数据挖掘导论课后习题答案-第四章
最近在读《Introduction to Data Mining 》这本书,发现课后答案只有英文版,于是打算结合自己的理解将答案翻译一下,其中难免有错误,欢迎大家指正和讨论。侵删。
第四章
![]()


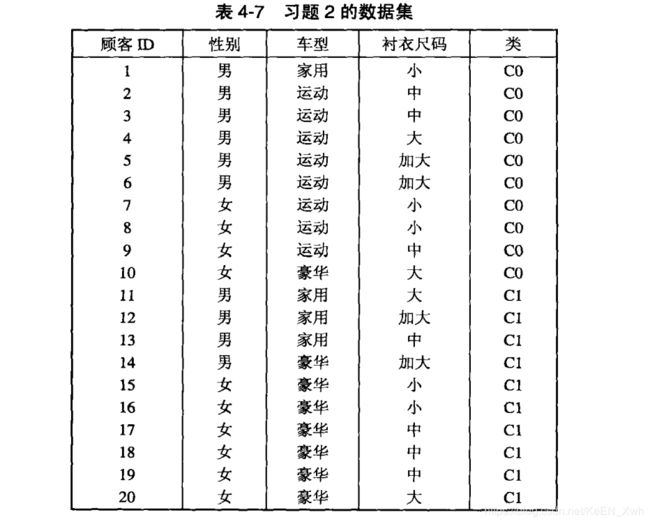
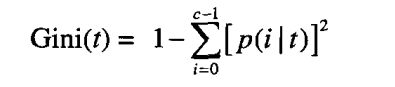
(a)Gini = 1 - ( 0.5 )2 - ( 0.5 )2 = 0.5
(b)

每个结点的 Gini = 0,因此总的Gini = 0.
(c)
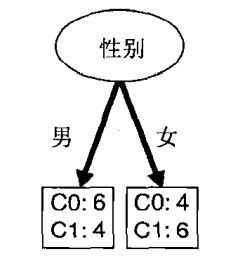
男:Gini = 1 - ( 0.6 )2 - ( 0.4 )2 = 0.48
女:Gini = 1 - ( 0.4 )2 - ( 0.6 )2 = 0.48
总:Gini = 0.5 × 0.48 + 0.5 × 0.48 = 0.48
(d)
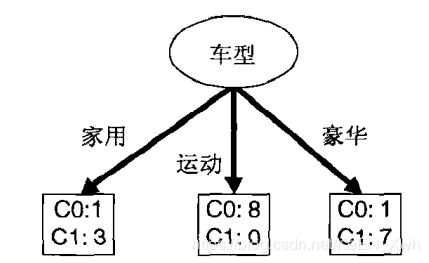
家用:Gini = 1 - ( 0.25 )2 - ( 0.75 )2 = 0.375
运动:Gini = 0
豪华:Gini = 1 - ( 1/8 )2 - ( 7/8 )2 = 0.219
总:Gini = 4/20 × 0.375 + 8/20 × 0.219 = 0.1626
(e)
加大:Gini = 1 - ( 0.5 )2 - ( 0.5 )2 = 0.5
大:Gini = 1 - ( 0.5 )2 - ( 0.5 )2 = 0.5
中:Gini = 1 - ( 3/7 )2 - ( 4/7 )2 = 0.4898
小:Gini = 1 - ( 3/5 )2 - ( 2/5 )2 = 0.48
总:Gini = 4/20 × 0.5 + 4/20 × 0.5 + 7/20 × 0.4898 + 5/20 × 0.48 = 0.4914
(f)车型更好,因为Gini值更小。
(g)ID并没有预测能力。新客户将有新的ID。


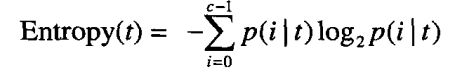
(a)Entropy = - 4/9 × log2( 4/9 ) - 5/9 × log2( 5/9 ) = 0.9911
(b)
Entropy = 4/9 × [ - 1/4 × log2( 1/4 ) - 3/4 × log2( 3/4 ) ] + 5/9 × [ - 1/5 × log2( 1/5 ) - 4/5 × log2( 4/5 ) ] = 0.7616
信息增益:0.9911 - 0.7616 = 0.2294
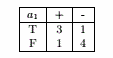
Entropy = 5/9 × [ - 2/5 × log2( 2/5 ) - 3/5 × log2( 3/5 ) ] + 4/9 × [ - 2/4 × log2( 2/4 ) - 2/4 × log2( 2/4 ) ] = 0.9839
信息增益:0.9911 - 0.9839 = 0.0072
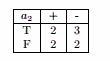
(c)
(d)a1
(e)
a1的分类错误率= 2/9
a2的分类错误率= 4/9
因此a1是最佳划分
(f)
a1 : Gini = 4/9 × [ 1 - ( 3/4 )2 - ( 1/4 )2 ] + 5/9 × [ 1 - ( 1/5 )2 - ( 4/5 )2 ] = 0.3444
a2 : Gini = 5/9 × [ 1 - ( 2/5 )2 - ( 3/5 )2 ] + 4/9 × [ 1 - ( 2/4 )2 - ( 2/4 )2 ] = 0.4889
![]()
结点划分后显然类的分布更加不均匀,因此熵不会增加。

(a)
划分前 Entropy = - 0.4 × log2( 0.4 ) - 0.6 × log2( 0.6 ) = 0.9710
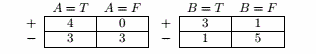
按A划分:
Entropy A=T = - 4/7 × log2( 4/7 ) - 3/7 × log2( 3/7 ) = 0.9852
Entropy A=F = 0
信息增益 = 0.9710 - 7/10 × 0.9852 - 3/10 × 0 = 0.2813
按B划分:
Entropy B=T = - 3/4 × log2( 3/4 ) - 1/4 × log2( 1/4 ) = 0.8113
Entropy B=F = - 1/6 × log2( 1/6 ) - 5/6 × log2( 5/6 ) = 0.6500
信息增益 = 0.9710 - 4/10 × 0.8113 - 6/10 × 0.6500 = 0.2565
因此会选择按A划分
(b)
划分前 Gini = 1 - ( 0.4 )2 - ( 0.6 )2 = 0.48
按A划分:
Gini A=T = 1 - ( 4/7 )2 - ( 3/7 )2 = 0.4898
Gini A=F = 0
Gini增益 = 0.48 - 7/10 × 0.4898 - 3/10 × 0 = 0.1371
按B划分:
Gini B=T = 1 - ( 3/4 )2 - ( 1/4 )2 = 0.3750
Gini B=F = 1 - ( 1/6 )2 - ( 5/6 )2 = 0.2778
Gini增益 = 0.48 - 4/10 × 0.3750 - 6/10 × 0.2778 = 0.1633
因此会选择按B划分
(c)
当然。虽然Gini指标和信息熵有着相同的范围和变化趋势,它们仍然有可能支持不同的属性,比如(a)和(b)。
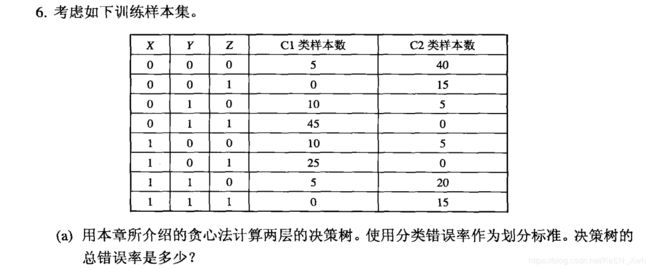

(a)为了决定根节点的划分属性,先计算X,Y,Z的分类错误率。
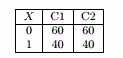
X的分类错误率 = ( 60+ 40 ) / 200 = 0.5

Y的分类错误率 = ( 40 + 40 ) / 200 =0.4

Z的分类错误率 = ( 30 + 30 ) / 200 = 0.3
因此选择Z作为根节点的划分属性。
Z=0时按X与Y分别划分如下:

X与Y的分类错误率相同 ( 15 + 15 ) / 100 = 0.3
Z=1时按X与Y分别划分如下:

X与Y的分类错误率相同 ( 15 + 15 ) / 100 = 0.3
构建决策树如下:
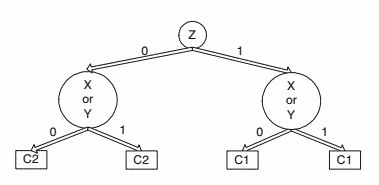
(b)
X=0时按Y与Z分别划分如下:

Y的分类错误率 = ( 5 + 5 ) / 120 = 0.0833
Z的分类错误率 = ( 15 + 15 ) / 120 = 0.25
因此按Y划分更好。
X=1时按Y与Z分别划分如下:

Y的分类错误率 = ( 5 + 5 ) / 80 = 0.125
Z的分类错误率 = ( 15 + 15 ) / 80 = 0.375
因此按Y划分更好。
构建决策树如下:
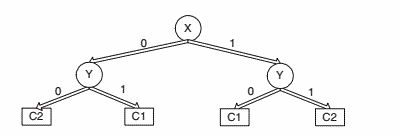
(c)显然,(b)构建的决策树分类错误率比(a)构建的更小,因此贪心策略并不一定能产生最优决策树。
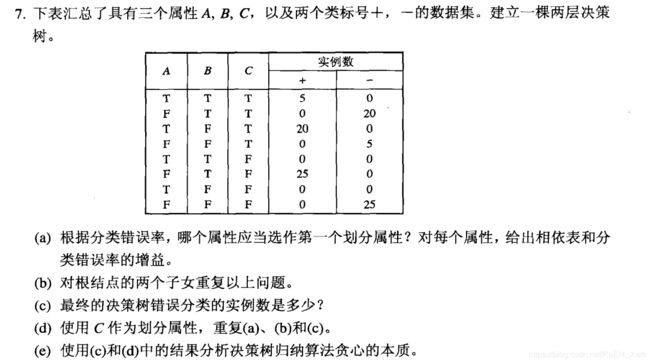
(a)
划分前的分类错误率E = 1 - 50/100 = 0.5
按A划分:

E A=T = 0
E A=F = 25/75 = 0.3333
分类错误率增益 = 0.5 - 75/100 × 0.3333 = 0.25
按B划分:
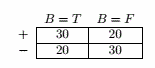
E B=T = 20/50 = 0.4
E B=F = 20/50 = 0.4
分类错误率增益 = 0.5 - 50/100 × 0.4 - 50/100 × 0.4 = 0.1
按C划分:

E C=T = 25/50 = 0.5
E C=F = 25/50 = 0.5
分类错误率增益 = 0.5 - 50/100 × 0.5 - 50/100 × 0.5 = 0
因此选择按A划分。
(b)
对于A=T,已经完全正确分类了,不需要再划分。
对于A=F:
划分前分类错误率 = 25/75 = 0.3333
按B划分:

E B=T = 20/45 = 0.4444
E B=F = 0
分类错误率增益 = 0.3333 - 45/75 × 0.4444 - 30/75 × 0 = 0.067
按C划分:

E C=T = 0
E C=F = 25/50 = 0.5
分类错误率增益 = 0.3333 - 25/75 × 0 - 50/75 × 0.5 = 0
因此选择按B划分。
(c)20
(d)
对于C=T:
划分前错误率 = 25/50 = 0.5
按A划分:
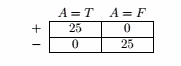
E A=T = 0
E A=F = 0
分类错误率增益 = 0.5 - 0 = 0.5
按B划分:
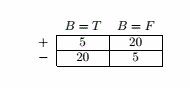
E B=T = 5/20 = 0.25
E B=F = 5/20 = 0.25
分类错误率增益 = 0.5 - 25/50 × 0.25 - 25/50 × 0.25 = 0.25
因此选择按A划分。
对于C=F:
划分前错误率 = 25/50 = 0.5
按A划分:
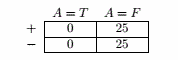
E A=T = 0
E A=F = 25/50 = 0.5
分类错误率增益 = 0.5 - 50/50 × 0.5 = 0
按B划分:
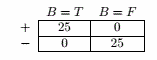
E B=T = 0
E B=F = 0
分类错误率增益 = 0.5
因此选择按B划分。
(e)贪心策略对决策树并不适用。

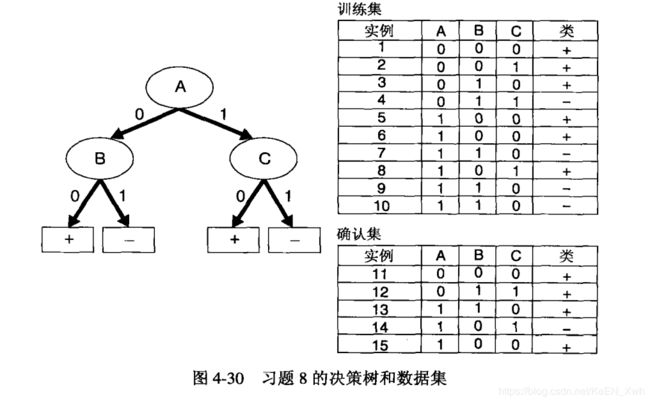
勘误:此题决策树中当A=1 , C=0时类是 - ,当A=1 , C=1时类是 + 。
(a)3/10=0.3
(b)( 3 + 0.5 × 4 ) / 10 = 0.5
(c)4/5 = 0.8

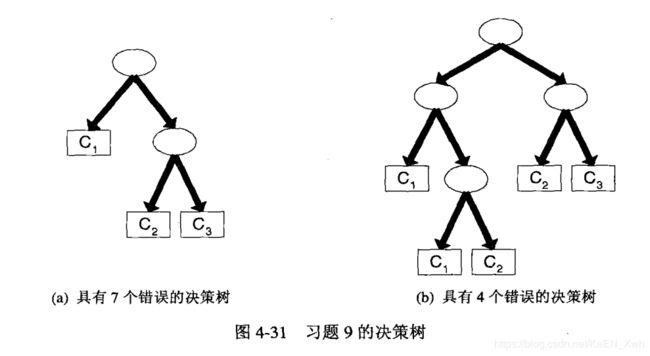
为每个内部结点编码的代价:[ log2 ( 16 ) ] = 4
为每个叶结点编码的代价:[ log2 ( 3 ) ] = 2
为每个错误编码的代价:log2 n
决策树(a)总代价:2 × 4 + 3 × 2 + 7 × log2 n = 14 + 7log2 n
决策树(b)总代价:4 × 4 + 5 × 2 + 4 × log2 n = 26 + 4log2 n
因此当 n>16 时决策树(a)更好,当 n <16 时决策树(b)更好,因此当 n=16 时一样。

(a)假设每个样本被抽中的概率相同,则误差率接近50%。
(b)假设每个样本被抽中的概率相同,则误差率接近50%。
(c)误差率为:
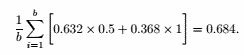
(d)十折交叉验证和保持原方法提供了更可靠的估计。


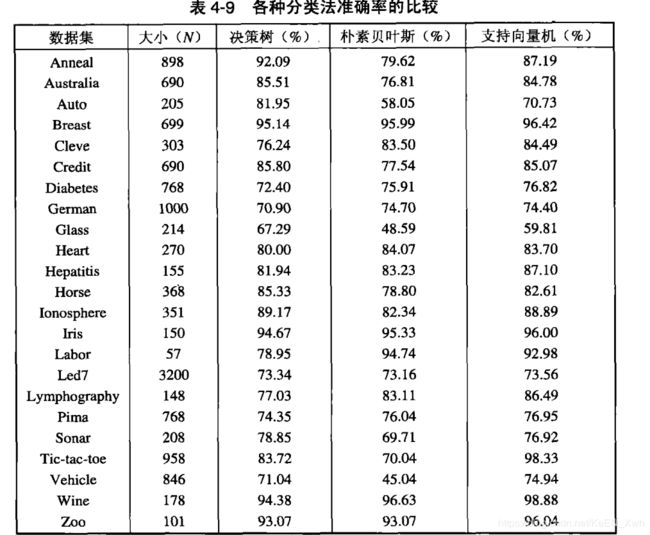

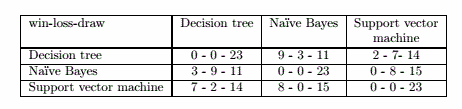
以决策树为分类法A,朴素贝叶斯为分类法B为例子(建议计算时通过编写一个函数):
Anneal:pA = 0.9209, pB = 0.7962,p = ( pA + pB ) / 2 = 0.8586,Z = 7.58
Australia:pA = 0.8551, pB = 0.7681,p = ( pA + pB ) / 2 = 0.8116,Z = 4.13
Auto:pA = 0.8195, pB = 0.5805,p = ( pA + pB ) / 2 = 0.7,Z = 5.28
Breast:pA = 0.9514, pB = 0.9599,p = ( pA + pB ) / 2 =0.9557 ,Z = -0.7719
Cleve:pA = 0.7624, pB = 0.8350,p = ( pA + pB ) / 2 =0.7987 ,Z = -2.2286
Credit:pA = 0.8580, pB = 0.7754,p = ( pA + pB ) / 2 =0.8167 ,Z = 3.9653
Diabetes:pA = 0.7240, pB = 0.7591,p = ( pA + pB ) / 2 =0.7280 ,Z = -1.6734
German:pA = 0.7090, pB = 0.7470,p = ( pA + pB ) / 2 =0.7280 ,Z = -1.9095
Class:pA = 0.6729, pB = 0.4859,p = ( pA + pB ) / 2 =0.5794 ,Z = 3.9184
Heart:pA = 0.8000, pB = 0.8407,p = ( pA + pB ) / 2 =0.8204 ,Z = -1.2318
Hepatitis:pA = 0.8194, pB = 0.8323,p = ( pA + pB ) / 2 =0.8259 ,Z = -0.2995
Horse:pA = 0.8533, pB = 0.7880,p = ( pA + pB ) / 2 = 0.8207,Z = 2.3088
Ionosphere:pA = 0.8917, pB = 0.8234,p = ( pA + pB ) / 2 =0.8576 ,Z = 2.5880
Iris:pA = 0.9467, pB = 0.9533,p = ( pA + pB ) / 2 = 0.9550,Z = 0.1420
Labor:pA = 0.7895, pB = 0.9474,p = ( pA + pB ) / 2 = 0.8684,Z = -2.4939
Led7:pA = 0.7334, pB = 0.7316,p = ( pA + pB ) / 2 = 0.7325,Z = 0.1627
Lymphography:pA = 0.7703, pB = 0.8311,p = ( pA + pB ) / 2 =0.8007 ,Z = -1.3093
Pima:pA = 0.7435, pB = 0.7604,p = ( pA + pB ) / 2 = 0.7520,Z = -0.7668
Sonar:pA = 0.7885, pB = 0.6971,p = ( pA + pB ) / 2 =0.7428 ,Z = 2.1325
Tic-tac-toe:pA = 0.8372, pB = 0.7004,p = ( pA + pB ) / 2 =0.7688 ,Z = 7.1016
Vehicle:pA = 0.7104, pB = 0.4504,p = ( pA + pB ) / 2 =0.5804 ,Z = 10.8358
Wine:pA = 0.9438, pB = 0.9663,p = ( pA + pB ) / 2 = 0.9551,Z = -1.0245
Zoo:pA = 0.9307, pB = 0.9307,p = ( pA + pB ) / 2 = 0.9307 ,Z = 0
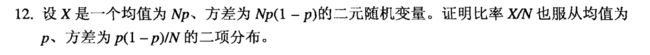
E[ X / N ] = E[ X ] / N = ( Np ) / N = p
E[ ( X / N - E[ X / N ] )2 ] = E[ ( X - E[ X ] ) 2 ] / N2 = Np( 1 - p ) / N2 = p( 1 - p ) / N