ON table_name1.column_name=table_name2.column_name
select empno,ename,dname from emp full outer join dept on
emp.deptno = dept.deptno;
5.2.9、集合操作
· UNION:并集,所有的内容都查询,重复的显示一次
·UNION ALL:并集,所有的内容都显示,包括重复的
· INTERSECT:交集:只显示重复的
· MINUS:差集:只显示对方没有的(跟顺序是有关系的)
SELECT column_name(s) FROM table_name1
UNION/INTERSECT/MINUS
SELECT column_name(s) FROM table_name2
首先建立一张只包含 20 部门员工信息的表:
CREATE TABLE emp20 AS SELECT * FROM emp WHERE deptno=20
;
1、验证 UNION 及 UNION ALL
UNION:SELECT * FROMemp UNION SELECT * FROM emp20 ;
使用此语句重复的内容不再显示了
UNION ALL:SELECT * FROMemp UNION ALL SELECT * FROM
emp20 ;
重复的内容依然显示
2、验证 INTERSECT
SELECT * FROM emp INTERSECT SELECT * FROM emp20 ; 只显示
了两个表中彼此重复的记录。
MINUS:返回差异的记录
SELECT * FROM emp MINUS SELECT * FROM emp20 ; 只显示了两
张表中的不同记录满链接也可以用以下的方式来表示:
select t1.id,t2.id from table1 t1,table t2 where
t1.id=t2.id(+) union
select t1.id,t2.id from table1 t1,table t2 where t1.id
(+)=t2.id
5.3 子查询
5.3.1、单行子查询
select * from emp
where sal > (select sal from emp where empno = 7566);
5.3.2、 子查询空值/多值问题
如果子查询未返回任何行,则主查询也不会返回任何结果
(空值)select *from emp where sal > (select sal from emp
where empno = 8888);
如果子查询返回单行结果,则为单行子查询,可以在主查询中对
其使用相应的单行记录比较运算符
(正常)select *from emp where sal > (select sal from emp
where empno = 7566);
如果子查询返回多行结果,则为多行子查询,此时不允许对其使
用单行记录比较运算符
(多值)select *from emp where sal > (select avg(sal) from
emp group by deptno);//非法----错误的
5.3.3、 多行子查询
select * from emp where sal > any(select avg(sal) from
emp group by deptno);
select * from emp where sal > all(select avg(sal) from
emp group by deptno);
select * from emp where job in (select job from emp where
ename = 'MARTIN' or ename = 'SMITH');
5.3.4、 分页查询
Oracle分页
①采用rownum关键字(三层嵌套)
SELECT * FROM(
SELECT A.*,ROWNUM num FROM (
SELECT * FROM t_order)A
WHERE ROWNUM<=15)
WHERE num>=5; --返回第5-15行数据
②采用row_number解析函数进行分页(效率更高)
SELECT xx.* FROM(
SELECT t.*,row_number() over(ORDER BY o_id)AS num
FROM t_order t
)xx
WHERE num BETWEEN 5 AND 15;
ROWID和ROWNUM的区别
1、ROWID是物理地址,用于定位ORACLE中具体数据的物理存储位
置是唯一的18位物理编号,而ROWNUM则是根据sql查询后得到的结
果自动加上去的
2、ROWNUM是暂时的并且总是从1开始排起,而ROWID是永久的。
解析函数能用格式
函数()over(pertion by 字段 order by 字段);
ROW_NUMBER(): Row_number函数返回一个唯一的值,当碰到相同
数据时,排名按照记录集中记录的顺序依次递增。 row_number()
和rownum差不多,功能更强一点(可以在各个分组内从1开时排序
),因为row_number()是分析函数而rownum是伪列所以
row_number()一定要over而rownum不能over。
RANK():Rank函数返回一个唯一的值,除非遇到相同的数据,此
时所有相同数据的排名是一样的,同时会在最后一条相同记录和
下一条不同记录的排名之间空出排名。rank()是跳跃排序,有两
个第二名时接下来就是第四名(同样是在各个分组内)。
DENSE_RANK():Dense_rank函数返回一个唯一的值,除非当碰到
相同数据,此时所有相同数据的排名都是一样的。
dense_rank()是连续排序,有两个第二名时仍然跟着第三名。他
和row_number的区别在于row_number是没有重复值的。
dense_rank()是连续排序,有两个第二名时仍然跟着第三名。他
和row_number的区别在于row_number是没有重复值的。
下面举个例子:
SQL> select * from user_order order by customer_sales;
REGION_ID CUSTOMER_ID CUSTOMER_SALES
---------- ----------- --------------
10 30 1216858
5 2 1224992
9 24 1224992
9 23 1224992
8 18 1253840
【3】row_number()、rank()、dense_rank()这三个分析函数的区
别实例
SQL>SELECT empno, deptno, SUM(sal) total,
RANK() OVER(ORDERBY SUM(sal) DESC) RANK,
dense_rank()OVER(ORDER BY SUM(sal) DESC)
dense_rank,
row_number()OVER(ORDER BY SUM(sal) DESC)
row_number
FROM emp1 GROUP BY empno, deptno;
--------------------------------------------------
1 7839 10 5000 1 1 1
2 7902 20 3000 2 2 2
3 7788 20 3000 2 2 3
4 7566 20 2975 4 3 4
5 7698 30 2850 5 4 5
6 7782 10 2450 6 5 6
7 7499 30 1600 7 6 7
比较上面3种不同的策略,我们在选择的时候就要根据客户的需求
来定夺了:
①假如客户就只需要指定数目的记录,那么采用row_number是最
简单的,但有漏掉的记录的危险
②假如客户需要所有达到排名水平的记录,那么采用rank或
dense_rank是不错的选择。至于选择哪一种则看客户的需要,选
择dense_rank或得到最大的记录
Mysql分页采用limt关键字
select * from t_order limit 5,10; #返回第6-15行数据
select * from t_order limit 5; #返回前5行
select * from t_order limit 0,5; #返回前5行
Mssql 2000分页采用top关键字(20005以上版本也支持关键字
rownum)
Select top 10 * from t_order where id not in (select id
from t_order where id>5 ); //返回第6到15行数据其中10表示
取10记录 5表示从第5条记录开始取
sql server 分页采用top关键字
5.3.5、 in 、exists
EXISTS 的执行流程
select * from t1 where exists ( select null from t2 where
y = x )
可以理解为:
for x in ( select * from t1 ) loop
if ( exists ( select null from t2 where y = x.x ) then
OUTPUT THE RECORD
end if;
end loop;
对于 in 和 exists 的性能区别:
如果子查询得出的结果集记录较少,主查询中的表较大且又有
索引时应该用 in,反之如果外层的主查询记录较少,子查询中的
表大,又有索引时使用exists。
其实我们区分 in 和 exists 主要是造成了驱动顺序的改变(
这是性能变化的关键),如果是exists,那么以外层表为驱动表
,先被访问,如果是 IN,那么先执行子查询,所以我们会以驱动
表的快速返回为目标,那么就会考虑到索引及结果集的关系了 另
外 IN 是不对 NULL 进行处理
如:
select 1 from dual where not in (0,1,2,null) 为空
第六章 约束
约束就是指对插入数据的各种限制,例如:人员的姓名不能为空
,人的年龄只能在0~150 岁之间。约束可以对数据库中的数据进
行保护。 约束可以在建表的时候直接声明,也可以为已建好的表
添加约束。
6.1、NOT NULL:非空约束 例如:姓名不能为空
CREATE TABLE person(
pid NUMBER ,
name VARCHAR2(30) NOT NULL
) ;
alter table emp
-- 插入数据
INSERT INTO person(pid,name) VALUES (11,'张三');
-- 错误的数据,会受到约束限制,无法插入
INSERT INTO person(pid) VALUES (12);
6.2、 PRIMARY KEY:主键约束
· 不能重复,不能为空 · 例如:身份证号不能为空。 现在假
设pid字段不能为空,且不能重复。
DROP TABLE person ;
CREATE TABLE person
(
pid NUMBER PRIMARY KEY , name VARCHAR(30) NOT NULL
) ;
-- 插入数据
INSERT INTO person(pid,name) VALUES (11,'张三');
-- 主键重复了
INSERT INTO person(pid,name) VALUES (11,'李四');
6.3、UNIQUE:唯一约束,值不能重复(空值除外) 人员中有电
话号码,电话号码不能重复。
DROP TABLE person ;
CREATE TABLE person
(
pid NUMBER PRIMARY KEY NOT NULL , name VARCHAR(30) NOT
NULL , tel VARCHAR(50) UNIQUE
) ;
-- 插入数据
INSERT INTO person(pid,name,tel) VALUES (11,'张
三','1234567');
-- 电话重复了
INSERT INTO person(pid,name,tel) VALUES (12,'李
四','1234567');
6.4、CHECK:条件约束,插入的数据必须满足某些条件
例如:人员有年龄,年龄的取值只能是 0~150 岁之间
DROP TABLE person ;
CREATE TABLE person(
pid NUMBER PRIMARY KEY NOT NULL ,
name VARCHAR2(30) NOT NULL ,
tel VARCHAR2(50) NOT NULL UNIQUE ,
age NUMBER CHECK(age BETWEEN 0 AND 150)
) ;
-- 插入数据
INSERT INTO person(pid,name,tel,age) VALUES (11,'张
三','1234567',30);
-- 年龄的输入错误
INSERT INTO person(pid,name,tel,age) VALUES (12,'李
四','2345678',-100);
alter table product
add constriant chk_product_unitprice check(unitprice>0);
6.5、Foreign Key:外键
例如:有以下一种情况:
· 一个人有很多本书:
|- Person 表
|- Book 表:而且book 中的每一条记录表示一本书的信息,一
本书的信息属于一个人
CREATE TABLE book(
bid NUMBER PRIMARY KEY NOT NULL ,
name VARCHAR(50) ,
-- 书应该属于一个人 pidNUMBER
) ;
如果使用了以上的表直接创建,则插入下面的记录有效:
INSERT INTO book(bid,name,pid) VALUES(1001,'JAVA',12) ;
以上的代码没有任何错误,但是没有任何意义,因为一本书应该
属于一个人,所以在此处的pid的取值应该与person 表中的pid一
致。
此时就需要外键的支持。修改book的表结构
DROP TABLE book ;
CREATE TABLE book
(
bid NUMBER PRIMARY KEY NOT NULL , name VARCHAR(50) ,
-- 书应该属于一个人 pidNUMBER REFERENCES person(pid) ON
DELETE CASCADE
-- 建立约束:book_pid_fk,与person中的pid 为主-外键关系
--CONSTRAINT book_pid_fk FOREIGN KEY(pid) REFERENCES
person(pid)
) ;
INSERT INTO book(bid,name,pid) VALUES(1001,'JAVA',12) ;
6.6、级联删除
此时如果想完成删除person表的数据同时自动删除掉book表的
数据操作,则必须使用级联删除。
在建立外键的时候必须指定级联删除(ON DELETE CASCADE)。
CREATE TABLE book
(
bid NUMBER PRIMARY KEY NOT NULL , name VARCHAR(50) ,
-- 书应该属于一个人
pid NUMBER ,
-- 建立约束:book_pid_fk,与person中的pid 为主-外键关系
CONSTRAINT book_pid_fk FOREIGN KEY(pid) REFERENCES
person(pid) ON DELETE CASCADE
) ;
DROP TABLE book ;
DROP TABLE person ;
CREATE TABLE person(
pid NUMBER ,
name VARCHAR(30) NOT NULL ,
tel VARCHAR(50) ,
age NUMBER
) ;
CREATE TABLE book(
bid NUMBER ,
name VARCHAR2(50) ,
pid NUMBER
) ;
以上两张表中没有任何约束,下面使用 alter 命令为表添加约
束
ALTER TABLE table_name ADD CONSTRAINT column_name 约束;
1、 为两个表添加主键:
· person 表 pid 为主键:
ALTER TABLE person ADD CONSTRAINT person_pid_pk
PRIMARY KEY(pid) ;
· book 表 bid 为主键:
ALTER TABLE book ADD CONSTRAINT book_bid_pk PRIMARY
KEY(bid) ;
2、 为 person 表中的 tel 添加唯一约束:
ALTER TABLE person ADD CONSTRAINT person_tel_uk UNIQUE
(tel) ;
3、 为 person 表中的 age 添加检查约束:
ALTER TABLE person ADD CONSTRAINT person_age_ck CHECK
(age BETWEEN 0 AND
150) ;
4、 为 book 表中的 pid 添加与 person 的主-外键约束,要求
带级联删除
ALTER TABLE book ADD CONSTRAINT person_book_pid_fk
FOREIGN KEY (pid)
REFERENCES person(pid) ON DELETE CASCADE ;
Q:如何用alter添加非空约束
A:用 check约束
6.7、删除约束:
ALTER TABLE book DROP CONSTRAINT person_book_pid_fk ;
alter table student drop unique(tel);
6.8、 启用约束
ALTER TABLE book enable CONSTRAINT person_book_pid_fk ;
6.9、 禁用约束
ALTER TABLE book disable CONSTRAINT person_book_pid_fk ;
第七章 SQL函数
7.1 单行函数
1、字符函数
Upper -------大写
SELECT Upper ('abcde') FROM dual ;
SELECT * FROM emp WHERE ename=UPPER('smith') ;
Lower --------小写
SELECT lower('ABCDE') FROM dual ;
Initcap--------首字母大写
Select initcap(ename) from emp;
Concat----联接
Select concat('a','b') from dual;
Select 'a'||'b' from dual;
Substr------截取
Select substr('abcde',length('abcde')-2) from dual;
Select substr('abcde',-3,3) from dual;
Length------长度
Select length(ename) from emp;
Replace------替代
Select replace(ename,'a','A') from emp;
Instr---------- indexof
Select instr('Hello World','or') from dual;
Lpad------------左侧填充 lpad()*****Smith
lpad('Smith',10,'*')
Rpad-------------右侧填充rpad()Smith*****
rpad('Smith',10,'*')
Trim-------------过滤首尾空格 trim()Mr Smith
trim(' Mr Smith ')
2、数值函数
Round
select round(412,-2) from dual; --400
select round(412.313,2) from dual;
Mod
select MOD(412,3) from dual;
Trunc
select trunc(412.13,-2) from dual;
3、日期函数
Months_between()
select months_between(sysdate,hiredate) from emp;
Add_months()
select add_months(sysdate,1) from dual;
Next_day()
select next_day(sysdate,'星期一') from dual;
Last_day
select last_day(sysdate) from dual;
4.4、转换函数
To_char
select to_char(sysdate,'yyyy') from dual; select to_char
(sysdate,'fmyyyy-mm-dd') from dual; select to_char
(sal,'L999,999,999') from emp; select to_char(sysdate,’D
’) from dual;//返回星期
To_number
select to_number('13')+to_number('14') from dual;
To_date
Select to_date(?20090210?,?yyyyMMdd?) from dual;
5、通用函数
NVL()函数
select nvl(comm,0) from emp;
NULLIF()函数
如果表达式 exp1 与 exp2 的值相等则返回 null,否则返回
exp1 的值
NVL2()函数 selectempno, ename, sal, comm, nvl2(comm,
sal+comm, sal) total from emp;
COALESCE()函数
依次考察各参数表达式,遇到非null 值即停止并返回该值。
select empno, ename, sal, comm, coalesce(sal+comm, sal,
0)总收入 from emp;
CASE 表达式------区间
SQL>select empno,
ename,
sal,
case deptno
when 10 then '财务部'
when 20 then '研发部'
when 30 then '销售部'
else '未知部门'
end 部门
from emp;
SQL>SELECT e.*,
CASE
WHEN sal>=3000 THEN '高'
WHEN sal>=2000 AND sal<3000THEN '中'
WHEN sal<2000 AND sal>0 THEN '高'
ELSE 'un'
END ca
FROM emp1 e;
DECODE()函数------------离散的值
SQL>select empno, ename, sal,
decode(deptno,
10, '财务部',
20, '研发部',
30, '销售部',
'未知部门') 部门
from emp;
单行函数嵌套
select empno, lpad(initcap(trim(ename)),10,' ') name,
job, sal from emp;
7.2 分组函数
1、COUNT
如果数据库表的没有数据,count(*)返回的不是 null,而是 0
2、Avg,max,min,sum
3、nvl----分组函数与空值
分组函数省略列中的空值
select avg(comm) from emp; select sum(comm) from emp;
可使用 NVL()函数强制分组函数处理空值 select avg(nvl(comm,
0)) from emp;
4、GROUP BY 子句
出现在 SELECT 列表中的字段或者出现在 order by 后面的字段
,如果不是包含在分组函数中,那么该字段必须同时在 GROUP BY
子句中出现。包含在GROUP BY 子句中的字段则不必须出现在
SELECT 列表中。
可使用 where 字句限定查询条件,可使用 Order by 子句指定排
序方式
如果没有 GROUP BY 子句,SELECT 列表中不允许出现字段(单行
函数)与分组函数混用的情况。
select empno, sal from emp; //合法 select avg(sal) from
emp; //合法 selectempno, initcap(ename), avg(sal) from
emp; //非法
不允许在 WHERE 子句中使用分组函数。 select deptno, avg
(sal) from emp where avg(sal) > 2000; group by deptno;
5、HAVING 子句
select deptno, job, avg(sal)
from emp
where hiredate >= to_date('1981-05-01','yyyy-mm-dd')
group by deptno,job having avg(sal) > 1200 order by
deptno,job;
6、分组函数嵌套
select max(avg(sal)) from emp group by deptno;
第八章 PLSQL变量与常量
1、声明变量
变量一般都在PL/SQL块的声明部分声明,引用变量前必须首
先声明,要在执行或异常处理部分使用变量,那么变量必须首先
在声明部分进行声明。
声明变量的语法如下:
Variable_name [CONSTANT] databyte [NOT NULL][:=|DEFAULT
expression]
注意:可以在声明变量的同时给变量强制性的加上NOT NULL
约束条件,此时变量在初始化时必须赋值。
2、给变量赋值
给变量赋值有两种方式:
. 直接给变量赋值
X:=200;
Y=Y+(X*20);
. 通过SQL SELECT INTO 或FETCH INTO给变量赋值
SELECT SUM(SALARY),SUM(SALARY*0.1)
INTO TOTAL_SALARY,TATAL_COMMISSION
FROM EMPLOYEE
WHERE DEPT=10;
3、常量
常量与变量相似,但常量的值在程序内部不能改变,常量的
值在定义时赋予,,他的声明方式与变量相似,但必须包括关键
字CONSTANT。常量和变量都可被定义为SQL和用户定义的数据类型
。
ZERO_VALUE CONSTANT NUMBER:=0;
4、标量(scalar)数据类型
标量(scalar)数据类型没有内部组件,他们大致可分为以下
四类:
. number
. char
. date/time
. boolean
表1 Numer
Datatype Range Subtypes description
BINARY_INTEGER -214748-2147483647 NATURAL
NATURAL
NPOSITIVE
POSITIVEN
SIGNTYPE
用于存储单字节整数。
要求存储长度低于NUMBER值。
用于限制范围的子类型(SUBTYPE):
NATURAL:用于非负数
POSITIVE:只用于正数
NATURALN:只用于非负数和非NULL值
POSITIVEN:只用于正数,不能用于NULL值
SIGNTYPE:只有值:-1、0或1.
NUMBER 1.0E-130-9.99E125 DEC
DECIMAL
DOUBLE
PRECISION
FLOAT
INTEGERIC
INT
NUMERIC
REAL
SMALLINT 存储数字值,包括整数和浮点数。可以选择精度和刻度
方式,语法:
number[([,])]。
缺省的精度是38,scale是0.
PLS_INTEGER -2147483647-2147483647 与BINARY_INTEGER基本相
同,但采用机器运算时,PLS_INTEGER提供更好的性能 。
表2 字符数据类型
datatype rang subtype description
CHAR 最大长度32767字节 CHARACTER 存储定长字符串,如果长度
没有确定,缺省是1
LONG 最大长度2147483647字节 存储可变长度字符串
RAW 最大长度32767字节 用于存储二进制数据和字节字符串,当
在两个数据库之间进行传递时,RAW数据不在字符集之间进行转换
。
LONGRAW 最大长度2147483647与LONG数据类型相似,同样他也不
能在字符集之间进行转换。
ROWID 18个字节 与数据库ROWID伪列类型相同,能够存储一个行
标示符,可以将行标示符看作数据库中每一行的唯一键值。
VARCHAR2 最大长度32767字节 STRINGVARCHAR 与VARCHAR数据类
型相似,存储可变长度的字符串。声明方法与VARCHAR相同
表3 DATE和BOOLEAN
datatype range description
BOOLEAN TRUE/FALSE 存储逻辑值TRUE或FALSE,无参数
DATE 01/01/4712 BC 存储固定长的日期和时间值,日期值中包含
时间
LOB数据类型
LOB(大对象,Large object) 数据类型用于存储类似图像,声
音这样的大型数据对象,LOB数据对象可以是二进制数据也可以是
字符数据,其最大长度不超过4G。LOB数据类型支持任意访问方式
,LONG只支持顺序访问方式。LOB存储在一个单独的位置上,同时
一个"LOB定位符"(LOB locator)存储在原始的表中,该定位符是
一个指向实际数据的指针。在PL/SQL中操作LOB数据对象使用
ORACLE提供的包DBMS_LOB.LOB数据类型可分为以下四类:
.BFILE----------------二进制文件
.BLOB--------------二进制对象
.CLOB---------------字符型对象
.NCLOB-------------nchar类型对象
操作符
PL/SQL有一系列操作符。操作符分为下面几类:
. 算术操作符
. 关系操作符
. 比较操作符
. 逻辑操作符
算术操作符如表4所示
operator operation
+ 加
- 减
/ 除
* 乘
** 乘方
关系操作符主要用于条件判断语句或用于where子串中,关系
操作符检查条件和结果是否为true或false,
表5PL/SQL中的关系操作符
operator operation
< 小于操作符
<= 小于或等于操作符
> 大于操作符
>= 大于或等于操作符
= 等于操作符
!= 不等于操作符
<> 不等于操作符
:= 赋值操作符
表6 显示的是比较操作符
operator operation
IS NULL 如果操作数为NULL返回TRUE
LIKE 比较字符串值
BETWEEN 验证值是否在范围之内
IN 验证操作数在设定的一系列值中
表7显示的是逻辑操作符
operator operation
AND 两个条件都必须满足
OR 只要满足两个条件中的一个
NOT 取反
第九章PL/SQL--------动态SQL
PL/SQL动态SQL(原创)
概念:动态SQL,编译阶段无法明确SQL命令,只有在运行阶段才
能被识别
动态SQL和静态SQL两者的异同
静态SQL为直接嵌入到PL/SQL中的代码,而动态SQL在运行时,根
据不同的情况产生不同的SQL语句。
静态SQL在执行前编译,一次编译,多次运行。动态SQL同样在执
行前编译,但每次执行需要重新编译。
静态SQL可以使用相同的执行计划,对于确定的任务而言,静态
SQL更具有高效性,但缺乏灵活性;动态SQL使用了不同的执行计
划,效率不如静态SQL,但能够解决复杂的问题。
动态SQL容易产生SQL注入,为数据库安全带来隐患。
动态SQL语句的几种方法
a.使用EXECUTEIMMEDIATE语句
包括DDL语句,DCL语句,DML语句以及单行的SELECT 语句。该方
法不能用于处理多行查询语句。
b.使用OPEN-FOR,FETCH和CLOSE语句
对于处理动态多行的查询操作,可以使用OPEN-FOR语句打开游标
,使用FETCH语句循环提取数据,最终使用CLOSE语句关闭游标。
c.使用批量动态SQL
即在动态SQL中使用BULK子句,或使用游标变量时在fetch中使用
BULK ,或在FORALL语句中使用BULK子句来实现。
d.使用系统提供的PL/SQL包DBMS_SQL来实现动态SQL
动态SQL的语法
下面是动态SQL常用的语法之一
EXECUTE IMMEDIATE dynamic_SQL_string
[INTO defined_variable1, defined_variable2, ...]
[USING [IN | OUT | IN OUT] bind_argument1,
bind_argument2,...]
[{RETURNING | RETURN} field1, field2, ... INTO
bind_argument1,
bind_argument2, ...]
语法描述
dynamic_SQL_string:存放指定的SQL语句或PL/SQL块的字符串变
量
defined_variable1:用于存放单行查询结果,使用时必须使用
INTO关键字,类似于使用
SELECT ename INTO v_name FROM scott.emp;
只不过在动态SQL时,将INTO defined_variable1移出到
dynamic_SQL_string语句之外。
bind_argument1:用于给动态SQL语句传入或传出参数,使用时必
须使用USING关键字,IN表示传入的参数,OUT表示传出的参数,
IN OUT则既可以传入,也可传出。
RETURNING | RETURN 子句也是存放SQL动态返回值的变量。
使用要点
a.EXECUTE IMMEDIATE执行DML时,不会提交该DML事务,需要使用
显示提交(COMMIT)或作为EXECUTE IMMEDIATE自身的一部分。
b.EXECUTE IMMEDIATE执行DDL,DCL时会自动提交其执行的事务。
c.对于多行结果集的查询,需要使用游标变量或批量动态SQL,或
者使用临时表来实现。
d.当执行SQL时,其尾部不需要使用分号,当执行PL/SQL 代码时
,其尾部需要使用分号。
f.动态SQL中的占位符以冒号开头,紧跟任意字母或数字表示。
动态SQL的使用(DDL,DCL,DML以及单行结果集)
DECLARE
v_table VARCHAR2(30):='emp1';
v_sql LONG:='SELECT ename FROM emp1 WHERE empno=:1';--
占位符\可以用任何符号(数字或字母)
--v_no emp1.empno%TYPE:='&请输入号码';--&是变量绑定符
绑定的数据是字符串类型时必须要加引号
--v_no emp1.empno%TYPE:=&请输入号码;
v_name emp1.ename%TYPE;
BEGIN
--EXECUTE IMMEDIATE v_sql INTO v_name USING IN v_no;
dbms_output.put_line('ename='||v_name);
--EXECUTE IMMEDIATE 'create table emp2 as select * from
emp';
--EXECUTE IMMEDIATE 'drop table '||v_table;
--EXECUTE IMMEDIATE 'alter table emp enable row
movement';
END;
BULK子句和动态SQL的使用
动态SQL中使用BULK子句的语法
EXECUTE IMMEDIATE dynamic_string --dynamic_string用于存放
动态SQL字符串
[BULK COLLECT INTO define_variable[,define_variable...]]
--存放查询结果的集合变量
[USING bind_argument[,argument...]] --使用参数传递给动态
SQL
[{RETURNING | RETURN} --返回子句
BULK COLLECT INTO return_variable[,return_variable...]];
--存放返回结果的集合变量
使用bulk collectinto子句处理动态SQL中T的多行查询可以加快
处理速度,从而提高应用程序的性能。当使用bulk子句时,集合
类型可以是PL/SQL所支持的索引表、嵌套表和VARRY,但集合元
素必须使用SQL数据类型。常用的三种语句支持BULK子句,分别为
EXECUTE IMMEDIATE,FETCH 和FORALL。
使用EXECUTEIMMEDIATE 结合BULK子句处理多行查询。使用了
BULK COLLECT INTO来传递结果。
SQL>declare
type ename_table_type is table of emp1.ename%type index
by binary_integer;
type sal_table_type is table OF emp1.sal%type index by
binary_integer;
ename_table ename_table_type;
sal_table sal_table_type;
sql_stat varchar2(100);
v_dno number := 7369;
begin
sql_stat := 'select ename,sal from emp1 where deptno
= :v_dno'; --动态DQL语句,未使用RETURNING子句
execute immediate sql_stat
bulk collect into ename_table,sal_table using v_dno;
for i in 1..ename_table.count loop
dbms_output.put_line('Employee ' ||ename_table
(i) || ' Salary is: ' || sal_table(i));
end loop;
end;
使用FETCH子句结合BULK子句处理多行结果集
下面的示例中首先定义了游标类型,游标变量以及复合类型,复
合变量,接下来从动态SQL中OPEN游标,然后使用FETCH将结果存
放到复合变量中。即使用OPEN,FETCH代替了EXECUTE IMMEDIATE
来完成动态SQL的执行。
SQL> declare
2 type empcurtype is ref cursor;
3 emp_cv empcurtype;
4 type ename_table_type is table of tb2.ename%type
index by binary_integer;
5 ename_table ename_table_type;
6 sql_stat varchar2(120);
7 begin
8 sql_stat := 'select ename from tb2 where deptno =
:dno';
9 open emp_cv for sql_stat using &dno;
10 fetch emp_cv bulk collect into ename_table;
11 for i in 1..ename_table.count loop
12 dbms_output.put_line('Employee Name: ' ||
ename_table(i));
13 end loop;
14 close emp_cv;
15* end;
在FORALL语句中使用BULK子句
下面是FORALL子句的语法
FORALL index IN lower bound..upper bound --FORALL循环计数
EXECUTE IMMEDIATE dynamic_string --结合EXECUTE IMMEDIATE
来执行动态SQL语句
USING bind_argument | bind_argument(index) --绑定输入参数
[bind_argument | bind_argument(index)]...
[{RETURNING | RETURN} BULK COLLECT INTO bind_argument
[,bind_argument...]]; --绑定返回结果集
FORALL子句允许为动态SQL输入变量,但FORALL子句仅支持的DML
(INSERT,DELETE,UPDATE)语句,不支持动态的SELECT语句。
下面的示例中,首先声明了两个复合类型以及复合变量,接下来
为复合变量ename_table赋值,以形成动态SQL语句。紧接着使用
FORALL子句结合EXECUTEIMMEDIATE 来提取结果集。
SQL> declare
2 type ename_table_type is table of tb2.ename%type;
3 type sal_table_type is table of tb2.sal%type;
4 ename_table ename_table_type;
5 sal_table sal_table_type;
6 sql_stat varchar2(100);
7 begin
8 ename_table := ename_table_type
('BLAKE','FORD','MILLER');
9 sql_stat := 'update tb2 set sal = sal * 1.1 where
ename = :1'
10 || ' returning sal into :2';
11 forall i in 1..ename_table.count
12 execute immediate sql_stat using ename_table(i)
returning bulk collect into sal_table;
13 for j in 1..sal_table.count loop
14 dbms_output.put_line('The ' || ename_table(j) || ''''
|| 's new salalry is ' || sal_table(j));
15 end loop;
16* end;
常见错误
1、使用动态DDL时,不能使用绑定变量。
EXECUTE IMMEDIATE 'CREATE TABLE dsa '||'as select * from
:1' USING IN v_table;
解决办法,将绑定变量直接拼接,如下:
EXECUTE IMMEDIATE 'CREATE TABLE dsa '||'as select * from
'|| v_table;
2、不能使用schema对象作为绑定参数,下面的示例中,动态SQL
语句查询需要传递表名,因此收到了错误提示。
EXECUTE IMMEDIATE 'SELECT COUNT(*) FROM:tb_name ' into
v_count;
解决办法,将绑定变量直接拼接,如下:
EXECUTE IMMEDIATE 'SELECT COUNT(*) FROM ' || tb_name into
v_count;
3、动态SQL块不能使用分号结束(;)
execute immediate 'select count(*) from emp;' --此处多
出了分号,应该去掉
4、动态PL/SQL块不能使用正斜杠来结束块,但是块结尾处必须要
使用分号(;)
SQL> declare
2 plsql_block varchar2(300);
3 begin
4 plsql_block := 'Declare ' ||
5 ' v_date date; ' ||
6 ' begin ' ||
7 ' select sysdate into v_date from dual; ' ||
8 ' dbms_output.put_line(to_char(v_date,''yyyy-mm-
dd'')); ' ||
9 ' end;
10 /'; --此处多出了/,应该将其去掉
11 execute immediate plsql_block;
12* end;
4、空值传递的问题
下面的示例中对表tb_emp更新,并将空值更新到sal列,直接使用
USING NULL收到错误提示。
execute immediate sql_stat using null,v_empno;
正确的处理方法
v_sal tb2.sal%type; --声明一个新变量,但不赋值
execute immediate sql_stat using v_sal,v_empno;
5、日期和字符型必须要使用引号来处理
DECLARE
sql_stat VARCHAR2(100);
v_date DATE :=TO_DATE('2013-11-21','yyyy-mm-dd');
v_empno NUMBER :=7900;
v_ename emp.ename%TYPE;
v_sal emp.sal%TYPE;
BEGIN
sql_stat := 'SELECT ename,sal FROM emp WHERE
hiredate=:v_date';
EXECUTE IMMEDIATE sql_stat
INTO v_ename,v_sal
USING v_date;
DBMS_OUTPUT.PUT_LINE('Employee Name '||v_ename||', sal
is '||v_sal);
END;
6、单行SELECT 查询不能使用RETURNING INTO返回
下面的示例中,使用了动态的单行SELECT查询,并且使用了
RETURNING子句来返回值。事实上,RETURNINGcoloumn_name
INTO 子句仅仅支持对DML结果集的返回,因此,收到了错误提示
。
SQL>declare
v_empno emp.empno%type := &empno;
v_ename emp.ename%type;
begin
execute immediate 'select ename from emp where empno =
:eno' into v_ename using v_empno;
dbms_output.put_line('Employee name: ' || v_ename);
end;
第十章PL/SQL---------游标
游标的使用
在 PL/SQL 程序中,对于处理多行记录的事务经常使用游标
来实现。
4.1 游标概念
对于不同的SQL语句,游标的使用情况不同:
SQL语句
游标
非查询语句
隐式的
结果是单行的查询语句
隐式的或显示的
结果是多行的查询语句
显示的
游标名%属性名
显式游标的名字右用户定义,隐式游标名为SQL
隐式游标只是一个状态
4.1.1 处理显式游标
1. 显式游标处理
语法格式:
CURSOR cursor_name is select * from emp;
OPEN cursor_name;
FETCH cursor_name INTO variables_list;
CLOSE cursor_name;
例1:
DECLARE
v_deptno NUMBER:=&inputno;
v_row emp1%ROWTYPE;
CURSOR v_cursor IS SELECT * FROM emp1 WHERE
deptno=v_deptno;
BEGIN
--打开
OPEN v_cursor;
--提取
LOOP
FETCH v_cursor INTO v_row;--先提取
EXIT WHEN v_cursor%NOTFOUND;
dbms_output.put_line('Employee Name: ' || v_row.ename
|| ' ,Salary: ' || v_row.sal);
END LOOP;
--关闭
CLOSE v_cursor;
END;
显式游标处理需四个PL/SQL步骤:
l 定义/声明游标:就是定义一个游标名,以及与其相对应的
SELECT 语句。
格式:
CURSOR cursor_name[(parameter[, parameter]…)]
[RETURN datatype]
IS
select_statement;
select_statement;
游标参数只能为输入参数,其格式为:
parameter_name [IN] datatype [{:= | DEFAULT} expression]
在指定数据类型时,不能使用长度约束。如NUMBER(4),CHAR(10)
等都是错误的。
[RETURN datatype]是可选的,表示游标返回数据的数据。如果选
择,则应该严格与select_statement中的选择列表在次序和数据
类型上匹配。一般是记录数据类型或带“%ROWTYPE”的数据。
l 打开游标:就是执行游标所对应的SELECT 语句,将其查询结果
放入工作区,并且指针指向工作区的首部,标识游标结果集合。
如果游标查询语句中带有FORUPDATE选项,OPEN 语句还将锁定数
据库表中游标结果集合对应的数据行。
格式:
OPEN cursor_name[([parameter =>] value[, [parameter =>]
value]…)];
在向游标传递参数时,可以使用与函数参数相同的传值方法,即
位置表示法和名称表示法。PL/SQL程序不能用OPEN 语句重复打
开一个游标。
l 提取游标数据:就是检索结果集合中的数据行,放入指定的输
出变量中。
格式:
FETCH cursor_name INTO {variable_list | record_variable
};
执行FETCH语句时,每次返回一个数据行,然后自动将游标移动指
向下一个数据行。当检索到最后一行数据时,如果再次执行FETCH
语句,将操作失败,并将游标属性%NOTFOUND置为TRUE。所以每次
执行完FETCH语句后,检查游标属性%NOTFOUND就可以判断FETCH语
句是否执行成功并返回一个数据行,以便确定是否给对应的变量
赋了值。
l 对该记录进行处理;
l 继续处理,直到活动集合中没有记录;
l 关闭游标:当提取和处理完游标结果集合数据后,应及时关闭
游标,以释放该游标所占用的系统资源,并使该游标的工作区变
成无效,不能再使用FETCH语句取其中数据。关闭后的游标可以
使用OPEN 语句重新打开。
格式:
CLOSE cursor_name;
注:定义的游标不能有INTO 子句。
例1. 查询前10名员工的信息。
DECLARE
CURSOR c_cursor
IS SELECT first_name || last_name, Salary FROM
EMPLOYEES WHERE rownum<11;
v_ename EMPLOYEES.first_name%TYPE;
v_sal EMPLOYEES.Salary%TYPE;
BEGIN
OPEN c_cursor;
FETCH c_cursor INTO v_ename, v_sal;
WHILE c_cursor%FOUND LOOP
DBMS_OUTPUT.PUT_LINE(v_ename||'---'||to_char(v_sal)
);
FETCH c_cursor INTO v_ename, v_sal;
END LOOP;
CLOSE c_cursor;
END;
2.游标属性
Cursor_name%FOUND 布尔型属性,当最近一次提取游标操作
FETCH成功则为 TRUE,否则为FALSE;
Cursor_name%NOTFOUND 布尔型属性,与%FOUND相反;
Cursor_name%ISOPEN 布尔型属性,当游标已打开时返回 TRUE;
Cursor_name%ROWCOUNT 数字型属性,返回已从游标中读取的记
录数。
例2:没有参数且没有返回值的游标。
DECLARE
v_f_name employees.first_name%TYPE;
v_j_id employees.job_id%TYPE;
CURSOR c1 --声明游标,没有参数没有返回值
IS
SELECT first_name, job_id FROM employees WHERE
department_id = 20;
BEGIN
OPEN c1; --打开游标
LOOP
FETCH c1 INTO v_f_name, v_j_id; --提取游标
IF c1%FOUND THEN
DBMS_OUTPUT.PUT_LINE(v_f_name||'的岗位是'||
v_j_id);
ELSE
DBMS_OUTPUT.PUT_LINE('已经处理完结果集了');
EXIT;
END IF;
END LOOP;
CLOSE c1; --关闭游标
END;
例3:有参数且没有返回值的游标。
DECLARE
v_f_name employees.first_name%TYPE;
v_h_date employees.hire_date%TYPE;
CURSOR c2(dept_id NUMBER, j_id VARCHAR2) --声明游标,有
参数没有返回值
IS
SELECT first_name, hire_date FROM employeesWHERE
department_id = dept_id AND job_id = j_id;
BEGIN
OPEN c2(90, 'AD_VP'); --打开游标,传递参数值
LOOP
FETCH c2 INTO v_f_name, v_h_date; --提取游标
IF c2%FOUND THEN
DBMS_OUTPUT.PUT_LINE(v_f_name||'的雇佣日期是'||
v_h_date);
ELSE
DBMS_OUTPUT.PUT_LINE('已经处理完结果集了');
EXIT;
END IF;
END LOOP;
CLOSE c2; --关闭游标
END;
例4:有参数且有返回值的游标。
DECLARE
TYPE emp_record_type IS RECORD(
f_name employees.first_name%TYPE,
h_date employees.hire_date%TYPE);
v_emp_record EMP_RECORD_TYPE;
v_emp_record EMP_RECORD_TYPE;
CURSOR c3(dept_id NUMBER, j_id VARCHAR2) --声明游标,有
参数有返回值
RETURN EMP_RECORD_TYPE
IS
SELECT first_name, hire_date FROM employeesWHERE
department_id = dept_id AND job_id = j_id;
BEGIN
OPEN c3(j_id => 'AD_VP', dept_id => 90); --打开游标,传
递参数值
LOOP
FETCH c3 INTO v_emp_record; --提取游标
IF c3%FOUND THEN
DBMS_OUTPUT.PUT_LINE(v_emp_record.f_name||'的雇
佣日期是'||v_emp_record.h_date);
ELSE
DBMS_OUTPUT.PUT_LINE('已经处理完结果集了');
EXIT;
END IF;
END LOOP;
CLOSE c3; --关闭游标
END;
例5:基于游标定义记录变量。
DECLARE
CURSOR c4(dept_id NUMBER, j_id VARCHAR2) --声明游标,有
参数没有返回值
IS
SELECT first_name f_name, hire_date FROMemployees
WHERE department_id = dept_id AND job_id = j_id;
--基于游标定义记录变量,比声明记录类型变量要方便,不
容易出错
v_emp_record c4%ROWTYPE;
BEGIN
OPEN c4(90, 'AD_VP'); --打开游标,传递参数值
LOOP
FETCH c4 INTO v_emp_record; --提取游标
IF c4%FOUND THEN
DBMS_OUTPUT.PUT_LINE(v_emp_record.f_name||'的雇
佣日期是'||v_emp_record.hire_date);
ELSE
DBMS_OUTPUT.PUT_LINE('已经处理完结果集了');
EXIT;
END IF;
END LOOP;
CLOSE c4; --关闭游标
END;
3. 游标的FOR循环
PL/SQL语言提供了游标FOR循环语句,自动执行游标的OPEN、
FETCH、CLOSE语句和循环语句的功能;当进入循环时,游标FOR循
环语句自动打开游标,并提取第一行游标数据,当程序处理完当
前所提取的数据而进入下一次循环时,游标FOR循环语句自动提取
下一行数据供程序处理,当提取完结果集合中的所有数据行后结
束循环,并自动关闭游标。
格式:
FOR index_variable IN cursor_name[(value[, value]…)]
LOOP
-- 游标数据处理代码
END LOOP;
其中:
index_variable为游标FOR 循环语句隐含声明的索引变量,该变
量为记录变量,其结构与游标查询语句返回的结构集合的结构相
同。在程序中可以通过引用该索引记录变量元素来读取所提取的
游标数据,index_variable中各元素的名称与游标查询语句选择
列表中所制定的列名相同。如果在游标查询语句的选择列表中存
在计算列,则必须为这些计算列指定别名后才能通过游标FOR 循
环语句中的索引变量来访问这些列数据。
注:不要在程序中对游标进行人工操作;不要在程序中定义用于
控制FOR循环的记录。
例6:当所声明的游标带有参数时,通过游标FOR 循环语句为游标
传递参数。
DECLARE
CURSOR c_cursor(dept_no NUMBER DEFAULT 10)
IS
SELECT department_name, location_id FROM departments
WHERE department_id <= dept_no;
BEGIN
DBMS_OUTPUT.PUT_LINE('当dept_no参数值为30:');
FOR c1_rec IN c_cursor(30) LOOP
DBMS_OUTPUT.PUT_LINE(c1_rec.department_name||'---'||
c1_rec.location_id);
END LOOP;
DBMS_OUTPUT.PUT_LINE(CHR(10)||'使用默认的dept_no参数
值10:');
FOR c1_rec IN c_cursor LOOP
DBMS_OUTPUT.PUT_LINE(c1_rec.department_name||'---'||
c1_rec.location_id);
END LOOP;
END;
例7:PL/SQL还允许在游标FOR循环语句中使用子查询来实现游标
的功能。
BEGIN
--隐含打开游标
FOR r IN (SELECT * FROM emp1 WHERE deptno=v_deptno)
LOOP
--隐含执行一个FETCH语句
dbms_output.put_line('Employee Name: ' ||r.ename
|| ' ,Salary: ' || r.sal);
--隐含监测c_sal%NOTFOUND
END LOOP;
--隐含关闭游标
END;
4.1.2 处理隐式游标
对于非查询语句,如修改、删除操作,则由ORACLE 系统自动地为
这些操作设置游标并创建其工作区,这些由系统隐含创建的游标
称为隐式游标,隐式游标的名字为SQL,这是由ORACLE 系统定义
的。对于隐式游标的操作,如定义、打开、取值及关闭操作,都
由ORACLE 系统自动地完成,无需用户进行处理。用户只能通过隐
式游标的相关属性,来完成相应的操作。在隐式游标的工作区中
,所存放的数据是与用户自定义的显示游标无关的、最新处理的
一条SQL 语句所包含的数据。
格式调用为: SQL%
注:INSERT,UPDATE, DELETE, SELECT(单查询) 语句中不必明
确定义游标。
隐式游标属性
属性
值
SELECT
INSERT
UPDATE
DELETE
SQL%ISOPEN
FALSE
FALSE
FALSE
FALSE
SQL%FOUND
TRUE
有结果
成功
成功
SQL%FOUND
FALSE
没结果
失败
失败
SQL%NOTFUOND
TRUE
没结果
失败
失败
SQL%NOTFOUND
FALSE
有结果
成功
失败
SQL%ROWCOUNT
返回行数,只为1
插入的行数
修改的行数
删除的行数
例8: 通过隐式游标SQL的%ROWCOUNT属性来了解修改了多少行。
DECLARE
v_rows NUMBER;
BEGIN
--更新数据
UPDATE employees SET salary = 30000
WHERE department_id = 90 AND job_id = 'AD_VP';
--获取默认游标的属性值
v_rows := SQL%ROWCOUNT;
DBMS_OUTPUT.PUT_LINE(
DBMS_OUTPUT.PUT_LINE('更新了'||v_rows||'个雇员的工
资');
--回退更新,以便使数据库的数据保持原样
ROLLBACK;
END;
4.1.3 使用游标更新和删除数据
游标修改和删除操作是指在游标定位下,修改或删除表中指定的
数据行。这时,要求游标查询语句中必须使用FOR UPDATE选项,
以便在打开游标时锁定游标结果集合在表中对应数据行的所有列
和部分列。
为了对正在处理(查询)的行不被另外的用户改动,ORACLE 提供一
个 FOR UPDATE 子句来对所选择的行进行锁住。该需求迫使
ORACLE锁定游标结果集合的行,可以防止其他事务处理更新或删
除相同的行,直到您的事务处理提交或回退为止。
语法:
SELECT column_list FROM table_list FOR UPDATE [OF column
[, column]…] [NOWAIT]
如果使用 FORUPDATE 声明游标,则可在DELETE和UPDATE 语句中
使用
WHERE CURRENT OF cursor_name子句,修改或删除游标结果集合
当前行对应的数据库表中的数据行。
例9:从EMPLOYEES表中查询某部门的员工情况,将其工资最低定
为 1500;
DECLARE
V_deptno employees.department_id
V_deptno employees.department_id%TYPE :=&p_deptno;
CURSOR emp_cursor
IS
SELECT employees.employee_id, employees.salary FROM
employees WHERE employees.department_id=v_deptno FOR
UPDATE NOWAIT;
BEGIN
FOR emp_record IN emp_cursor LOOP
IF emp_record.salary < 1500 THEN
UPDATE employees SET salary=1500WHERE CURRENT OF
emp_cursor;
END IF;
END LOOP;
COMMIT;
END;
4.2 游标变量
与游标一样,游标变量也是一个指向多行查询结果集合中当前数
据行的指针。但与游标不同的是,游标变量是动态的,而游标是
静态的。游标只能与指定的查询相连,即固定指向一个查询的内
存处理区域,而游标变量则可与不同的查询语句相连,它可以指
向不同查询语句的内存处理区域(但不能同时指向多个内存处理
区域,在某一时刻只能与一个查询语句相连),只要这些查询语
句的返回类型兼容即可。
4.2.1 声明游标变量
游标变量为一个指针,它属于参照类型,所以在声明游标变量类
型之前必须先定义游标变量类型。在PL/SQL中,可以在块、子程
序和包的声明区域内定义游标变量类型。
语法格式为:
1.定义游标变量
TYPE cursortype IS REF CURSOR;
cursor_variable cursortype;
2.打开游标变量
OPEN cursor_variable FOR dynamic_string
[USING bind_argument[,bind_argument]...]
3.循环提取数据
FETCH cursor_variable INTO {var1[,var2]...|
record_variable};
EXIT WHEN cursor_variable%NOTFOUND
4.关闭游标变量
CLOSE cursor_variable;
例10:使用游标变量(没有RETURN子句)
DECLARE
--定义一个游标数据类型
TYPE emp_cursor_type IS REF CURSOR;
--声明一个游标变量
c1 EMP_CURSOR_TYPE;
--声明两个记录变量
v_emp_record employees%ROWTYPE;
v_reg_record regions%ROWTYPE;
BEGIN
OPEN c1 FOR SELECT * FROM employees WHERE
department_id = 20;
LOOP
FETCH c1 INTO v_emp_record;
EXIT WHEN c1%NOTFOUND;
DBMS_OUTPUT.PUT_LINE(v_emp_record.first_name||'的雇
佣日期是'||v_emp_record.hire_date);
END LOOP;
--将同一个游标变量对应到另一个SELECT语句
OPEN c1 FOR SELECT * FROM regions WHERE region_id IN(
1,2);
LOOP
FETCH c1 INTO v_reg_record;
EXIT WHEN c1%NOTFOUND;
DBMS_OUTPUT.PUT_LINE(v_reg_record.region_id||'表
示'||v_reg_record.region_name);
END LOOP;
CLOSE c1;
END;
例11:使用游标变量(有RETURN子句)
DECLARE
--定义一个与employees表中的这几个列相同的记录数据类型
TYPE emp_record_type IS RECORD(
f_name employees.first_name
f_name employees.first_name%TYPE,
h_date employees.hire_date
h_date employees.hire_date%TYPE,
j_id employees.job_id
j_id employees.job_id%TYPE);
--声明一个该记录数据类型的记录变量
v_emp_record EMP_RECORD_TYPE;
--定义一个游标数据类型
TYPE emp_cursor_type IS REF CURSOR
RETURN EMP_RECORD_TYPE;
--声明一个游标变量
c1 EMP_CURSOR_TYPE;
BEGIN
OPEN c1 FOR SELECT first_name, hire_date, job_id FROM
employees WHERE department_id = 20;
LOOP
FETCH c1 INTO v_emp_record;
EXIT WHEN c1%NOTFOUND;
DBMS_OUTPUT.PUT_LINE('雇员名称:'||
v_emp_record.f_name||' 雇佣日期:'||
v_emp_record.h_date||' 岗位:'||v_emp_record.j_id);
END LOOP;
CLOSE c1;
END;
第十一章 视图
视图:是一个封装了各种复杂查询的语句,就称为视图。不存储
数据,只存储定义,定义被保存在数据字典中
作用:1、可以保证安全,隐藏一些数据,保证数据不会被误删;
2、多表连接,可以使复杂的查询易于理解和使用
15.1、创建视图
需要权限才能创建
grant create view to scott;
CREATE OR REPLACE VIEW 视图名字(字段) AS 子查
CREATE OR REPLACE VIEW v_表名_业务 AS 查询语句
建立一个只包含 20 部门雇员信息的视图(雇员的编号、姓名、
工资)
CREATE VIEW empv20 (empno,ename,sal) AS SELECT
empno,ename,sal FROM emp WHERE deptno=20 ;
现在直接更新视图里的数据 将 7369 的部门编号修改为 30。此
操作在视图中完成。
update empv20 SET deptno=30 where empno=7369 ; 此时,
提示更新完成。
默认情况下创建的视图,如果更新了,则会自动将此数据从视图
中删除,之后会更新原本的数据。
在建立视图的时候有两个参数:
· WITH CHECK OPTION à 保护视图的创建规则
CREATE OR REPLACE VIEW empv20
AS SELECT empno,ename,sal,deptno FROM emp WHERE deptno=20
WITH CHECK OPTION CONSTRAINT empv20_ck;----约束条件
ALTER TABLE emp1 add CONSTRAINT empv20_ck check(约束条
件);
再执行更新操作:
update empv20 SET deptno=30 where empno=7369 ; à 此处更
新的是部门编号,失败
|- 之前是按照部门编号建立的视图,所以不能修改部门编号
update empv20 SET ename='tom' where empno=7369 ; à 可以
更新,更新的是名字,成功
· WITH READ ONLY(只读,不可修改),视图最好不要轻易的
修改
CREATE OR REPLACE VIEW empv20
AS SELECT empno,ename,sal,deptno FROM emp WHERE deptno=20
WITH READ ONLY;
现在任意的字段都不可更改,所以现在的视图是只读的。
如果视图的基表有多行查询(比如:group by,distinct)那么该
视图也是只读的
15.1、查看视图
SELECT * FROM v_emp;
update v_emp SET deptno=20 where empno=7369;
DELETE FROM v_emp WHERE empno=7369;
ROLLBACK;
DROP VIEW v_emp;
在视图终不能被修改删除,1、多表构成的视图;2、group by
资料:
http://database.51cto.com/art/200904/118306.htm
http://blog.csdn.net/fan_xiao_ming/article/details/617406
5
第十六章 索引
工作原理:rowid
用执行计划检测索引是否起作用(set autot on exp)
执行计划 cbo(选择)和cro(规则)
16.1、索引
索引是一种用于提升查询效率的数据库对象,通过快速定位数据
的方法,索引信息与表独立存放,Oracle数据库自动使用和维护
索引
索引的存储
索引和表都是独立存在的。在为索引指定表空间的时候,
不要将被索引的表和索引指向同一个表空间,这样可以避免产生
IO 冲突。使 Oracle 能够并行访问存放在不同硬盘中的索引数据
和表数据,更好的提高查询速度。
16.2、索引优缺点
建立索引的优点
1.加快数据的检索速度;
2.创建唯一性索引,保证数据库表中每一行数据的唯一性;
3.加速表和表之间的连接;
4.在使用分组和排序子句进行数据检索时,可以显著减少查询
中分组和排序的时间。
索引的缺点
1.索引需要占物理空间。
2.当对表中的数据进行增加、删除和修改的时候,索引也要动
态的维护,降低了数据的维护速度。
16.3、创建索引
创建索引的方式
1、自动创建:在定义主键或唯一键约束时系统会自动在相应的字
段上创建唯一性索引
2、手动创建:用户可以在其他列上创建非唯一索引,以加速查询
。
创建索引:创建索引一般有以下两个目的:维护被索引列的唯一
性和提供快速访问表中数据的策略。
--在 select 操作占大部分的表上创建索引;
--在 where 子句中出现最频繁的列上创建索引;
--在选择性高的列上创建索引(补充索引选择性,最高是 1,eg
:primary key)
--复合索引的主列应该是最有选择性的和 where 限定条件最常用
的列,并以此类推第二列……。
--小于 5M 的表,最好不要使用索引来查询,表越小,越适合用
全表扫描。
Create [UNIQUE|BITMAP] index
[schema.]index_name on [schema.]table_name(column_name
[ASC|DESC],…n,[column_expression])|CLUSTER [schema.]
cluster_name
[INITRANS integer]
[MAXTRANS integer]
[PCTFREE integer]
[PCTUESD integer]
[TABLESPACE tablespace_name]
[STORAGE storage_clause]
[NOSORT]
[REVERSE]
UNIQUE 指定索引所基于的列(或多列)值必须唯一。默认的索引
是非唯一的。
BITMAP 指定建立位映射索引而不是B*索引。位映射索引保存的行
标识符与作为位映射的键值有关。位映射中的每一位都对应于一
个可能的行标识符,位设置意味着具有对应行标识符的行包含该
键值。
ON table_name 建立基于函数的索引。用table_name的列、常数
、SQL函数和自定义函数创建的表达式。指定column_expression
,以后用基于函数的索引查询时,必须保证查询该
column_expression不为空。
CLUSTER 创建cluster_name簇索引。若表不用schema限制,
oracle假设簇包含在你自己的方案中。不能为散列簇创建簇索引
。
NOSORT 数据库中的行以升序保存,在创建索引时不必对行排序。
若索引列或多列的行不以升序保存,oracle会返回错误。
REVERSE 指定以反序索引块的字节,不包含行标识符。NOSORT不
能与REVERSE一起指定。
CREATE INDEX idx_表名_列名 on 表名(列1,列2...)
create index abc on student(sid,sname);
create index abc1 on student(sname,sid);
这两种索引方式是不一样的
索引 abc 对 Select * from student where sid=1;这样的查询
语句更有效索引 abc1 对 Select * from student where
sname=?louis?; 这样的查询语句更有效
因此建立索引的时候,字段的组合顺序是非常重要的。一般情况
下,需要经常访问的字段放在组合字段的前面
16.4、使用索引的原则
--查询结果是所有数据行的 5%以下时,使用 index 查询效果最
好;
--where 条件中经常用到表的多列时,使用复合索引效果会好于
几个单列索引。因为当 sql语句所查询的列,全部都出现在复合
索引中时,此时由于Oracle 只需要查询索引块即可获得所有数
据,当然比使用多个单列索引要快得多;
--索引利于 select,但对经常 insert,delte 尤其 update 的
表,会降低效率。
eg:试比较下面两条 SQL 语句(emp 表的 deptno 列上建有
ununique index):
语句 A:SELECT dname, deptno FROM deptWHERE deptno NOT
IN (SELECT deptno FROM emp);
语句 B:SELECT dname, deptno FROM dept WHERENOT EXISTS
(SELECT deptno FROM emp WHERE dept.deptno = emp.deptno);
这两条查询语句实现的结果是相同的,但是执行语句 A 的时候,
ORACLE 会对整个 emp 表进行扫描,没有使用建立在 emp 表上的
deptno 索引,执行语句 B 的时候,由于在子查询中使用了联合
查询,ORACLE 只是对 emp 表进行的部分数据扫描,并利用了
deptno 列的索引,所以语句 B 的效率要比语句 A 的效率高。
----where 子句中的这个字段,必须是复合索引的第一个字段;
eg:一个索引是按 f1,f2, f3 的次序建立的,若 where子句是
f2 = : var2, 则因为 f2 不是索引的第 1 个字段,无法使用该
索引。
---- where 子句中的这个字段,不应该参与任何形式的计算:任
何对列的操作都将导致表扫描,它包括数据库函数、计算表达式
等等,查询时要尽可能将操作移至等号右边。 ----应尽量熟悉各
种操作符对 Oracle 是否使用索引的影响:以下这些操作会显式
(explicitly)地阻止 Oracle 使用索引: is null ; is not
null ; not in; !=; like ; numeric_col+0;date_col+0;
char_col||' '; to_char; to_number,to_date 等。
Eg:
Select jobid from mytabs where isReq='0' and to_date
(updatedate) >= to_Date ( '2001-7-18',
'YYYY-MM-DD');--updatedate 列的索引也不会生效。
在正确使用索引的前提下,索引可以提高检索相应的表的速度。
当用户考虑在表中使用索引时,应遵循下列一些基本原则。
(1)在表中插入数据后创建索引。在表中插入数据后,创建索引
效率将更高。如果在装载数据之前创建索引,那么插入每行时
oracle都必须更改索引。
(2)索引正确的表和列。如果经常检索包含大量数据的表中小于
15%的行,就需要创建索引。为了改善多个表的相互关系,常常使
用索引列进行关系连接。
(3)主键和唯一关键字所在的列自动具有索引,但应该在与之关
联的表中的外部关键字所在的列上创建索引。
(4)合理安排索引列。在create index 语句中,列的排序会影
响查询的性能,通常将最常用的列放在前面。创建一个索引来提
高多列的查询效率时,应该清楚地了解这个多列的索引对什么列
的存取有效,对什么列的存取无效。
(5)限制表中索引的数量。尽管表可以有任意数量的索引,可是
索引越多,在修改表中的数据时对索引做出相应更改的工作量也
越大,效率也就越低。同样,目前不用的索引应该及时删除。
(6)指定索引数据块空间的使用。创建索引时,索引的数据块是
用表中现存的值填充的,直到达到PCTFREE为止。如果打算将许多
行插入到被索引的表中,PCTFREE就应设置得大一点,不能给索引
指定PCTUSED。
(7)根据索引大小设置存储参数。创建索引之前应先估计索引的
大小,以便更好地促进规划和管理磁盘空间。单个索引项的最大
值大约是数据块大小的一半。
16.6、删除索引
drop index PK_DEPT1;
16.7、索引类型
B树索引 B-treeindexes;
B树索引又可分为以下子类:
索引组织表Index-organizedtables;
反转索引Reversekey indexes;
降序索引Descendingindexes;
B树聚簇索引B-treecluster indexes;
位图和位图联合索引Bitmapand bitmap join indexes;
基于函数的索引Function-basedindexes;
应用域索引Applicationdomain indexes;
B-Tree是一个平衡树的结构【注意这里的B表示Balanced平衡的意
思,而不是Binary二叉】,B树索引也是Oracle里最为常见的索引
类型。B树索引里的数据是已经按照关键字或者是被索引字段事先
排好序存放的,默认是升序存放。
对于这幅B树存储结构图作以下几点介绍:
1 、索引高度是指从根块到达叶子块时所遍历的数据块的个数,
而索引层次=索引高度-1;本图中的索引的高度是3,索引层次等
于2;通常,索引的高度是2或者3,即使表中有上百万条记录,也
就意味着,从索引中定位一个键字只需要2或3次I/O,索引越高,
性能越差;
2、 B树索引包含两种数据块儿:分枝块(Branch Block)和叶子块
(Leaf Block);
3 、分枝块里存放指向下级分枝块(索引高度大于2,即有超过两
层分枝块的情况)或者直接指向叶子块的指针(索引高度等于2,即
层次为1的索引);
4 、叶子块,就是位于B树结构里最底层的数据块。叶子块里存放
的是索引条目,即索引关键字和rowid,rowid用来精确定位表里
的记录;索引条目都是按照索引关键字+rowid已经排好序存放的
;同一个叶子块里的索引条目同时又和左右兄弟条目形成链表,
并且是一个双向链表;
5 、B树索引的所有叶子块一定位于同一层上,这是由B树的数据
结构定义的。因此,从根块到达任何一个叶子块的遍历代价都是
相同的;
B 树索引(B-TreeIndex)
创建索引的默认类型,结构是一颗树,采用的是平衡 B 树算法:
l 右子树节点的键值大于等于父节点的键值 l 左子树节点的键值
小于等于父节点的键值
位图索引(BitMapIndex)
如果表中的某些字段取值范围比较小,比如职员性别、分数列
ABC 级等。只有两个值。
这样的字段如果建 B 树索引没有意义,不能提高检索速度。这时
我们推荐用位图索引
Create BitMap Index student on(sex);
索引按功能和索引对象分还有以下类型。
(1)唯一索引意味着不会有两行记录相同的索引键值。唯一
索引表中的记录没有RowID,不能再对其建立其他索引。在
oracle10g中,要建立唯一索引,必须在表中设置主关键字,建立
了唯一索引的表只按照该唯一索引结构排序。
(2)非唯一索引不对索引列的值进行唯一性限制。
(3)分区索引是指索引可以分散地存在于多个不同的表空间
中,其优点是可以提高数据查询的效率。
(4)未排序索引也称为正向索引。Oracle10g数据库中的行
是按升序排序的,创建索引时不必指定对其排序而使用默认的顺
序。
(5)逆序索引也称反向索引。该索引同样保持列按顺序排列
,但是颠倒已索引的每列的字节。
按照索引所包含的列数可以把索引分为单列索引和复合索引
。索引列只有一列的索引为单列索引,对多列同时索引称为复合
索引。
16.8、管理索引
1)先插入数据后创建索引
向表中插入大量数据之前最好不要先创建索引,因为如果先建立
索引。那么在插入每行数据的时候都要更改索引。这样会大大降
低插入数据的速度。
2)设置合理的索引列顺序
3)限制每个表索引的数量
4)删除不必要的索引
5)为每个索引指定表空间
6)经常做 insert,delete 尤其是 update 的表最好定期
exp/imp 表数据,整理数据,降低碎片(缺点:要停应用,以保
持数据一致性,不实用);
有索引的最好定期 rebuild 索引(rebuild期间只允许表的
select 操作,可在数据库较空闲时间提交),以降低索引碎片,
提高效率
16.8、索引问题
1.一个表的查询语句可以同时用到两个索引。
2.索引是以独立于表存在的一种数据库对象,它是对基表的一种
排序(默认是 B 树索引就是二叉树的排序方式),比如:
3.这样的查询效率,肯定是大于没有索引情况的全表扫描(table
access full),但是有两个问题。
问题一:建立索引将占用额外的数据库空间,更重要的是增
删改操作的时候,索引的排序也必须改变,加大的维护的成本 问
题二:如果经常查询 x=?和 y=?,那推荐使用组合 index(x,y),
这种情况下组合索引的效率是远高于两个单独的索引的。
同时在用组合索引的时候,大家一定要注意一个细节:建立组合
索引index(x,y,z)的时候,那在查询条件中出现x,xy,xyz,yzx
都是可以用到该组合索引,但是y,yz,z 是不能用到该索引的。
第十三章 序列、同义词
13.1、 创建序列(sequence)
CREATE SEQUENCE seq
INCREMENT BY 2--增量
START WITH 2--起始值 不能小于min
MAXVALUE 10--最大值
MINVALUE 1--最小值
CYCLE--/NOCYCLE 序列号是否可循环(到了maxvalue在从min开
始)
CACHE 5--/NOCACHE 缓存下一个值,必须满足大于1,小于等于
(MAXVALUE-MINVALUE)/INCREMENT
NOORDER--/NOORDER 序列号是否顺序产生
13.2、 属性 NextVal,CurrVal
--当前值-----currval
SELECT seq.currval FROM dual;
--下一个值------nextval
SELECT seq.nextval FROM dual;
(必须先有 nextval,才能有 currval)
--在向表中插入数据时使用
INSERT INTO emp1(empno) VALUES(seq.nextval);
使用 cache 或许会跳号, 比如数据库突然不正常 down 掉
(shutdownabort),cache中的sequence就会丢失. 所以可以在
create sequence的时候用nocache防止这种情况
13.3、 修改
不能改变当前值,但是可以改变增量
ALTER SEQUENCE seq INCREMENT BY 3;
ALTER SEQUENCE seq CACHE 3;
13.4、 删除
DROP SEQUENCE seq;
13.5、 同义词 (synonym)
Select * from dual;
为什么?因为同义词的存在
Dual 其实是 sys 用户下的一张表
select table_name from user_tables where lower
(table_name) = 'dual';
1、概念
同义词是数据库方案对象的一个别名,经常用于简化对象访问和
提高对象访问的安全性。在使用同义词时,Oracle数据库将它翻
译成对应方案对象的名字。与视图类似,同义词并不占用实际存
储空间,只有在数据字典中保存了同义词的定义。在Oracle数据
库中的大部分数据库对象,如表、视图、同义词、序列、存储过
程、包等等,数据库管理员都可以根据实际情况为他们定义同义
词。
同义词,顾名思义就是两个词的意思一样,可以互相替换.
2、作用:
1) 多用户协同开发中,可以屏蔽对象的名字及其持有者。如果没
有同义词,当操作其他用户的表时,必须通过user名.object名的
形式,采用了Oracle同义词之后就可以隐蔽掉user名,当然这里
要注意的是:public同义词只是为数据库对象定义了一个公共的
别名,其他用户能否通过这个别名访问这个数据库对象,还要看
是否已经为这个用户授权。
2) 简化sql语句。上面的一条其实就是一种简化sql的体现,同时
如果自己建的表的名字很长,可以为这个表创建一个Oracle同义
词来简化sql开发。
3)为分布式数据库的远程对象提供位置透明性。
4)Oracle同义词在数据库链接中的作用
数据库链接是一个命名的对象,说明一个数据库到另一个数据库
的路径,通过其可以实现不同数据库之间的通信。
Create database link 数据库链名 connect to user名
identified by 口令 using‘Oracle连接串’;
访问对象要通过 object名@数据库链名。同义词在数据库链中的
作用就是提供位置透明性。
3、分类:
Create synonym dept for soctt.dept;(这样创建的同义词是私
有的,只有创建者才能用)
Drop synonym dept;
Create public synonym dept for soctt.dept;(这样创建的同
义词才是公有的)
Drop public synonym dept;
4、权限管理
与同义词相关的权限有CREATESYNONYM、CREATE ANYSYNONYM、
CREATE PUBLIC SYNONYM权限。
1:用户在自己的模式下创建私有同义词,这个用户必须拥有
CREATE SYNONYM权限,否则不能创建私有同义词。
2:如果需要在其它模式下创建同义词,则必须具有CREATE ANY
SYNONYM的权限。
3:创建公有同义词则需要CREATEPUBLIC SYNONYM系统权限。
5、查看同义词
SQL> SELECT * FROM DBA_SYNONYMS WHERE SYNONYM_NAME IN (
'SYSN_TEST','PUBLIC_TEST');
OWNER SYNONYM_NAME TABLE_OWNER TABLE_NAME DB_LINK
------------------------------
------------------------------
PUBLIC PUBLIC_TEST ETL TEST
ETL SYSN_TEST ETL TEST
SQL> SELECT * FROM USER_SYNONYMS
6、使用同义词
SELECT * FROM SYSN_TEST;
使用同义词可以保证当数据库的位置或对象名称发生改变时,应
用程序的代码保持稳定不变,仅需要改变同义词;
当使用一个没有指定schema的同义词是,首先在用户自己的
schema中寻找,然后再公共同义词中寻找
7、删除同义词
DROP [ PUBLIC ] SYNONYM [ schema. ] 同义词名称 [ FORCE ];
DROP SYNONYM SYSN_TEST;
DROP PUBLIC SYNONYM PUBLIC_TEST;--当同义词的原对象被删除
是,同义词并不会被删除
8、编译同义词
ALTER SYNONYM T COMPILE; --当同义词的原对象被重新建立时,
同义词需要重新编译
对原对象进行DDL操作后,同义词的状态会变成INVALID;当再次
引用这个同义词时,同义词会自动编译,状态会变成VALID,无需
人工干预,当然前提是不改变原对象的名称
问题锦集
1:公用同义词与私有同义词能否同名呢?如果可以,访问同义词
时,是共有同义词还是私有同义词优先?
可以,如果存在公用同义词和私有同义词同名的情况,在访问同
义词是,访问的是私有同义词的指向的对象。
2:为啥OE用户创建的公用同义词,HR用户不能访问呢?
因为HR没有访问OE模式下对象的权限,如果OE模式给HR用户赋予
了SELECT对象等权限,那么HR用户即可访问。
3:对象、私有同义词、公共同义词是否可以存在三者同名的情况
?
存在同名对象和公共同义词时,数据库优先选择对象作为目标,
存在同名私有对象和公共对象时,数据库优先选择私有同义词作
为目标
第十四章 函数
in 只读
out 只写
in out 可读写
函数就是一个有返回值的过程。
定义一个函数:此函数可以根据雇员的编号查询出雇员的年薪
CREATE OR REPLACE FUNCTION myfun(eno emp.empno%TYPE)
RETURN NUMBER
AS
rsal NUMBER ;
BEGIN
SELECT (sal+nvl(comm,0))*12 INTO rsal FROM emp WHERE
empno=eno ;
RETURN rsal ;
END ;
/
直接写 SQL 语句,调用此函数:
SELECT myfun(7369) FROM dual ;
第十五章 触发器
15.1分类:
DML触发器-----------基于表的(insert、alter、update)
替代触发器-----------基于VIEW的
系统触发器-----------基于系统的
好处:自动调用、记录日志、保证数据安全、用数据库触发器可
以保证数据的一致性和完整性。
语法:
CREATE [OR REPLACE] TRIGGER trigger_name
{BEFORE | AFTER }
{INSERT | DELETE | UPDATE [OF column [, column …]]}
[OR {INSERT | DELETE | UPDATE [OF column [, column
…]]}...]
ON [schema.]table_name | [schema.]view_name
[REFERENCING {OLD [AS] old | NEW [AS] new| PARENT as
parent}]
[FOR EACH ROW ]
[WHEN condition]
PL/SQL_BLOCK | CALL procedure_name;
BEFORE 和AFTER指出触发器的触发时序分别为前触发和后
触发方式,前触发是在执行触发事件之前触发当前所创建的触发
器,后触发是在执行触发事件之后触发当前所创建的触发器。
FOR EACH ROW选项说明触发器为行触发器。行触发器和语
句触发器的区别表现在:行触发器要求当一个DML语句操走影响数
据库中的多行数据时,对于其中的每个数据行,只要它们符合触
发约束条件,均激活一次触发器;而语句触发器将整个语句操作
作为触发事件,当它符合约束条件时,激活一次触发器。当省略
FOR EACH ROW 选项时,BEFORE 和AFTER 触发器为语句触发器,
而INSTEAD OF 触发器则只能为行触发器。
REFERENCING 子句说明相关名称,在行触发器的PL/SQL块
和WHEN 子句中可以使用相关名称参照当前的新、旧列值,默认的
相关名称分别为OLD和NEW。触发器的PL/SQL块中应用相关名称时
,必须在它们之前加冒号(:),但在WHEN子句中则不能加冒号。
WHEN 子句说明触发约束条件。Condition 为一个逻辑表达
时,其中必须包含相关名称,而不能包含查询语句,也不能调用
PL/SQL 函数。WHEN 子句指定的触发约束条件只能用在BEFORE 和
AFTER行触发器中,不能用在INSTEADOF 行触发器和其它类型的
触发器中。
15.2、 触发器触发次序
1. 执行 BEFORE语句级触发器;
2. 对与受语句影响的每一行:
l 执行 BEFORE行级触发器
l 执行 DML语句
l 执行 AFTER行级触发器
3. 执行 AFTER语句级触发器
15.3、语句触发器
after 语句触发器
Before 语句触发器
例如:禁止工作人员在休息日改变雇员信息
create or replace trigger tr_src_emp
before insert or update or delete
on emp
begin
if to_char(sysdate,'DY','nls_date_language=AMERICAN') in(
'SAT','SUN') then
raise_application_error(-20001,'can?t modify user
information in weekend');
end if;
end;
/
使用条件谓语---------inserting、updating、deleting
create or replace trigger tr_src_emp
before insert or update or delete
on emp
begin
if to_char(sysdate,'DY') in( '星期六','星期天') then
case
when inserting then
raise_application_error(-20001,'fail to insert');
when updating then
raise_application_error(-20001,'fail to update');
when deleting then
raise_application_error(-20001,'fail to delete');
end case;
end if;
end;
/
15.4、行触发器
执行 DML 操作时,每作用一行就触发一次触发器。
Bofre 行触发器
例如:确保员工工资不能低于原有工资
Create or replace trigger tr_emp_sal
before update of sal
on emp
for each row
begin
if :new.sal<:old.sal then
raise_application_error(-20010,'sal should not be
less');
end if;
end;
/
after 行触发器
例如:统计员工工资变化
Create table audit_emp_change(
Name varchar2(10),
Oldsal number(6,2),
Newsal number(6,2),
Time date);
Create or replace trigger tr_sal_sal after update of sal
on emp for each row declare v_temp int;
begin
select count(*) into v_temp from audit_emp_change where
name=:old.ename; if v_temp=0 then
insert into audit_emp_change values
(:old.ename,:old.sal,:new.sal,sysdate); else
update audit_emp_change set
oldsal=:old.sal,newsal=:new.sal,time=sysdate where
name=:old.ename;
end if; end;
/
限制行触发器
Create or replace trigger tr_sal_sal
after update of sal
on emp
for each row when (old.job=?SALESMAN?)
declare
v_temp int;
begin
select count(*) into v_temp from audit_emp_change where
name=:old.ename;
if v_temp=0 then
insert into audit_emp_change values
(:old.ename,:old.sal,:new.sal,sysdate);
else
update audit_emp_change set
oldsal=:old.sal,newsal=:new.sal,time=sysdate where
name=:old.ename;
end if;
end;
/
注意:
例如:如果要基于 EMP 表建立触发器。那么该触发器的执行代码
不能包含对 EMP 表的查询操作编写 DML 触发器的时,触发器代
码不能从触发器所对应的基表中读取数据。
Create or replace trigger tr_emp_sal
Before update of sal
on emp
For each row
declare
Maxsal number(6,2);
Begin
If :new.sal>maxsal then Select max(sal) into maxsal from
emp;
Raise_application_error(-21000,?error?);
End if;
End;
/
创建的时候不会报错。但是一旦执行就报错了
update emp set sal=sal*1.1 where deptno=30
DML触发器的限制
l CREATE TRIGGER语句文本的字符长度不能超过32KB;
l 触发器体内的SELECT 语句只能为SELECT … INTO …结构,或
者为定义游标所使用的SELECT语句。
l 触发器中不能使用数据库事务控制语句 COMMIT; ROLLBACK,
SVAEPOINT 语句;
l 由触发器所调用的过程或函数也不能使用数据库事务控制语句
;
l 触发器中不能使用LONG,LONG RAW 类型;
l 触发器内可以参照LOB 类型列的列值,但不能通过 :NEW 修改
LOB列中的数据;
:NEW 修饰符访问操作完成后列的值
:OLD 修饰符访问操作完成前列的值
特性
INSERT
UPDATE
DELETE
OLD
NULL
实际值
实际值
NEW
实际值
实际值
NULL
15.4 替代触发器
语法:
CREATE [OR REPLACE] TRIGGER trigger_name
INSTEAD OF
{INSERT | DELETE | UPDATE [OF column [, column …]]}
[OR {INSERT | DELETE | UPDATE [OF column [, column
…]]}...]
ON [schema.] view_name --只能定义在视图上
[REFERENCING {OLD [AS] old | NEW [AS] new| PARENT as
parent}]
[FOR EACH ROW ] --因为INSTEAD OF触发器只能在行级上触发,所
以没有必要指定
[WHEN condition]
PL/SQL_block | CALL procedure_name;
例2:创建复杂视图,针对INSERT操作创建INSTEAD OF触发器,向
复杂视图插入数据。
l 创建视图:
CREATE OR REPLACE FORCE VIEW "HR"."V_REG_COU"("R_ID",
"R_NAME", "C_ID", "C_NAME")
AS
SELECT r.region_id,
r.region_name,
c.country_id,
c.country_name
FROM regions r,
countries c
WHERE r.region_id = c.region_id;
l 创建触发器:
CREATE OR REPLACE TRIGGER "HR"."TR_I_O_REG_COU"
INSTEAD OF INSERT
ON v_reg_cou
FOR EACH ROW
DECLARE
v_count NUMBER;
BEGIN
SELECT COUNT(*) INTO v_count FROM regions WHERE
region_id = :new.r_id;
IF v_count = 0 THEN
INSERT INTO regions
(region_id, region_name
) VALUES
(:new.r_id, :new.r_name
);
END IF;
SELECT COUNT(*) INTO v_count FROM countries WHERE
country_id = :new.c_id;
IF v_count = 0 THEN
INSERT
INTO countries
(
country_id,
country_name,
region_id
)
VALUES
(
:new.c_id,
:new.c_name,
:new.r_id
);
END IF;
END;
创建INSTEAD OF触发器需要注意以下几点:
l 只能被创建在视图上,并且该视图没有指定WITH CHECK OPTION
选项。
l 不能指定BEFORE 或 AFTER选项。
l FOR EACH ROW子可是可选的,即INSTEADOF触发器只能在行级
上触发、或只能是行级触发器,没有必要指定。
l 没有必要在针对一个表的视图上创建INSTEAD OF触发器,只要
创建DML触发器就可以了。
15.5、系统事件触发器
语法:
CREATE OR REPLACE TRIGGER [sachema.]trigger_name
{BEFORE
{BEFORE|AFTER}
{ddl_event_list
{ddl_event_list | database_event_list}
ON { DATABASE | [schema.]SCHEMA }
[WHEN condition]
PL/SQL_block | CALL procedure_name;
其中:ddl_event_list:一个或多个DDL 事件,事件间用 OR 分
开;
database_event_list:一个或多个数据库事件,事件
间用 OR 分开;
下面给出系统触发器的种类和事件出现的时机(前或后):
事件
允许的时机
说明
STARTUP
AFTER
启动数据库实例之后触发
SHUTDOWN
BEFORE
关闭数据库实例之前触发(非正常关闭不触发)
SERVERERROR
AFTER
数据库服务器发生错误之后触发
LOGON
AFTER
成功登录连接到数据库后触发
LOGOFF
BEFORE
开始断开数据库连接之前触发
CREATE
BEFORE,AFTER
在执行CREATE语句创建数据库对象之前、之后触发
DROP
BEFORE,AFTER
在执行DROP语句删除数据库对象之前、之后触发
ALTER
BEFORE,AFTER
在执行ALTER语句更新数据库对象之前、之后触发
DDL
BEFORE,AFTER
在执行大多数DDL语句之前、之后触发
GRANT
BEFORE,AFTER
执行GRANT语句授予权限之前、之后触发
REVOKE
BEFORE,AFTER
执行REVOKE语句收权限之前、之后触犯发
RENAME
BEFORE,AFTER
执行RENAME语句更改数据库对象名称之前、之后触犯发
AUDIT / NOAUDIT
BEFORE,AFTER
执行AUDIT或NOAUDIT进行审计或停止审计之前、之后触发
/*create or replace trigger tr_emp1_1
--before update on emp1
after update on emp1
for each row
declare
-- local variables here
begin
if :new.sal<:old.sal then
Raise_application_error(-20000, ':new.sal>:old.sal');
end if;
end tr;*/
/*create or replace trigger tr_emp1_2
after delete on emp1
--before delete on emp1
for each row
begin
Raise_application_error(-20001, '不能删');
end;*/
create or replace trigger tr_emp1_3
after delete or update or insert on emp1
for each ROW
begin
if deleting then
if :new.sal>0 then
Raise_application_error(-20000,'deleting');
end IF;
/*elsif updating then
if :new.sal<:old.sal then
Raise_application_error(-20001,'updating');
end if;
else
if :new.sal<:old.sal then
Raise_application_error(-20002,'inserting');
end if;*/
end if;
end;
资料:
http://www.cnblogs.com/huyong/archive/2011/04/27/2030466.
html
第十六章 存储过程
16.1、存储过程
CREATE OR REPLACE PROCEDURE procedure_name AS PL/SQL块
现在定义一个简单的过程,就是打印一个数字
CREATE OR REPLACE PROCEDURE myproc AS
i NUMBER ;
BEGIN
i := 100 ;
DBMS_OUTPUT.put_line('i = '||i) ;
END ;
/
执行过程: exec 过程名字---------set serveroutput on
下面编写一个过程,要求,可以传入部门的编号,部门的名称,
部门的位置,之后调用此过程就可以完成部门的增加操作。
CREATE OR REPLACE PROCEDURE myproc(dno dept.deptno%TYPE,
name dept.dname%TYPE,
dl dept.loc%TYPE)
AS
cou NUMBER ;
BEGIN
-- 判断插入的部门编号是否存在,如果存在则不能插入
SELECT COUNT(deptno) INTO cou FROM dept WHERE deptno=dno
;
IF cou=0 THEN
-- 可以增加新的部门
INSERT INTO dept(deptno,dname,loc) VALUES(dno,name,dl) ;
DBMS_OUTPUT.put_line('部门插入成功!') ;
ELSE
DBMS_OUTPUT.put_line('部门已存在,无法插入!') ;
END IF ;
END ;
/
16.2 过程的参数类型:
? IN:值传递,默认的-----只读
? IN OUT:带值进,带值出---可读写
? OUT:不带值进,带值出----只写
IN OUT 类型:
CREATE OR REPLACE PROCEDURE myproc(dno IN OUT
dept.deptno%TYPE,
name dept.dname%TYPE,
dl dept.loc%TYPE) AS
cou NUMBER ;
BEGIN
-- 判断插入的部门编号是否存在,如果存在则不能插入
SELECT COUNT(deptno) INTO cou FROM dept WHERE deptno=dno
;
IF cou=0 THEN
-- 可以增加新的部门
INSERT INTO dept(deptno,dname,loc) VALUES(dno,name,dl)
;
DBMS_OUTPUT.put_line('部门插入成功!') ;
-- 修改 dno 的值
dno := 1 ;
ELSE
DBMS_OUTPUT.put_line('部门已存在,无法插入!') ; dno :=
-1 ;
END IF ;
END ;
/
编写 PL/SQL 块验证过程:
DECLARE
deptno dept.deptno%TYPE ; BEGIN
deptno := 12 ;
myproc(deptno,'开发','南京') ;
DBMS_OUTPUT.put_line(deptno) ;
END ;
/
OUT 类型 不带任何值进,只把值带出来。
CREATE OR REPLACE PROCEDURE myproc(dno OUT dept.deptno
%TYPE)
AS
I number
BEGIN
I:= dno;
END ;
/
执行上面的存储过程
DECLARE
deptno dept.deptno%TYPE ;
BEGIN
deptno :=myproc(deptno) ;
DBMS_OUTPUT.put_line(deptno) ;
END ;
/
第十七章 包
17.1 定义
包------规范和主体
包就是将一系列的相关联的PLSQL类型、项目和子程序等有计划的
组织起来封装在一起
规范(包头)---------一个操作或应用的接口部分
主体----------对包的规范部分进行实现
语法;
包的规范
CREATE OR REPLACE PACKAGE package_name AS|IS
参数、类型(type)、异常(exception)、游标(cursor)、
procedure、function
END[package_name];
包的主体
CREATE OR REPLACE PACKAGE BODY package_name AS|IS
参数、类型(type)、异常(exception)、游标(cursor)、
procedure、function
END[package_name];
调用:
package_name.type_name;
package_name.item_name;
package_name.call_spec_name;
删除:
drop package package_name;
drop package body package_name;
好处:
1、模块化;-----提高应用程序的交互性
2、信息隐藏
例:
CREATE OR REPLACE PACKAGE DEMO_PKG
IS
DEPTREC DEPT%ROWTYPE;
--Add dept...
FUNCTION add_dept(
dept_no NUMBER,
dept_nameVARCHAR2,
location VARCHAR2)
RETURN NUMBER;
--delete dept...
FUNCTION delete_dept(dept_no NUMBER)
RETURN NUMBER;
--query dept...
PROCEDURE query_dept(dept_no IN NUMBER);
END DEMO_PKG;
CREATE OR REPLACE PACKAGE BODY DEMO_PKG
IS
FUNCTION add_dept
(
dept_no NUMBER,
dept_name VARCHAR2,
location VARCHAR2
)
RETURN NUMBER
IS
empno_remaining EXCEPTION; --自定义异常
PRAGMA EXCEPTION_INIT(empno_remaining, -1);
/* -1 是违反唯一约束条件的错误代码 */
BEGIN
INSERT INTO dept VALUES(dept_no, dept_name, location);
IF SQL%FOUND THEN
RETURN 1;
END IF;
EXCEPTION
WHEN empno_remaining THEN
RETURN 0;
WHEN OTHERS THEN
RETURN -1;
END add_dept;
FUNCTION delete_dept(dept_no NUMBER)
RETURN NUMBER
IS
BEGIN
DELETE FROM dept WHERE deptno = dept_no;
IF SQL%FOUND THEN
RETURN 1;
ELSE
RETURN 0;
END IF;
EXCEPTION
WHEN OTHERS THEN
RETURN -1;
END delete_dept;
PROCEDURE query_dept
(dept_no IN NUMBER)
IS
BEGIN
SELECT * INTO DeptRec FROM dept WHERE
deptno=dept_no;
EXCEPTION
WHEN NO_DATA_FOUND THEN
DBMS_OUTPUT.PUT_LINE('温馨提示:数据库中没有编码
为'||dept_no||'的部门');
WHEN TOO_MANY_ROWS THEN
DBMS_OUTPUT.PUT_LINE('程序运行错误,请使用游标进
行操作!');
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE(SQLCODE||'----'||
SQLERRM);
END query_dept;
BEGIN
Null;
END DEMO_PKG;
一、数据库连接
1、JDBC连接
1、加载JDBC驱动程序;
Class.forName
("com.mysql.jdbc.Driver");//oracle.jdbc.OracleDriver
2、创建数据库的连接;
Connection conn =DriverManager.getConnection
(url,user,password);
3、创建一个Statement对象;
Statement stat =conn.createStatement() ;
//PreparedStatement pstat =
conn.prepareStatement(SQL_classification_INSERT);
4、执行SQL语句;
executeQuery 、executeUpdate 和execute
ResultSet rs = stmt.executeQuery("SELECT* FROM
...") ;
//rs=pstat.executeQuery();
5、返回并处理结果;
while(rs.next()){
...
}
6、关闭连接;
rs.close() ;
stat.close();
conn.close();
2、Hibernate连接
name="dialect">org.hibernate.dialect.MySQLDialect
ty>
name="connection.url">jdbc:mysql://localhost:3306/eshop_1
name="connection.username">root
name="connection.password">107510
name="connection.driver_class">com.mysql.jdbc.Driver
perty>
name="myeclipse.connection.profile">eshop_1
Configuration cfg=new Configuration().configure();
SessionFactory sf=cfg.buildSessionFactory
();------------------2级缓存
Session session=sf.openSession
();-------------------------------------1级缓存
Transaction tx=session.beginTransaction();
session.save()//增删改查的动作
tx.commit();
session.close();
sf.close();
3、SSH中数据源连接
class="org.apache.commons.dbcp.BasicDataSource">
value="jdbc:oracle:thin:@127.0.0.1:1521:orcl">
value="oracle.jdbc.OracleDriver"/>
value="scott">
value="tiger">
value="false">
class="org.springframework.orm.hibernate3.annotation.Anno
tationSessionFactoryBean">
key="hibernate.dialect">org.hibernate.dialect.OracleDiale
ct
key="hibernate.format_sql">true
name="annotatedClasses">
/value>
二、Oracle
1、 事务的特性
原子性、隔离性、持久性、一致性
savepoint p
commit
rollback
2、 动态SQL
dml:
ddl:
占位符’:‘
declare
v_no emp1.ename%type:='&请输入号码'; --&变量绑定符
v_name emp1.ename%type;
v_job emp1.job%type;
v_sql long:='select ename,job from emp1 where
ename=:xxx';--占位符
begin
execute immediate v_sql into v_name,v_jobusing
v_no;
dbms_output.put_line('name= '||v_name||'job='||
v_job);
end;
3、游标
1、分类:
显示游标----游标名%属性名
隐式游标----SQL%
2、步骤;
显示游标 语法格式:
CURSOR cursor_name is select * fromemp;--声明游
标
OPEN cursor_name;--打开游标
FETCH cursor_name INTOvariables_list;--提取游标
CLOSE cursor_name;--关闭游标
例1:
DECLARE
v_deptnoNUMBER:=&inputno;
v_row emp1%ROWTYPE;
CURSOR v_cursor ISSELECT * FROM emp1 WHERE
deptno=v_deptno;--声明游标
BEGIN
OPEN v_cursor; --打开
--提取
LOOP
FETCHv_cursor INTO v_row;--先提取
EXIT WHENv_cursor%NOTFOUND;
dbms_output.put_line('Employee Name: ' ||
v_row.ename || ' ,Salary: ' || v_row.sal);
END LOOP;
--关闭
CLOSE v_cursor;
END;
--隐式游标
自动打开游标
自动关闭游标
通过隐式游标SQL的%ROWCOUNT属性来了解修改了多少行
。
DECLARE
v_rows NUMBER;
BEGIN
--更新数据
UPDATE employeesSET salary = 30000
WHEREdepartment_id = 90 AND job_id = 'AD_VP';
--获取默认游标的属性值
v_rows :=SQL%ROWCOUNT;
DBMS_OUTPUT.PUT_LINE('更新了'||v_rows||'个雇员
的工资');
--回退更新,以便使数据库的数据保持原样
ROLLBACK;
END;
3、应用中---for游标----无需声明、打开、提取、关闭
BEGIN
--隐含打开游标
FOR r IN (SELECT * FROM emp1 WHERE
deptno=v_deptno) LOOP
--隐含执行一个FETCH语句
dbms_output.put_line('Employee Name: ' ||
r.ename || ' ,Salary: ' || r.sal);
--隐含监测c_sal%NOTFOUND
END LOOP;
--隐含关闭游标
END;
4、视图
1、假表【不存储数据,只存储定义,定义被保
存数据字典】
2、作用:数据安全:(隐藏行或者列,保证数据不会
被误删除)
简化查询
3、定义格式:
CREATE OR REPLACEVIEW v_表名_业务
as
查询语句
5、索引
1、原理:先在索引中根据关键字找到记录的rowid,然
后利用rowid在基表中直接定位记录并检索出来,所以速度快
2、特征:1、索引自动维护
2、索引需要占据实际存储空间
3、对于表中的主键列,将自动建立唯
一索引
3、语法:
create index索引名
on
表名(列1,列2,...)
drop index 索引名
4、作用:提高查询速度,通常情况下,索引应该建立在
那些经常出现在where子句中的列上
6、序列
1、步骤
CREATE SEQUENCE seq
INCREMENT BY 2--增量
START WITH 2--起始值 不能小于min
MAXVALUE 10--最大值
MINVALUE 1--最小值
CYCLE--/NOCYCLE 序列号是否可循环(到了maxvalue
在从min开始)
CACHE 5--/NOCACHE 缓存下一个值,必须满足大于1,
小于等于(MAXVALUE-MINVALUE)/INCREMENT
NOORDER--/NOORDER 序列号是否顺序产生
2、 属性 NextVal,CurrVal
3、作用
序列通常和触发器一起使用,来自动生成主键
7、函数
1、定义:函数就是一个有返回值的过程。
2、步骤:此函数可以根据雇员的编号查询出雇员的年薪
CREATE OR REPLACE FUNCTION myfun(enoemp.empno
%TYPE)
RETURN NUMBER
AS
rsalNUMBER ;
BEGIN
SELECT(sal+nvl(comm,0))*12 INTO rsal FROM
emp WHERE empno=eno ;
RETURN rsal;
END ;
/
3、直接写 SQL 语句,调用此函数:
SELECT myfun(7369) FROM dual ;
v_dfd := EXEC myfun(7369);
8、触发器
1、分类;
DML触发器-----------基于表的(insert、alter、
update)
替代触发器-----------基于VIEW的---行级
系统触发器-----------基于系统的
2、创建步骤;
CREATE [ORREPLACE] TRIGGER trigger_name
{BEFORE | AFTER }
{INSERT | DELETE | UPDATE [OF column[, column …
]]}
[OR {INSERT | DELETE | UPDATE [OFcolumn [,
column …]]}...]
ON [schema.]table_name |[schema.]view_name
[REFERENCING {OLD [AS] old | NEW[AS] new| PARENT
as parent}]
[FOR EACH ROW ]
[WHEN condition]
PL/SQL_BLOCK | CALL procedure_name;
3、作用
自动调用、记录日志、保证数据安全、用数据库触
发器可以保证数据的一致性和完整性。
触发器(语句级、行级、谓词、分类、作用)
基于表的触发器:[delete\update\insert]
create or replace trigger tr_src_emp
before insert or update or delete
on emp
begin
if to_char(sysdate,'DY') in( '星期六','星期天') then
case
when inserting then
raise_application_error(-20001,'fail toinsert');
when updating then
raise_application_error(-20001,'fail toupdate');
when deleting then
raise_application_error(-20001,'fail todelete');
end case;
end if;
end;
/
9、存储过程
1、定义
CREATE ORREPLACE PROCEDURE procedure_name
AS PL/SQL块
2、参数类型
? IN:值传递,默认的-----只读
? IN OUT:带值进,带值出---可读写
? OUT:不带值进,带值出----只写
3、作用
将通用的执行过程封装起来
10、包
1、语法;
包的规范
CREATE OR REPLACE PACKAGE package_name AS|IS
参数、类型(type)、异常(exception)、游标(cursor)
、procedure、function
END[package_name];
包的主体
CREATE OR REPLACE PACKAGE BODY package_name AS|IS
参数、类型(type)、异常(exception)、游标(cursor)
、procedure、function
END[package_name];
2、调用:
package_name.type_name;
package_name.item_name;
package_name.call_spec_name;
3、作用
1、模块化;-----提高应用程序的交互性
2、信息隐藏