爬虫学习(二)
Scrapy使用和入门
1.创建一个scrapy项目
scrapy startproject myspider
 创建了一个名为
创建了一个名为myspider的项目,生成了这么些东西
2.生成一个爬虫
cd myspider# 进入项目文件夹里scrapy genspider itcast itcast.cn

首先进入哪个爬虫项目(可能有多个),然后生成了一个爬虫,爬虫名为itcast,爬取的域名范围是itcast.cn,怕的就是这爬虫爬的太快,爬到别的网站去了,所以限制一下
生成了这么一个文件
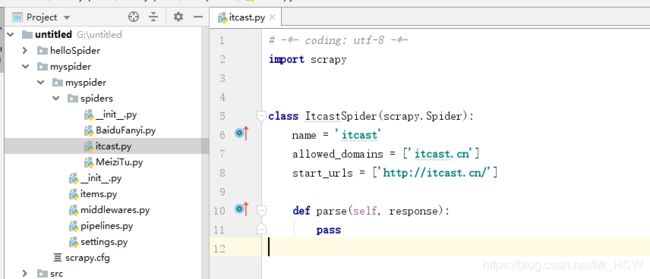
这个文件主要就是处理响应信息,提取数据,我们可以写如下程序,是请求某一个url,提取里面某些数据
# -*- coding: utf-8 -*-
import scrapy
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ['http://www.itcast.cn/channel/teacher.shtml#ajavaee']
def parse(self, response):
# 处理start_url地址对应的响应
ret = response.xpath("//div[@class='tea_con']//h3/text()")
print(ret)
然后我们启动这个爬虫 scrapy crawl itcast
注意要在项目文件夹下运行,后面一个是爬虫的名字

看看结果,除了我们需要打印的东西,还要好多乱七八糟的东西,这些其实是日志

打印这么多日志,看起来非常麻烦,我们可以设置一下,在settings.py中添加一行语句
LOG_LEVEL = "WARNING"
现在运行的时候,除了打印我们想要的信息,只会显示WARNING及等级以上的信息,比如WARNING和WRONG
我们从上面打印中,还发现,这是一个对象,我们可以提取里面的数据,使用.extract()方法
def parse(self, response):
# 处理start_url地址对应的响应
ret = response.xpath("//div[@class='tea_con']//h3/text()").extract()
print(ret)

我们还可以像以前一样进行分组写
def parse(self, response):
# 处理start_url地址对应的响应
# ret = response.xpath("//div[@class='tea_con']//h3/text()").extract()
# print(ret)
# 分组
li_list = response.xpath("//div[@class='tea_con']//li")
for li in li_list:
item = {}
item["name"] = li.xpath(".//h3/text()").extract()[0]
item["title"] = li.xpath(".//h4/text()").extract()[0]
print(item)

如果但是这样写,有时会出现错误,比如某一个字段里面没有值,因为去了第0个,所以会报错
其实还有更好的方法,也不用判断它的长度是否大于0,它提供了.extract_first()方法
这个方法的好处在于,当不存在某个字段的时候,会自动填充None
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ['http://www.itcast.cn/channel/teacher.shtml#ajavaee']
def parse(self, response):
# 处理start_url地址对应的响应
# ret = response.xpath("//div[@class='tea_con']//h3/text()").extract()
# print(ret)
# 分组
li_list = response.xpath("//div[@class='tea_con']//li")
for li in li_list:
item = {}
item["name"] = li.xpath(".//h3/text()").extract_first()
item["title"] = li.xpath(".//h4/text()").extract_first()
print(item)
接下来,我们看看如果将获取的数据放进pipeline里面,pipeline主要实现保存数据
使用yield可以将数据传到pipeline里面,(可以返回一个字典,但是不能返回列表)
def parse(self, response):
# 处理start_url地址对应的响应
# ret = response.xpath("//div[@class='tea_con']//h3/text()").extract()
# print(ret)
# 分组
li_list = response.xpath("//div[@class='tea_con']//li")
for li in li_list:
item = {}
item["name"] = li.xpath(".//h3/text()").extract_first()
item["title"] = li.xpath(".//h4/text()").extract_first()
# print(item)
yield item
当然,scrapy模式是关闭pipeline的,我们需要将它开启
在settings.py中,我们需要作如下操作,将这些部分取消注释就好了
图中的300是权重,值越小先执行,因为可以存在多个pipeline,

在pipelines.py中,我们可以打印数据
class MyspiderPipeline(object):
def process_item(self, item, spider):
print(item)
return item
pipline介绍
当存在多个爬虫,pipline怎么能确定这数据是来自与哪一个爬虫的呢?
pipline里面的函数还有一个参数,当爬虫传递数据过来,会指名是哪个爬虫传过来的
class MyspiderPipeline(object):
def process_item(self, item, spider):
if spider.name == 'itcast':
print(item)
return item
logging模块的使用
它可以帮助生成日志
# -*- coding: utf-8 -*-
import scrapy
import logging
logger = logging.getLogger(__name__)
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ['http://itcast.cn/']
def parse(self, response):
for i in range(10):
item = {}
item["com_from"] = "itcast"
logger.warning(item)
导入模块,生成实例,调用,打印如下,可以看出哪个文件打印出来的日志
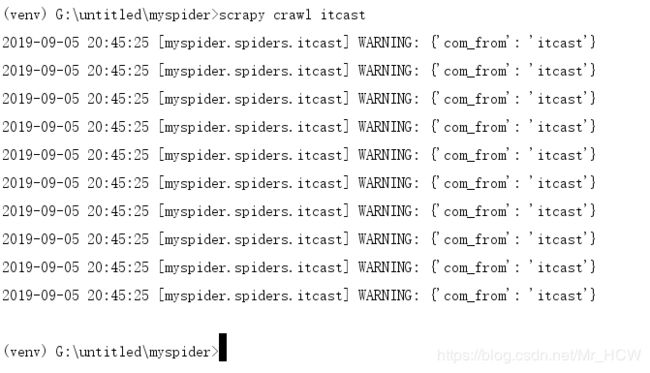
还可以将日志保存到本地
在settings.py里添加如下语句
LOG_FILE = './log.log' # 文件路径
这时候,日志都保存到这个文件里面,而终端不会显示
构造request请求
我们如何请求下一页呢?或者又是别的url?
# -*- coding: utf-8 -*-
import scrapy
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ['http://itcast.cn/']
def parse(self, response):
'''
do something
'''
# 通过一系列操作获取到url
next_url = "http://www.xxx.com"
yield scrapy.Request(
next_url,
callback=self.parse
)
还可以带其他的参数

cookie和headers是分开的
callback可以指向另一个parse函数,不一定是本身
还可以实现参数的传递
# -*- coding: utf-8 -*-
import scrapy
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ['http://itcast.cn/']
def parse(self, response):
'''
do something
'''
item = {}
item["title"] = "xxx"
item["href"] = "xxx"
yield item
# 通过一系列操作获取到url
next_url = "http://www.xxx.com"
yield scrapy.Request(
next_url,
callback=self.parse1,
meta = {"item":item }
)
def parse1(self, response):
item = response.meta["item"] # 获取上面的item
小练习,爬取腾讯的某网站
# -*- coding: utf-8 -*-
import scrapy
class HrSpider(scrapy.Spider):
name = 'hr'
allowed_domains = ['tencent.com']
start_urls = ['http://hr.tencent.com/position.php']
def parse(self, response):
tr_list = response.xpath("//table[@class='tablelist']/tr")[1:-1]
for tr in tr_list:
item = {}
item["title"] = tr.xpath("./td[1]/a/text()").extract_first()
item["position"] = tr.xpath("./td[2]/text()").extract_first()
item["publish_date"] = tr.xpath("./td[5]/a/text()").extract_first()
yield item
# 找到下一页的url
next_url= response.xpath("//a[@id='next']/@href").extract_first()
if next_url != "javascript":
yield scrapy.Request(
next_url,
callback=self.parse # 下一页处理方式一样,所以返给自己
# 如果处理方式不一样,可以另外写一个回调函数
)
设置User-Agent
在setting.py文件里,注销这么条语句,换取自己的User-Agent
![]()
携带cookies模拟登入
有没有这么个疑问
start_urls是谁发送请求的呢
其实里面有个start_requests()方法,用来解析start_urls的
要想携带cookies模拟登入,这需要重写start_requests()方法
def start_requests(self):
# cookies = "ASP.NET_SessionId=cnnceln3g2ldis55lhjuyxrw"
# cookies = {i.split("=")[0]:i.split("="[1]) for i in cookies.split("; ")}
cookies = {"ASP.NET_SessionId":"cnnceln3g2ldis55lhjuyxrw"}
yield scrapy.Request(
self.start_urls[0],
callback=self.parse,
cookies=cookies
)