张小白的渗透之路(一)——HTTP协议详解
HTTP简介
HTTP(Hyper Text Transfer Protocol 超文本传输协议),是互联网上应用最为广泛的一种网络协议。基于TCP/IP通信协议来传递数据(HTML文件,图片文件,查询结果等)
目前HTTP的版本是HTTP/1.1,HTTP/2.0正在设计当中
HTTP工作原理
HTTP协议采用C/S的工作架构,通常我们使用浏览器充当客户端角色通过URL(传输数据和建立连接)向HTTP服务端(WEB服务器)发送所有请求。
对于HTTP协议的工作原理可以简单的用下图作以理解
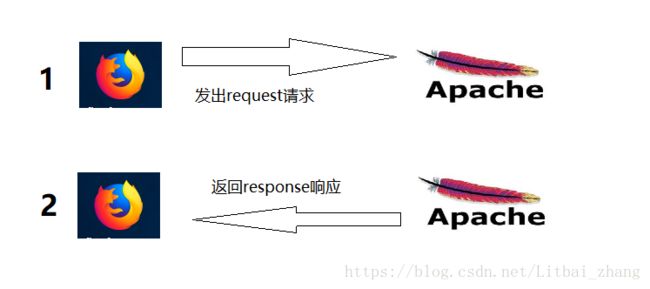
值得一提的HTTP
- HTTP是无连接的,无连接的意思就是每次连接只处理一个请求,像上图描述的一个请求响应来回之后,便断开连接。这种方式可以节省信息传输的时间
- HTTP是无状态的,协议自身不对请求和响应之间的同行状态进行保存。也就是说,协议对于发送过的请求和响应都不做持久化处理。但是随着web的发展,因为无状态而导致业务处理变得棘手的情况增多了。比如登录CSDN的网站,我要跳转到该站的其他页面后,也需要保持登录的状态,因为网站需要知道是谁发出的这个请求。于是HTTP/1.1引入了cookie技术,用以实现期望的保持状态功能。
- HTTP是媒体独立的,也就是说,只要服务端和客户端知道处理数据的方式,那么任何类型的数据都可以通过http协议发送。
值得一提的URL的格式
首先URL(Uniform Resource Locator 统一资源定位符)用来描述一个网络上的资源。基本格式如下
schema://host[:port#]/path/.../[;url-params][?query-string][#anchor]*
schema 指定低层使用的协议(例如:http,https,ftp)
host HTTP服务器的IP地址或者域名
port# HTTP服务器的端口号,默认80
path 访问资源的路径
url-params
query-string
(这两个东西就是发送给http服务器的数据,那么怎么去理解他呢首先我们要搞清楚什么是params,什么是query。简单的理解:
params:/router1/:id ,/router1/123,/router1/789 ,这里的id叫做params
query:/router1?id=123 ,/router1?id=456 ,这里的id叫做query。
举个例子,现在我有一个网页,有多个层级的按钮
公司列表(id=111)->部门列表(id=222)->员工列表(id=333)->员工详情(id=444)
| 公司列表 | 部门列表 | 员工列表 | 员工详情 | 说明 | |
|---|---|---|---|---|---|
| params风格1 | /corps/ | /corps/111 | /corps/111/222/ | /corps/111/222/333/ | 依次罗列id |
| params风格2 | /corps/ | /corps/111 | /111/departs/222/ | /111/222/users/333/ | 最后一定是/items/item_id格式 |
| params风格3 | /corps/ | /corps/111 | /corps/111/departs/222 | /corps/111/departs/222/users/333/ | 严格保持restful格式 |
| query风格 | /corps/ | /departs/?corp=111 | /users/?corp=111&depart=222 | /detail/?corp=111&depart=222&user=333 | 从url直接看出意思,query依次罗列 |
| 混合风格 | /corps/ | /corps/111 | /departs/222/?corp=111 | /users/333/?corp=111&depart=222 | 最后是/items/item_id格式,缺失信息用query补 |
看到这里我想大家都发现其实这两个是一个属性,只不过表达方式不一样,一般怎样会让URL美观就采用怎样的方式。)
anchor 锚
Anchor 对象表示 HTML 超链接
在 HTML 文档中 a 标签每出现一次,就会创建 Anchor 对象;
锚可用于创建指向另一个文档的链接(通过 href 属性),或者创建文档内的书签(通过 name 属性);
HTTP消息结构
HTTP请求消息
一个HTTP请求报文由请求行(request line)、请求头部(header)、空行和请求数据4个部分组成,下面是请求报文的一般格式。
//请求行
//请求头
//空格
//请求数据
Request URL:http://www.baidu.com/ //请求行
Request Method:GET //请求头
Status Code:200 OK
Remote Address:172.31.1.246:8080
//空格
1.请求行
请求行由请求方法字段、URL字段和HTTP协议版本字段3个字段组成,它们用空格分隔。例如,GET /index.html HTTP/1.1。
HTTP协议的请求方法有GET、POST、HEAD、PUT、DELETE、OPTIONS、TRACE、CONNECT。
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | GET | 请求指定的页面信息,并返回实体主体 |
| 2 | HEAD | 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| 3 | POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立或已有的资源的修改 |
| 4 | PUT | 从客户端向服务器传送的数据取代指定的文档的内容 |
| 5 | DELET | 请求服务器删除指定的页面 |
| 6 | CONNECT | HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器 |
| 7 | OPTIONS | 允许客户端查看服务器的性能 |
| 8 | TRACE | 回显服务器收到的请求,主要用于测试或诊断 |
2.请求头部
请求头部由关键字/值对组成,每行一对,关键字和值用英文冒号“:”分隔。请求头部通知服务器有关于客户端请求的信息,典型的请求头有:
User-Agent:产生请求的浏览器类型。
Accept:客户端可识别的内容类型列表。
Host:请求的主机名,允许多个域名同处一个IP地址,即虚拟主机。
列子:
| 应答头 | 说明 |
|---|---|
| Content-Encoding | 文档的编码(Encode)方法。解码后才可以得到Content-Type头指定的内容类型。 |
| Content-Length | 表示内容长度。只有当浏览器使用HTTP连接时才需要这个数据。例如,下载数据时,通过它查看字节大小 |
| Content-Type | 表示后面的文档是属于什么MIME类型。Servlet默认为text/plain,但最好显式指出 |
| Date | 当前的GMT时间(格林威治时间) |
| Expires | 表示在什么时候认为文档已经过期,从而不再缓存它 |
| Last-Modified | 文档的最后改动时间 |
| Location | 文档位置,表示客户端应该到那提取文档 |
| Refresh | 表示浏览器应该在多少时间后刷新文档或页面(只一次,非重复),以秒计。Refresh不属于HTTP1.1正式规范中,而是一个扩展,但Netscape和IE都支持它 |
| Server | 服务器名字 |
| Set-Cookie | 设置页面相关的Cookie |
| WWWW-Authenticate | 表示客户端需要在其中提供某类型的授权信息。例如,在包含401状态行的应答中,这个头就需要设置 |
一般来说,请求头里面包含着客户端此次请求的具体信息:
比如说,客户端接受服务器返回的文件的类型,Content-Type
客户端此次接受服务器返回文件的长度,Content-Length
客户端想要的返回文件的具体范围,Range
客户端的语言环境等,都是包含在请求头里面的。知道这些信息,我们就可以加以利用,来达到想要的效果。
3.空行
最后一个请求头之后是一个空行,发送回车符和换行符,通知服务器以下不再有请求头。
4.请求数据
一般是POST请求才有请求体的,主要是上传文件时用到,一般是放需要传给客户端的具体文件。POST方法适用于需要客户填写表单的场合。
HTTP响应报文
HTTP响应也由三个部分组成,分别是:状态行、响应头、响应正文。
<status-line> //状态行
<headers> //消息头头
<blank line> //空格
<response-body> //响应正文
协议版本 状态码
| |
HTTP/1.1 200 OK ——状态码的原因短语
Date: Tue, 10 Jul 2012 06:50:15 GMT ——响应报头
Content-Length:362
Content-Type:text/html
——响应正文
……
1.状态行
正如你所见,在响应中唯一真正的区别在于第一行中用状态信息代替了请求信息。
状态行(status line)通过提供一个状态码来说明所请求的资源情况。
1xx:指示信息--表示请求已接收,继续处理。
2xx:成功--表示请求已被成功接收、理解、接受。
3xx:重定向--要完成请求必须进行更进一步的操作。
4xx:客户端错误--请求有语法错误或请求无法实现。
5xx:服务器端错误--服务器未能实现合法的请求。
常见状态代码、状态描述的说明如下。
200 OK:客户端请求成功。
400 Bad Request:客户端请求有语法错误,不能被服务器所理解。
401 Unauthorized:请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用。
403 Forbidden:服务器收到请求,但是拒绝提供服务。
404 Not Found:请求资源不存在,举个例子:输入了错误的URL。
500 Internal Server Error:服务器发生不可预期的错误。
503 Server Unavailable:服务器当前不能处理客户端的请求,一段时间后可能恢复正常,举个例子:HTTP/1.1 200 OK(CRLF)。
2.响应头
也就是服务器返回给客户端,服务器的具体信息,和请求头想表达的意思是一样的。
3.空行
最后一个响应头之后是一个空行,发送回车符和换行符,通知服务器以下不再有请求头。
4.响应正文
服务器返回给客户端的文件、数据等。
下面实例是一典型的使用GET来传递数据的实例:
客户端请求:
GET /hello.txt HTTP/1.1
User-Agent: curl/7.16.3 libcurl/7.16.3 OpenSSL/0.9.7l zlib/1.2.3
Host: www.example.com
Accept-Language: en,mi
服务端请求:
HTTP/1.1 200 OK
Date: Mon, 27 Jul 2009 12:28:53 GMT
Server: Apache
Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT
ETag: “34aa387-d-1568eb00”
Accept-Ranges: bytes
Content-Length: 51
Vary: Accept-Encoding
Content-Type: text/plain
输出结果:
Hello World! My payload includes a trailing CRLF.