Python学习笔记(八)——从Web抓取信息
小实验——利用webbrowser模块的mapIt.py
>>> import webbrowser
>>> webbrowser.open('http://www.baidu.com')弄清楚URL
http://news.baidu.com/ns?word=搜索内容
https://www.baidu.com/s?wd='+address 百度搜索
处理命令行参数
if len(sys.argv) > 1:
#Get address from command line
address = ' '.join(sys.argv[1:])处理剪贴板内容
address = pyperclip.paste()加载浏览器
webbrowser.open('https://www.baidu.com/s?wd='+address)用requests模块从Web下载文件
requests 是第三方文件
import requests快速上手 — Requests 2.18.1 文档
用requests.get()函数下载一个网页
>>> import requests
>>> res = requests.get('http://blog.csdn.net/mq_go')
>>> type(res)
<class 'requests.models.Response'>
>>> res.status_code == requests.codes.ok
True
>>> len(res.text)
40492
>>> print(res.text[:500])
<html>
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=Edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no">
<meta name="apple-mobile-web-app-status-bar-style" content="black">
<link rel="canonical" href="http://blog.csdn.net/mq_go"/>
<script type="text/javascript">
console.log('version: phoeni
检查错误
res.raise_for_status()
res = requests.get(‘http://blog.csdn.net/mq_go‘)
res.raise_for_status()
res = requests.get(‘http://aosdfhaufa.com/‘)
将下载的文件保存到硬盘
>>> import requests
>>> re = requests.get('http://www.baidu.com')
>>> re.raise_for_status()
>>> playFile = open('baidu_html.txt','wb')
>>> for chunk in re.iter_content(100000):
playFile.write(chunk)
2381
>>> playFile.close()HTML
用BeautifulSoup模块解析HTML
从HTML中创建一个BeautifulSoup对象
使用载的网页创建
>>> import bs4,requests
>>> re = requests.get('http://blog.csdn.net/Mq_Go')
>>> re.status_code
200
>>> re.status_code == requests.codes.ok
True
>>> re.raise_for_status()
>>> shup = bs4.BeautifulSoup(re.text)
>>> type(shup)
<class 'bs4.BeautifulSoup'>使用本地是html文件
>>> exampleFile = open('example.html')
>>> example = exampleFile.read()
>>> exampleShup = bs4.BeautifulSoup(example)
>>> type(exampleShup)
<class 'bs4.BeautifulSoup'>用select()方法寻找答案
| 传递给select()方法的选择器 | 将匹配… |
|---|---|
| soup.select(‘div’) | 所有名为 |
| soup.select(‘#author’) | 带有id 属性为author的元素 |
| soup select(‘.notice’) | 所有使用CSS class 属性名为notice 的元素 |
| soup.select(‘div span’) | 所有在 |
| soup.select(‘div>span’) | 所有直接在 |
| soup.select(input[name]’) | 所有名为 |
| soup.select(‘input[type=”button”]’) | 所有名为 |
>>> import bs4
>>> exampleFile = open('example.html')
>>> exampleShup = bs4.BeautifulSoup(exampleFile.read())
>>> elems = exampleShup.select('#author')
>>> type(elems)
<class 'list'>
>>> len(elems)
1
>>> type(elems[0])
<class 'bs4.element.Tag'>
>>> elems[0].getText()
'AI Sweigart'
>>> elems[0]
"author">AI Sweigart
>>> elems[0].attrs
{'id': 'author'}>>> pElems = exampleShup.select('p')
>>> len(pElems)
3
>>> print(str(pElems[0])+'\n'+str(pElems[1])+'\n'+str(pElems[2]))
<p>Download my <strong>Pythonstrong> book from <a href="http://inventwitnpython.com">My websitea>.p>
<p class="slogan">Learn Python the easy way!p>
<p>By<span id="author">AI Sweigartspan>p>
>>> print(str(pElems[0].getText())+'\n'+str(pElems[1].getText())+'\n'+str(pElems[2].getText()))
Download my Python book from My website.
Learn Python the easy way!
ByAI Sweigart通过元素的属性获取数据
>>> import bs4
>>> soup = bs4.BeautifulSoup(open('example.html'))
>>> soanElem = soup.select('span')[0]
>>> soanElem.get('id')
'author'
>>> str(soanElem)
''
>>> soanElem.attrs
{'id': 'author'}
小实验——“I’m Feeling Lucky” 查找
- 从命令行参数中获取查询关键字。
- 取得查询结果页面。
- 为每个结果打开一个浏览器选项卡。
- 这意味着代码需要完成以下工作:
- 从sys.argv 中读取命令行参数。
- 用requests 模块取得查询结果页面。
- 找到每个查询结果的链接。
- 调用webbrowser.open()华丽的打开Web 浏览器。
- 打开一个新的文件编辑器窗口,并保存为lucky.py.
#! python3
#lucky.py - Opens several baidu search results.
#
#
#Author : qmeng
#MailTo : [email protected]
#QQ : 1163306125
#Blog : http://blog.csdn.net/Mq_Go/
#Create : 2018-02-08
#Version: 1.0
import requests,sys,bs4,webbrowser
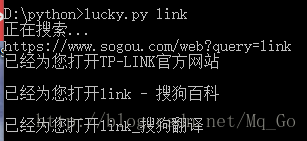
print('Baidu...')
re = requests.get('https://www.sogou.com/web?query='+' '.join(sys.argv[1:]))
print('https://www.sogou.com/web?query='+' '.join(sys.argv[1:]))
re.raise_for_status()
#print(re.text[:5600])
#Retrieve top search result links.
soup = bs4.BeautifulSoup(re.text, "html.parser")
#Open a browser tab for each result.
linkElems = soup.select('.vrTitle a')
numopen = min(3,len(linkElems))
for i in range(numopen):
print('已经为您打开'+linkElems[i].getText())
print()
webbrowser.open(linkElems[i].get('href'))
小实验——下载所有的XKCD漫画
#! python3
#downloadXKcd.py - downloads every single XKCD comic.
#
#
#Author : qmeng
#MailTo : [email protected]
#QQ : 1163306125
#Blog : http://blog.csdn.net/Mq_Go/
#Create : 2018-02-08
#Version: 1.0
import requests,os,bs4
url = 'http://xkcd.com'
os.makedirs('xkcd',exist_ok=True)
k = 0
while not url.endswith('#') and k != 5:
k = k + 1
#download the page.
print('Downloading page %s...'%(url))
res = requests.get(url)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text,"html.parser")
#find the URL of the comic image.
comicElem = soup.select('#comic img')
if comicElem == []:
print('Could not find comic image.')
else:
comicUrl = comicElem[0].get('src')
comicUrl = 'http://xkcd.com' + comicUrl[1:]
print('Downloading image %s...'%(comicUrl))
res = requests.get(comicUrl)
res.raise_for_status()
imgFile = open(os.path.join('xkcd',os.path.basename(comicUrl)),'wb')
for chunk in res.iter_content(100000):
imgFile.write(chunk)
imgFile.close()
prevLink = soup.select('a[rel="prev"]')[0]
url = 'http://xkcd.com' + prevLink.get('href')