论文解读:Once-for-All: Train One Network and Specialize it for Efficient Deployment
Once-for-All: Train One Network and Specialize it for Efficient Deployment
Arxiv PDF: paper link
目录
Once-for-All: Train One Network and Specialize it for Efficient Deployment
概述
Trainining
Progressive Shrinking(简称PS)
Channel Shrinking
Kernel Shrinking
Depth Shrinking
Width Shrinking
渐进收缩算法 (Progressive Shrinking Approach)
知识蒸馏:
网络专门化
Deployment
一些想法:
概述

给每一个设备设计一个自己的结构,不论是人工去做,还是依靠NAS都是很昂贵的,而且这里面要retrain大量的网络,费时费电,污染大气,而且没法覆盖每一种设备。于是提出了OFA网络,一次训练,到处部署。
那么他们认为主要的难点是没法去更新所有sub-networks的gradient,但是如果只是每步随机采样几个sub-networks,就会带来显著的accu drop。而且这些sub-networks都是耦合的,会互相干扰,所以train大网络会很困难,所以他们提出了一个progressive shrinking 的算法,就是先train一个最大的网络(最大的深度,宽度,核大小),再fine-tune到小网络(share weights)。他们认为这么做会让较大的网络更好的初始化,较小的网络可能可以distill到更小,因而可以提高训练效率。
听起来就是NAS搜一个网络,再Prune一下。所以他们也说了,这个其实就是广义上的prune,只不过prune的维度更多。
让后又刷榜了...嗯...牛逼,跳过刷榜的部分给下数据,Imagenet 80.0% Top-1, 595MACs, 同精度最快的。(但是其实吧,FixEfficientNet-B0比他高0.2% hhhh,不过在意这点真的没啥意义= =)
那么对于一个NAS类的文章,其实我觉得核心还是在于Serach Space的选择,和Search算法的设计。Space的部分,他们还是adopt了一般的做法,就是用Block搭成一个自下而上的网络,然后一边减feature map size,一边增加channel,然后每组Unit的第一个Layer是Stride=2。
每一个Unit可以有任意数量的layer(elastic depth),每个layer有任意数量channel(elastic width),以及任意大小的kernel(elastic kernel),以及支持任意大小输入(elastic resolution)。
他们取的input image size是[128,224],输入Stide=4,每个unit的depth是{2,3,4},kernel size expansion ratio是{3,5,7},每层的channel数 {4,5,6}。那么他们就有2*10^19中不同的结构,每种都可以接受25种不同的输入分辨率,因为他们都share同样的weights,整个网络只有7.7M参数量。即便不做shrinking,这个模型的大小依旧是比较有限的。(原文是will be probitive...第一反应...这个模型大小是禁止的X)
关于有2 * 10^19种子网络的计算:
- No.sub-net =
- 每一项中的3 x 3代表三种kernel size和三种channel的组合数
- 指数2,3,4代表每一个block的深度depth {2,3,4},每种深度的每一层都有3x3种网络结构,那么两层即2次方,3层即3次方....
- 指数5代表五个unit,网络训练过程中共有5个阶段,详见Figure 2
Naive一点呢,NAS可以被当成是一个多目标多变量优化问题,枚举每一个sub-network就能找到最好的(真简单直接呢!),不过考虑到计算量,肯定是不行的。那么还有一种naive的方法就是每次随机采样一些sub-networks,但是问题在于,这么多的sub-network肯定会互相干扰,从而造成比较大的accu drop。
(嗯...终于到正题了。不过shared weight的网络如何training一直是一个还没有被很好的解决问题,从为啥这个方法会work,到没法避免的bias问题。)
Trainining
Progressive Shrinking(简称PS)
基本的训练方法就是从大到小。首先训练那个最大的sub-network(resolution, kernel size, depth, width)全都开满。然后通过share weights的方法把这个大的网络fine tune到较小的网络上。

这个顺序就如上图一样,不过Resolution在整个过程中都是elastic的。先砍kernel size,再砍depth,再砍width,整个的想法还是很intuitive的。(不过我很好奇,虽然这个熟悉很符合直觉,他们有没有测试过其他的顺序,以及这个顺序造成的影响)。他们也提到了在训练过程中用了distill的一些方法,小的网络会使用大的网络提供的soft labels。
这个方法能够避免不同的sub-networks互相干扰(解决问题最好的方法就是解决产生问题的人X,大家不joint-training就不会出问题)。

那么和传统的Prune比,他们的是在多个维度上shrink,以及他们会fine-tine多个sub-nets.(不过我觉得区别不够吧...这个不就是一个维度比较高的pruning)

那么在shrinking的时候也是有特殊的操作。
Channel Shrinking
在Channel Shrinking的时候,他们会根据“Channel Importance”来选择最“Important”的几个layer和更小的网络share。(这个地方一开始看蒙我了,我还以为是他从darts有一些take-away,但是实际上就是根据L1 Norm来排个名。那么L1 Norm是啥呢?L1 Norm又称曼哈顿距离或者出租车范数,用人话说呢,就是绝对值求和。也就是他会把大网络里面值最大的几个channel给更小的...大家写文章能用人话么...)(这个地方我觉得还是挺不合理的...不过考虑到Shared Weight本来也不是啥合理的东西...anyway)

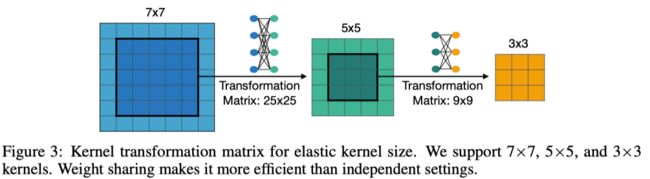
Kernel Shrinking
因为这些kernel都是share weight的,所以他们不能直接share,因为不同kernel大小都会share同样的中心位置的weights,也对于中心的weights的分布和大小有不同的要求。所以他们提出了一个卷积核变换矩阵。他们在不同的layer用不同的变换矩阵,同一层内会share同样的kernel变换矩阵,所以这样他们只需要25x25+9x9=706个额外的参数。
Depth Shrinking
这个他们处理的方式和传统NAS差不多,就是保留前D个layer,跳过后面的layer。如Figure 5右图
Width Shrinking
就是上面的channel shrinking
渐进收缩算法 (Progressive Shrinking Approach)
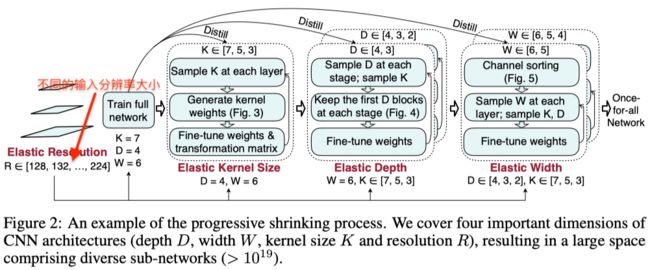
上图展示了算法的整个步骤,首先训练整个网络,然后从不同角度收缩网络进行 fine-tune。作者描述这个算法具有以下优点:
子网络相比超网是更容易收敛的,因为结构更加简单
通过超网提供的初始化参数,子网络更容易训练。子网的参数选择过程使用了重要性评价的方式,并且通过知识蒸馏能够使子网络获得更好的监督
因为进行了参数的排序,因此能够防止子网络影响超网的性能
| 优化目标 | 详细方法 |
备注 |
|---|---|---|
| 弹性分辨率 | 神经网络应该允许不同尺寸的图像输入,但是作者发现如果输入的分辨率是悬链过程中没有见过的,则会造成明显的性能损失,因此作者对分辨率进行了采样,让输入的分辨率在一定范围内变化 | 直接通过修改 data loader 实现 |
| 弹性卷积核大小 | 如果训练效果好,大卷积核的中心是可以被当做小卷积核使用的。难点在于小的卷积核是需要被共享的,而小的卷积核在不同的角色中可能有不同的分布和量级,因此作者引入了 核变换矩阵(输入大核的中心,输入小核)来完成,该矩阵在channel间共享
|
转移矩阵的通道共享性质值得思考。共享和不共享相比对模型的性能有何影响?根据作者的描述,小核的参数和转移矩阵是一起训练的,那么使用的是端到端 |
| 弹性深度 | 通过跳过 stage 中的部分 block 实现,但采用收缩的方式跳过,即只是一次跳过后面的几个block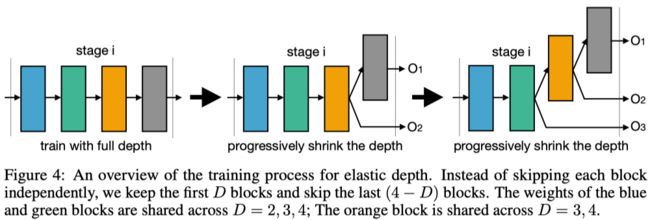 |
这里使用的方法应该和cascade的思想是已知的,不但是引入跳过连接,而是因此多阶段的loss回传,从而使得浅层模块具备单独使用的能力 |
| 弹性宽度 | 对不同的 channel 进行排序,通过重要性重新组织 channels,这个指标通过 channel 权重的 L1 norm 来衡量,值大的更加重要。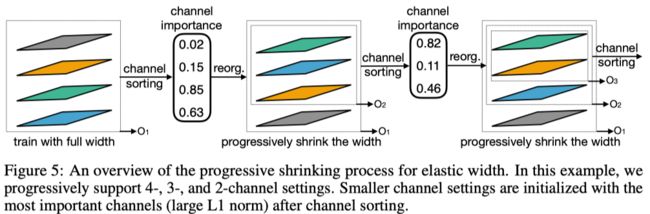 |
L1 norm 在语义理解比较简单,但有一个问题,既然卷积是“加权求和”,那么为什么不同ones卷积结果(即保留正负)或者其他控制分布的方式而使用绝对值呢——我感觉评价参数的分布值(例如方差等)应该更有意义一些 |
知识蒸馏:
出了常规的 label 之外,还引入了 soft label (通过整个网络的前向传播给出),通过作用于子网的训练

即子网络同时学习超网的辨识能力,这在超网效果较好的情况下能够提供好的结果,但是超网是一次训练的,相当于一个 roof,稍有偏差都会对子网造成不小的影响吧。
网络专门化
这个阶段并不需要训练网络。通过随机取样(文中选择了16K个结构)来建立准确率表和延迟表,这样在给定硬件设置之后只需要检索这个表就能够做出结构的选择了。
网路结构变化部分按照上述的方式进行,分辨率变化采用每16一个步长建立表格,缺失的分辨率通过加权计算得到,例如:

Deployment
那么部署的话,他们做了一个三层前馈网络的一个小accuracy predictor(输入是one-hot编码的网络结构和输入大小)来减少search的时间。他们抽了16K sub-networks,然后跑了10K张从原始训练集中抽出来的测试集图片用于训练那个accurancy predictor。然后他们还在各个硬件上做了一个latency lookup table用于得到latency。
这样子之后,其实训练和NAS的过程就完全解耦了~
然后他们用进化算法来找到一个合适的sub-network。(因为其实有了两个predictor之后,evalute每个sample的开销会非常小)
他们的Search Space是设计和MobileNetV3一样,然后整个训练过程在V100 GPU上使用了1200GPU Hours。
一些想法:
我觉得他主要是这两大部分,
- 先训练一个大网络,再通过Distill/Prune的方式把大网络finetune到小网络上
- 有一个相对准确的accurancy predictor和latency lut来search最后需要的参数
本身大网络distill到小网络的这个做法是一直广泛使用的,这里是把单纯的puring/distill延伸成了一种有效的NAS的做法。
我觉得整个做法与传统puring所延伸的地方在于如何有效的predict你distill出来的网络的accurancy,可能就是他的这种PS的做法让构建一个有效的accurancy predictor成为了可能。(如果我不使用PS,而是直接做一个大网络,然后随机sample一些结构把大网络distill过去,来构建accurancy predictor是否能得到同样的结果呢?)
所以我觉得这个更加是一个系统类的工作,而不是一个算法类的工作,作者整合了先有的方法,融入了一些自己的trick来提高(比如说kernel transform matrix(文章里没有什么细节,代码扫了一眼似乎就是一个线性变换矩阵)以及channel sorting)。(以及Han Lab讲故事真的强...这文章要是我写,估计根本中不了)
版权声明:本文为CSDN博主「flyminnnnn」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_39505272/article/details/100184165
作者:Mars韩笑
链接:https://zhuanlan.zhihu.com/p/137086377
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。